
 Peranti teknologi
AI
Google mengeluarkan set data BIG-Bench Mistake untuk membantu model bahasa AI meningkatkan keupayaan pembetulan diri
Peranti teknologi
AI
Google mengeluarkan set data BIG-Bench Mistake untuk membantu model bahasa AI meningkatkan keupayaan pembetulan diri
Google mengeluarkan set data BIG-Bench Mistake untuk membantu model bahasa AI meningkatkan keupayaan pembetulan diri


Google Research menggunakan penanda aras BIG-Bench sendiri untuk menubuhkan set data "BIG-Bench Mistake" dan menjalankan penyelidikan penilaian tentang kebarangkalian ralat dan keupayaan pembetulan ralat model bahasa popular di pasaran. Inisiatif ini bertujuan untuk meningkatkan kualiti dan ketepatan model bahasa dan menyediakan sokongan yang lebih baik untuk aplikasi dalam bidang carian pintar dan pemprosesan bahasa semula jadi.
Penyelidik Google berkata mereka mencipta set data khas yang dipanggil "BIG-Bench Mistake" untuk menilai kebarangkalian ralat dan keupayaan pembetulan sendiri model bahasa besar. Tujuan set data ini adalah untuk mengisi jurang kekurangan set data masa lalu untuk menilai keupayaan ini.
Para penyelidik menjalankan 5 tugasan pada penanda aras BIG-Bench menggunakan model bahasa PaLM. Selepas itu, mereka mengubah suai trajektori "Rantai-Pemikiran" yang dijana, menambah bahagian "ralat logik", dan menggunakan model itu sekali lagi untuk menentukan ralat dalam trajektori rantaian-pemikiran.
Untuk meningkatkan ketepatan set data, penyelidik Google mengulangi proses di atas dan membentuk set data penanda aras khusus yang dipanggil "BIG-Bench Mistake", yang mengandungi 255 ralat logik.
Penyelidik menegaskan bahawa ralat logik dalam set data "BIG-Bench Mistake" adalah sangat jelas, jadi ia boleh digunakan sebagai standard ujian yang baik untuk membantu model bahasa mula berlatih daripada ralat logik mudah dan secara beransur-ansur meningkatkan keupayaannya untuk mengenal pasti kesilapan.
Para penyelidik menggunakan set data ini untuk menguji model di pasaran, dan mendapati bahawa walaupun sebahagian besar model bahasa dapat mengenal pasti ralat logik yang berlaku semasa proses penaakulan dan membetulkan sendiri, proses ini "tidak ideal" dan biasanya memerlukan campur tangan Manusia untuk membetulkan kandungan output model.
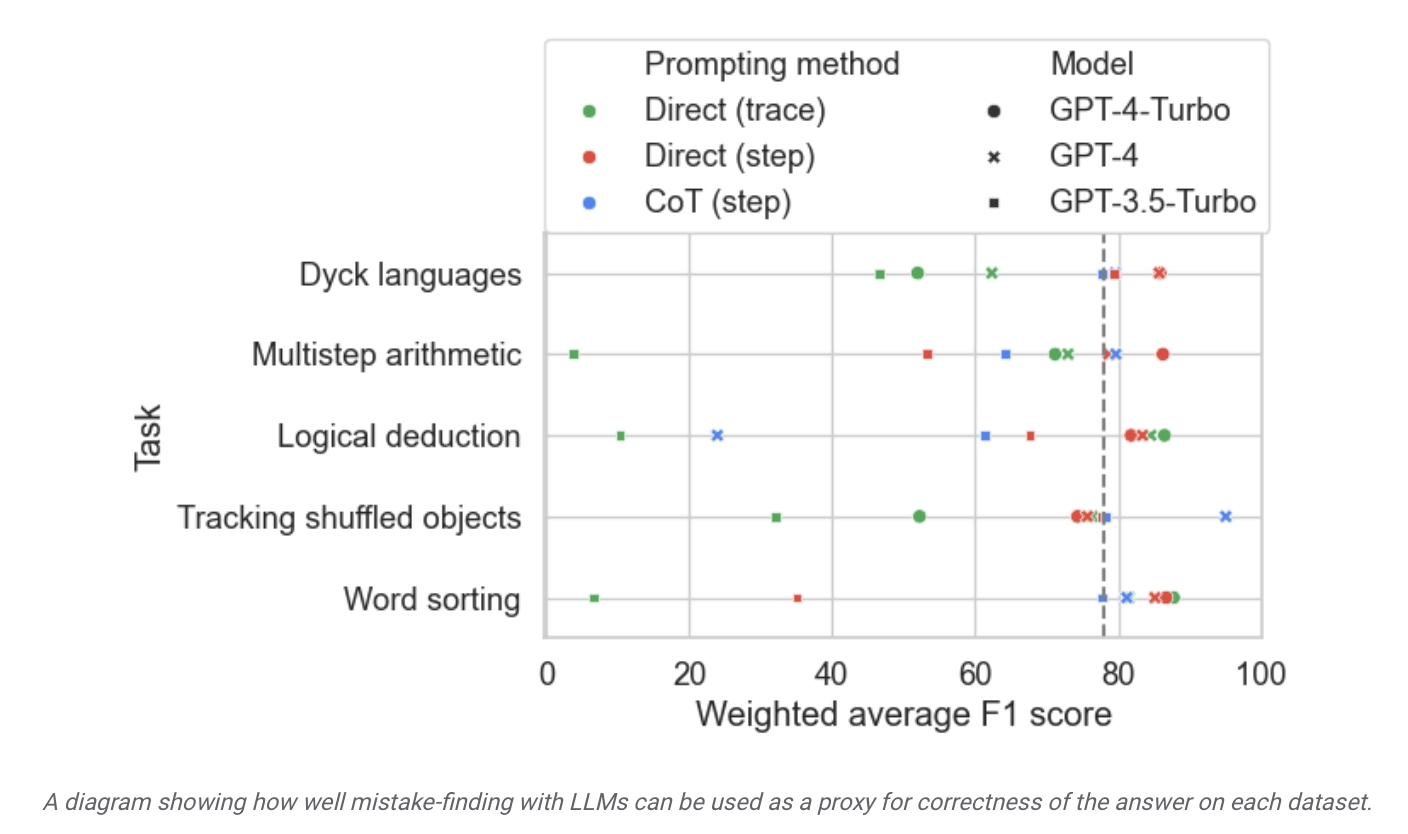
▲ Sumber gambar Siaran Akhbar Penyelidikan Google
Tapak ini mendapati daripada laporan bahawa Google mendakwa bahawa "model bahasa besar yang paling maju pada masa ini" mempunyai keupayaan pembetulan diri yang agak terhad, dan ia menunjukkan prestasi terbaik dalam keputusan ujian yang berkaitan. Model itu hanya menemui 52.9% daripada ralat logik.

Menggunakan model khusus yang kecil. untuk menyelia model besar mempunyai Ia akan membantu meningkatkan kecekapan, mengurangkan kos penggunaan AI yang berkaitan dan memudahkan penalaan halus.
Atas ialah kandungan terperinci Google mengeluarkan set data BIG-Bench Mistake untuk membantu model bahasa AI meningkatkan keupayaan pembetulan diri. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1384
1384
 52
52

 Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Perintah shutdown CentOS adalah penutupan, dan sintaks adalah tutup [pilihan] [maklumat]. Pilihan termasuk: -h menghentikan sistem dengan segera; -P mematikan kuasa selepas penutupan; -r mulakan semula; -T Waktu Menunggu. Masa boleh ditentukan sebagai segera (sekarang), minit (minit), atau masa tertentu (HH: mm). Maklumat tambahan boleh dipaparkan dalam mesej sistem.
 Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Panduan Lengkap untuk Memeriksa Konfigurasi HDFS Dalam Sistem CentOS Artikel ini akan membimbing anda bagaimana untuk memeriksa konfigurasi dan menjalankan status HDFS secara berkesan pada sistem CentOS. Langkah -langkah berikut akan membantu anda memahami sepenuhnya persediaan dan operasi HDFS. Sahkan Pembolehubah Alam Sekitar Hadoop: Pertama, pastikan pembolehubah persekitaran Hadoop ditetapkan dengan betul. Di terminal, laksanakan arahan berikut untuk mengesahkan bahawa Hadoop dipasang dan dikonfigurasi dengan betul: Hadoopversion Semak fail konfigurasi HDFS: Fail konfigurasi teras HDFS terletak di/etc/hadoop/conf/direktori, di mana core-site.xml dan hdfs-site.xml adalah kritikal. gunakan
 Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Dasar sandaran dan pemulihan Gitlab di bawah sistem CentOS untuk memastikan keselamatan data dan pemulihan, Gitlab pada CentOS menyediakan pelbagai kaedah sandaran. Artikel ini akan memperkenalkan beberapa kaedah sandaran biasa, parameter konfigurasi dan proses pemulihan secara terperinci untuk membantu anda menubuhkan strategi sandaran dan pemulihan GitLab lengkap. 1. Backup Manual Gunakan Gitlab-Rakegitlab: Backup: Buat Perintah untuk Melaksanakan Backup Manual. Perintah ini menyokong maklumat utama seperti repositori Gitlab, pangkalan data, pengguna, kumpulan pengguna, kunci, dan kebenaran. Fail sandaran lalai disimpan dalam direktori/var/opt/gitlab/sandaran. Anda boleh mengubah suai /etc /gitlab
 Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Membolehkan pecutan GPU pytorch pada sistem CentOS memerlukan pemasangan cuda, cudnn dan GPU versi pytorch. Langkah-langkah berikut akan membimbing anda melalui proses: Pemasangan CUDA dan CUDNN Tentukan keserasian versi CUDA: Gunakan perintah NVIDIA-SMI untuk melihat versi CUDA yang disokong oleh kad grafik NVIDIA anda. Sebagai contoh, kad grafik MX450 anda boleh menyokong CUDA11.1 atau lebih tinggi. Muat turun dan pasang Cudatoolkit: Lawati laman web rasmi Nvidiacudatoolkit dan muat turun dan pasang versi yang sepadan mengikut versi CUDA tertinggi yang disokong oleh kad grafik anda. Pasang Perpustakaan Cudnn:
 Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Docker menggunakan ciri -ciri kernel Linux untuk menyediakan persekitaran berjalan yang cekap dan terpencil. Prinsip kerjanya adalah seperti berikut: 1. Cermin digunakan sebagai templat baca sahaja, yang mengandungi semua yang anda perlukan untuk menjalankan aplikasi; 2. Sistem Fail Kesatuan (Unionfs) menyusun pelbagai sistem fail, hanya menyimpan perbezaan, menjimatkan ruang dan mempercepatkan; 3. Daemon menguruskan cermin dan bekas, dan pelanggan menggunakannya untuk interaksi; 4. Ruang nama dan cgroups melaksanakan pengasingan kontena dan batasan sumber; 5. Pelbagai mod rangkaian menyokong interkoneksi kontena. Hanya dengan memahami konsep -konsep teras ini, anda boleh menggunakan Docker dengan lebih baik.
 CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
Memasang MySQL pada CentOS melibatkan langkah -langkah berikut: Menambah sumber MySQL YUM yang sesuai. Jalankan YUM Pasang Perintah MySQL-Server untuk memasang pelayan MySQL. Gunakan perintah mysql_secure_installation untuk membuat tetapan keselamatan, seperti menetapkan kata laluan pengguna root. Sesuaikan fail konfigurasi MySQL seperti yang diperlukan. Tune parameter MySQL dan mengoptimumkan pangkalan data untuk prestasi.
 Cara Melihat Log Gitlab Di Bawah Centos
Apr 14, 2025 pm 06:18 PM
Cara Melihat Log Gitlab Di Bawah Centos
Apr 14, 2025 pm 06:18 PM
Panduan Lengkap untuk Melihat Log Gitlab Di bawah Sistem CentOS Artikel ini akan membimbing anda bagaimana untuk melihat pelbagai log Gitlab dalam sistem CentOS, termasuk log utama, log pengecualian, dan log lain yang berkaitan. Sila ambil perhatian bahawa laluan fail log mungkin berbeza -beza bergantung pada versi GitLab dan kaedah pemasangan. Jika laluan berikut tidak wujud, sila semak fail Direktori Pemasangan dan Konfigurasi GitLab. 1. Lihat log Gitlab utama Gunakan arahan berikut untuk melihat fail log utama aplikasi GitLabRails: Perintah: Sudocat/var/Log/Gitlab/Gitlab-Rails/Production.log Perintah ini akan memaparkan produk
 Cara Mengendalikan Latihan Pittorch Diagihkan di Centos
Apr 14, 2025 pm 06:36 PM
Cara Mengendalikan Latihan Pittorch Diagihkan di Centos
Apr 14, 2025 pm 06:36 PM
Latihan yang diedarkan Pytorch pada sistem CentOS memerlukan langkah -langkah berikut: Pemasangan Pytorch: Premisnya ialah Python dan PIP dipasang dalam sistem CentOS. Bergantung pada versi CUDA anda, dapatkan arahan pemasangan yang sesuai dari laman web rasmi Pytorch. Untuk latihan CPU sahaja, anda boleh menggunakan arahan berikut: PipinstallToRchTorchVisionTorchaudio Jika anda memerlukan sokongan GPU, pastikan versi CUDA dan CUDNN yang sama dipasang dan gunakan versi pytorch yang sepadan untuk pemasangan. Konfigurasi Alam Sekitar Teragih: Latihan yang diedarkan biasanya memerlukan pelbagai mesin atau mesin berbilang mesin tunggal. Tempat
