
 Peranti teknologi
AI
Google melancarkan set data BIG-Bench Mistake untuk membantu AI meningkatkan keupayaan pembetulan ralat
Peranti teknologi
AI
Google melancarkan set data BIG-Bench Mistake untuk membantu AI meningkatkan keupayaan pembetulan ralat
Google melancarkan set data BIG-Bench Mistake untuk membantu AI meningkatkan keupayaan pembetulan ralat

Google Research baru-baru ini menjalankan kajian penilaian ke atas model bahasa popular, menggunakan penanda aras BIG-Bench sendiri dan set data "BIG-Bench Mistake" yang baru ditubuhkan. Mereka tertumpu terutamanya pada kebarangkalian ralat dan keupayaan pembetulan ralat model bahasa. Kajian ini menyediakan data berharga untuk lebih memahami prestasi model bahasa di pasaran.
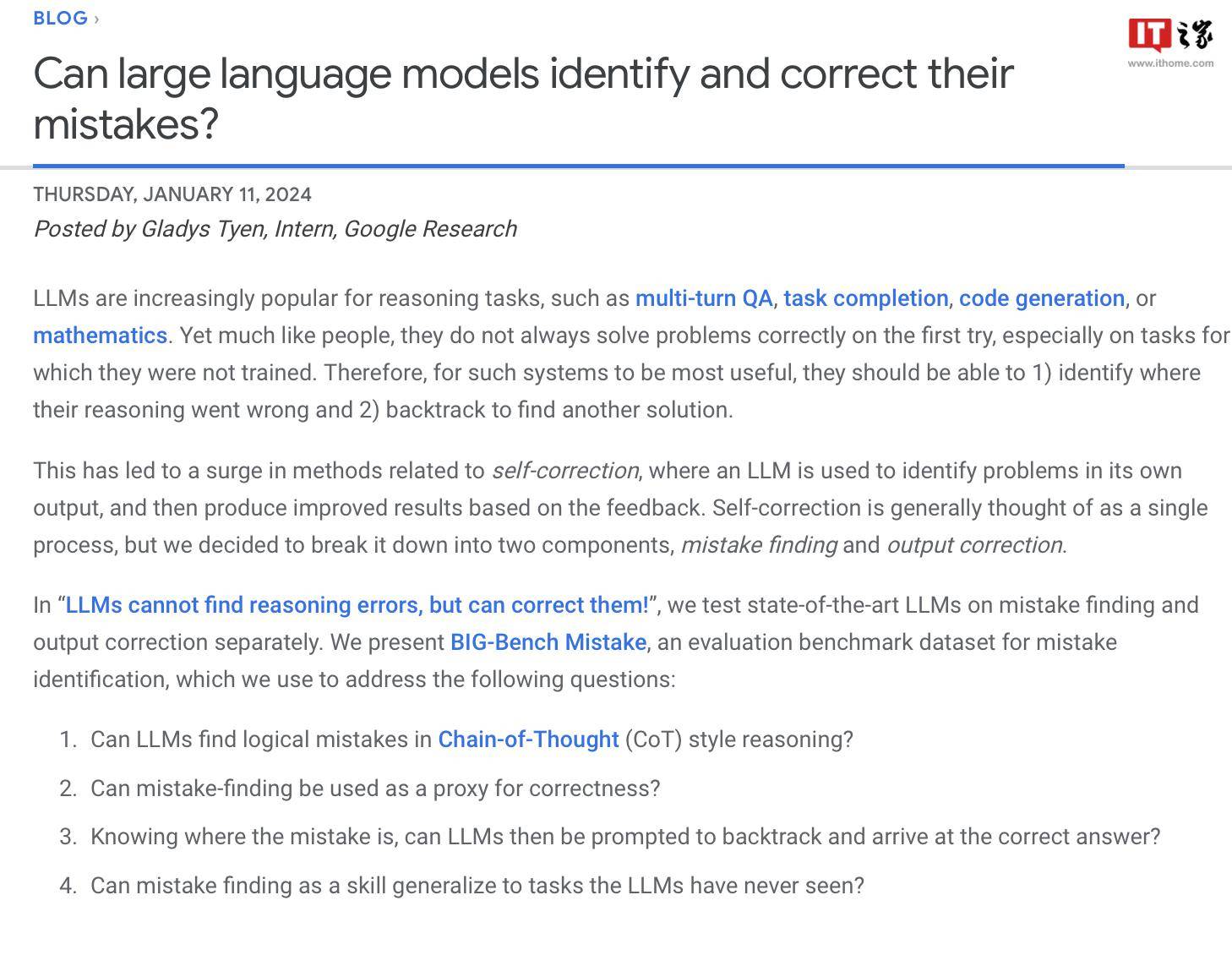
Penyelidik Google berkata mereka mencipta set data penanda aras khas yang dipanggil "BIG-Bench Mistake" untuk menilai "kebarangkalian ralat" dan "keupayaan pembetulan diri" model bahasa yang besar. Ini disebabkan oleh kekurangan set data yang sepadan pada masa lalu untuk menilai dan menguji penunjuk utama ini dengan berkesan.
Para penyelidik menggunakan model bahasa PaLM untuk menjalankan 5 tugasan dalam tugasan penanda aras BIG-Bench mereka sendiri, dan menambahkan trajektori "Chain-of-Thought" yang dijana pada bahagian "Logic Error" untuk menguji semula ketepatan Model.
Untuk meningkatkan ketepatan set data, penyelidik Google mengulangi proses di atas dan akhirnya mencipta set data penanda aras khusus untuk penilaian, yang mengandungi 255 ralat logik, yang dipanggil "BIG-Bench Mistake".
Para penyelidik menegaskan bahawa ralat logik dalam set data "BIG-Bench Mistake" sangat jelas, jadi ia boleh digunakan sebagai standard yang baik untuk ujian model bahasa. Set data ini membantu model belajar daripada ralat mudah dan secara beransur-ansur meningkatkan keupayaannya untuk mengenal pasti ralat.
Para penyelidik menggunakan set data ini untuk menguji model di pasaran dan mendapati bahawa walaupun kebanyakan model bahasa boleh mengenal pasti ralat logik dalam proses penaakulan dan membetulkannya sendiri, proses ini tidak begitu ideal. Selalunya, campur tangan manusia juga diperlukan untuk membetulkan apa yang dihasilkan oleh model.
▲ Sumber gambar siaran akhbar Google Research
Menurut laporan itu, Google mendakwa bahawa ia dianggap sebagai model bahasa besar yang paling maju pada masa ini, tetapi keupayaan pembetulan sendirinya agak terhad. Dalam ujian, model berprestasi terbaik mendapati hanya 52.9% ralat logik.

Penyelidik Google juga mendakwa bahawa set data BIG-Bench Mistake ini kondusif untuk meningkatkan keupayaan pembetulan kendiri model Selepas memperhalusi model pada tugas ujian yang berkaitan, "walaupun model kecil biasanya berprestasi lebih baik daripada model besar dengan gesaan sampel sifar. " ".
Menurut ini, Google percaya bahawa dari segi pembetulan ralat model, model kecil proprietari boleh digunakan untuk "mengawasi" model besar daripada membiarkan model bahasa besar belajar "membetulkan kesilapan diri", menggunakan model khusus kecil yang didedikasikan untuk menyelia. model besar bermanfaat untuk meningkatkan kecekapan, mengurangkan kos penggunaan AI yang berkaitan dan memudahkan penalaan halus.
Atas ialah kandungan terperinci Google melancarkan set data BIG-Bench Mistake untuk membantu AI meningkatkan keupayaan pembetulan ralat. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Apakah Protokol Konteks Model (MCP)?
Mar 03, 2025 pm 07:09 PM
Apakah Protokol Konteks Model (MCP)?
Mar 03, 2025 pm 07:09 PM
Protokol Konteks Model (MCP): Penyambung Universal untuk AI dan Data Kita semua biasa dengan peranan AI dalam pengekodan harian. Replit, GitHub Copilot, Black Box AI, dan Kursor IDE hanyalah beberapa contoh bagaimana AI menyelaraskan aliran kerja kami. Tetapi bayangkan
 Membina ejen penglihatan tempatan menggunakan omniparser v2 dan omnitool
Mar 03, 2025 pm 07:08 PM
Membina ejen penglihatan tempatan menggunakan omniparser v2 dan omnitool
Mar 03, 2025 pm 07:08 PM
Microsoft's Omniparser V2 dan Omnitool: Merevolusi Automasi GUI dengan AI Bayangkan AI yang bukan sahaja memahami tetapi juga berinteraksi dengan antara muka Windows 11 anda seperti profesional berpengalaman. Microsoft Omniparser V2 dan Omnitool menjadikannya semula
 Ejen replit: panduan dengan contoh praktikal
Mar 04, 2025 am 10:52 AM
Ejen replit: panduan dengan contoh praktikal
Mar 04, 2025 am 10:52 AM
Merevolusi pembangunan aplikasi: menyelam mendalam ke dalam ejen replit Bosan dengan gusti dengan persekitaran pembangunan yang kompleks dan fail konfigurasi yang tidak jelas? Ejen replit bertujuan untuk memudahkan proses mengubah idea ke dalam aplikasi berfungsi. Ini AI-P
 Saya cuba pengekodan getaran dengan kursor AI dan ia menakjubkan!
Mar 20, 2025 pm 03:34 PM
Saya cuba pengekodan getaran dengan kursor AI dan ia menakjubkan!
Mar 20, 2025 pm 03:34 PM
Pengekodan Vibe membentuk semula dunia pembangunan perisian dengan membiarkan kami membuat aplikasi menggunakan bahasa semulajadi dan bukannya kod yang tidak berkesudahan. Diilhamkan oleh penglihatan seperti Andrej Karpathy, pendekatan inovatif ini membolehkan Dev
 Panduan Runway Act-One: Saya memfilmkan diri untuk mengujinya
Mar 03, 2025 am 09:42 AM
Panduan Runway Act-One: Saya memfilmkan diri untuk mengujinya
Mar 03, 2025 am 09:42 AM
Pos blog ini berkongsi pengalaman saya menguji Runway ML alat animasi baru ML, yang meliputi kedua-dua antara muka web dan API Python. Walaupun menjanjikan, keputusan saya kurang mengesankan daripada yang diharapkan. Mahu meneroka AI generatif? Belajar menggunakan LLMS dalam p
 Top 5 Genai dilancarkan pada Februari 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
Top 5 Genai dilancarkan pada Februari 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
Februari 2025 telah menjadi satu lagi bulan yang berubah-ubah untuk AI generatif, membawa kita beberapa peningkatan model yang paling dinanti-nantikan dan ciri-ciri baru yang hebat. Dari Xai's Grok 3 dan Anthropic's Claude 3.7 Sonnet, ke Openai's G
 Bagaimana cara menggunakan Yolo V12 untuk pengesanan objek?
Mar 22, 2025 am 11:07 AM
Bagaimana cara menggunakan Yolo V12 untuk pengesanan objek?
Mar 22, 2025 am 11:07 AM
Yolo (anda hanya melihat sekali) telah menjadi kerangka pengesanan objek masa nyata yang terkemuka, dengan setiap lelaran bertambah baik pada versi sebelumnya. Versi terbaru Yolo V12 memperkenalkan kemajuan yang meningkatkan ketepatan
 Elon Musk & Sam Altman bertembung lebih daripada $ 500 bilion projek Stargate
Mar 08, 2025 am 11:15 AM
Elon Musk & Sam Altman bertembung lebih daripada $ 500 bilion projek Stargate
Mar 08, 2025 am 11:15 AM
Projek AI Stargate $ 500 bilion, yang disokong oleh gergasi teknologi seperti Openai, Softbank, Oracle, dan Nvidia, dan disokong oleh kerajaan A.S., bertujuan untuk mengukuhkan kepimpinan AI Amerika. Usaha bercita -cita tinggi ini menjanjikan masa depan yang dibentuk oleh AI Advanceme
