

Yuanxiang mengeluarkan model besar sumber terbuka pertama di dunia XVERSE-Long-256K dengan panjang tetingkap konteks 256K. Model ini menyokong input 250,000 aksara Cina, membolehkan aplikasi model besar memasuki "era teks panjang." Model ini adalah sumber terbuka sepenuhnya dan boleh digunakan secara komersil secara percuma tanpa sebarang syarat Ia juga disertakan dengan tutorial latihan langkah demi langkah yang terperinci, yang membolehkan sejumlah besar perusahaan kecil dan sederhana, penyelidik dan pemaju merealisasikan "besar. kebebasan model" tadi.
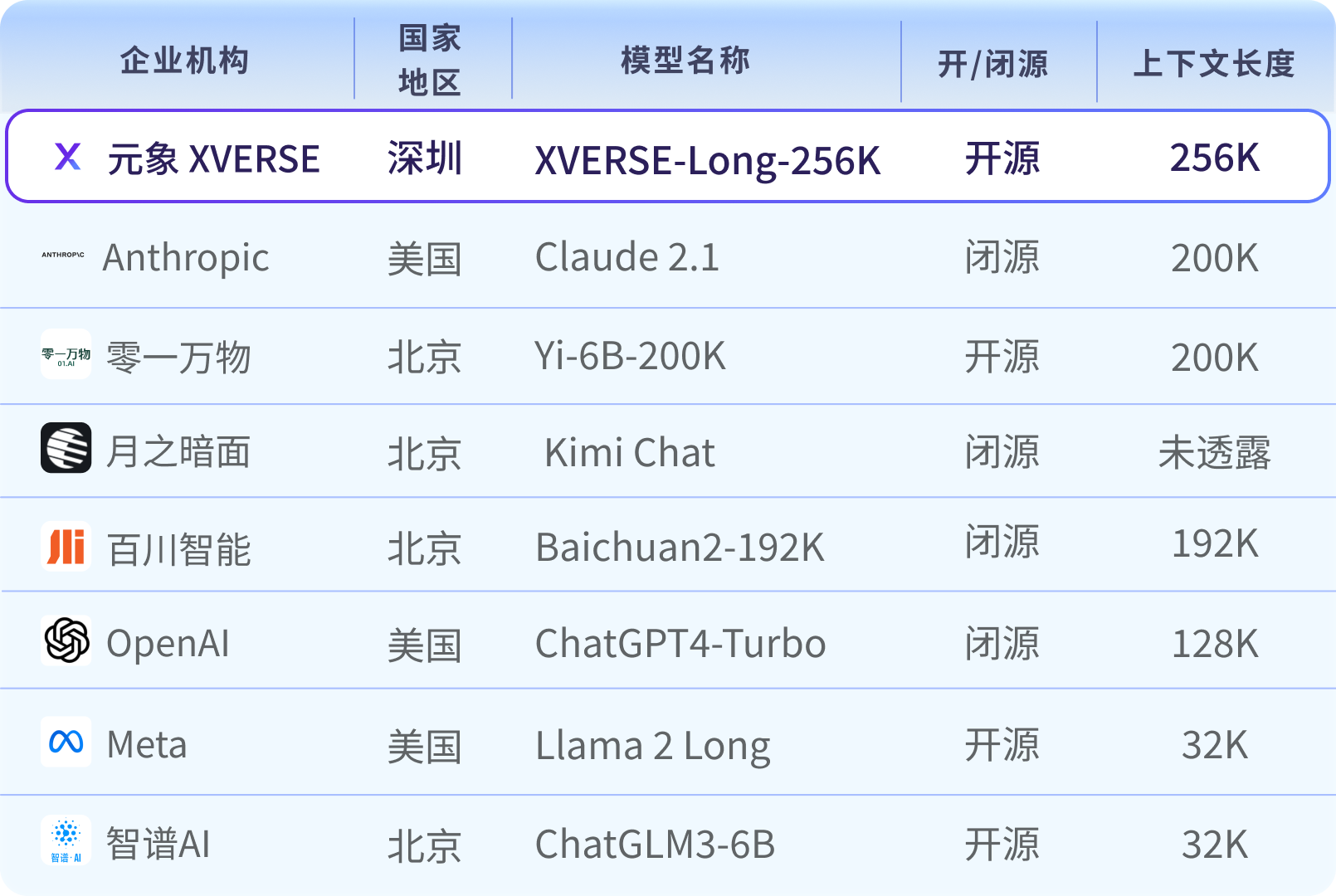 Peta model besar teks panjang arus perdana global
Peta model besar teks panjang arus perdana global
Jumlah parameter dan jumlah data berkualiti tinggi menentukan kerumitan pengiraan model besar, dan teknologi teks panjang (Konteks Panjang) ialah "pembunuh" dalam pembangunan daripada aplikasi model besar Disebabkan oleh teknologi baru, Sukar untuk dibangunkan dan dibangunkan, dan kebanyakannya kini disediakan oleh sumber tertutup berbayar.
XVERSE-Long-256K menyokong input teks ultra-panjang dan boleh digunakan untuk analisis data berskala besar, pemahaman bacaan berbilang dokumen dan integrasi pengetahuan merentas domain, meningkatkan kedalaman dan keluasan aplikasi model besar dengan berkesan: 1. Bagi peguam, penganalisis kewangan atau perunding Guru, jurutera segera, penyelidik saintifik, dan lain-lain boleh menyelesaikan kerja menganalisis dan memproses teks yang lebih panjang 2. Dalam aplikasi main peranan atau sembang, ia boleh mengurangkan masalah ingatan model "melupakan"; dialog sebelumnya, atau masalah karut "halusinasi";
Setakat ini, XVERSE-Long-256K telah mengisi jurang dalam ekosistem sumber terbuka, dan juga telah membentuk "baldi keluarga berprestasi tinggi" dengan model besar parameter 7 bilion, 13 bilion dan 65 bilion Yuanxiang sebelum ini, meningkatkan sumber terbuka domestik ke peringkat kelas pertama dunia. 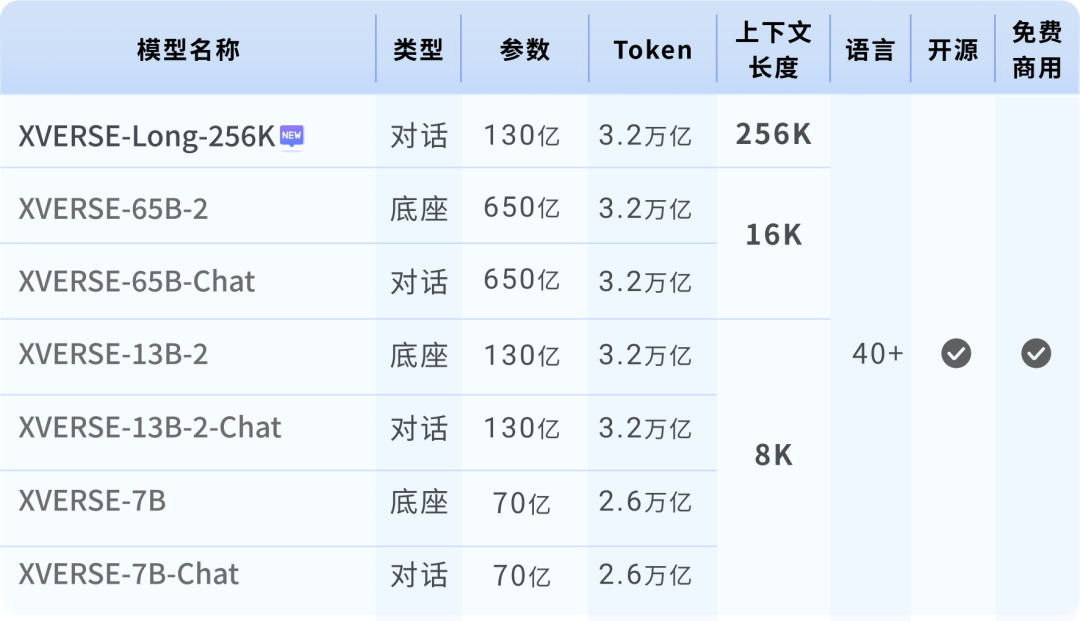 Siri model besar Yuanxiang
Siri model besar Yuanxiang
Muat turun percuma model besar Yuanxiang
Untuk memastikan industri mempunyai pemahaman yang komprehensif, objektif dan jangka panjang tentang model besar Yuanxiang, para penyelidik merujuk kepada penilaian industri yang berwibawa dan membangunkan 9 item komprehensif sistem penilaian dalam enam dimensi. XVERSE-Long-256K semuanya berprestasi baik, mengatasi model teks panjang yang lain.
Hasil penilaian model besar sumber terbuka teks panjang arus perdana global XVERSE-Long-256K lulus ujian tekanan prestasi model besar teks panjang biasa "mencari jarum dalam timbunan jerami". Ujian ini menyembunyikan ayat dalam korpus teks panjang yang tiada kaitan dengan kandungannya dan menggunakan soalan bahasa semula jadi untuk membolehkan model besar mengeluarkan ayat dengan tepat.
Novel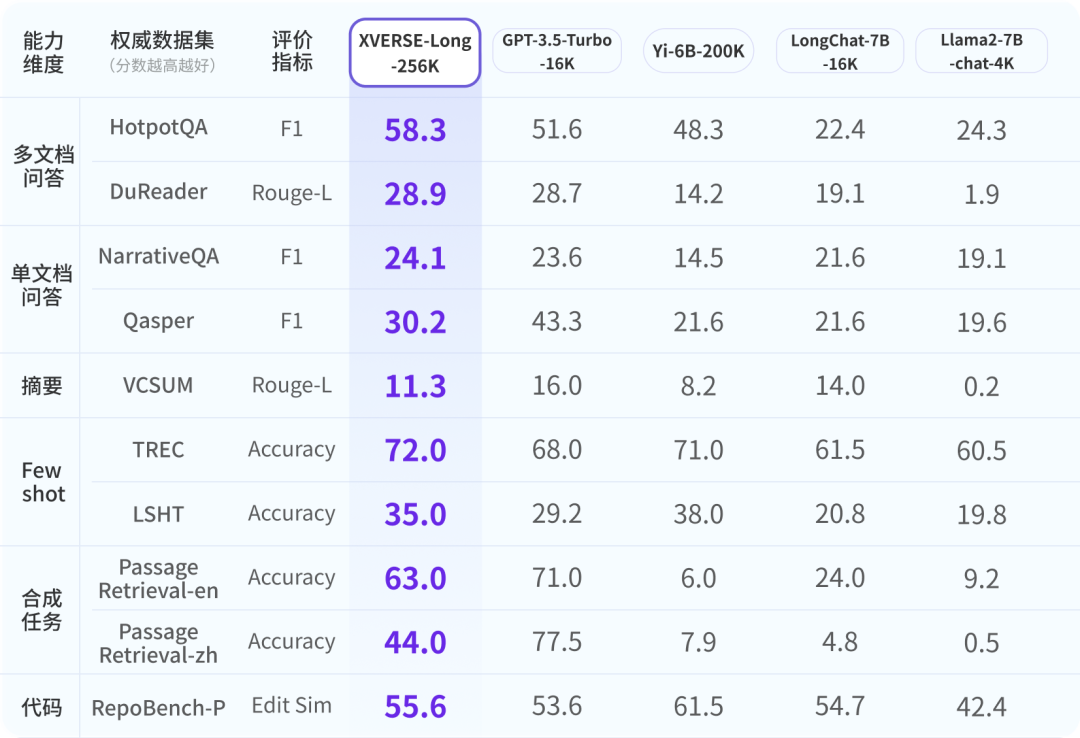
Pemahaman Membaca
Pada masa ini, kebanyakan model berskala besar di China hanya menyokong dwibahasa Cina dan Inggeris, tetapi Yuanxiang menyokong lebih daripada 40 bahasa. Kami menguji novel klasik Rusia 160,000 aksara "How the Steel Was Tempered" dan biografi sejarah Jerman 410,000 aksara "When the Stars of Mankind Shine." Ujian "How Steel Was Tempered (Versi Rusia)"
"When Human Stars Shine (Versi Jerman)" UjianUndang-undang dan Peraturan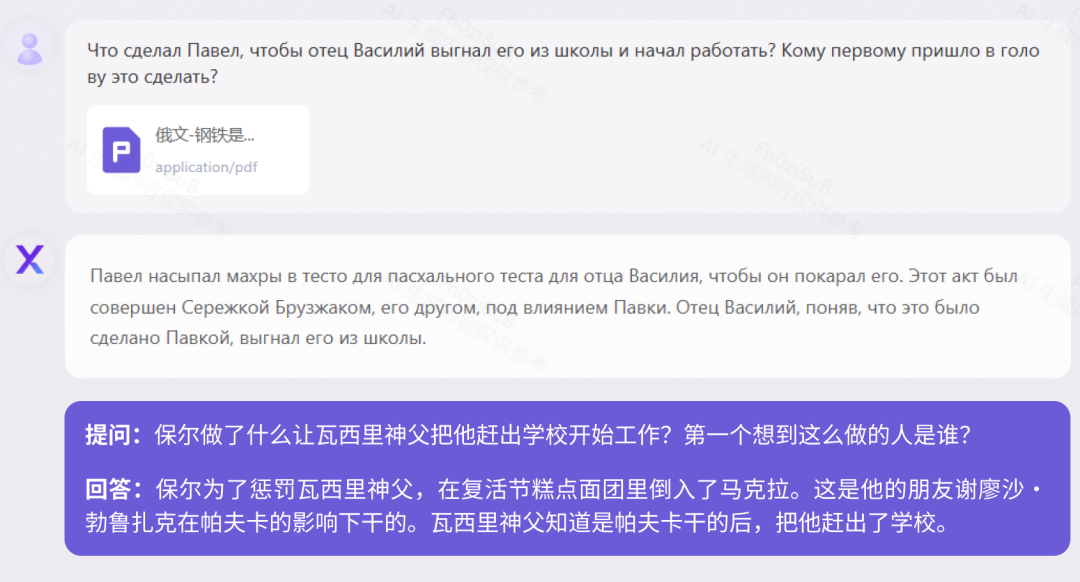
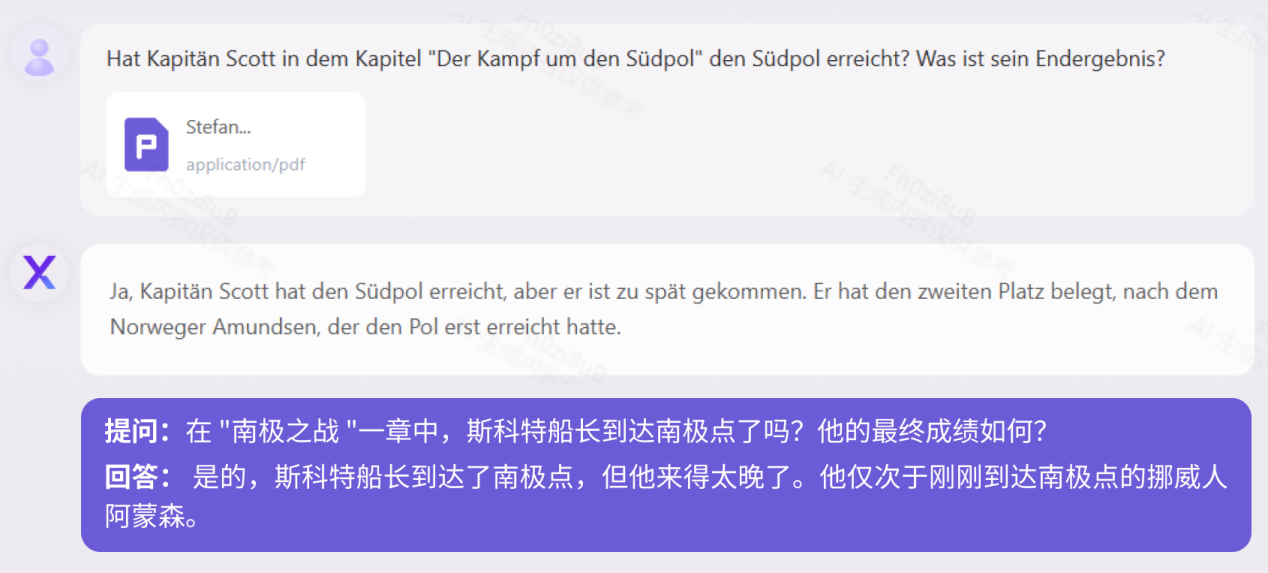
Accurate Aplikasi Berasaskan Sivil China Kod Republik Rakyat China sebagai contoh, ia menunjukkan penjelasan istilah undang-undang, analisis logik kes, dan aplikasi fleksibel dalam kombinasi dengan realiti: ujian "Kod Sivil"
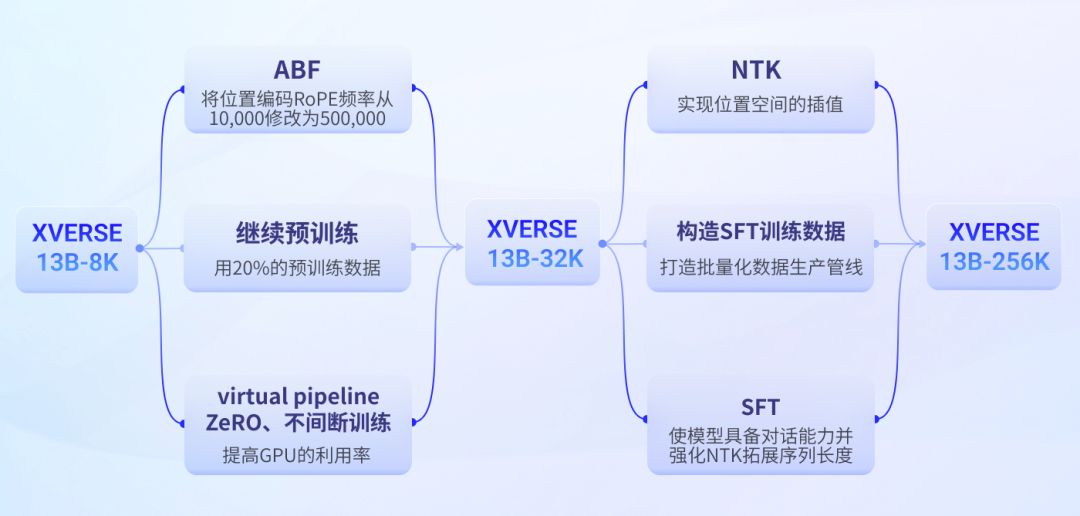
Ajar anda langkah demi langkah cara melatih model besar teks panjang 


Cabaran Teknikal
Proses latihan model besar teks panjang Yuanxiang
https://Github1.
Atas ialah kandungan terperinci Model sumber terbuka terpanjang di dunia XVERSE-Long-256K, yang percuma tanpa syarat untuk kegunaan komersial. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



