

Artikel ini akan memperkenalkan kerosakan yang sukar dalam persekitaran virtualisasi yang telah menyusahkan penulis selama hampir setengah tahun Punca terakhir kerosakan dan kaedah pembaikan juga tidak masuk akal. Bukan kerana proses ini rumit, tetapi untuk berkongsi proses psikologi, memikirkan cara mengimbangi perniagaan dan teknologi apabila menghadapi kegagalan, dan cara menggunakan enjin carian dengan betul.
Fenomena kesalahanKami mempunyai kluster proksi berprestasi tinggi yang berjalan secara stabil semasa fasa ujian dalaman Namun, kurang daripada setengah bulan ia dilancarkan secara rasmi, hos yang menyediakan perkhidmatan proksi tiba-tiba ranap satu demi satu, menyebabkan semua perkhidmatan pada hos menjadi. tergendala.
Analisis KesalahanApabila berlaku kerosakan, hos ranap secara langsung dan tidak boleh log masuk dari jauh Bilik komputer bertindak balas kepada penaipan papan kekunci di tapak. Memandangkan syslog hos telah disambungkan kepada ELK, kami mengumpul pelbagai syslog sebelum dan selepas ranap sistem.
Log ralatDengan menyemak syslog hos yang ranap, saya mendapati bahawa ralat kernel berikut telah dilaporkan sebelum mesin ranap:
Nov 12 15:06:31 hello-worldkernel: [6373724.634681] BUG: unable to handle kernel NULL pointer dereferenceat 0000000000000078 Nov 12 15:06:31 hello-world kernel: [6373724.634718] IP: []pick_next_task_fair+0x6b8/0x820 Nov 12 15:06:31 hello-world kernel: [6373724.634749] PGD 10561e4067 PUDffdb46067 PMD 0 Nov 12 15:06:31 hello-world kernel: [6373724.634780] Oops: 0000 [#1] SMP
Ia menunjukkan bahawa mengakses penuding null kernel mencetuskan pepijat sistem, yang kemudian menyebabkan satu siri ralat tindanan panggilan dan akhirnya ranap.
Untuk menganalisis lebih lanjut fenomena kerosakan, anda perlu memahami seni bina kelompok proksi berprestasi tinggi ini terlebih dahulu.
Pengenalan seni bina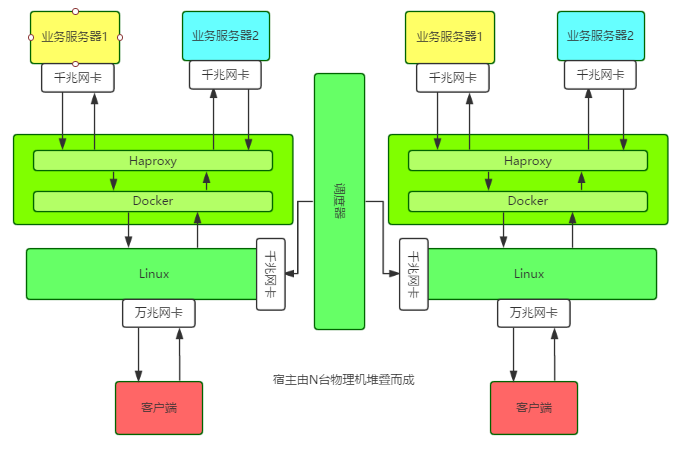
Satu nod menjalankan bekas Docker pada hos dengan kad rangkaian 10G, dan kemudian menjalankan tika Haproxy dalam bekas Maklumat konfigurasi dan maklumat perniagaan setiap nod dan tika itu dihoskan pada penjadual.
Perkara istimewanya ialah: hos menggunakan Linux Bridge untuk mengkonfigurasi terus alamat IP untuk bekas Docker Semua IP perkhidmatan luaran, termasuk IP rangkaian luaran hos sendiri, terikat dengan Linux Bridge.
Pengenalan permohonanSistem pengendalian, perkakasan dan versi Docker bagi setiap hos semuanya adalah sama Sistem pengendalian dan versi Docker adalah seperti berikut:
[操作系统] System : Linux Kernel : 3.16.0-4-amd64 Version : 8.5 Arch : x86_64 [Docker版本] Docker version 1.12.1, build 6b644ec
Konfigurasi hos kluster ini adalah konsisten, dan simptom kerosakan juga konsisten. Terdapat tiga keraguan:
1. Versi Docker tidak serasi dengan versi kernel hosPersekitaran tiga hos pada asalnya adalah sama, tetapi satu hos menjalankan perkhidmatan secara stabil selama 2 bulan sebelum ranap, satu hos menjalankan perkhidmatan dan ranap selepas sebulan, dan satu lagi ranap selepas seminggu menjalankan perkhidmatan dalam talian.
Didapati bahawa sebagai tambahan kepada log ranap yang tidak normal, setiap hos juga mempunyai log ralat yang sama:
time=”2016-09-07T20:22:19.450573015+08:00″level=warning msg=”Your kernel does not support cgroup memory limit” time=”2016-09-07T20:22:19.450618295+08:00″ level=warningmsg=”Your kernel does not support cgroup cfs period” time=”2016-09-07T20:22:19.450640785+08:00″ level=warningmsg=”Your kernel does not support cgroup cfs quotas” time=”2016-09-07T20:22:19.450769672+08:00″ level=warningmsg=”mountpoint for pids not found”
Mengikut petua di atas, ia sepatutnya disebabkan oleh versi kernel sistem pengendalian tidak menyokong fungsi tertentu untuk versi Docker ini. Walau bagaimanapun, carian pada enjin carian tidak menjejaskan fungsi Docker, dan ia juga tidak menjejaskan kestabilan sistem.
Contohnya:
time=”2017-01-19T18:16:30+08:00″level=error msg=”containerd: notify OOM events” error=”openmemory.oom_control: no such file or directory” time=”2017-01-19T18:22:41.368392532+08:00″level=error msg=”Handler for POST /v1.23/containers/338016c68da6/stopreturned error: No such container: 338016c68da6″
Ini adalah masalah yang telah wujud sejak Docker 1.9 dan telah diperbaiki dalam 1.12.3.
Sebagai contoh, seseorang di Github menjawab:
“I have been update my docker from 1.11.2 to 1.12.3, This issue is fixed. BTW, this error message can be ignored, it should really just be a warning.”
Tetapi apa yang dinyatakan di sini hanyalah masalah yang boleh diperbaiki oleh versi v1.12.2 Selepas kami menaik taraf versi Docker, kami mendapati bahawa ranap sistem masih berterusan.
Jadi, kami kemudian mengesahkan banyak masalah dengan fenomena kerosakan yang sama seperti kami melalui pelbagai Google, dan pada mulanya mengesahkan korelasi antara kesalahan dan Docker Berdasarkan isu rasmi, kami juga pada mulanya mengesahkan bahawa versi Docker tidak serasi dengan kernel sistem versi dan boleh menyebabkan prestasi henti; kemudian, melalui changelog dan isu rasmi, kami mengesahkan bahawa versi Docker yang digunakan oleh hos tidak serasi dengan versi kernel sistem, kami telah meningkatkan versi Docker kepada 1.12.2 , tetapi nahas masih berlaku tanpa sebarang kemalangan.
2 Menggunakan kaedah jambatan Linux untuk mengubah suai kad rangkaian hos boleh mencetuskan pepijatSaya menemui hos yang ranap selepas menjalankan perkhidmatan selama seminggu, berhenti menjalankan Docker dan hanya mengubah suai rangkaian Ia berjalan dengan stabil selama seminggu dan tiada kelainan ditemui.
3 Menggunakan kerja paip untuk mengkonfigurasi IP untuk bekas Docker boleh mencetuskan pepijatMemandangkan kami menggunakan skrip kerja paip sumber terbuka semasa memberikan IP kepada bekas, kami mengesyaki terdapat pepijat dalam prinsip kerja kerja paip, jadi kami cuba menetapkan alamat IP tanpa menggunakan kerja paip, dan mendapati hos masih ranap.
Jadi penyelesaian masalah awal menghadapi masalah, dan sangat mengecewakan untuk melihat hos mengalami kemalangan sekurang-kurangnya sekali sebulan.
故障定位因为还有线上业务在跑,所以没有贸然升级所有宿主内核,而是期望能通过升级Docker或者其它热更新的方式修复问题。但是不断的尝试并没有带来理想中的效果。
直到有一天,在跟一位对Linux内核颇有研究的老司机聊起这个问题时,他三下五除二,Google到了几篇文章,然后提醒我们如果是这个 bug,那是在 Linux 3.18 内核才能修复的。
原因:从sched: Fix race between task_group and sched_task_group的解析来看,就是parent 进程改变了它的task_group,还没调用cgroup_post_fork()去同步给child,然后child还去访问原来的cgroup就会null。
不过这个问题发生在比较低版本的Docker,基本是Docker 1.9以下,而我们用的是Docker1.11.1/1.12.1。所以尽管报错现象比较相似,但我们还是没有100%把握。
但是,这个提醒却给我们打开了思路:去看内核代码,实在不行就下掉所有业务,然后全部升级操作系统内核,保持一个月观察期。
于是,我们开始啃Linux内核代码之路。先查看操作系统本地是否有源码,没有的话需要去Linux kernel官方网站搜索。
下载了源码包后,根据报错syslog的内容进行关键字匹配,发现了以下内容。由于我们的机器是x86_64架构,所以那些avr32/m32r之类的可以跳过不看。结果看下来,完全没有可用信息。
/kernel/linux-3.16.39#grep -nri “unable to handle kernel NULL pointer dereference” * arch/tile/mm/fault.c:530: pr_alert(“Unable to handlekernel NULL pointer dereference/n”); arch/sparc/kernel/unaligned_32.c:221: printk(KERN_ALERT “Unable to handle kernel NULL pointerdereference in mna handler”); arch/sparc/mm/fault_32.c:44: “Unable to handle kernel NULL pointer dereference/n”); arch/m68k/mm/fault.c:47: pr_alert(“Unable tohandle kernel NULL pointer dereference”); arch/ia64/mm/fault.c:292: printk(KERN_ALERT “Unable tohandle kernel NULL pointer dereference (address %016lx)/n”, address); debian/patches/bugfix/all/mpi-fix-null-ptr-dereference-in-mpi_powm-ver-3.patch:20:BUG:unable to handle kernel NULL pointer dereference at (null)
最后,我们还是下线了所有业务,将操作系统内核和Docker版本全部升级到最新版。这个过程有些艰难,当初推广这个系统时拉的广告历历在目,现在下线业务,回炉重造,挺考验勇气和决心的。
故障处理下面是整个故障处理过程中,我们进行的一些操作。
升级操作系统内核对于Docker 1.11.1与内核4.9不兼容的问题,可以删除原有的Docker配置,然后使用官方脚本重新安装最新版本Docker
/proxy/bin#ls /var/lib/dpkg/info/docker-engine. docker-engine.conffiles docker-engine.md5sums docker-engine.postrm docker-engine.prerm docker-engine.list docker-engine.postinst docker-engine.preinst #Getthe latest Docker package. $curl -fsSL https://get.docker.com/ | sh #启动 nohupdocker daemon -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock-s=devicemapper&
这里需要注意的是,Docker安装方式在不同操作系统版本上不尽相同,甚至相同发行版上也有不同,比如原来我们使用以下方式安装Docker:
apt-get install docker-engine
然后在早些时候,还有使用下面的安装方式:
apt-get install lxc-docker
可能是基于原来安装方式的千奇百怪导致问题丛出,所以Docker官方提供了一个脚本用于适配不同系统、不同发行版本Docker安装的问题,这也是一个比较奇怪的地方,所以Docker生态还是蛮乱的。
验证16:44:15 up 28 days, 23:41, 2 users, load average: 0.10, 0.13, 0.15 docker 30320 1 0 Jan11 ? 00:49:56 /usr/bin/docker daemon -p/var/run/docker.pid
Docker内核升级到1.19,Linux内核升级到3.19后,保持运行至今已经2个月多了,都是ok的。
总结这个故障的处理时间跨度很大,都快半年了,想起今年除夕夜收到服务器死机报警的情景,心里像打破五味瓶一样五味杂陈。期间问过不少研究Docker和操作系统内核的同事,往操作系统内核版本等各个方向进行了测试,但总与正确答案背道而驰或差那么一点点。最后发现原来是处理得不够彻底,比如升级不彻底,环境被污染;比如升级的版本不够新,填的坑不够厚。回顾了整个故障处理过程,总结下来大概如下:
回归运维的本质运维要具有预见性、长期规划,而不能仅仅满足于眼前:
Dalam proses menangani masalah ini, anda akan mendapati bahawa orang yang berbeza mencari perkara yang berbeza menggunakan Google. Saya rasa di sinilah enjin carian penuh dengan kelemahan, atau fleksibel. Untuk kesalahan ini, saya menggunakan Linux Docker Unable to handle kernel NULL pointer dereference untuk mencari, tetapi hasilnya berbeza daripada yang lain menggunakan "Unable to handle kernel NULL pointer dereference". Sebabnya ialah selepas menambah "", carian menjadi lebih tepat. Mengenai cara yang betul untuk membuka Google.
Atas ialah kandungan terperinci Masalah yang merisaukan saya selama setengah tahun. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



