
 Peranti teknologi
AI
Pengubah Titik Dikemas kini: lebih cekap, lebih pantas dan lebih berkuasa!
Peranti teknologi
AI
Pengubah Titik Dikemas kini: lebih cekap, lebih pantas dan lebih berkuasa!
Pengubah Titik Dikemas kini: lebih cekap, lebih pantas dan lebih berkuasa!

Tajuk asal: Point Transformer V3: Lebih Ringkas, Lebih Cepat, Lebih Kuat
Pautan kertas: https://arxiv.org/pdf/2312.10035.pdf
Pautan kod: https://github.com/Pointcept/PointTransformerV3
Unit: HKU SH AI Lab MPI PKU MITIdea tesis:
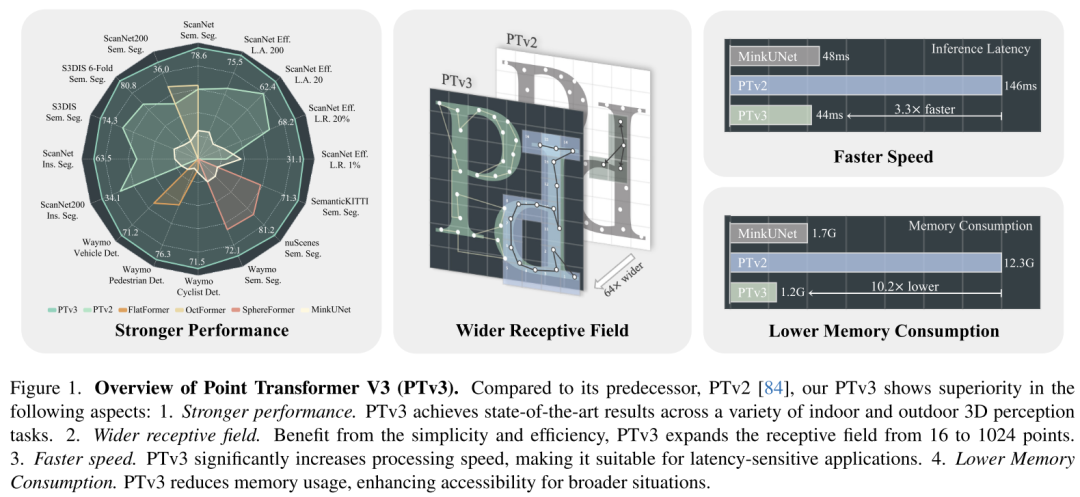
Artikel ini tidak berhasrat untuk mencari inovasi dalam mekanisme perhatian. Sebaliknya, ia memberi tumpuan kepada memanfaatkan kuasa skala untuk mengatasi pertukaran sedia ada antara ketepatan dan kecekapan dalam konteks pemprosesan awan titik. Mendapat inspirasi daripada kemajuan terkini dalam pembelajaran perwakilan berskala besar 3D, kertas kerja ini menyedari bahawa prestasi model lebih dipengaruhi oleh skala berbanding kerumitan reka bentuk. Oleh itu, kertas kerja ini mencadangkan Point Transformer V3 (PTv3), yang mengutamakan kesederhanaan dan kecekapan berbanding ketepatan mekanisme tertentu yang kurang memberi kesan kepada prestasi keseluruhan selepas penskalaan, seperti awan titik yang disusun dalam corak tertentu Pemetaan kejiranan bersiri yang cekap untuk menggantikan KNN carian kejiranan yang tepat. Prinsip ini membolehkan penskalaan yang ketara, memanjangkan medan penerimaan daripada 16 kepada 1024 mata, sambil kekal cekap (pemprosesan 3x lebih pantas dan 10x lebih cekap memori berbanding PTv2 sebelumnya). PTv3 mencapai keputusan terkini pada lebih daripada 20 tugasan hiliran yang meliputi senario dalaman dan luaran. PTv3 membawa keputusan ini ke peringkat seterusnya dengan peningkatan selanjutnya melalui latihan bersama multi-dataset.Reka Bentuk Rangkaian:
Kemajuan terkini dalam pembelajaran perwakilan 3D [85] telah mencapai kemajuan dalam mengatasi had skala data dalam pemprosesan awan titik dengan memperkenalkan kaedah latihan kolaboratif merentas berbilang set data 3D. Digabungkan dengan strategi ini, tulang belakang konvolusi yang cekap [12] secara berkesan merapatkan jurang ketepatan yang biasanya dikaitkan dengan pengubah awan titik [38, 84]. Walau bagaimanapun, pengubah awan titik sendiri masih belum mendapat manfaat sepenuhnya daripada kelebihan skala ini disebabkan oleh jurang kecekapan pengubah awan titik berbanding lilitan jarang. Penemuan ini membentuk motivasi awal untuk kerja ini: untuk menimbang semula pilihan reka bentuk pengubah titik dari perspektif prinsip penskalaan. Makalah ini percaya bahawa prestasi model lebih ketara dipengaruhi oleh skala daripada oleh reka bentuk yang kompleks. Oleh itu, artikel ini memperkenalkan Point Transformer V3 (PTv3), yang mengutamakan kesederhanaan dan kecekapan berbanding ketepatan mekanisme tertentu untuk mencapai kebolehskalaan. Pelarasan sedemikian mempunyai kesan yang boleh diabaikan ke atas prestasi keseluruhan selepas penskalaan. Khususnya, PTv3 membuat pelarasan berikut untuk mencapai kecekapan dan kebolehskalaan yang unggul:- Diilhamkan oleh dua kemajuan terkini [48, 77] dan mengiktiraf kelebihan kebolehskalaan awan titik tidak berstruktur berstruktur, PTv3 berubah Kedekatan ruang tradisional yang ditakrifkan oleh K-Nearest Pertanyaan Jiran (KNN) menyumbang 28% daripada masa hadapan. Sebaliknya, ia meneroka potensi kejiranan bersiri dalam awan titik yang disusun mengikut corak tertentu.
- PTv3 menggunakan pendekatan ringkas yang disesuaikan khusus untuk awan titik bersiri, menggantikan mekanisme interaksi patch perhatian yang lebih kompleks seperti tetingkap anjakan (yang menghalang gabungan pengendali perhatian) dan mekanisme kejiranan (membawa kepada penggunaan memori yang tinggi ).
- PTv3 menghapuskan pergantungan pada pengekodan kedudukan relatif, yang menyumbang 26% masa hadapan, memihak kepada lapisan konvolusi jarang bahagian hadapan yang lebih ringkas.
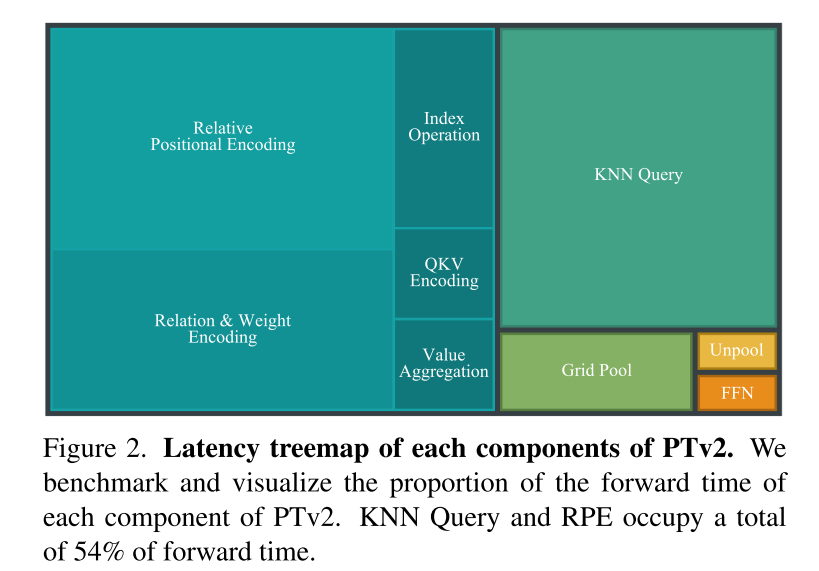

Rajah 3. Siri awan titik. Artikel ini menunjukkan empat corak bersiri melalui visualisasi triplet. Untuk setiap triplet, lengkung pengisian ruang untuk bersiri (kiri), susunan pemboleh ubah siri titik awan dalam lengkung pengisian ruang (tengah), dan tompok awan titik bersiri terkumpul untuk perhatian setempat ditunjukkan (kanan). Transformasi empat mod bersiri membolehkan mekanisme perhatian untuk menangkap pelbagai hubungan ruang dan konteks, dengan itu meningkatkan ketepatan model dan keupayaan generalisasi.
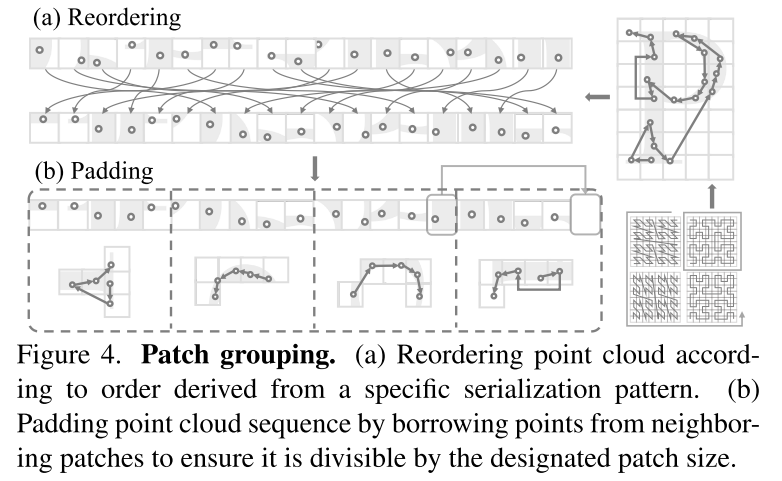
Rajah 4. Pengumpulan tampalan. (a) Menyusun semula awan titik mengikut susunan yang diperoleh daripada skema siri tertentu. (b) Isikan jujukan awan titik dengan meminjam mata daripada tampalan bersebelahan untuk memastikan ia boleh dibahagikan sama rata dengan saiz tampalan yang ditentukan.
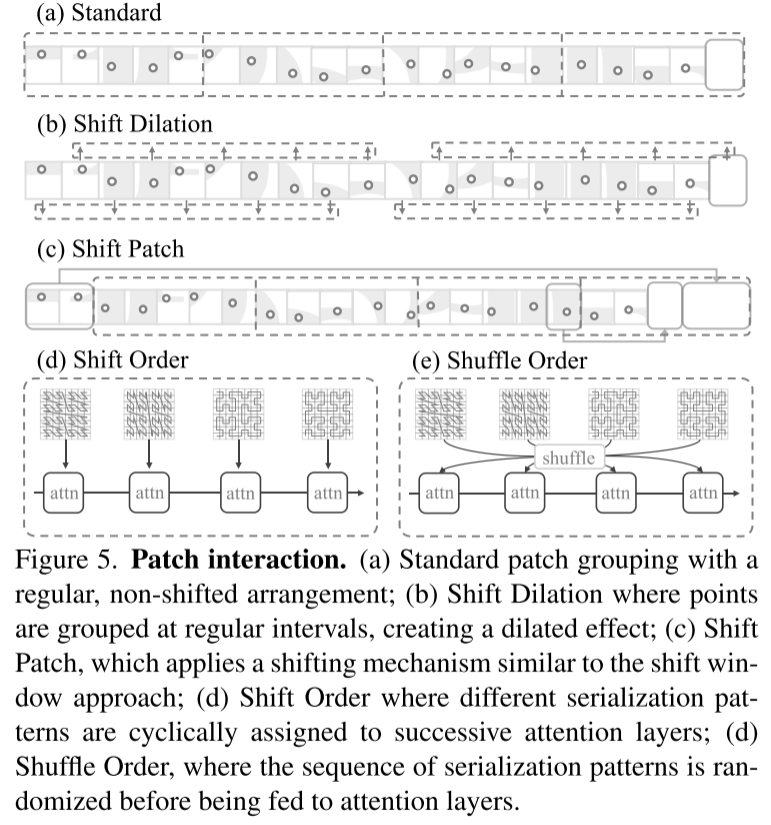
Rajah 5. Interaksi tampalan. (a) Pengelompokan tampalan standard, dengan susunan biasa, tidak beralih; (b) Pengembangan translasi, di mana titik diagregatkan pada selang masa yang tetap untuk menghasilkan kesan pengembangan, yang menggunakan mekanisme peralihan yang serupa dengan kaedah tetingkap anjakan ; (d) Susunan Anjakan, di mana corak siri yang berbeza secara kitaran diberikan kepada lapisan perhatian berturut-turut, di mana urutan corak siri adalah rawak sebelum dimasukkan ke lapisan perhatian.
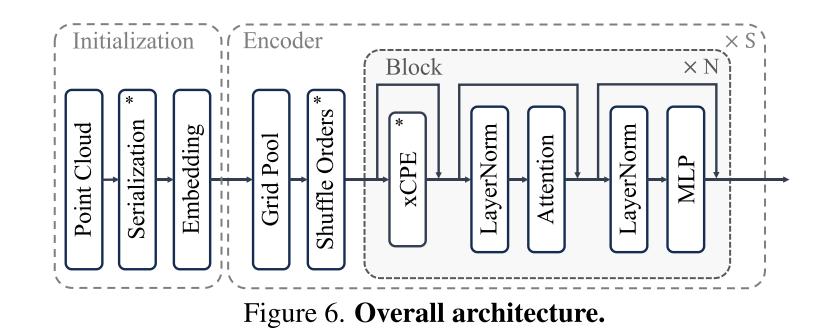
Rajah 6. Keseluruhan seni bina. Hasil eksperimen: Artikel ini memperkenalkan Point Transform er V3, yang berfungsi ke arah mengatasi ketepatan dalam pemprosesan awan titik Satu langkah besar ke hadapan daripada pertukaran tradisional antara kecekapan dan kecekapan. Berpandukan tafsiran baru mengenai prinsip penskalaan dalam reka bentuk tulang belakang, kertas kerja ini berpendapat bahawa prestasi model lebih dipengaruhi oleh skala daripada kerumitan reka bentuk. Dengan mengutamakan kecekapan berbanding ketepatan mekanisme impak yang lebih kecil, kertas kerja ini memanfaatkan kuasa skala, dengan itu meningkatkan prestasi. Ringkasnya, artikel ini boleh menjadikan model lebih berkuasa dengan menjadikannya lebih ringkas dan pantas.
Petikan:
Wu, X., Jiang, L., Wang, P., Liu, Z., Liu, X., Qiao, Y., Ouyang, W., He, T., & Zhao , H. (2023 Point Transformer V3: Lebih Mudah, Lebih Cepat, Lebih Kuat.
Atas ialah kandungan terperinci Pengubah Titik Dikemas kini: lebih cekap, lebih pantas dan lebih berkuasa!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1374
1374
 52
52

 Sumber terbuka! Di luar ZoeDepth! DepthFM: Anggaran kedalaman monokular yang cepat dan tepat!
Apr 03, 2024 pm 12:04 PM
Sumber terbuka! Di luar ZoeDepth! DepthFM: Anggaran kedalaman monokular yang cepat dan tepat!
Apr 03, 2024 pm 12:04 PM
0. Apakah fungsi artikel ini? Kami mencadangkan DepthFM: model anggaran kedalaman monokular generatif yang serba boleh dan pantas. Sebagai tambahan kepada tugas anggaran kedalaman tradisional, DepthFM juga menunjukkan keupayaan terkini dalam tugas hiliran seperti mengecat kedalaman. DepthFM cekap dan boleh mensintesis peta kedalaman dalam beberapa langkah inferens. Mari kita baca karya ini bersama-sama ~ 1. Tajuk maklumat kertas: DepthFM: FastMonocularDepthEstimationwithFlowMatching Pengarang: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Tongyi Qianwen adalah sumber terbuka sekali lagi, Qwen1.5 membawakan enam model volum, dan prestasinya melebihi GPT3.5
Feb 07, 2024 pm 10:15 PM
Tongyi Qianwen adalah sumber terbuka sekali lagi, Qwen1.5 membawakan enam model volum, dan prestasinya melebihi GPT3.5
Feb 07, 2024 pm 10:15 PM
Pada masanya untuk Festival Musim Bunga, versi 1.5 Model Tongyi Qianwen (Qwen) berada dalam talian. Pagi ini, berita versi baharu itu menarik perhatian komuniti AI. Versi baharu model besar termasuk enam saiz model: 0.5B, 1.8B, 4B, 7B, 14B dan 72B. Antaranya, prestasi versi terkuat mengatasi GPT3.5 dan Mistral-Medium. Versi ini termasuk model Base dan model Sembang, dan menyediakan sokongan berbilang bahasa. Pasukan Tongyi Qianwen Alibaba menyatakan bahawa teknologi yang berkaitan juga telah dilancarkan di laman web rasmi Tongyi Qianwen dan Apl Tongyi Qianwen. Selain itu, keluaran Qwen 1.5 hari ini juga mempunyai sorotan berikut: menyokong panjang konteks 32K membuka pusat pemeriksaan model Base+Chat;
 Tinggalkan seni bina pengekod-penyahkod dan gunakan model resapan untuk pengesanan tepi, yang lebih berkesan Universiti Teknologi Pertahanan Nasional mencadangkan DiffusionEdge
Feb 07, 2024 pm 10:12 PM
Tinggalkan seni bina pengekod-penyahkod dan gunakan model resapan untuk pengesanan tepi, yang lebih berkesan Universiti Teknologi Pertahanan Nasional mencadangkan DiffusionEdge
Feb 07, 2024 pm 10:12 PM
Rangkaian pengesanan tepi dalam semasa biasanya menggunakan seni bina penyahkod pengekod, yang mengandungi modul pensampelan atas dan bawah untuk mengekstrak ciri berbilang peringkat dengan lebih baik. Walau bagaimanapun, struktur ini mengehadkan rangkaian untuk mengeluarkan hasil pengesanan tepi yang tepat dan terperinci. Sebagai tindak balas kepada masalah ini, kertas kerja mengenai AAAI2024 menyediakan penyelesaian baharu. Tajuk tesis: DiffusionEdge:DiffusionProbabilisticModelforCrispEdgeDetection Penulis: Ye Yunfan (Universiti Teknologi Pertahanan Nasional), Xu Kai (Universiti Teknologi Pertahanan Kebangsaan), Huang Yuxing (Universiti Teknologi Pertahanan Nasional), Yi Renjiao (Universiti Teknologi Pertahanan Nasional), Cai Zhiping (Universiti Teknologi Pertahanan Negara) Pautan kertas: https ://ar
 Model besar juga boleh dihiris, dan Microsoft SliceGPT sangat meningkatkan kecekapan pengiraan LLAMA-2
Jan 31, 2024 am 11:39 AM
Model besar juga boleh dihiris, dan Microsoft SliceGPT sangat meningkatkan kecekapan pengiraan LLAMA-2
Jan 31, 2024 am 11:39 AM
Model bahasa besar (LLM) biasanya mempunyai berbilion parameter dan dilatih menggunakan trilion token. Walau bagaimanapun, model sedemikian sangat mahal untuk dilatih dan digunakan. Untuk mengurangkan keperluan pengiraan, pelbagai teknik pemampatan model sering digunakan. Teknik pemampatan model ini secara amnya boleh dibahagikan kepada empat kategori: penyulingan, penguraian tensor (termasuk pemfaktoran peringkat rendah), pemangkasan dan kuantisasi. Kaedah pemangkasan telah wujud sejak sekian lama, tetapi banyak yang memerlukan penalaan halus pemulihan (RFT) selepas pemangkasan untuk mengekalkan prestasi, menjadikan keseluruhan proses mahal dan sukar untuk skala. Penyelidik dari ETH Zurich dan Microsoft telah mencadangkan penyelesaian kepada masalah ini yang dipanggil SliceGPT. Idea teras kaedah ini adalah untuk mengurangkan pembenaman rangkaian dengan memadamkan baris dan lajur dalam matriks berat.
 Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas secara rasmi memasuki era robot elektrik! Semalam, Atlas hidraulik hanya "menangis" menarik diri daripada peringkat sejarah Hari ini, Boston Dynamics mengumumkan bahawa Atlas elektrik sedang berfungsi. Nampaknya dalam bidang robot humanoid komersial, Boston Dynamics berazam untuk bersaing dengan Tesla. Selepas video baharu itu dikeluarkan, ia telah pun ditonton oleh lebih sejuta orang dalam masa sepuluh jam sahaja. Orang lama pergi dan peranan baru muncul. Ini adalah keperluan sejarah. Tidak dinafikan bahawa tahun ini adalah tahun letupan robot humanoid. Netizen mengulas: Kemajuan robot telah menjadikan majlis pembukaan tahun ini kelihatan seperti manusia, dan tahap kebebasan adalah jauh lebih besar daripada manusia Tetapi adakah ini benar-benar bukan filem seram? Pada permulaan video, Atlas berbaring dengan tenang di atas tanah, seolah-olah terlentang. Apa yang berikut adalah rahang-jatuh
 Pengubah Titik Dikemas kini: lebih cekap, lebih pantas dan lebih berkuasa!
Jan 17, 2024 am 08:27 AM
Pengubah Titik Dikemas kini: lebih cekap, lebih pantas dan lebih berkuasa!
Jan 17, 2024 am 08:27 AM
Tajuk asal: PointTransformerV3: Pautan Kertas Lebih Ringkas, Pantas, Lebih Kuat: https://arxiv.org/pdf/2312.10035.pdf Pautan kod: https://github.com/Pointcept/PointTransformerV3 Unit pengarang: HKUSHAILabMPIPKUMIT Idea kertas: Artikel ini ialah tidak bertujuan untuk diterbitkan dalam Mencari inovasi dalam mekanisme perhatian. Sebaliknya, ia memberi tumpuan kepada memanfaatkan kuasa skala untuk mengatasi pertukaran sedia ada antara ketepatan dan kecekapan dalam konteks pemprosesan awan titik. Dapatkan inspirasi daripada kemajuan terkini dalam pembelajaran perwakilan berskala besar 3D,
 Daya hidup kecerdasan super membangkitkan! Tetapi dengan kedatangan AI yang mengemas kini sendiri, ibu tidak perlu lagi bimbang tentang kesesakan data
Apr 29, 2024 pm 06:55 PM
Daya hidup kecerdasan super membangkitkan! Tetapi dengan kedatangan AI yang mengemas kini sendiri, ibu tidak perlu lagi bimbang tentang kesesakan data
Apr 29, 2024 pm 06:55 PM
Saya menangis hingga mati. Dunia sedang membina model besar. Data di Internet tidak mencukupi. Model latihan kelihatan seperti "The Hunger Games", dan penyelidik AI di seluruh dunia bimbang tentang cara memberi makan data ini kepada pemakan yang rakus. Masalah ini amat ketara dalam tugas berbilang modal. Pada masa mereka mengalami kerugian, pasukan pemula dari Jabatan Universiti Renmin China menggunakan model baharu mereka sendiri untuk menjadi yang pertama di China untuk menjadikan "suapan data yang dijana model itu sendiri" menjadi kenyataan. Selain itu, ia merupakan pendekatan serampang dua mata dari segi pemahaman dan sisi penjanaan Kedua-dua pihak boleh menjana data baharu berbilang modal yang berkualiti tinggi dan memberikan maklum balas data kepada model itu sendiri. Apakah model? Awaker 1.0, model berbilang modal besar yang baru sahaja muncul di Forum Zhongguancun. Siapa pasukan itu? Enjin Sophon. Diasaskan oleh Gao Yizhao, pelajar kedoktoran di Sekolah Kecerdasan Buatan Hillhouse Universiti Renmin.
 Versi Kuaishou Sora 'Ke Ling' dibuka untuk ujian: menghasilkan video lebih 120-an, memahami fizik dengan lebih baik dan boleh memodelkan pergerakan kompleks dengan tepat
Jun 11, 2024 am 09:51 AM
Versi Kuaishou Sora 'Ke Ling' dibuka untuk ujian: menghasilkan video lebih 120-an, memahami fizik dengan lebih baik dan boleh memodelkan pergerakan kompleks dengan tepat
Jun 11, 2024 am 09:51 AM
Apa? Adakah Zootopia dibawa menjadi realiti oleh AI domestik? Didedahkan bersama-sama dengan video itu ialah model penjanaan video domestik berskala besar baharu yang dipanggil "Keling". Sora menggunakan laluan teknikal yang serupa dan menggabungkan beberapa inovasi teknologi yang dibangunkan sendiri untuk menghasilkan video yang bukan sahaja mempunyai pergerakan yang besar dan munasabah, tetapi juga mensimulasikan ciri-ciri dunia fizikal dan mempunyai keupayaan gabungan konsep dan imaginasi yang kuat. Mengikut data, Keling menyokong penjanaan video ultra panjang sehingga 2 minit pada 30fps, dengan resolusi sehingga 1080p dan menyokong berbilang nisbah aspek. Satu lagi perkara penting ialah Keling bukanlah demo atau demonstrasi hasil video yang dikeluarkan oleh makmal, tetapi aplikasi peringkat produk yang dilancarkan oleh Kuaishou, pemain terkemuka dalam bidang video pendek. Selain itu, tumpuan utama adalah untuk menjadi pragmatik, bukan untuk menulis cek kosong, dan pergi ke dalam talian sebaik sahaja ia dikeluarkan Model besar Ke Ling telah pun dikeluarkan di Kuaiying.
