
 Peranti teknologi
AI
Pasukan carian Xiaohongshu mendedahkan: kepentingan mengesahkan sampel negatif dalam penyulingan model berskala besar
Peranti teknologi
AI
Pasukan carian Xiaohongshu mendedahkan: kepentingan mengesahkan sampel negatif dalam penyulingan model berskala besar
Pasukan carian Xiaohongshu mendedahkan: kepentingan mengesahkan sampel negatif dalam penyulingan model berskala besar


Model Bahasa Besar (LLM) berfungsi dengan baik pada tugasan inferens, tetapi sifat kotak hitamnya dan sejumlah besar parameter mengehadkan penggunaannya dalam amalan. Terutama apabila menangani masalah matematik yang kompleks, LLM kadangkala membangunkan rantaian penaakulan yang salah. Kaedah penyelidikan tradisional hanya memindahkan pengetahuan daripada sampel positif, mengabaikan maklumat penting dengan jawapan yang salah dalam data sintetik. Oleh itu, untuk meningkatkan prestasi dan kebolehpercayaan LLM, kami perlu mempertimbangkan dan menggunakan data sintetik secara lebih komprehensif, bukan hanya terhad kepada sampel positif, untuk membantu LLM lebih memahami dan membuat alasan tentang masalah yang kompleks. Ini akan membantu menyelesaikan cabaran LLM dalam amalan dan mempromosikan aplikasinya yang meluas.
Pada AAAAI 2024, Pasukan algoritma carian Xiaohongshu mencadangkan rangka kerja inovatif yang menggunakan sepenuhnya pengetahuan sampel negatif dalam proses penyulingan penaakulan model besar Sampel negatif, iaitu, data yang gagal menghasilkan jawapan yang betul semasa proses inferens, sering dianggap sebagai tidak berguna, tetapi sebenarnya ia mengandungi maklumat yang berharga.
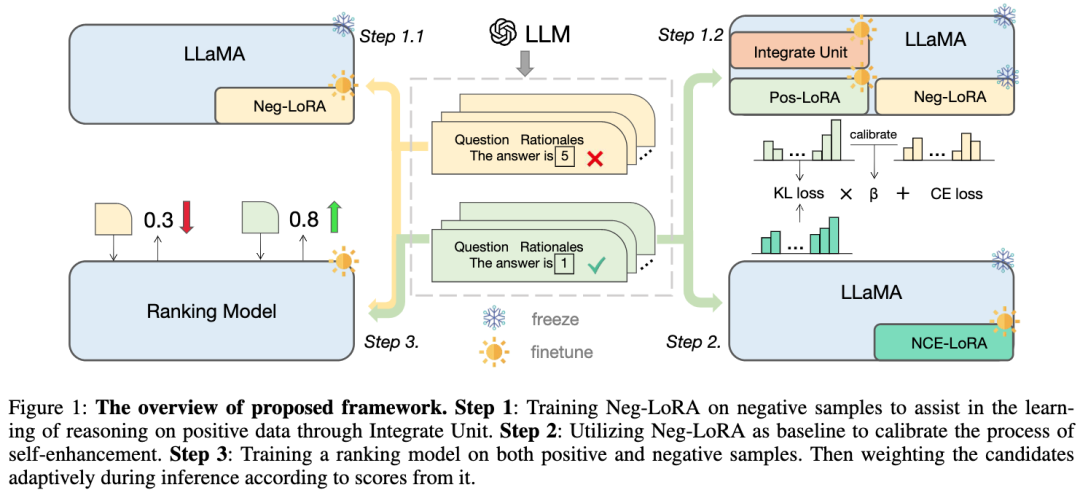
Kertas ini mencadangkan dan mengesahkan nilai sampel negatif dalam proses penyulingan model besar, dan membina rangka kerja pengkhususan model: selain menggunakan sampel positif, sampel negatif juga digunakan sepenuhnya untuk memperhalusi pengetahuan LLM. Rangka kerja tersebut merangkumi tiga langkah bersiri, termasuk Latihan Berbantu Negatif (NAT), Penentukuran Negatif (NCE), dan Ketekalan Diri Dinamik (ASC), merangkumi keseluruhan proses daripada latihan hingga inferens. Melalui siri eksperimen yang meluas, kami menunjukkan peranan kritikal data negatif dalam penyulingan pengetahuan LLM.
1. Latar Belakang
Di bawah situasi semasa, dipandu oleh Rantaian Pemikiran (CoT), model bahasa besar (LLM) telah menunjukkan keupayaan penaakulan yang kuat. Walau bagaimanapun, kami telah menunjukkan bahawa keupayaan muncul ini hanya boleh dicapai oleh model dengan ratusan bilion parameter. Memandangkan model ini memerlukan sumber pengkomputeran yang besar dan kos inferens yang tinggi, model ini sukar untuk digunakan di bawah kekangan sumber. Oleh itu, matlamat penyelidikan kami adalah untuk membangunkan model kecil yang mampu membuat penaakulan aritmetik yang kompleks untuk penggunaan berskala besar dalam aplikasi dunia sebenar.
Penyulingan pengetahuan menyediakan cara yang cekap untuk memindahkan keupayaan khusus LLM kepada model yang lebih kecil. Proses ini, juga dikenali sebagai pengkhususan model, memaksa model kecil untuk menumpukan pada keupayaan tertentu. Penyelidikan terdahulu menggunakan pembelajaran kontekstual (ICL) LLM untuk menjana laluan penaakulan bagi masalah matematik dan menggunakannya sebagai data latihan, yang membantu model kecil memperoleh keupayaan penaakulan yang kompleks. Walau bagaimanapun, kajian ini hanya menggunakan laluan inferens yang dijana dengan jawapan yang betul (iaitu, sampel positif) sebagai sampel latihan, mengabaikan pengetahuan berharga dalam langkah inferens dengan jawapan yang salah (iaitu, sampel negatif). Oleh itu, penyelidik mula meneroka cara menggunakan langkah inferens dalam sampel negatif untuk meningkatkan prestasi model kecil. Satu pendekatan ialah menggunakan latihan lawan, di mana model penjana diperkenalkan untuk menjana laluan inferens untuk jawapan yang salah, dan laluan ini kemudiannya digunakan bersama-sama dengan contoh positif untuk melatih model kecil. Dengan cara ini, model kecil boleh mempelajari pengetahuan yang berharga dalam langkah penaakulan ralat dan meningkatkan keupayaan penaakulannya. Pendekatan lain ialah menggunakan pembelajaran penyeliaan kendiri, dengan membandingkan jawapan yang betul dengan jawapan yang salah dan membiarkan model kecil belajar membezakan antara mereka dan mengekstrak maklumat berguna daripadanya. Kaedah ini boleh menyediakan latihan yang lebih komprehensif untuk model kecil, memberikan mereka keupayaan penaakulan yang lebih berkuasa. Ringkasnya, menggunakan langkah inferens dalam sampel negatif boleh membantu model kecil memperoleh latihan yang lebih komprehensif dan meningkatkan keupayaan inferens mereka.
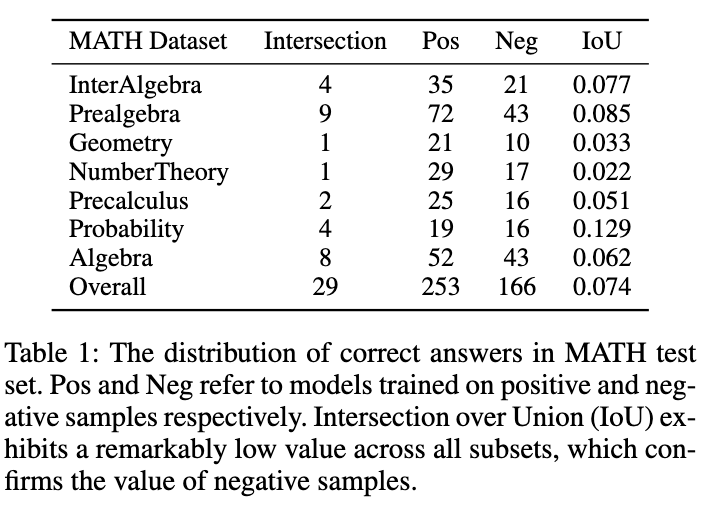 gambar
gambar
seperti ini ditunjukkan dalam rajah 1 menunjukkan fenomena menarik: model yang dilatih pada data sampel positif dan negatif masing-masing mempunyai pertindihan yang sangat kecil dalam jawapan yang tepat pada set ujian MATH. Walaupun model yang dilatih dengan sampel negatif kurang tepat, ia boleh menyelesaikan beberapa soalan yang model sampel positif tidak dapat menjawab dengan betul, yang mengesahkan bahawa sampel negatif mengandungi pengetahuan yang berharga. Selain itu, pautan yang salah dalam sampel negatif boleh membantu model mengelak daripada membuat kesilapan yang sama. Satu lagi sebab mengapa kita harus mengambil kesempatan daripada sampel negatif ialah strategi harga berasaskan token OpenAI. Malah ketepatan GPT-4 pada set data MATH adalah kurang daripada 50%, yang bermaksud bahawa sejumlah besar token akan dibazirkan jika hanya pengetahuan sampel positif digunakan. Oleh itu, kami mencadangkan bahawa daripada membuang sampel negatif secara langsung, cara yang lebih baik adalah dengan mengekstrak dan menggunakan pengetahuan berharga daripadanya untuk meningkatkan pengkhususan model kecil.
Proses pengkhususan model secara amnya boleh diringkaskan kepada tiga langkah:
1) Penyulingan Rantaian Pemikiran, menggunakan rantaian inferens yang dihasilkan oleh LLM untuk melatih model kecil.
2) Peningkatan Kendiri, lakukan penyulingan sendiri atau pengembangan diri data untuk mengoptimumkan lagi model.
3) Ketekalan Diri digunakan secara meluas sebagai strategi penyahkodan yang berkesan untuk meningkatkan prestasi model dalam tugasan inferens.
Dalam kerja ini, kami mencadangkan rangka kerja pengkhususan model baharu yang boleh menggunakan sepenuhnya sampel negatif dan memudahkan pengekstrakan keupayaan inferens kompleks daripada LLM.
- Kami mula-mula mereka bentuk kaedah Negative Assisted Training (NAT), di mana struktur dwi-LoRA direka untuk memperoleh pengetahuan dari aspek positif dan negatif. Sebagai modul tambahan, pengetahuan tentang LoRA negatif boleh disepadukan secara dinamik ke dalam proses latihan LoRA positif melalui mekanisme perhatian pembetulan.
- Untuk peningkatan diri, kami mereka bentuk Penentukuran Negatif (NCE), yang mengambil output negatif sebagai garis asas untuk meningkatkan penyulingan pautan penaakulan ke hadapan utama.
- Selain fasa latihan, kami juga menggunakan maklumat negatif semasa proses inferens. Kaedah ketekalan diri tradisional memberikan pemberat yang sama atau berasaskan kebarangkalian kepada semua keluaran calon, menyebabkan mengundi untuk beberapa jawapan yang tidak boleh dipercayai. Untuk mengurangkan masalah ini, kaedah ketekalan diri dinamik (ASC) dicadangkan untuk mengisih sebelum mengundi, di mana model pengisihan dilatih pada sampel positif dan negatif.
2. Kaedah
Rangka kerja yang kami cadangkan menggunakan LLaMA sebagai model asas dan terutamanya mengandungi tiga bahagian, seperti yang ditunjukkan dalam rajah:
-
Langkah 1: Melatih unit negatif pelajari pengetahuan inferens tentang sampel positif; Langkah 3: Model pemeringkatan dilatih mengenai sampel positif dan negatif, dan pautan inferens calon ditimbang secara adaptif mengikut markah mereka semasa inferens.
- Gambar2.1 Latihan Bantuan Negatif (NAT)
Kami mencadangkan dua peringkat Latihan Bantuan Negatif,T Unit penyepaduan dinamik - mempunyai dua bahagian: 2.1.1 Penyerapan pengetahuan negatif
 Dengan memaksimumkan jangkaan berikut pada data negatif
Dengan memaksimumkan jangkaan berikut pada data negatif
, pengetahuan tentang sampel negatif
, pengetahuan tentang sampel negatif . Semasa proses ini, parameter LLaMA kekal beku.
Pictures
2.1.2 Unit Bersepadu Dinamik
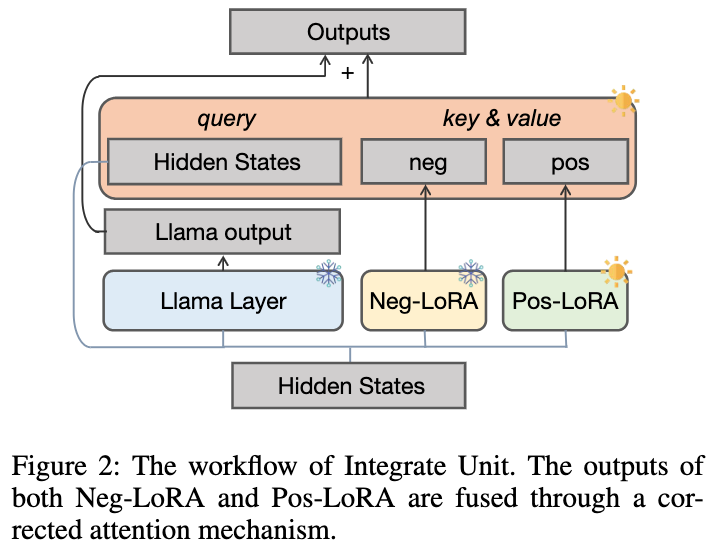
Since Tidak mustahil untuk menentukan terlebih dahulu masalah matematik θ
baik, kami merancang unit bersepadu dinamik seperti yang ditunjukkan dalam rajah di bawah untuk memudahkan Dalam proses pembelajaran pengetahuan sampel positif, pengetahuan daripada θ
disepadukan secara dinamik: 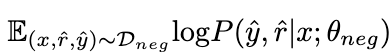
gambarKami membekukan θ
dilupakan, dan tambahan memperkenalkan modul LoRA positif θ . Sebaik-baiknya, kita harus menyepadukan modul LoRA positif dan negatif ke hadapan (output dalam setiap lapisan LLaMA diwakili sebagai dan ) untuk menambah pengetahuan berfaedah yang kurang dalam sampel positif tetapi sepadan dengan . Apabila θ
mengandungi pengetahuan yang berbahaya, kita harus melakukan penyepaduan negatif modul LoRA positif dan negatif untuk membantu mengurangkan kemungkinan tingkah laku buruk dalam sampel positif.
Kami mencadangkan mekanisme perhatian pembetulan untuk mencapai matlamat ini seperti berikut:
 Gambar
Gambar
Gambar
Kami menggunakan
sebagai pertanyaan untuk mengira berat perhatian dan . Dengan menambah istilah pembetulan [0.5; -0.5], berat perhatian adalah terhad kepada julat [-0.5, 0.5], dengan itu mencapai kesan menyepadukan pengetahuan secara adaptif dari arah positif dan negatif. Akhir sekali, jumlah
dan output lapisan LLaMA membentuk output unit penyepaduan dinamik.
2.2 Peningkatan Kalibrasi Negatif (NCE)
Untuk meningkatkan lagi keupayaan penaakulan model, kami mencadangkan Peningkatan Kalibrasi Negatif (NCE), yang menggunakan pengetahuan negatif untuk membantu proses peningkatan diri. Kami mula-mula menggunakan NAT untuk menjana pasangan sebagai sampel penambahan untuk setiap soalan dalam dan menambahnya ke dalam set data latihan. Untuk bahagian penyulingan sendiri, kami ambil perhatian bahawa sesetengah sampel mungkin mengandungi langkah inferens yang lebih kritikal, yang penting untuk meningkatkan keupayaan inferens model. Matlamat utama kami adalah untuk mengenal pasti langkah inferens kritikal ini dan meningkatkan pembelajaran mereka semasa penyulingan diri.
Memandangkan NAT sudah mengandungi pengetahuan berguna tentang θ
, faktor-faktor yang menjadikan NAT mempunyai keupayaan penaakulan yang lebih kuat daripada θ
adalah tersirat dalam kedua-dua pautan penaakulan yang tidak konsisten. Oleh itu, kami menggunakan perbezaan KL untuk mengukur ketidakkonsistenan ini dan memaksimumkan jangkaan formula ini:
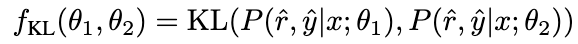 Pictures
Pictures
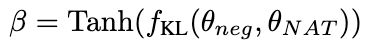 Pictures
Pictures
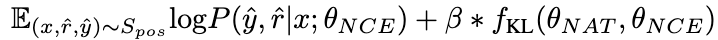
Pictures
Pictures
Pictures
Pictures
Semakin besar nilai β , semakin tinggi semakin besar perbezaan antara kedua-duanya, bermakna sampel mengandungi lebih banyak pengetahuan kritikal. Dengan memperkenalkan β untuk melaraskan berat kehilangan sampel yang berbeza, NCE akan dapat secara selektif mempelajari dan meningkatkan pengetahuan yang tertanam dalam NAT.
2.3 Ketekalan diri dinamik (ASC) 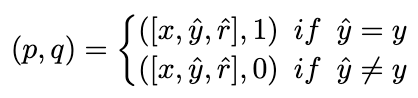
2.3.1 Latihan model pemeringkatan 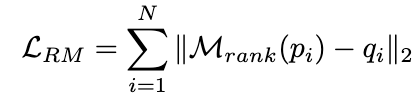
Sebaik-baiknya, kami mahu model pemeringkatan memberikan wajaran yang lebih tinggi kepada pautan inferens yang membawa kepada jawapan yang betul, dan sebaliknya. Oleh itu, kami membina sampel latihan dengan cara berikut:
gambardan menggunakan kehilangan MSE untuk melatih model kedudukan:
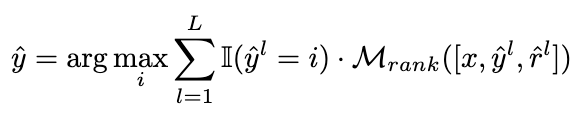
strategi penimbangan.

Kami mengubah suai strategi pengundian kepada formula berikut untuk mencapai matlamat menimbang semula secara adaptif pautan inferens calon:
Gambar
🎜Angka berikut menunjukkan aliran strategi ASC🜎🜎🜎🎜: 🎜🎜 🎜🎜Dari perspektif pemindahan pengetahuan, ASC melaksanakan penggunaan lanjut pengetahuan (positif dan negatif) daripada LLM untuk membantu model kecil mencapai prestasi yang lebih baik. 🎜🎜🎜3. Eksperimen🎜🎜🎜Kajian ini memfokuskan kepada set data penaakulan matematik yang mencabar, yang mempunyai sejumlah 12,500 soalan yang melibatkan tujuh subjek berbeza. Selain itu, kami memperkenalkan empat set data berikut untuk menilai keupayaan generalisasi rangka kerja yang dicadangkan kepada data luar pengedaran (OOD): GSM8K, ASDiv, MultiArith dan SVAMP. 🎜🎜Untuk model guru, kami menggunakan API gpt-3.5-turbo dan gpt-4 Open AI untuk menjana rantaian inferens. Untuk model pelajar, kami memilih LLaMA-7b.
Terdapat dua jenis garis dasar utama dalam penyelidikan kami: satu ialah model bahasa besar (LLM) dan satu lagi adalah berdasarkan LLaMA-7b. Untuk LLM, kami membandingkannya dengan dua model popular: GPT3 dan PaLM. Untuk LLaMA-7b, kami mula-mula membentangkan kaedah kami untuk perbandingan dengan tiga tetapan: Few-shot, Fine-tune (pada sampel latihan asal), CoT KD (Chain of Thought Distillation). Dari segi pembelajaran dari perspektif negatif, empat kaedah asas juga akan disertakan: MIX (latihan LLaMA secara langsung dengan campuran data positif dan negatif), CL (pembelajaran kontrastif), NT (latihan negatif) dan UL (kerugian bukan kemungkinan ) ).
3.1 Keputusan Eksperimen NAT
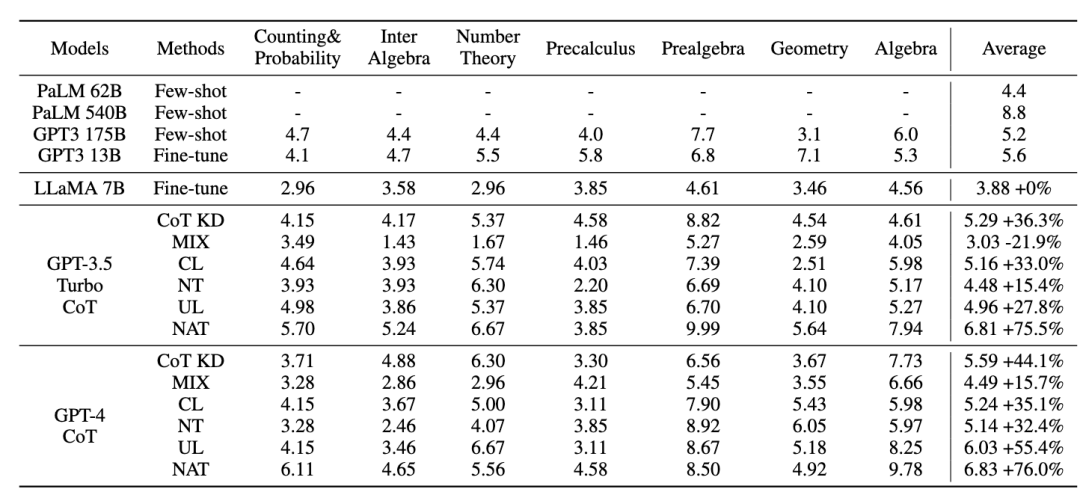
Semua kaedah menggunakan carian tamak (iaitu suhu = 0), dan keputusan percubaan NAT ditunjukkan dalam rajah, menunjukkan bahawa kaedah NAT yang dicadangkan meningkatkan tugasan pada semua ketepatan garis dasar.
Seperti yang dapat dilihat daripada nilai GPT3 dan PaLM yang rendah, MATH ialah set data matematik yang sangat sukar, tetapi NAT masih mampu berprestasi baik dengan parameter yang sangat sedikit. Berbanding dengan penalaan halus pada data mentah, NAT mencapai kira-kira 75.75% peningkatan di bawah dua sumber CoT berbeza. NAT juga meningkatkan ketepatan dengan ketara berbanding CoT KD pada sampel positif, menunjukkan nilai sampel negatif.
Untuk menggunakan garis dasar maklumat negatif, prestasi MIX yang rendah menunjukkan bahawa latihan sampel negatif secara langsung akan menjadikan model berprestasi buruk. Kaedah lain juga kebanyakannya lebih rendah daripada NAT, yang menunjukkan bahawa menggunakan hanya sampel negatif ke arah negatif tidak mencukupi dalam tugas penaakulan yang kompleks. . sampel Kesahan maklumat penentukuran yang disediakan untuk penyulingan. Berbanding dengan NAT, walaupun NCE mengurangkan beberapa parameter, ia masih mempunyai peningkatan 6.5%, mencapai tujuan memampatkan model dan meningkatkan prestasi. . Seperti yang ditunjukkan dalam rajah, keputusan menunjukkan bahawa ASC, yang mengagregatkan jawapan daripada sampel yang berbeza, adalah strategi yang lebih menjanjikan. .
 Gambar
Gambar
4. Kesimpulan
Kerja ini meneroka keberkesanan menggunakan sampel negatif untuk mengekstrak keupayaan penaakulan kompleks daripada model bahasa besar dan memindahkannya kepada model kecil khusus.Pasukan Algoritma Carian Xiaohongshu mencadangkan rangka kerja serba baharu, yang terdiri daripada tiga langkah bersiri, dan menggunakan sepenuhnya maklumat negatif sepanjang keseluruhan proses pengkhususan model. Latihan Berbantu Negatif (NAT)
boleh menyediakan cara yang lebih komprehensif untuk menggunakan maklumat negatif dari dua perspektif.Negative Calibration Enhancement (NCE)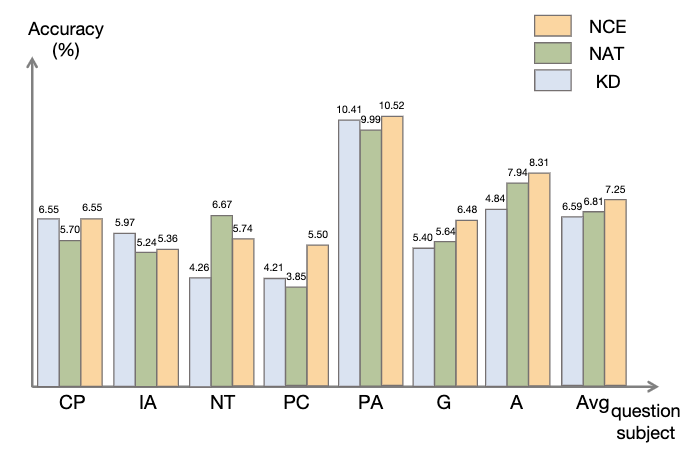 mampu menentukur proses penyulingan sendiri supaya ia dapat menguasai pengetahuan utama dengan cara yang lebih disasarkan. Model kedudukan yang dilatih pada kedua-dua sudut pandangan boleh menetapkan pemberat yang lebih sesuai untuk menjawab pengagregatan bagi mencapai ketekalan diri dinamik (ASC). Eksperimen yang meluas menunjukkan bahawa rangka kerja kami boleh meningkatkan keberkesanan memperhalusi keupayaan penaakulan melalui sampel negatif yang dihasilkan.
mampu menentukur proses penyulingan sendiri supaya ia dapat menguasai pengetahuan utama dengan cara yang lebih disasarkan. Model kedudukan yang dilatih pada kedua-dua sudut pandangan boleh menetapkan pemberat yang lebih sesuai untuk menjawab pengagregatan bagi mencapai ketekalan diri dinamik (ASC). Eksperimen yang meluas menunjukkan bahawa rangka kerja kami boleh meningkatkan keberkesanan memperhalusi keupayaan penaakulan melalui sampel negatif yang dihasilkan.
Alamat kertas:
https://www.php.cn/link/8fa2a95ee83cd1633cfd64f78e856bd3
5. Pengenalan kepada penulis
- Menerbitkan beberapa kertas kerja dalam persidangan/jurnal teratas dalam bidang pembelajaran mesin dan pemprosesan bahasa semula jadinya ialah penyulingan dan inferens model bahasa besar, penjanaan dialog domain terbuka, dsb. . DSTC11 Track 4 Tempat kedua. Arah kajian utama ialah inferens dan penilaian model bahasa yang besar.
Feng Shaoxiong: Bertanggungjawab untuk penarikan semula vektor carian komuniti Xiaohongshu. Menerbitkan beberapa kertas kerja dalam persidangan/jurnal teratas dalam bidang pembelajaran mesin dan pemprosesan bahasa semula jadi seperti AAAI, EMNLP, ACL, NAACL, KBS, dsb.
- Daoxuan (Pan Boyuan): Ketua carian transaksi Xiaohongshu. Beliau telah menerbitkan beberapa makalah pengarang pertama di persidangan teratas dalam bidang pembelajaran mesin dan pemprosesan bahasa semula jadi seperti NeurIPS, ICML, dan ACL, memenangi tempat kedua dalam ranking SKUAD Pertandingan Membaca Mesin Stanford, dan memenangi tempat pertama dalam Stanford Natural. Kedudukan Inferens Bahasa.
- Zeng Shushu (Zeng Shushu): Ketua pemahaman dan ingatan semantik carian dalam komuniti Xiaohongshu. Beliau berkelulusan ijazah sarjana dari Jabatan Elektronik Universiti Tsinghua dan telah terlibat dalam kerja algoritma dalam pemprosesan bahasa semula jadi, pengesyoran, carian dan bidang lain yang berkaitan dalam bidang Internet.
Atas ialah kandungan terperinci Pasukan carian Xiaohongshu mendedahkan: kepentingan mengesahkan sampel negatif dalam penyulingan model berskala besar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Saya cuba pengekodan getaran dengan kursor AI dan ia menakjubkan!
Mar 20, 2025 pm 03:34 PM
Saya cuba pengekodan getaran dengan kursor AI dan ia menakjubkan!
Mar 20, 2025 pm 03:34 PM
Pengekodan Vibe membentuk semula dunia pembangunan perisian dengan membiarkan kami membuat aplikasi menggunakan bahasa semulajadi dan bukannya kod yang tidak berkesudahan. Diilhamkan oleh penglihatan seperti Andrej Karpathy, pendekatan inovatif ini membolehkan Dev
 Top 5 Genai dilancarkan pada Februari 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
Top 5 Genai dilancarkan pada Februari 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
Februari 2025 telah menjadi satu lagi bulan yang berubah-ubah untuk AI generatif, membawa kita beberapa peningkatan model yang paling dinanti-nantikan dan ciri-ciri baru yang hebat. Dari Xai's Grok 3 dan Anthropic's Claude 3.7 Sonnet, ke Openai's G
 Bagaimana cara menggunakan Yolo V12 untuk pengesanan objek?
Mar 22, 2025 am 11:07 AM
Bagaimana cara menggunakan Yolo V12 untuk pengesanan objek?
Mar 22, 2025 am 11:07 AM
Yolo (anda hanya melihat sekali) telah menjadi kerangka pengesanan objek masa nyata yang terkemuka, dengan setiap lelaran bertambah baik pada versi sebelumnya. Versi terbaru Yolo V12 memperkenalkan kemajuan yang meningkatkan ketepatan
 Adakah chatgpt 4 o tersedia?
Mar 28, 2025 pm 05:29 PM
Adakah chatgpt 4 o tersedia?
Mar 28, 2025 pm 05:29 PM
CHATGPT 4 kini tersedia dan digunakan secara meluas, menunjukkan penambahbaikan yang ketara dalam memahami konteks dan menjana tindak balas yang koheren berbanding dengan pendahulunya seperti ChATGPT 3.5. Perkembangan masa depan mungkin merangkumi lebih banyak Inter yang diperibadikan
 Google ' s Gencast: Peramalan Cuaca dengan Demo Mini Gencast
Mar 16, 2025 pm 01:46 PM
Google ' s Gencast: Peramalan Cuaca dengan Demo Mini Gencast
Mar 16, 2025 pm 01:46 PM
Google Deepmind's Gencast: AI Revolusioner untuk Peramalan Cuaca Peramalan cuaca telah menjalani transformasi dramatik, bergerak dari pemerhatian asas kepada ramalan berkuasa AI yang canggih. Google Deepmind's Gencast, tanah air
 AI mana yang lebih baik daripada chatgpt?
Mar 18, 2025 pm 06:05 PM
AI mana yang lebih baik daripada chatgpt?
Mar 18, 2025 pm 06:05 PM
Artikel ini membincangkan model AI yang melampaui chatgpt, seperti Lamda, Llama, dan Grok, menonjolkan kelebihan mereka dalam ketepatan, pemahaman, dan kesan industri. (159 aksara)
 O1 vs GPT-4O: Adakah model baru OpenAI ' lebih baik daripada GPT-4O?
Mar 16, 2025 am 11:47 AM
O1 vs GPT-4O: Adakah model baru OpenAI ' lebih baik daripada GPT-4O?
Mar 16, 2025 am 11:47 AM
Openai's O1: Hadiah 12 Hari Bermula dengan model mereka yang paling berkuasa Ketibaan Disember membawa kelembapan global, kepingan salji di beberapa bahagian dunia, tetapi Openai baru sahaja bermula. Sam Altman dan pasukannya melancarkan mantan hadiah 12 hari
 Penjana Seni AI Terbaik (Percuma & amp; Dibayar) untuk projek kreatif
Apr 02, 2025 pm 06:10 PM
Penjana Seni AI Terbaik (Percuma & amp; Dibayar) untuk projek kreatif
Apr 02, 2025 pm 06:10 PM
Artikel ini mengkaji semula penjana seni AI atas, membincangkan ciri -ciri mereka, kesesuaian untuk projek kreatif, dan nilai. Ia menyerlahkan Midjourney sebagai nilai terbaik untuk profesional dan mengesyorkan Dall-E 2 untuk seni berkualiti tinggi dan disesuaikan.
