
 Peranti teknologi
AI
RoSA: Kaedah baharu untuk penalaan halus parameter model besar yang cekap
Peranti teknologi
AI
RoSA: Kaedah baharu untuk penalaan halus parameter model besar yang cekap
RoSA: Kaedah baharu untuk penalaan halus parameter model besar yang cekap

Memandangkan model bahasa berskala ke skala yang belum pernah berlaku sebelum ini, penalaan menyeluruh tugas hiliran menjadi mahal. Bagi menyelesaikan masalah ini, penyelidik mula memberi perhatian dan mengamalkan kaedah PEFT. Idea utama kaedah PEFT adalah untuk mengehadkan skop penalaan halus kepada set kecil parameter untuk mengurangkan kos pengiraan sambil masih mencapai prestasi terkini dalam tugas pemahaman bahasa semula jadi. Dengan cara ini, penyelidik boleh menjimatkan sumber pengkomputeran sambil mengekalkan prestasi tinggi, membawa tempat tumpuan penyelidikan baharu ke bidang pemprosesan bahasa semula jadi.
ROSA adalah teknik PEFT baru. -kaedah penalaan.
Artikel ini akan menyelidiki prinsip, kaedah dan keputusan RoSA, menerangkan cara prestasinya menandakan kemajuan yang bermakna. Bagi mereka yang ingin memperhalusi model bahasa besar dengan berkesan, RoSA menyediakan penyelesaian baharu yang lebih baik daripada penyelesaian sebelumnya.
Keperluan untuk penalaan halus yang cekap bagi parameter
NLP telah direvolusikan oleh model bahasa berasaskan pengubah seperti GPT-4. Model ini mempelajari perwakilan bahasa yang berkuasa dengan pra-latihan mengenai korpora teks besar. Mereka kemudiannya memindahkan perwakilan ini kepada tugas bahasa hiliran melalui proses yang mudah.
Apabila saiz model berkembang daripada berbilion kepada bertrilion parameter, penalaan halus membawa beban pengiraan yang besar. Sebagai contoh, untuk model seperti GPT-4 dengan 1.76 trilion parameter, penalaan halus boleh menelan belanja berjuta-juta dolar. Ini menjadikan penggunaan dalam aplikasi sebenar sangat tidak praktikal.
Kaedah PEFT meningkatkan kecekapan dan ketepatan dengan mengehadkan julat parameter penalaan halus. Baru-baru ini, pelbagai teknologi PEFT telah muncul yang menukar kecekapan dan ketepatan.
LoRA
Kaedah PEFT yang terkenal ialah penyesuaian peringkat rendah (LoRA). LoRA telah dilancarkan pada 2021 oleh penyelidik dari Meta dan MIT. Pendekatan ini didorong oleh pemerhatian mereka bahawa pengubah mempamerkan struktur peringkat rendah dalam matriks kepalanya. LoRA dicadangkan untuk memanfaatkan struktur peringkat rendah ini untuk mengurangkan kerumitan pengiraan dan meningkatkan kecekapan dan kelajuan model.
LoRA hanya memperhalusi vektor k tunggal pertama, manakala parameter lain kekal tidak berubah. Ini hanya memerlukan O(k) parameter tambahan untuk ditala, bukannya O(n).
Dengan memanfaatkan struktur peringkat rendah ini, LoRA boleh menangkap isyarat bermakna yang diperlukan untuk generalisasi tugas hiliran dan mengehadkan penalaan halus kepada vektor tunggal teratas ini, menjadikan pengoptimuman dan inferens lebih cekap.
Percubaan menunjukkan bahawa LoRA boleh memadankan prestasi diperhalusi sepenuhnya pada penanda aras GLUE sambil menggunakan lebih daripada 100 kali lebih sedikit parameter. Walau bagaimanapun, apabila saiz model terus berkembang, mendapatkan prestasi yang kukuh melalui LoRA memerlukan peningkatan pangkat k, mengurangkan penjimatan pengiraan berbanding dengan penalaan halus sepenuhnya.
Sebelum RoSA, LoRA mewakili kaedah PEFT yang terkini, dengan hanya penambahbaikan sederhana menggunakan teknik seperti pemfaktoran matriks yang berbeza atau menambah sebilangan kecil parameter penalaan halus tambahan.
Penyesuaian Teguh (RoSA)
Penyesuaian Teguh (RoSA) memperkenalkan kaedah penalaan halus yang cekap parameter baharu. RoSA diilhamkan oleh analisis komponen utama yang teguh (PCA teguh), dan bukannya bergantung semata-mata pada struktur peringkat rendah.
Dalam analisis komponen utama tradisional, matriks data PCA yang teguh melangkah lebih jauh dan menguraikan X menjadi L peringkat rendah yang bersih dan S jarang "tercemar/korup".
RoSA mengambil inspirasi daripada ini dan menguraikan penalaan halus model bahasa menjadi:
Matriks penyesuaian (L) peringkat rendah seperti LoRA, diperhalusi untuk menghampiri isyarat berkaitan tugas yang dominan
Ketinggian Matriks penalaan halus (S) yang jarang mengandungi sebilangan kecil parameter yang ditala halus secara terpilih yang mengekodkan isyarat sisa yang terlepas oleh L.
Memodelkan komponen jarang sisa secara eksplisit membolehkan RoSA mencapai ketepatan yang lebih tinggi daripada LoRA sahaja.
RoSA membina L dengan melakukan penguraian peringkat rendah matriks kepala model. Ini akan mengekodkan perwakilan semantik asas yang berguna untuk tugas hiliran. RoSA kemudiannya memperhalusi secara selektif m parameter paling penting atas setiap lapisan kepada S, manakala semua parameter lain kekal tidak berubah. Langkah ini menangkap isyarat sisa yang tidak sesuai untuk pemasangan peringkat rendah.
Bilangan parameter penalaan halus m ialah susunan magnitud yang lebih kecil daripada pangkat k yang diperlukan oleh LoRA sahaja. Oleh itu, digabungkan dengan matriks kepala peringkat rendah dalam L, RoSA mengekalkan kecekapan parameter yang sangat tinggi.
RoSA juga menggunakan beberapa pengoptimuman lain yang mudah tetapi berkesan:
Sisa sambungan jarang: Sisa S ditambah terus ke output setiap blok pengubah sebelum ia melalui penormalan lapisan dan sublapisan suapan. Ini boleh mensimulasikan isyarat yang terlepas oleh L.
Topeng jarang bebas: Metrik yang dipilih dalam S untuk penalaan halus dijana secara bebas untuk setiap lapisan pengubah.
Struktur peringkat rendah yang dikongsi: Matriks U,V asas peringkat rendah yang sama dikongsi antara semua lapisan L, sama seperti dalam LoRA. Ini akan menangkap konsep semantik dalam subruang yang konsisten.
Pilihan seni bina ini menyediakan pemodelan RoSA dengan fleksibiliti serupa dengan penalaan halus penuh, sambil mengekalkan kecekapan parameter untuk pengoptimuman dan inferens. Menggunakan kaedah PEFT ini yang menggabungkan penyesuaian peringkat rendah yang teguh dan sisa yang sangat jarang, RoSA mencapai teknologi baharu bagi pertukaran kecekapan ketepatan. . Mereka menjalankan eksperimen menggunakan RoSA berdasarkan pembantu kecerdasan buatan LLM, menggunakan model parameter 12 bilion.
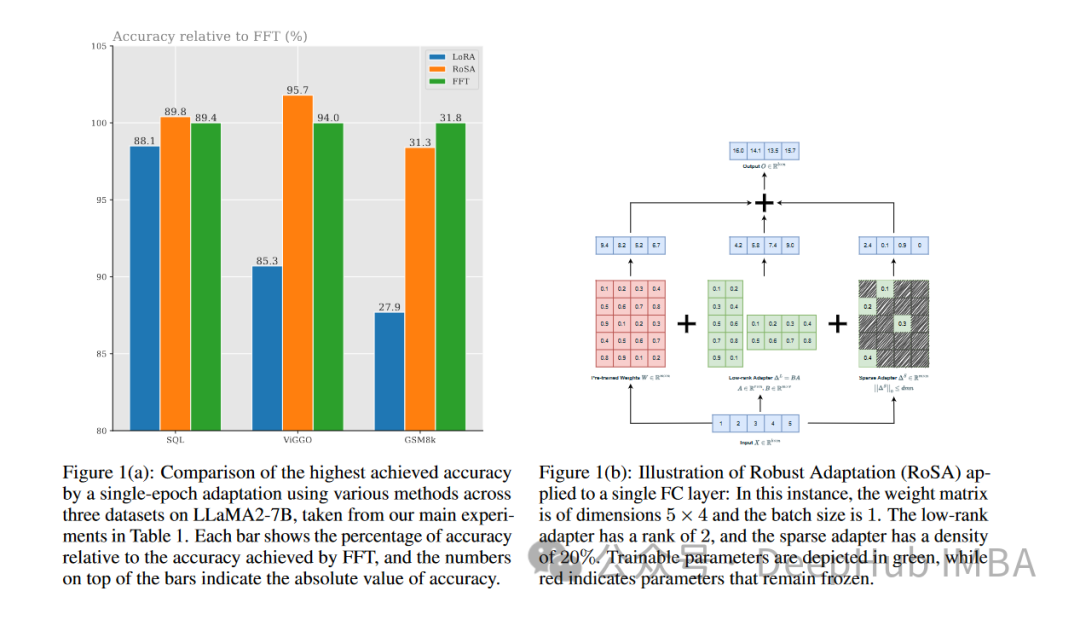
Pada setiap tugasan, RoSA menunjukkan prestasi yang lebih baik daripada LoRA apabila menggunakan parameter yang sama. Jumlah parameter kedua-dua kaedah adalah lebih kurang 0.3% daripada keseluruhan model. Ini bermakna terdapat kira-kira 4.5 juta parameter penalaan halus dalam kedua-dua kes untuk k = 16 untuk LoRA dan m = 5120 untuk RoSA.
RoSA juga sepadan atau melebihi prestasi garis dasar yang ditala halus tulen.
Pada penanda aras ANLI yang menilai keteguhan kepada contoh lawan, RoSA mendapat markah 55.6, manakala LoRA mendapat markah 52.7. Ini menunjukkan peningkatan dalam generalisasi dan penentukuran. 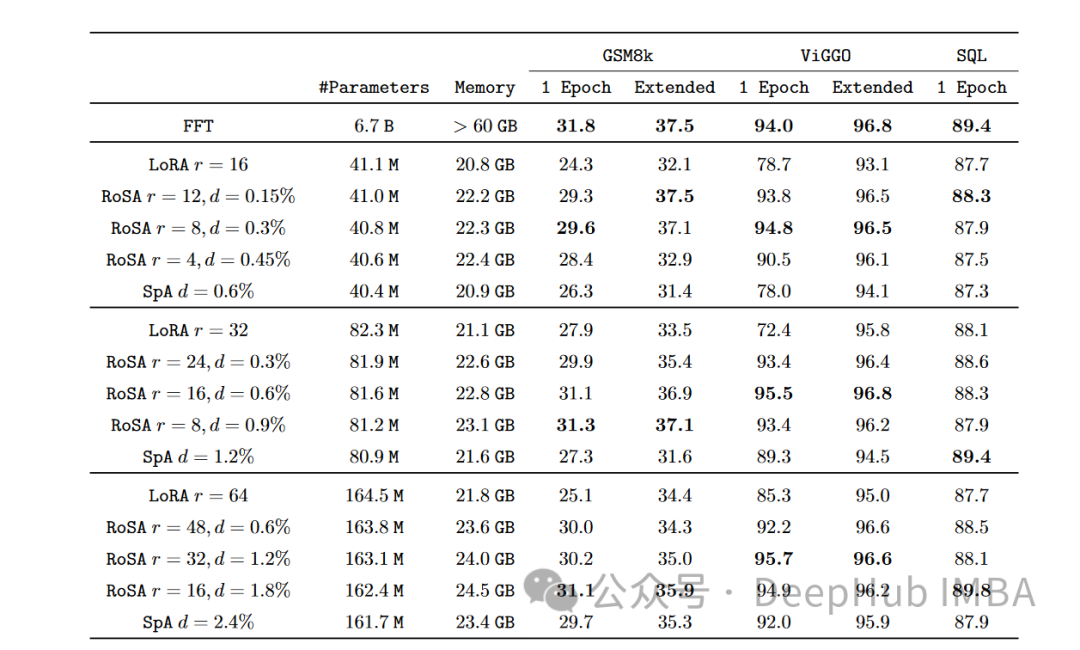
Untuk tugasan analisis sentimen SST-2 dan IMDB, ketepatan RoSA mencapai 91.2% dan 96.9%, manakala ketepatan LoRA mencapai 90.1% dan 95.3%.
Pada WIC, ujian nyahkekaburan deria perkataan yang mencabar, RoSA mencapai skor F1 93.5, manakala LoRA mencapai skor F1 91.7.
Di seluruh 12 set data, RoSA umumnya menunjukkan prestasi yang lebih baik daripada LoRA di bawah belanjawan parameter yang sepadan.
Terutamanya, RoSA mampu mencapai keuntungan ini tanpa memerlukan sebarang penalaan atau pengkhususan khusus. Ini menjadikan RoSA sesuai digunakan sebagai penyelesaian PEFT universal.
Ringkasan
Memandangkan skala model bahasa terus berkembang pesat, mengurangkan keperluan pengiraan untuk memperhalusinya merupakan masalah mendesak yang perlu diselesaikan. Teknik latihan penyesuaian yang cekap parameter seperti LoRA telah menunjukkan kejayaan awal tetapi menghadapi batasan yang wujud dalam anggaran peringkat rendah.
RoSA secara organik menggabungkan penguraian peringkat rendah yang teguh dan sisa penalaan halus yang sangat jarang untuk memberikan penyelesaian baharu yang meyakinkan. Ia sangat meningkatkan prestasi PEFT dengan mempertimbangkan isyarat yang terlepas daripada pemasangan peringkat rendah melalui sisa-sisa jarang terpilih. Penilaian empirikal menunjukkan peningkatan ketara ke atas LoRA dan garis dasar sparsity yang tidak terkawal pada set tugas NLU yang berbeza.
RoSA secara konsep mudah tetapi berprestasi tinggi, dan boleh memajukan lagi persimpangan kecekapan parameter, perwakilan penyesuaian dan pembelajaran berterusan untuk mengembangkan kecerdasan bahasa.
Atas ialah kandungan terperinci RoSA: Kaedah baharu untuk penalaan halus parameter model besar yang cekap. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Mengapakah model bahasa besar menggunakan SwiGLU sebagai fungsi pengaktifan?
Apr 08, 2024 pm 09:31 PM
Mengapakah model bahasa besar menggunakan SwiGLU sebagai fungsi pengaktifan?
Apr 08, 2024 pm 09:31 PM
Jika anda telah memberi perhatian kepada seni bina model bahasa yang besar, anda mungkin pernah melihat istilah "SwiGLU" dalam model dan kertas penyelidikan terkini. SwiGLU boleh dikatakan sebagai fungsi pengaktifan yang paling biasa digunakan dalam model bahasa besar Kami akan memperkenalkannya secara terperinci dalam artikel ini. SwiGLU sebenarnya adalah fungsi pengaktifan yang dicadangkan oleh Google pada tahun 2020, yang menggabungkan ciri-ciri SWISH dan GLU. Nama penuh Cina SwiGLU ialah "unit linear berpagar dua arah". Ia mengoptimumkan dan menggabungkan dua fungsi pengaktifan, SWISH dan GLU, untuk meningkatkan keupayaan ekspresi tak linear model. SWISH ialah fungsi pengaktifan yang sangat biasa yang digunakan secara meluas dalam model bahasa besar, manakala GLU telah menunjukkan prestasi yang baik dalam tugas pemprosesan bahasa semula jadi.
 Fahami Tokenisasi dalam satu artikel!
Apr 12, 2024 pm 02:31 PM
Fahami Tokenisasi dalam satu artikel!
Apr 12, 2024 pm 02:31 PM
Model bahasa menaakul tentang teks, yang biasanya dalam bentuk rentetan, tetapi input kepada model hanya boleh menjadi nombor, jadi teks perlu ditukar kepada bentuk berangka. Tokenisasi ialah tugas asas pemprosesan bahasa semula jadi Mengikut keperluan khusus, urutan teks berterusan (seperti ayat, perenggan, dll.) boleh dibahagikan kepada urutan aksara (seperti perkataan, frasa, aksara, tanda baca, dsb. berbilang. unit), di mana unit Dipanggil token atau perkataan. Mengikut proses khusus yang ditunjukkan dalam rajah di bawah, ayat teks mula-mula dibahagikan kepada unit, kemudian elemen tunggal didigitalkan (dipetakan ke dalam vektor), kemudian vektor ini dimasukkan ke dalam model untuk pengekodan, dan akhirnya output ke tugas hiliran untuk seterusnya memperoleh keputusan akhir. Pembahagian teks boleh dibahagikan kepada Toke mengikut butiran pembahagian teks.
 Bolehkah penalaan halus benar-benar membolehkan LLM mempelajari perkara baharu: memperkenalkan pengetahuan baharu boleh menjadikan model menghasilkan lebih banyak halusinasi
Jun 11, 2024 pm 03:57 PM
Bolehkah penalaan halus benar-benar membolehkan LLM mempelajari perkara baharu: memperkenalkan pengetahuan baharu boleh menjadikan model menghasilkan lebih banyak halusinasi
Jun 11, 2024 pm 03:57 PM
Model Bahasa Besar (LLM) dilatih pada pangkalan data teks yang besar, di mana mereka memperoleh sejumlah besar pengetahuan dunia sebenar. Pengetahuan ini dibenamkan ke dalam parameter mereka dan kemudiannya boleh digunakan apabila diperlukan. Pengetahuan tentang model ini "diperbaharui" pada akhir latihan. Pada akhir pra-latihan, model sebenarnya berhenti belajar. Selaraskan atau perhalusi model untuk mempelajari cara memanfaatkan pengetahuan ini dan bertindak balas dengan lebih semula jadi kepada soalan pengguna. Tetapi kadangkala pengetahuan model tidak mencukupi, dan walaupun model boleh mengakses kandungan luaran melalui RAG, ia dianggap berfaedah untuk menyesuaikan model kepada domain baharu melalui penalaan halus. Penalaan halus ini dilakukan menggunakan input daripada anotasi manusia atau ciptaan LLM lain, di mana model menemui pengetahuan dunia sebenar tambahan dan menyepadukannya
 Visualisasikan ruang vektor FAISS dan laraskan parameter RAG untuk meningkatkan ketepatan hasil
Mar 01, 2024 pm 09:16 PM
Visualisasikan ruang vektor FAISS dan laraskan parameter RAG untuk meningkatkan ketepatan hasil
Mar 01, 2024 pm 09:16 PM
Memandangkan prestasi model bahasa berskala besar sumber terbuka terus bertambah baik, prestasi dalam penulisan dan analisis kod, pengesyoran, ringkasan teks dan pasangan menjawab soalan (QA) semuanya bertambah baik. Tetapi apabila ia berkaitan dengan QA, LLM sering gagal dalam isu yang berkaitan dengan data yang tidak terlatih, dan banyak dokumen dalaman disimpan dalam syarikat untuk memastikan pematuhan, rahsia perdagangan atau privasi. Apabila dokumen ini disoal, LLM boleh berhalusinasi dan menghasilkan kandungan yang tidak relevan, rekaan atau tidak konsisten. Satu teknik yang mungkin untuk menangani cabaran ini ialah Retrieval Augmented Generation (RAG). Ia melibatkan proses meningkatkan respons dengan merujuk pangkalan pengetahuan berwibawa di luar sumber data latihan untuk meningkatkan kualiti dan ketepatan penjanaan. Sistem RAG termasuk sistem mendapatkan semula untuk mendapatkan serpihan dokumen yang berkaitan daripada korpus
 Pengoptimuman LLM menggunakan teknologi SPIN untuk latihan penalaan halus permainan sendiri
Jan 25, 2024 pm 12:21 PM
Pengoptimuman LLM menggunakan teknologi SPIN untuk latihan penalaan halus permainan sendiri
Jan 25, 2024 pm 12:21 PM
2024 ialah tahun pembangunan pesat untuk model bahasa besar (LLM). Dalam latihan LLM, kaedah penjajaran ialah cara teknikal yang penting, termasuk penyeliaan penalaan halus (SFT) dan pembelajaran pengukuhan dengan maklum balas manusia (RLHF) yang bergantung pada pilihan manusia. Kaedah ini telah memainkan peranan penting dalam pembangunan LLM, tetapi kaedah penjajaran memerlukan sejumlah besar data beranotasi secara manual. Menghadapi cabaran ini, penalaan halus telah menjadi bidang penyelidikan yang rancak, dengan para penyelidik giat berusaha untuk membangunkan kaedah yang boleh mengeksploitasi data manusia dengan berkesan. Oleh itu, pembangunan kaedah penjajaran akan menggalakkan lagi kejayaan dalam teknologi LLM. Universiti California baru-baru ini menjalankan kajian yang memperkenalkan teknologi baharu yang dipanggil SPIN (SelfPlayfInetuNing). S
 Menggunakan graf pengetahuan untuk meningkatkan keupayaan model RAG dan mengurangkan tanggapan palsu model besar
Jan 14, 2024 pm 06:30 PM
Menggunakan graf pengetahuan untuk meningkatkan keupayaan model RAG dan mengurangkan tanggapan palsu model besar
Jan 14, 2024 pm 06:30 PM
Halusinasi adalah masalah biasa apabila bekerja dengan model bahasa besar (LLM). Walaupun LLM boleh menjana teks yang lancar dan koheren, maklumat yang dijananya selalunya tidak tepat atau tidak konsisten. Untuk mengelakkan LLM daripada halusinasi, sumber pengetahuan luaran, seperti pangkalan data atau graf pengetahuan, boleh digunakan untuk memberikan maklumat fakta. Dengan cara ini, LLM boleh bergantung pada sumber data yang boleh dipercayai ini, menghasilkan kandungan teks yang lebih tepat dan boleh dipercayai. Pangkalan Data Vektor dan Graf Pengetahuan Pangkalan Data Vektor Pangkalan data vektor ialah satu set vektor berdimensi tinggi yang mewakili entiti atau konsep. Ia boleh digunakan untuk mengukur persamaan atau korelasi antara entiti atau konsep yang berbeza, dikira melalui perwakilan vektornya. Pangkalan data vektor boleh memberitahu anda, berdasarkan jarak vektor, bahawa "Paris" dan "Perancis" lebih dekat daripada "Paris" dan
 Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) set data memainkan peranan penting dalam mempromosikan penyelidikan pemprosesan bahasa semula jadi (NLP). Set data QA berkualiti tinggi bukan sahaja boleh digunakan untuk memperhalusi model, tetapi juga menilai dengan berkesan keupayaan model bahasa besar (LLM), terutamanya keupayaan untuk memahami dan menaakul tentang pengetahuan saintifik. Walaupun pada masa ini terdapat banyak set data QA saintifik yang meliputi bidang perubatan, kimia, biologi dan bidang lain, set data ini masih mempunyai beberapa kekurangan. Pertama, borang data adalah agak mudah, kebanyakannya adalah soalan aneka pilihan. Ia mudah dinilai, tetapi mengehadkan julat pemilihan jawapan model dan tidak dapat menguji sepenuhnya keupayaan model untuk menjawab soalan saintifik. Sebaliknya, Soal Jawab terbuka
 Tiga rahsia untuk menggunakan model besar dalam awan
Apr 24, 2024 pm 03:00 PM
Tiga rahsia untuk menggunakan model besar dalam awan
Apr 24, 2024 pm 03:00 PM
Kompilasi|Dihasilkan oleh Xingxuan|51CTO Technology Stack (WeChat ID: blog51cto) Dalam dua tahun lalu, saya lebih terlibat dalam projek AI generatif menggunakan model bahasa besar (LLM) berbanding sistem tradisional. Saya mula merindui pengkomputeran awan tanpa pelayan. Aplikasi mereka terdiri daripada meningkatkan AI perbualan kepada menyediakan penyelesaian analitik yang kompleks untuk pelbagai industri, dan banyak lagi keupayaan lain. Banyak perusahaan menggunakan model ini pada platform awan kerana penyedia awan awam sudah menyediakan ekosistem siap sedia dan ia merupakan laluan yang paling tidak mempunyai rintangan. Walau bagaimanapun, ia tidak murah. Awan juga menawarkan faedah lain seperti kebolehskalaan, kecekapan dan keupayaan pengkomputeran lanjutan (GPU tersedia atas permintaan). Terdapat beberapa aspek yang kurang diketahui untuk menggunakan LLM pada platform awan awam
