

Pangkalan data akan menggunakan beberapa kaedah untuk menyimpan, membaca dan mengubah suai data Dalam pengurusan pangkalan data sebenar, pangkalan data akan menggunakan kedua-dua B-tree dan B+tree untuk menyimpan data. Antaranya, B-tree digunakan untuk pengindeksan, dan B+tree digunakan untuk menyimpan rekod sebenar. Artikel ini memperkenalkan mekanisme pengindeksan B-tree dalam pangkalan data.
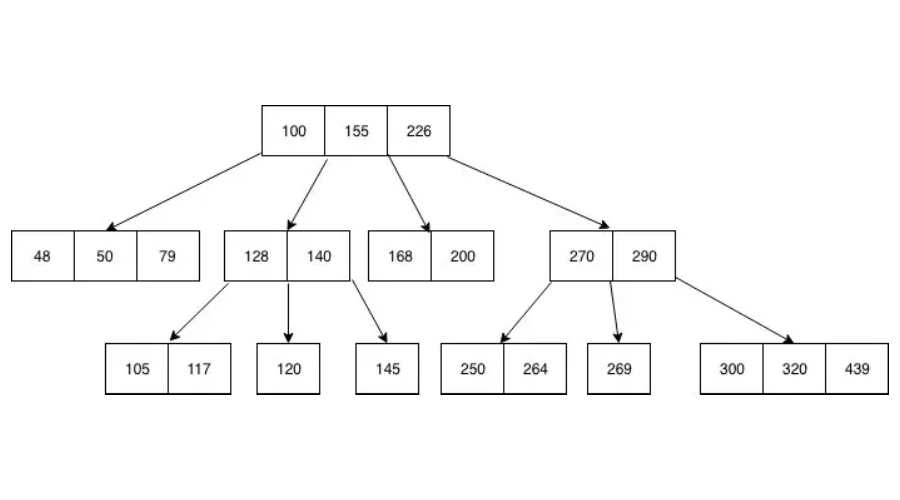
B-tree ialah B-tree Ia adalah struktur data dan jenis indeks MySQL, yang menyimpan data dalam bentuk nod yang disusun dalam susunan tertentu.
Cara B-tree menyimpan data ialah setiap nod menyimpan kunci dalam tertib menaik, dan setiap kunci mengandungi 2 pautan ke nod sebelum dan selepasnya. Kunci nod kiri adalah kurang daripada atau sama dengan kunci nod semasa, dan kunci nod kanan lebih besar daripada atau sama dengan kunci nod semasa. Jika nod mempunyai n kekunci, maka ia mempunyai paling banyak n+1 nod anak.
Indeks B-tree mempercepatkan pertanyaan data Enjin storan tidak perlu melintasi seluruh jadual untuk mencari data, ia akan bermula dari nod akar. Lokasi nod akar tidak mengandungi penunjuk ke nod kanak-kanak; ia mencari penunjuk yang betul dengan melihat nilai dalam nod kanak-kanak dan dengan menentukan sempadan atas dan bawah nod, menjadikannya lebih mudah bagi enjin storan untuk mencari data.
Perlu diambil perhatian bahawa susunan indeks akan bergantung pada susunan lajur semasa proses penciptaan jadual Apabila nilai bertindih, nilai seterusnya akan digunakan sebagai standard pengisihan. Oleh itu, susunan lajur dalam indeks adalah sangat penting Untuk prestasi terbaik, anda perlu membuat indeks dalam susunan yang berbeza untuk lajur yang sama.
B-tree bukan sahaja menyimpan indeks, tetapi juga nilai yang dikaitkan dengan indeks itu, yang dikaitkan dengan rekod data sebenar dalam pangkalan data.
Atas ialah kandungan terperinci Prinsip pelaksanaan indeks dalam pangkalan data: indeks B-tree. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Perbezaan antara nohup dan &
Perbezaan antara nohup dan &
 Mengapa saya tidak boleh mengakses penyemak imbas Ethereum?
Mengapa saya tidak boleh mengakses penyemak imbas Ethereum?
 Apakah maksud pycharm apabila berjalan secara selari?
Apakah maksud pycharm apabila berjalan secara selari?
 Cara menggunakan fungsi bulan
Cara menggunakan fungsi bulan
 Tiada perkhidmatan pada data mudah alih
Tiada perkhidmatan pada data mudah alih
 Bagaimana untuk mengalih keluar kunci keselamatan Firefox
Bagaimana untuk mengalih keluar kunci keselamatan Firefox
 Bagaimana untuk menyemak penggunaan memori jvm
Bagaimana untuk menyemak penggunaan memori jvm
 Penjelasan terperinci tentang arahan linux dd
Penjelasan terperinci tentang arahan linux dd








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



