

Struktur rangkaian yang cekap: EfficientNet


EfficientNet ialah struktur rangkaian saraf konvolusi yang cekap dan berskala dengan penskalaan model automatik. Idea teras adalah untuk meningkatkan prestasi model dengan meningkatkan kedalaman, lebar dan resolusi rangkaian berdasarkan struktur rangkaian asas yang cekap. Berbanding dengan proses membosankan melaraskan struktur rangkaian secara manual, kaedah ini bukan sahaja meningkatkan kecekapan dan ketepatan model, tetapi juga mengelakkan kerja yang tidak perlu. Melalui kaedah penskalaan model automatik, EfficientNet boleh melaraskan saiz rangkaian secara automatik mengikut keperluan tugas, supaya model boleh mencapai hasil yang lebih baik dalam senario yang berbeza. Ini menjadikan EfficientNet struktur rangkaian saraf yang sangat praktikal yang boleh digunakan secara meluas dalam pelbagai tugas dalam bidang penglihatan komputer.
Struktur model EfficientNet adalah berdasarkan tiga komponen utama: kedalaman, lebar dan resolusi. Kedalaman merujuk kepada bilangan lapisan dalam rangkaian, manakala lebar merujuk kepada bilangan saluran dalam setiap lapisan. Resolusi merujuk kepada saiz imej input. Dengan mengimbangi ketiga-tiga komponen ini, kita dapat memperoleh model yang cekap dan tepat.
EfficientNet menggunakan blok lilitan ringan, dipanggil blok MBConv, sebagai struktur rangkaian asasnya. Blok MBConv terdiri daripada tiga bahagian: lilitan 1x1, lilitan boleh pisah dalam berskala dan lilitan 1x1. Konvolusi 1x1 digunakan terutamanya untuk melaraskan bilangan saluran, manakala lilitan boleh dipisahkan dalam digunakan untuk mengurangkan jumlah pengiraan dan bilangan parameter. Dengan menyusun berbilang blok MBConv, struktur rangkaian asas yang cekap boleh dibina. Reka bentuk ini membolehkan EfficientNet mempunyai saiz model yang lebih kecil dan kerumitan pengiraan sambil mengekalkan prestasi tinggi.
Dalam EfficientNet, kaedah penskalaan model boleh dibahagikan kepada dua langkah utama. Pertama, struktur rangkaian asas diperbaiki dengan meningkatkan kedalaman, lebar dan resolusi rangkaian. Kedua, ketiga-tiga komponen tersebut diseimbangkan dengan menggunakan faktor penskalaan komposit. Faktor penskalaan komposit ini termasuk faktor penskalaan kedalaman, faktor penskalaan lebar dan faktor penskalaan resolusi. Faktor penskalaan ini digabungkan melalui fungsi komposit untuk mendapatkan faktor penskalaan akhir, yang digunakan untuk melaraskan struktur model. Dengan cara ini, EfficientNet boleh meningkatkan kecekapan dan ketepatan model sambil mengekalkan prestasi model.
Model EfficientNet boleh dinyatakan sebagai EfficientNetB{N} mengikut saiznya, di mana N ialah integer yang digunakan untuk mewakili skala model. Terdapat korelasi positif antara saiz model dan prestasi, iaitu lebih besar model, lebih baik prestasinya. Walau bagaimanapun, apabila saiz model meningkat, kos pengiraan dan penyimpanan juga meningkat dengan sewajarnya. Pada masa ini, EfficientNet menyediakan tujuh model dengan saiz yang berbeza dari B0 hingga B7 Pengguna boleh memilih saiz model yang sesuai mengikut keperluan tugas tertentu.
Selain struktur rangkaian asas, EfficientNet juga menggunakan beberapa teknologi lain untuk meningkatkan prestasi model. Yang paling penting ialah fungsi pengaktifan Swish, yang mempunyai prestasi yang lebih baik daripada fungsi pengaktifan ReLU yang biasa digunakan. Di samping itu, EfficientNet juga menggunakan teknologi DropConnect untuk mengelakkan overfitting dan teknologi standardisasi untuk meningkatkan kestabilan model.
Atas ialah kandungan terperinci Struktur rangkaian yang cekap: EfficientNet. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Terokai konsep, perbezaan, kebaikan dan keburukan RNN, LSTM dan GRU
Jan 22, 2024 pm 07:51 PM
Terokai konsep, perbezaan, kebaikan dan keburukan RNN, LSTM dan GRU
Jan 22, 2024 pm 07:51 PM
Dalam data siri masa, terdapat kebergantungan antara pemerhatian, jadi ia tidak bebas antara satu sama lain. Walau bagaimanapun, rangkaian saraf tradisional menganggap setiap pemerhatian sebagai bebas, yang mengehadkan keupayaan model untuk memodelkan data siri masa. Untuk menyelesaikan masalah ini, Rangkaian Neural Berulang (RNN) telah diperkenalkan, yang memperkenalkan konsep ingatan untuk menangkap ciri dinamik data siri masa dengan mewujudkan kebergantungan antara titik data dalam rangkaian. Melalui sambungan berulang, RNN boleh menghantar maklumat sebelumnya ke dalam pemerhatian semasa untuk meramalkan nilai masa hadapan dengan lebih baik. Ini menjadikan RNN alat yang berkuasa untuk tugasan yang melibatkan data siri masa. Tetapi bagaimanakah RNN mencapai ingatan seperti ini? RNN merealisasikan ingatan melalui gelung maklum balas dalam rangkaian saraf Ini adalah perbezaan antara RNN dan rangkaian saraf tradisional.
 Mengira operan titik terapung (FLOPS) untuk rangkaian saraf
Jan 22, 2024 pm 07:21 PM
Mengira operan titik terapung (FLOPS) untuk rangkaian saraf
Jan 22, 2024 pm 07:21 PM
FLOPS ialah salah satu piawaian untuk penilaian prestasi komputer, digunakan untuk mengukur bilangan operasi titik terapung sesaat. Dalam rangkaian saraf, FLOPS sering digunakan untuk menilai kerumitan pengiraan model dan penggunaan sumber pengkomputeran. Ia adalah penunjuk penting yang digunakan untuk mengukur kuasa pengkomputeran dan kecekapan komputer. Rangkaian saraf ialah model kompleks yang terdiri daripada berbilang lapisan neuron yang digunakan untuk tugas seperti klasifikasi data, regresi dan pengelompokan. Latihan dan inferens rangkaian saraf memerlukan sejumlah besar pendaraban matriks, konvolusi dan operasi pengiraan lain, jadi kerumitan pengiraan adalah sangat tinggi. FLOPS (FloatingPointOperationsperSecond) boleh digunakan untuk mengukur kerumitan pengiraan rangkaian saraf untuk menilai kecekapan penggunaan sumber pengiraan model. FLOP
 Definisi dan analisis struktur rangkaian neural kabur
Jan 22, 2024 pm 09:09 PM
Definisi dan analisis struktur rangkaian neural kabur
Jan 22, 2024 pm 09:09 PM
Rangkaian saraf kabur ialah model hibrid yang menggabungkan logik kabur dan rangkaian saraf untuk menyelesaikan masalah kabur atau tidak pasti yang sukar dikendalikan dengan rangkaian saraf tradisional. Reka bentuknya diilhamkan oleh kekaburan dan ketidakpastian dalam kognisi manusia, jadi ia digunakan secara meluas dalam sistem kawalan, pengecaman corak, perlombongan data dan bidang lain. Seni bina asas rangkaian neural kabur terdiri daripada subsistem kabur dan subsistem saraf. Subsistem kabur menggunakan logik kabur untuk memproses data input dan menukarnya kepada set kabur untuk menyatakan kekaburan dan ketidakpastian data input. Subsistem saraf menggunakan rangkaian saraf untuk memproses set kabur untuk tugasan seperti pengelasan, regresi atau pengelompokan. Interaksi antara subsistem kabur dan subsistem saraf menjadikan rangkaian neural kabur mempunyai keupayaan pemprosesan yang lebih berkuasa dan boleh
 Kajian kes menggunakan model LSTM dwiarah untuk pengelasan teks
Jan 24, 2024 am 10:36 AM
Kajian kes menggunakan model LSTM dwiarah untuk pengelasan teks
Jan 24, 2024 am 10:36 AM
Model LSTM dwiarah ialah rangkaian saraf yang digunakan untuk pengelasan teks. Berikut ialah contoh mudah yang menunjukkan cara menggunakan LSTM dwiarah untuk tugasan pengelasan teks. Pertama, kita perlu mengimport perpustakaan dan modul yang diperlukan: importosimportnumpyasnpfromkeras.preprocessing.textimportTokenizerfromkeras.preprocessing.sequenceimportpad_sequencesfromkeras.modelsimportSequentialfromkeras.layersimportDense,Em
 Penghapusan imej menggunakan rangkaian saraf konvolusi
Jan 23, 2024 pm 11:48 PM
Penghapusan imej menggunakan rangkaian saraf konvolusi
Jan 23, 2024 pm 11:48 PM
Rangkaian neural konvolusi berfungsi dengan baik dalam tugasan menghilangkan imej. Ia menggunakan penapis yang dipelajari untuk menapis bunyi dan dengan itu memulihkan imej asal. Artikel ini memperkenalkan secara terperinci kaedah denoising imej berdasarkan rangkaian neural convolutional. 1. Gambaran Keseluruhan Rangkaian Neural Konvolusi Rangkaian saraf konvolusi ialah algoritma pembelajaran mendalam yang menggunakan gabungan berbilang lapisan konvolusi, lapisan gabungan dan lapisan bersambung sepenuhnya untuk mempelajari dan mengelaskan ciri imej. Dalam lapisan konvolusi, ciri tempatan imej diekstrak melalui operasi konvolusi, dengan itu menangkap korelasi spatial dalam imej. Lapisan pengumpulan mengurangkan jumlah pengiraan dengan mengurangkan dimensi ciri dan mengekalkan ciri utama. Lapisan bersambung sepenuhnya bertanggungjawab untuk memetakan ciri dan label yang dipelajari untuk melaksanakan pengelasan imej atau tugas lain. Reka bentuk struktur rangkaian ini menjadikan rangkaian neural konvolusi berguna dalam pemprosesan dan pengecaman imej.
 Rangkaian Neural Berkembar: Analisis Prinsip dan Aplikasi
Jan 24, 2024 pm 04:18 PM
Rangkaian Neural Berkembar: Analisis Prinsip dan Aplikasi
Jan 24, 2024 pm 04:18 PM
Rangkaian Neural Siam ialah struktur rangkaian saraf tiruan yang unik. Ia terdiri daripada dua rangkaian neural yang sama yang berkongsi parameter dan berat yang sama. Pada masa yang sama, kedua-dua rangkaian juga berkongsi data input yang sama. Reka bentuk ini diilhamkan oleh kembar, kerana kedua-dua rangkaian saraf adalah sama dari segi struktur. Prinsip rangkaian saraf Siam adalah untuk menyelesaikan tugas tertentu, seperti padanan imej, padanan teks dan pengecaman muka, dengan membandingkan persamaan atau jarak antara dua data input. Semasa latihan, rangkaian cuba untuk memetakan data yang serupa ke wilayah bersebelahan dan data yang tidak serupa ke wilayah yang jauh. Dengan cara ini, rangkaian boleh belajar cara mengklasifikasikan atau memadankan data yang berbeza dan mencapai yang sepadan
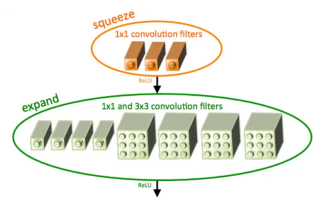 Pengenalan kepada SqueezeNet dan ciri-cirinya
Jan 22, 2024 pm 07:15 PM
Pengenalan kepada SqueezeNet dan ciri-cirinya
Jan 22, 2024 pm 07:15 PM
SqueezeNet ialah algoritma kecil dan tepat yang memberikan keseimbangan yang baik antara ketepatan tinggi dan kerumitan rendah, menjadikannya sesuai untuk sistem mudah alih dan terbenam dengan sumber terhad. Pada 2016, penyelidik dari DeepScale, University of California, Berkeley, dan Stanford University mencadangkan SqueezeNet, rangkaian neural convolutional (CNN) yang padat dan cekap. Dalam beberapa tahun kebelakangan ini, penyelidik telah membuat beberapa penambahbaikan pada SqueezeNet, termasuk SqueezeNetv1.1 dan SqueezeNetv2.0. Penambahbaikan dalam kedua-dua versi bukan sahaja meningkatkan ketepatan tetapi juga mengurangkan kos pengiraan. Ketepatan SqueezeNetv1.1 pada dataset ImageNet
 rangkaian neural convolutional sebab
Jan 24, 2024 pm 12:42 PM
rangkaian neural convolutional sebab
Jan 24, 2024 pm 12:42 PM
Rangkaian neural convolutional kausal ialah rangkaian neural convolutional khas yang direka untuk masalah kausalitas dalam data siri masa. Berbanding dengan rangkaian neural convolutional konvensional, rangkaian neural convolutional kausal mempunyai kelebihan unik dalam mengekalkan hubungan kausal siri masa dan digunakan secara meluas dalam ramalan dan analisis data siri masa. Idea teras rangkaian neural convolutional kausal adalah untuk memperkenalkan kausalitas dalam operasi konvolusi. Rangkaian saraf konvolusional tradisional boleh melihat data secara serentak sebelum dan selepas titik masa semasa, tetapi dalam ramalan siri masa, ini mungkin membawa kepada masalah kebocoran maklumat. Kerana keputusan ramalan pada titik masa semasa akan dipengaruhi oleh data pada titik masa akan datang. Rangkaian saraf konvolusi penyebab menyelesaikan masalah ini Ia hanya dapat melihat titik masa semasa dan data sebelumnya, tetapi tidak dapat melihat data masa depan.
