
 Peranti teknologi
AI
Kaedah baharu Google ASPIRE: memperkasakan LLM dengan keupayaan pemarkahan sendiri, menyelesaikan masalah 'ilusi' dengan berkesan dan mengatasi 10 kali ganda model volum
Peranti teknologi
AI
Kaedah baharu Google ASPIRE: memperkasakan LLM dengan keupayaan pemarkahan sendiri, menyelesaikan masalah 'ilusi' dengan berkesan dan mengatasi 10 kali ganda model volum
Kaedah baharu Google ASPIRE: memperkasakan LLM dengan keupayaan pemarkahan sendiri, menyelesaikan masalah 'ilusi' dengan berkesan dan mengatasi 10 kali ganda model volum

Masalah "ilusi" model besar akan selesai tidak lama lagi?
Para penyelidik di University of Wisconsin-Madison dan Google baru-baru ini melancarkan sistem ASPIRE, yang membolehkan model besar menilai sendiri output mereka.
Jika pengguna melihat bahawa hasil yang dihasilkan oleh model mempunyai skor yang rendah, dia akan menyedari bahawa balasan itu mungkin ilusi.
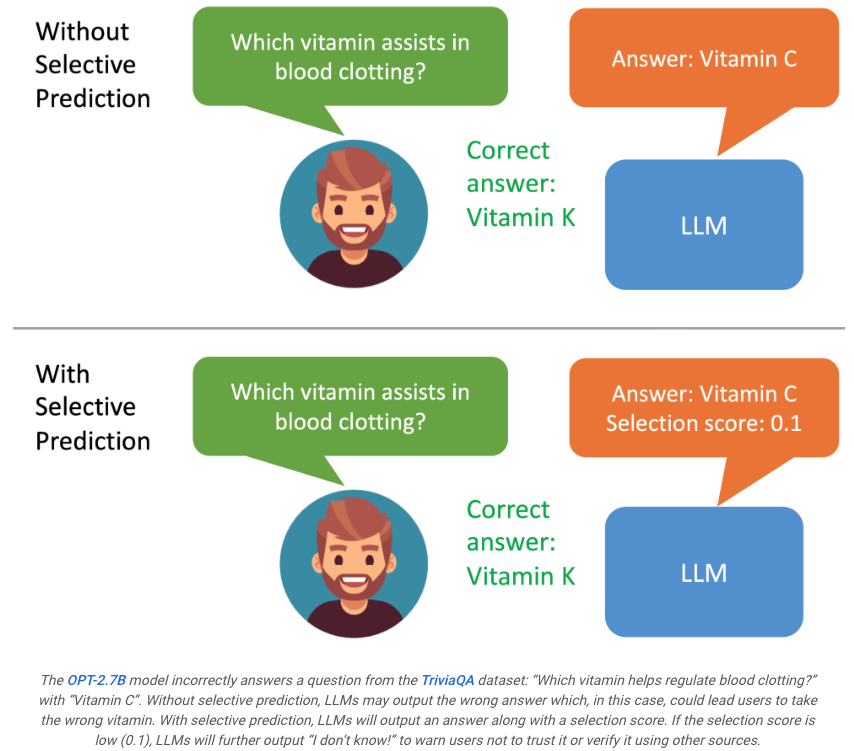
Sekiranya sistem boleh menapis kandungan output berdasarkan hasil penilaian, contohnya, apabila rating rendah, model besar boleh menjana pernyataan seperti "Saya tidak dapat menjawab soalan ini", yang mungkin memaksimumkan penambahbaikan masalah halusinasi.

Alamat kertas: https://aclanthology.org/2023.findings-emnlp.345.pdf
ASPIRE membolehkan LLM mengeluarkan jawapan dan skor keyakinan jawapan.
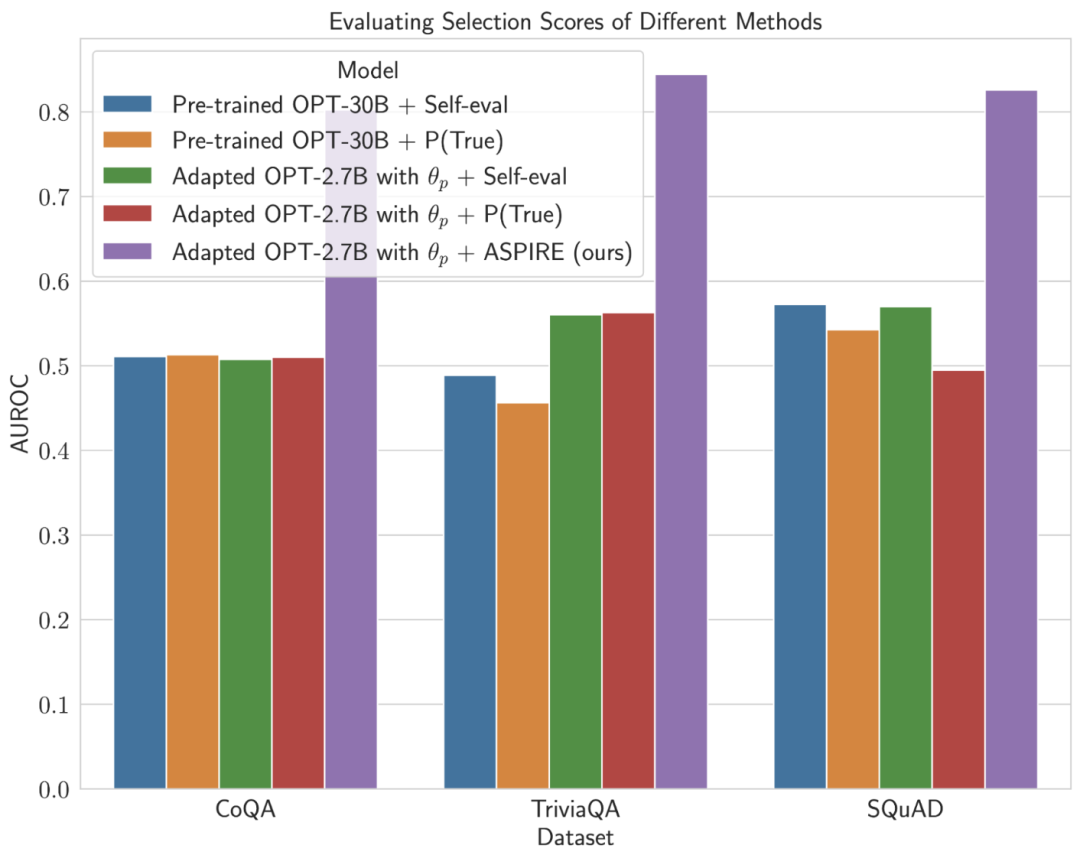
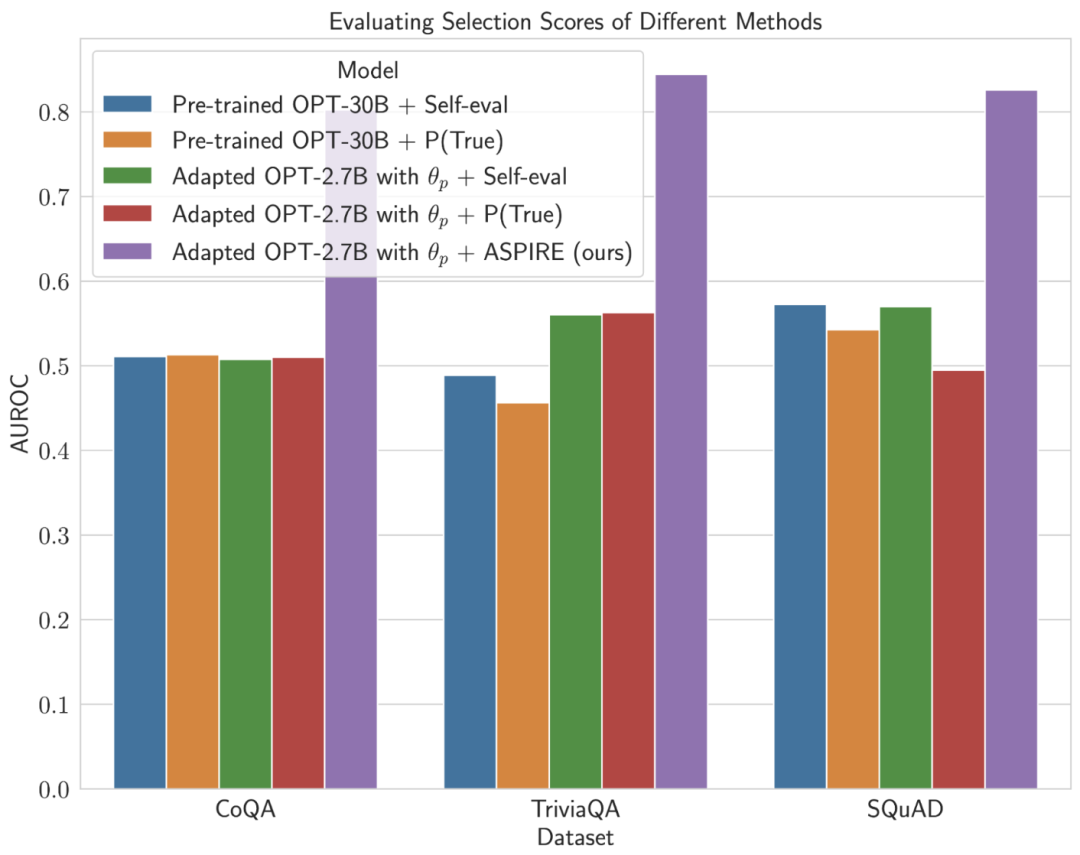
Keputusan percubaan penyelidik menunjukkan bahawa ASPIRE secara ketara mengatasi kaedah ramalan terpilih tradisional pada pelbagai set data QA (seperti penanda aras CoQA).
Biar LLM bukan sahaja menjawab soalan tetapi juga menilai jawapan tersebut.
Dalam ujian penanda aras ramalan terpilih, penyelidik mencapai keputusan lebih daripada 10 kali ganda skala model melalui sistem ASPIRE.
Ia seperti meminta pelajar mengesahkan jawapan mereka sendiri di belakang buku teks Walaupun kedengarannya agak tidak boleh dipercayai, jika difikirkan dengan teliti, semua orang memang akan berpuas hati dengan jawapan selepas menjawab soalan. Akan ada penilaian.
Inilah intipati ASPIRE, yang melibatkan tiga peringkat:
(1) Menala untuk tugas tertentu,
(2)
Jawapan,( 3 ) Menilai pembelajaran kendiri.
Di mata penyelidik, ASPIRE bukan sekadar rangka kerja lain, ia mewakili masa depan yang cerah yang meningkatkan kebolehpercayaan LLM secara menyeluruh dan mengurangkan halusinasi.
Jika LLM boleh menjadi rakan kongsi yang boleh dipercayai dalam proses membuat keputusan.
Selagi kita terus mengoptimumkan keupayaan ramalan terpilih, manusia selangkah lebih dekat untuk merealisasikan potensi model besar sepenuhnya.
Penyelidik berharap dapat menggunakan ASPIRE untuk memulakan evolusi generasi LLM seterusnya, dengan itu mencipta kecerdasan buatan yang lebih dipercayai dan sedar diri.
Mekanisme ASPIRE
Penalaan halus khusus tugas
ASPIRE melakukan penalaan halus khusus tugasan untuk melatih parameter penyesuaian🜎🜎 membebaskan 
Untuk tujuan ini, teknik penalaan halus yang cekap parameter (cth., penalaan halus perkataan kiu lembut dan LoRA) boleh digunakan untuk memperhalusi LLM pra-latihan pada tugas itu, kerana mereka boleh memperoleh generalisasi yang kukuh dengan berkesan dengan sejumlah kecil data sasaran.
Secara khusus, parameter LLM (θ) dibekukan dan parameter penyesuaian
ditambah untuk penalaan halus. 
Penalaan halus ini boleh meningkatkan prestasi ramalan terpilih kerana ia bukan sahaja meningkatkan ketepatan ramalan, tetapi juga meningkatkan kemungkinan mengeluarkan jujukan dengan betul.
Selepas ditala untuk tugasan tertentu, ASPIRE menggunakan LLM dan belajar Matlamat penyelidik adalah untuk menjana jujukan output dengan kemungkinan yang tinggi. Mereka menggunakan Carian Rasuk sebagai algoritma penyahkodan untuk menjana jujukan output berkemungkinan tinggi dan menggunakan metrik Rouge-L untuk menentukan sama ada jujukan output yang dijana adalah betul. . boleh mengelakkan perubahan tingkah laku ramalan LLM semasa mempelajari penilaian kendiri. . , penyelidik memperoleh ramalan pertanyaan melalui penyahkodan carian pancaran. Para penyelidik kemudiannya mentakrifkan skor pilihan yang menggabungkan kemungkinan menjana jawapan dengan skor penilaian kendiri yang dipelajari (iaitu, kemungkinan ramalan itu betul untuk pertanyaan) untuk membuat ramalan terpilih. Dengan melaraskan latihan menggunakan isyarat lembut Sebagai contoh, model OPT-2.7B dengan ASPIRE menunjukkan prestasi yang lebih baik berbanding model OPT-30B pra-latihan yang lebih besar menggunakan set data CoQA dan SQuAD. Hasil ini mencadangkan bahawa dengan penalaan yang sesuai, LLM yang lebih kecil mungkin mempunyai keupayaan untuk memadankan atau mungkin melebihi ketepatan model yang lebih besar dalam beberapa kes. Apabila menyelidiki pengiraan skor pemilihan untuk ramalan model tetap, ASPIRE mencapai skor AUROC yang lebih tinggi daripada kaedah garis dasar untuk semua set data (urutan output betul yang dipilih secara rawak mempunyai nilai yang lebih tinggi daripada urutan output salah yang dipilih secara rawak) kebarangkalian skor pemilihan yang lebih tinggi). Sebagai contoh, pada penanda aras CoQA, ASPIRE meningkatkan AUROC daripada 51.3% kepada 80.3% berbanding garis dasar. Satu corak menarik muncul daripada penilaian pada set data TriviaQA. . Sebaliknya, model OPT-2.7B yang jauh lebih kecil mengatasi model lain dalam hal ini selepas dipertingkatkan dengan ASPIRE. Perbezaan ini merangkumi isu penting: LLM yang lebih besar yang menggunakan teknik penilaian kendiri tradisional mungkin tidak berkesan dalam ramalan terpilih seperti model yang dipertingkatkan ASPIRE yang lebih kecil.
Perjalanan percubaan penyelidik dengan ASPIRE menyerlahkan anjakan utama dalam landskap LLM: kapasiti model bahasa bukanlah keseluruhan dan akhir dari prestasinya. Sebaliknya, keberkesanan model boleh dipertingkatkan dengan banyak melalui pelarasan dasar, membolehkan ramalan yang lebih tepat dan yakin walaupun dalam model yang lebih kecil. Oleh itu, ASPIRE menunjukkan potensi LLM untuk menentukan dengan wajar kepastian jawapannya sendiri dan dengan ketara mengatasi prestasi 10x lebih besar model lain dalam tugas ramalan terpilih. Pensampelan Jawapan
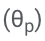 untuk menjana jawapan yang berbeza bagi setiap soalan latihan dan mencipta set data untuk pembelajaran penilaian kendiri.
untuk menjana jawapan yang berbeza bagi setiap soalan latihan dan mencipta set data untuk pembelajaran penilaian kendiri.
Memandangkan penjanaan jujukan keluaran hanya bergantung kepada θ dan , pembekuan θ dan yang dipelajari
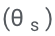 Para penyelidik mengoptimumkan
Para penyelidik mengoptimumkan 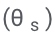 supaya LLM yang disesuaikan dapat membezakan jawapan yang betul dan salah dengan sendirinya.
supaya LLM yang disesuaikan dapat membezakan jawapan yang betul dan salah dengan sendirinya. 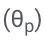 Dalam rangka kerja ini, sebarang kaedah penalaan halus yang cekap parameter boleh digunakan untuk melatih
Dalam rangka kerja ini, sebarang kaedah penalaan halus yang cekap parameter boleh digunakan untuk melatih 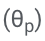 dan
dan 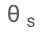 Dalam kerja ini, penyelidik menggunakan penalaan halus kiu lembut, mekanisme yang mudah namun berkesan untuk mempelajari "isyarat lembut" untuk menala model bahasa beku supaya lebih berkesan daripada isyarat teks diskret tradisional untuk melaksanakan tugas hiliran tertentu.
Dalam kerja ini, penyelidik menggunakan penalaan halus kiu lembut, mekanisme yang mudah namun berkesan untuk mempelajari "isyarat lembut" untuk menala model bahasa beku supaya lebih berkesan daripada isyarat teks diskret tradisional untuk melaksanakan tugas hiliran tertentu. 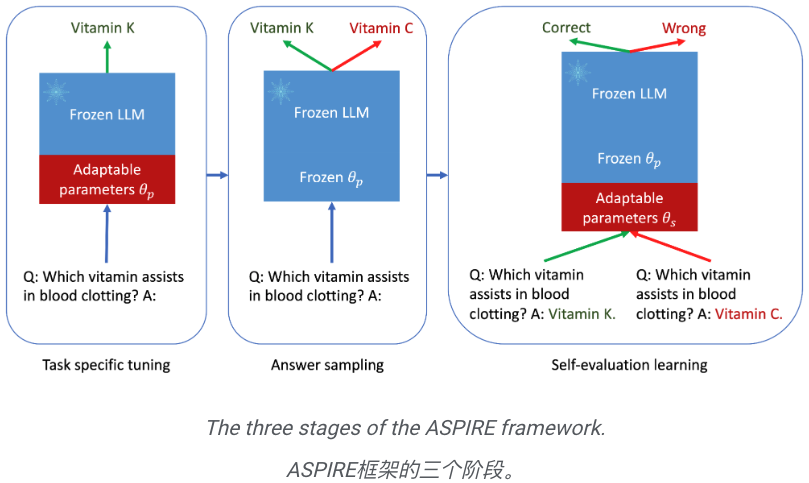
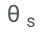 Selepas latihan
Selepas latihan 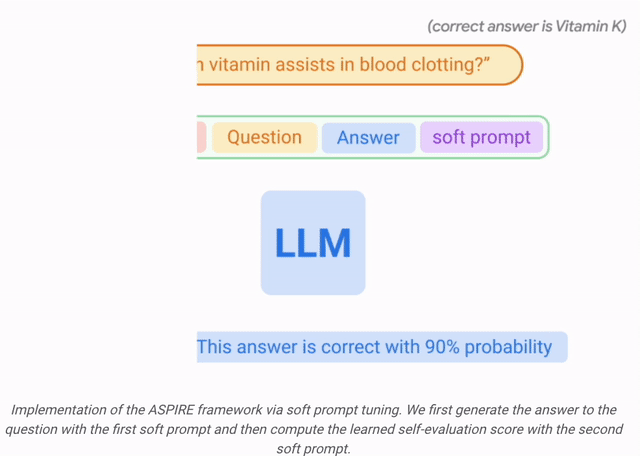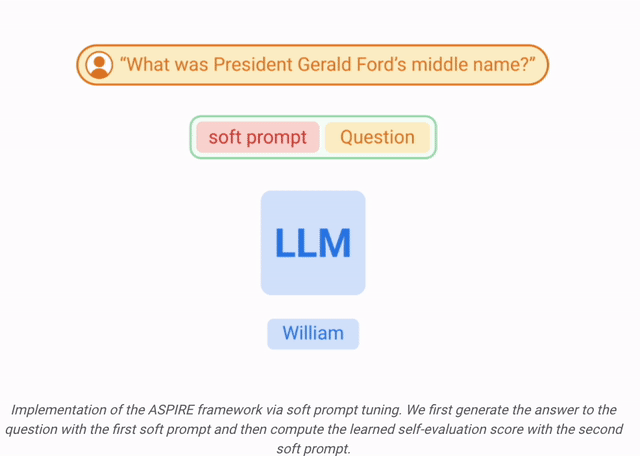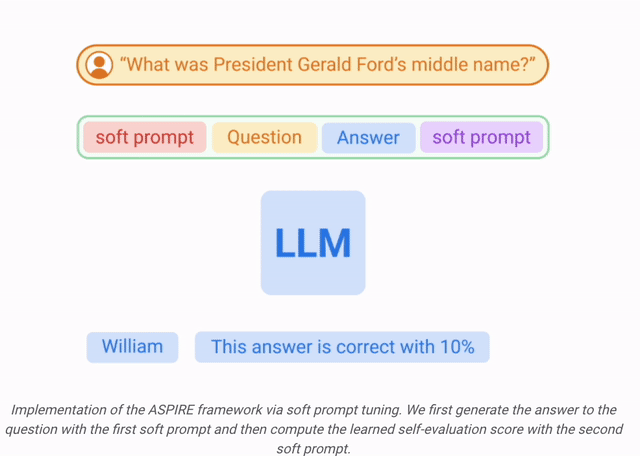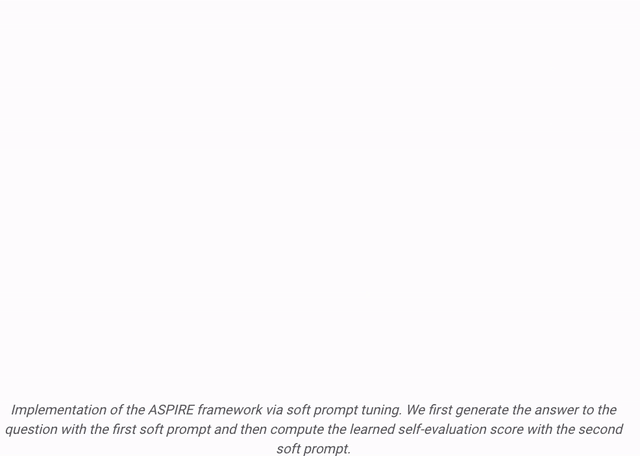 Keputusan
Keputusan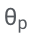 Untuk menunjukkan keberkesanan ASPIRE, para penyelidik menggunakan pelbagai model Transformer (OPT) pra-latihan terbuka untuk menilai mereka pada tiga set data menjawab soalan (CoQA, TriviaQA dan SQuAD).
Untuk menunjukkan keberkesanan ASPIRE, para penyelidik menggunakan pelbagai model Transformer (OPT) pra-latihan terbuka untuk menilai mereka pada tiga set data menjawab soalan (CoQA, TriviaQA dan SQuAD). 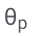 Para penyelidik memerhatikan peningkatan yang ketara dalam ketepatan LLM.
Para penyelidik memerhatikan peningkatan yang ketara dalam ketepatan LLM. 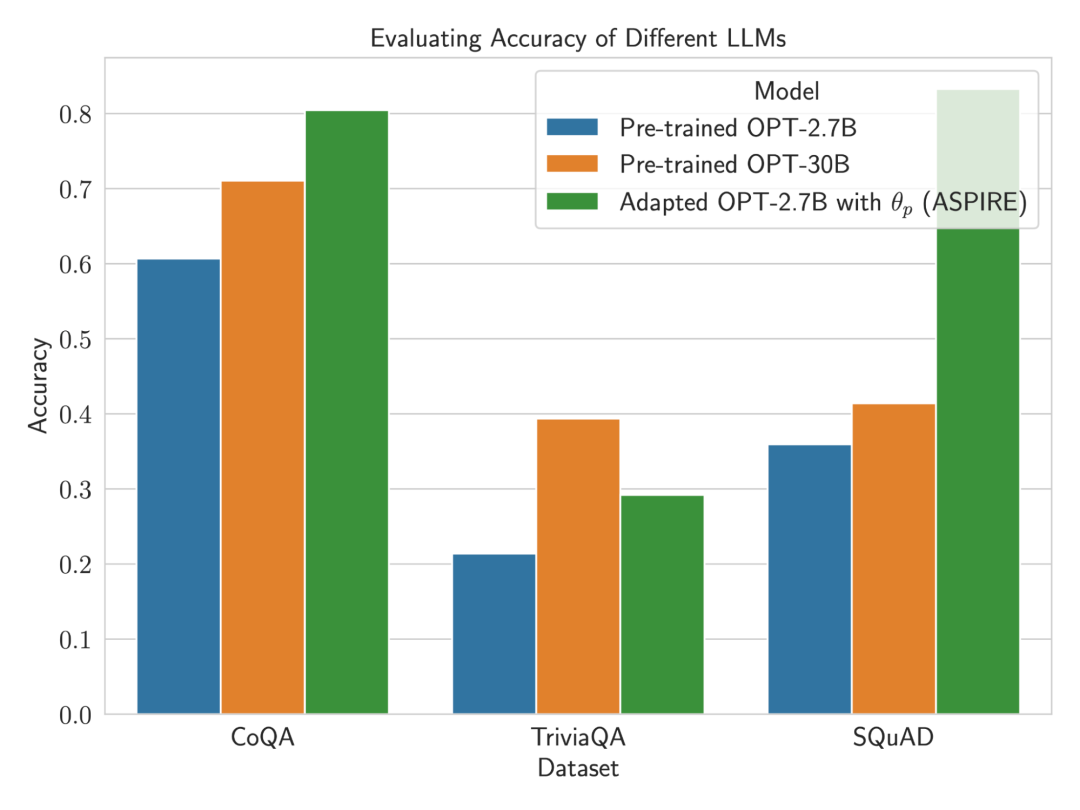
Atas ialah kandungan terperinci Kaedah baharu Google ASPIRE: memperkasakan LLM dengan keupayaan pemarkahan sendiri, menyelesaikan masalah 'ilusi' dengan berkesan dan mengatasi 10 kali ganda model volum. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Gunakan ddrescue untuk memulihkan data pada Linux
Mar 20, 2024 pm 01:37 PM
Gunakan ddrescue untuk memulihkan data pada Linux
Mar 20, 2024 pm 01:37 PM
DDREASE ialah alat untuk memulihkan data daripada fail atau peranti sekat seperti cakera keras, SSD, cakera RAM, CD, DVD dan peranti storan USB. Ia menyalin data dari satu peranti blok ke peranti lain, meninggalkan blok data yang rosak dan hanya memindahkan blok data yang baik. ddreasue ialah alat pemulihan yang berkuasa yang automatik sepenuhnya kerana ia tidak memerlukan sebarang gangguan semasa operasi pemulihan. Selain itu, terima kasih kepada fail peta ddasue, ia boleh dihentikan dan disambung semula pada bila-bila masa. Ciri-ciri utama lain DDREASE adalah seperti berikut: Ia tidak menimpa data yang dipulihkan tetapi mengisi jurang sekiranya pemulihan berulang. Walau bagaimanapun, ia boleh dipotong jika alat itu diarahkan untuk melakukannya secara eksplisit. Pulihkan data daripada berbilang fail atau blok kepada satu
 Sumber terbuka! Di luar ZoeDepth! DepthFM: Anggaran kedalaman monokular yang cepat dan tepat!
Apr 03, 2024 pm 12:04 PM
Sumber terbuka! Di luar ZoeDepth! DepthFM: Anggaran kedalaman monokular yang cepat dan tepat!
Apr 03, 2024 pm 12:04 PM
0. Apakah fungsi artikel ini? Kami mencadangkan DepthFM: model anggaran kedalaman monokular generatif yang serba boleh dan pantas. Sebagai tambahan kepada tugas anggaran kedalaman tradisional, DepthFM juga menunjukkan keupayaan terkini dalam tugas hiliran seperti mengecat kedalaman. DepthFM cekap dan boleh mensintesis peta kedalaman dalam beberapa langkah inferens. Mari kita baca karya ini bersama-sama ~ 1. Tajuk maklumat kertas: DepthFM: FastMonocularDepthEstimationwithFlowMatching Pengarang: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas secara rasmi memasuki era robot elektrik! Semalam, Atlas hidraulik hanya "menangis" menarik diri daripada peringkat sejarah Hari ini, Boston Dynamics mengumumkan bahawa Atlas elektrik sedang berfungsi. Nampaknya dalam bidang robot humanoid komersial, Boston Dynamics berazam untuk bersaing dengan Tesla. Selepas video baharu itu dikeluarkan, ia telah pun ditonton oleh lebih sejuta orang dalam masa sepuluh jam sahaja. Orang lama pergi dan peranan baru muncul. Ini adalah keperluan sejarah. Tidak dinafikan bahawa tahun ini adalah tahun letupan robot humanoid. Netizen mengulas: Kemajuan robot telah menjadikan majlis pembukaan tahun ini kelihatan seperti manusia, dan tahap kebebasan adalah jauh lebih besar daripada manusia Tetapi adakah ini benar-benar bukan filem seram? Pada permulaan video, Atlas berbaring dengan tenang di atas tanah, seolah-olah terlentang. Apa yang berikut adalah rahang-jatuh
 Google gembira: prestasi JAX mengatasi Pytorch dan TensorFlow! Ia mungkin menjadi pilihan terpantas untuk latihan inferens GPU
Apr 01, 2024 pm 07:46 PM
Google gembira: prestasi JAX mengatasi Pytorch dan TensorFlow! Ia mungkin menjadi pilihan terpantas untuk latihan inferens GPU
Apr 01, 2024 pm 07:46 PM
Prestasi JAX, yang dipromosikan oleh Google, telah mengatasi Pytorch dan TensorFlow dalam ujian penanda aras baru-baru ini, menduduki tempat pertama dalam 7 penunjuk. Dan ujian tidak dilakukan pada TPU dengan prestasi JAX terbaik. Walaupun dalam kalangan pembangun, Pytorch masih lebih popular daripada Tensorflow. Tetapi pada masa hadapan, mungkin lebih banyak model besar akan dilatih dan dijalankan berdasarkan platform JAX. Model Baru-baru ini, pasukan Keras menanda aras tiga hujung belakang (TensorFlow, JAX, PyTorch) dengan pelaksanaan PyTorch asli dan Keras2 dengan TensorFlow. Pertama, mereka memilih satu set arus perdana
 Kelajuan Internet Data Selular Perlahan pada iPhone: Pembetulan
May 03, 2024 pm 09:01 PM
Kelajuan Internet Data Selular Perlahan pada iPhone: Pembetulan
May 03, 2024 pm 09:01 PM
Menghadapi ketinggalan, sambungan data mudah alih perlahan pada iPhone? Biasanya, kekuatan internet selular pada telefon anda bergantung pada beberapa faktor seperti rantau, jenis rangkaian selular, jenis perayauan, dsb. Terdapat beberapa perkara yang boleh anda lakukan untuk mendapatkan sambungan Internet selular yang lebih pantas dan boleh dipercayai. Betulkan 1 – Paksa Mulakan Semula iPhone Kadangkala, paksa memulakan semula peranti anda hanya menetapkan semula banyak perkara, termasuk sambungan selular. Langkah 1 – Hanya tekan kekunci naikkan kelantangan sekali dan lepaskan. Seterusnya, tekan kekunci Turun Kelantangan dan lepaskannya semula. Langkah 2 - Bahagian seterusnya proses adalah untuk menahan butang di sebelah kanan. Biarkan iPhone selesai dimulakan semula. Dayakan data selular dan semak kelajuan rangkaian. Semak semula Betulkan 2 – Tukar mod data Walaupun 5G menawarkan kelajuan rangkaian yang lebih baik, ia berfungsi lebih baik apabila isyarat lemah
 Versi Kuaishou Sora 'Ke Ling' dibuka untuk ujian: menghasilkan video lebih 120-an, memahami fizik dengan lebih baik dan boleh memodelkan pergerakan kompleks dengan tepat
Jun 11, 2024 am 09:51 AM
Versi Kuaishou Sora 'Ke Ling' dibuka untuk ujian: menghasilkan video lebih 120-an, memahami fizik dengan lebih baik dan boleh memodelkan pergerakan kompleks dengan tepat
Jun 11, 2024 am 09:51 AM
Apa? Adakah Zootopia dibawa menjadi realiti oleh AI domestik? Didedahkan bersama-sama dengan video itu ialah model penjanaan video domestik berskala besar baharu yang dipanggil "Keling". Sora menggunakan laluan teknikal yang serupa dan menggabungkan beberapa inovasi teknologi yang dibangunkan sendiri untuk menghasilkan video yang bukan sahaja mempunyai pergerakan yang besar dan munasabah, tetapi juga mensimulasikan ciri-ciri dunia fizikal dan mempunyai keupayaan gabungan konsep dan imaginasi yang kuat. Mengikut data, Keling menyokong penjanaan video ultra panjang sehingga 2 minit pada 30fps, dengan resolusi sehingga 1080p dan menyokong berbilang nisbah aspek. Satu lagi perkara penting ialah Keling bukanlah demo atau demonstrasi hasil video yang dikeluarkan oleh makmal, tetapi aplikasi peringkat produk yang dilancarkan oleh Kuaishou, pemain terkemuka dalam bidang video pendek. Selain itu, tumpuan utama adalah untuk menjadi pragmatik, bukan untuk menulis cek kosong, dan pergi ke dalam talian sebaik sahaja ia dikeluarkan Model besar Ke Ling telah pun dikeluarkan di Kuaiying.
 Daya hidup kecerdasan super membangkitkan! Tetapi dengan kedatangan AI yang mengemas kini sendiri, ibu tidak perlu lagi bimbang tentang kesesakan data
Apr 29, 2024 pm 06:55 PM
Daya hidup kecerdasan super membangkitkan! Tetapi dengan kedatangan AI yang mengemas kini sendiri, ibu tidak perlu lagi bimbang tentang kesesakan data
Apr 29, 2024 pm 06:55 PM
Saya menangis hingga mati. Dunia sedang membina model besar. Data di Internet tidak mencukupi. Model latihan kelihatan seperti "The Hunger Games", dan penyelidik AI di seluruh dunia bimbang tentang cara memberi makan data ini kepada pemakan yang rakus. Masalah ini amat ketara dalam tugas berbilang modal. Pada masa mereka mengalami kerugian, pasukan pemula dari Jabatan Universiti Renmin China menggunakan model baharu mereka sendiri untuk menjadi yang pertama di China untuk menjadikan "suapan data yang dijana model itu sendiri" menjadi kenyataan. Selain itu, ia merupakan pendekatan serampang dua mata dari segi pemahaman dan sisi penjanaan Kedua-dua pihak boleh menjana data baharu berbilang modal yang berkualiti tinggi dan memberikan maklum balas data kepada model itu sendiri. Apakah model? Awaker 1.0, model berbilang modal besar yang baru sahaja muncul di Forum Zhongguancun. Siapa pasukan itu? Enjin Sophon. Diasaskan oleh Gao Yizhao, pelajar kedoktoran di Sekolah Kecerdasan Buatan Hillhouse Universiti Renmin.
 Tentera Udara A.S. mempamerkan jet pejuang AI pertamanya dengan profil tinggi! Menteri secara peribadi menjalankan pandu uji tanpa campur tangan semasa keseluruhan proses, dan 100,000 baris kod telah diuji selama 21 kali.
May 07, 2024 pm 05:00 PM
Tentera Udara A.S. mempamerkan jet pejuang AI pertamanya dengan profil tinggi! Menteri secara peribadi menjalankan pandu uji tanpa campur tangan semasa keseluruhan proses, dan 100,000 baris kod telah diuji selama 21 kali.
May 07, 2024 pm 05:00 PM
Baru-baru ini, bulatan tentera telah terharu dengan berita: jet pejuang tentera AS kini boleh melengkapkan pertempuran udara automatik sepenuhnya menggunakan AI. Ya, baru-baru ini, jet pejuang AI tentera AS telah didedahkan buat pertama kali, mendedahkan misterinya. Nama penuh pesawat pejuang ini ialah Variable Stability Simulator Test Aircraft (VISTA). Ia diterbangkan sendiri oleh Setiausaha Tentera Udara AS untuk mensimulasikan pertempuran udara satu lawan satu. Pada 2 Mei, Setiausaha Tentera Udara A.S. Frank Kendall berlepas menggunakan X-62AVISTA di Pangkalan Tentera Udara Edwards Ambil perhatian bahawa semasa penerbangan selama satu jam, semua tindakan penerbangan telah diselesaikan secara autonomi oleh AI! Kendall berkata - "Sejak beberapa dekad yang lalu, kami telah memikirkan tentang potensi tanpa had pertempuran udara-ke-udara autonomi, tetapi ia sentiasa kelihatan di luar jangkauan." Namun kini,
