
 pembangunan bahagian belakang
Tutorial Python
Pengenalan kepada algoritma Wu-Manber dan arahan pelaksanaan Python
pembangunan bahagian belakang
Tutorial Python
Pengenalan kepada algoritma Wu-Manber dan arahan pelaksanaan Python
Pengenalan kepada algoritma Wu-Manber dan arahan pelaksanaan Python


Algoritma Wu-Manber ialah algoritma pemadanan rentetan yang digunakan untuk mencari rentetan dengan cekap. Ia adalah algoritma hibrid yang menggabungkan kelebihan algoritma Boyer-Moore dan Knuth-Morris-Pratt untuk menyediakan padanan corak yang pantas dan tepat.
Langkah algoritma Wu-Manber
1 Cipta jadual cincang yang memetakan setiap subrentetan corak ke kedudukan corak di mana subrentetan itu berlaku.
2. Jadual cincang ini digunakan untuk mengenal pasti potensi kedudukan permulaan corak dalam teks.
3 Gelung melalui teks dan bandingkan setiap aksara dengan watak yang sepadan dalam corak.
4. Jika watak itu sepadan, anda boleh beralih ke watak seterusnya dan teruskan membandingkan.
5 Jika aksara tidak sepadan, jadual cincang boleh digunakan untuk menentukan bilangan maksimum aksara yang boleh dilangkau sebelum potensi kedudukan permulaan corak seterusnya.
6 Ini membolehkan algoritma melangkau sebahagian besar teks dengan cepat tanpa kehilangan sebarang kemungkinan padanan.
Python melaksanakan algoritma Wu-Manber
# Define the hash_pattern() function to generate
# a hash for each subpattern
def hashPattern(pattern, i, j):
h = 0
for k in range(i, j):
h = h * 256 + ord(pattern[k])
return h
# Define the Wu Manber algorithm
def wuManber(text, pattern):
# Define the length of the pattern and
# text
m = len(pattern)
n = len(text)
# Define the number of subpatterns to use
s = 2
# Define the length of each subpattern
t = m // s
# Initialize the hash values for each
# subpattern
h = [0] * s
for i in range(s):
h[i] = hashPattern(pattern, i * t, (i + 1) * t)
# Initialize the shift value for each
# subpattern
shift = [0] * s
for i in range(s):
shift[i] = t * (s - i - 1)
# Initialize the match value
match = False
# Iterate through the text
for i in range(n - m + 1):
# Check if the subpatterns match
for j in range(s):
if hashPattern(text, i + j * t, i + (j + 1) * t) != h[j]:
break
else:
# If the subpatterns match, check if
# the full pattern matches
if text[i:i + m] == pattern:
print("Match found at index", i)
match = True
# Shift the pattern by the appropriate
# amount
for j in range(s):
if i + shift[j] < n - m + 1:
break
else:
i += shift[j]
# If no match was found, print a message
if not match:
print("No match found")
# Driver Code
text = "the cat sat on the mat"
pattern = "the"
# Function call
wuManber(text, pattern)Perbezaan antara algoritma KMP dan Wu-Manber
Algoritma KMP dan algoritma Wu Manber adalah kedua-dua algoritma pemadanan rentetan, yang bermaksud kedua-duanya berada dalam kedua-dua algoritma pemadanan rentetan. rentetan yang lebih besar. Kedua-dua algoritma mempunyai kerumitan masa yang sama, yang bermaksud ia mempunyai ciri prestasi yang sama dari segi masa yang diperlukan untuk algoritma dijalankan.
Walau bagaimanapun, terdapat beberapa perbezaan antara mereka:
1 Algoritma KMP menggunakan langkah prapemprosesan untuk menghasilkan jadual padanan separa, yang digunakan untuk mempercepatkan proses pemadanan rentetan. Ini menjadikan algoritma KMP lebih cekap daripada algoritma Wu Manber apabila corak yang dicari agak panjang.
2 Algoritma Wu Manber menggunakan kaedah yang berbeza untuk padanan rentetan Ia membahagikan corak kepada berbilang sub-corak dan menggunakan sub-corak ini untuk mencari padanan dalam teks. Ini menjadikan algoritma Wu Manber lebih cekap daripada algoritma KMP apabila corak yang dicari agak pendek.
Atas ialah kandungan terperinci Pengenalan kepada algoritma Wu-Manber dan arahan pelaksanaan Python. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Analisis mendalam tentang Algoritma Pengoptimuman Serigala Kelabu (GWO) serta kekuatan dan kelemahannya
Jan 19, 2024 pm 07:48 PM
Analisis mendalam tentang Algoritma Pengoptimuman Serigala Kelabu (GWO) serta kekuatan dan kelemahannya
Jan 19, 2024 pm 07:48 PM
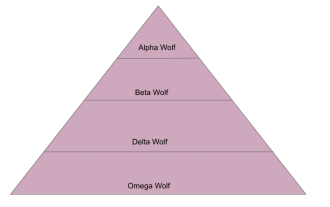
Algoritma Pengoptimuman Serigala Kelabu (GWO) ialah algoritma metaheuristik berasaskan populasi yang menyerupai hierarki kepimpinan dan mekanisme memburu serigala kelabu dalam alam semula jadi. Inspirasi Algoritma Serigala Kelabu 1. Serigala kelabu dianggap sebagai pemangsa puncak dan berada di bahagian atas rantai makanan. 2. Serigala kelabu suka hidup dalam kumpulan (hidup berkumpulan), dengan purata 5-12 serigala dalam setiap pek. 3. Serigala kelabu mempunyai hierarki penguasaan sosial yang sangat ketat, seperti yang ditunjukkan di bawah: Serigala alfa: Serigala alfa menduduki kedudukan dominan dalam keseluruhan kumpulan serigala kelabu dan mempunyai hak untuk memerintah seluruh kumpulan serigala kelabu. Dalam aplikasi algoritma, Alpha Wolf adalah salah satu penyelesaian terbaik, penyelesaian optimum yang dihasilkan oleh algoritma pengoptimuman. Serigala beta: Serigala beta melaporkan kepada serigala Alpha dengan kerap dan membantu serigala Alpha membuat keputusan yang terbaik. Dalam aplikasi algoritma, Beta Wolf boleh
 Terokai prinsip asas dan proses pelaksanaan algoritma pensampelan bersarang
Jan 22, 2024 pm 09:51 PM
Terokai prinsip asas dan proses pelaksanaan algoritma pensampelan bersarang
Jan 22, 2024 pm 09:51 PM
Algoritma persampelan bersarang ialah algoritma inferens statistik Bayesian yang cekap digunakan untuk mengira kamiran atau penjumlahan di bawah taburan kebarangkalian kompleks. Ia berfungsi dengan menguraikan ruang parameter kepada berbilang hiperkubus dengan isipadu yang sama, dan secara beransur-ansur dan berulang "menolak keluar" salah satu hiperkubus volum terkecil, dan kemudian mengisi hiperkubus dengan sampel rawak untuk menganggarkan nilai kamiran taburan kebarangkalian dengan lebih baik. Melalui lelaran berterusan, algoritma pensampelan bersarang boleh memperoleh nilai kamiran ketepatan tinggi dan sempadan ruang parameter, yang boleh digunakan untuk masalah statistik seperti perbandingan model, anggaran parameter, dan pemilihan model. Idea teras algoritma ini adalah untuk mengubah masalah penyepaduan kompleks kepada satu siri masalah penyepaduan mudah, dan mendekati nilai kamiran sebenar dengan mengurangkan jumlah ruang parameter secara beransur-ansur. Setiap langkah lelaran mengambil sampel secara rawak daripada ruang parameter
 Menganalisis prinsip, model dan komposisi Algoritma Carian Sparrow (SSA)
Jan 19, 2024 pm 10:27 PM
Menganalisis prinsip, model dan komposisi Algoritma Carian Sparrow (SSA)
Jan 19, 2024 pm 10:27 PM
Algoritma Carian Sparrow (SSA) ialah algoritma pengoptimuman meta-heuristik berdasarkan tingkah laku anti-pemangsaan dan mencari makan burung pipit. Tingkah laku mencari makan burung pipit boleh dibahagikan kepada dua jenis utama: pengeluar dan pemulung. Pengeluar secara aktif mencari makanan, manakala pemulung bersaing untuk mendapatkan makanan daripada pengeluar. Prinsip Algoritma Pencarian Sparrow (SSA) Dalam Algoritma Pencarian Sparrow (SSA), setiap burung pipit sangat memperhatikan tingkah laku jiran-jirannya. Dengan menggunakan strategi mencari makan yang berbeza, individu dapat menggunakan tenaga tertahan dengan cekap untuk mengejar lebih banyak makanan. Selain itu, burung lebih terdedah kepada pemangsa dalam ruang carian mereka, jadi mereka perlu mencari lokasi yang lebih selamat. Burung di tengah koloni boleh meminimumkan pelbagai bahaya mereka sendiri dengan tinggal dekat dengan jiran mereka. Apabila burung mengesan pemangsa, ia membuat panggilan penggera
 Apakah peranan perolehan maklumat dalam algoritma id3?
Jan 23, 2024 pm 11:27 PM
Apakah peranan perolehan maklumat dalam algoritma id3?
Jan 23, 2024 pm 11:27 PM
Algoritma ID3 adalah salah satu algoritma asas dalam pembelajaran pokok keputusan. Ia memilih titik perpecahan terbaik dengan mengira keuntungan maklumat setiap ciri untuk menjana pepohon keputusan. Keuntungan maklumat ialah konsep penting dalam algoritma ID3, yang digunakan untuk mengukur sumbangan ciri kepada tugas pengelasan. Artikel ini akan memperkenalkan secara terperinci konsep, kaedah pengiraan dan aplikasi perolehan maklumat dalam algoritma ID3. 1. Konsep entropi maklumat Entropi maklumat ialah konsep dalam teori maklumat, yang mengukur ketidakpastian pembolehubah rawak. Untuk nombor pembolehubah rawak diskret, dan p(x_i) mewakili kebarangkalian bahawa pembolehubah rawak X mengambil nilai x_i. surat
 Pengenalan kepada algoritma Wu-Manber dan arahan pelaksanaan Python
Jan 23, 2024 pm 07:03 PM
Pengenalan kepada algoritma Wu-Manber dan arahan pelaksanaan Python
Jan 23, 2024 pm 07:03 PM
Algoritma Wu-Manber ialah algoritma pemadanan rentetan yang digunakan untuk mencari rentetan dengan cekap. Ia adalah algoritma hibrid yang menggabungkan kelebihan algoritma Boyer-Moore dan Knuth-Morris-Pratt untuk menyediakan padanan corak yang pantas dan tepat. Langkah algoritma Wu-Manber 1. Cipta jadual cincang yang memetakan setiap subrentetan yang mungkin bagi corak ke kedudukan corak di mana subrentetan itu berlaku. 2. Jadual cincang ini digunakan untuk mengenal pasti potensi lokasi permulaan corak dalam teks dengan cepat. 3. Lelaran melalui teks dan bandingkan setiap aksara dengan aksara yang sepadan dalam corak. 4. Jika aksara sepadan, anda boleh beralih ke aksara seterusnya dan meneruskan perbandingan. 5. Jika aksara tidak sepadan, anda boleh menggunakan jadual cincang untuk menentukan watak berpotensi seterusnya dalam corak.
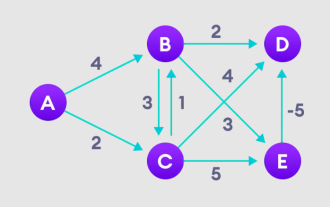 Penjelasan terperinci algoritma Bellman Ford dan pelaksanaan dalam Python
Jan 22, 2024 pm 07:39 PM
Penjelasan terperinci algoritma Bellman Ford dan pelaksanaan dalam Python
Jan 22, 2024 pm 07:39 PM
Algoritma Bellman Ford boleh mencari laluan terpendek dari nod sasaran ke nod lain dalam graf berwajaran. Ini sangat serupa dengan algoritma Dijkstra Algoritma Bellman-Ford boleh mengendalikan graf dengan pemberat negatif dan agak mudah dari segi pelaksanaan. Penjelasan terperinci tentang prinsip algoritma Bellman Ford Algoritma Bellman Ford secara lelaran mencari laluan baharu yang lebih pendek daripada laluan yang terlebih anggaran dengan membuat anggaran terlebih panjang laluan dari bucu permulaan kepada semua bucu lain. Kerana kita ingin merekodkan jarak laluan setiap nod, kita boleh menyimpannya dalam tatasusunan saiz n, di mana n juga mewakili bilangan nod. Contoh Rajah 1. Pilih nod permulaan, tetapkan ia kepada semua bucu lain tanpa terhingga, dan rekod nilai laluan. 2. Lawati setiap tepi dan lakukan operasi kelonggaran untuk mengemas kini laluan terpendek secara berterusan. 3. Kita perlukan
 Prinsip pengoptimuman berangka dan analisis Algoritma Pengoptimuman Paus (WOA)
Jan 19, 2024 pm 07:27 PM
Prinsip pengoptimuman berangka dan analisis Algoritma Pengoptimuman Paus (WOA)
Jan 19, 2024 pm 07:27 PM
Algoritma Pengoptimuman Paus (WOA) ialah algoritma pengoptimuman metaheuristik yang diilhamkan oleh alam semula jadi yang menyerupai tingkah laku memburu ikan paus bungkuk dan digunakan untuk pengoptimuman masalah berangka. Algoritma Pengoptimuman Paus (WOA) bermula dengan satu set penyelesaian rawak dan mengoptimumkan berdasarkan ejen carian yang dipilih secara rawak atau penyelesaian terbaik setakat ini melalui kemas kini kedudukan ejen carian dalam setiap lelaran. Inspirasi Algoritma Pengoptimuman Paus Algoritma Pengoptimuman Paus diinspirasikan oleh tingkah laku memburu ikan paus bungkuk. Paus bungkuk lebih suka makanan yang terdapat berhampiran permukaan, seperti krill dan kumpulan ikan. Oleh itu, paus bungkuk mengumpulkan makanan bersama-sama untuk membentuk rangkaian gelembung dengan meniup buih dalam lingkaran bawah ke atas semasa memburu. Dalam gerakan "lingkaran ke atas", ikan paus bungkuk menyelam kira-kira 12m, kemudian mula membentuk gelembung lingkaran di sekeliling mangsanya dan berenang ke atas.
 Algoritma Ciri Invarian Skala (SIFT).
Jan 22, 2024 pm 05:09 PM
Algoritma Ciri Invarian Skala (SIFT).
Jan 22, 2024 pm 05:09 PM
Algoritma Scale Invariant Feature Transform (SIFT) ialah algoritma pengekstrakan ciri yang digunakan dalam bidang pemprosesan imej dan penglihatan komputer. Algoritma ini telah dicadangkan pada tahun 1999 untuk meningkatkan pengecaman objek dan prestasi pemadanan dalam sistem penglihatan komputer. Algoritma SIFT adalah teguh dan tepat dan digunakan secara meluas dalam pengecaman imej, pembinaan semula tiga dimensi, pengesanan sasaran, penjejakan video dan medan lain. Ia mencapai invarian skala dengan mengesan titik utama dalam ruang skala berbilang dan mengekstrak deskriptor ciri tempatan di sekitar titik utama. Langkah-langkah utama algoritma SIFT termasuk pembinaan ruang skala, pengesanan titik utama, kedudukan titik utama, penetapan arah dan penjanaan deskriptor ciri. Melalui langkah-langkah ini, algoritma SIFT boleh mengekstrak ciri yang teguh dan unik, dengan itu mencapai pemprosesan imej yang cekap.
