
 pembangunan bahagian belakang
Tutorial Python
Alat analisis data Pandas: pelajari teknik penduaan dan tingkatkan kecekapan pemprosesan data
pembangunan bahagian belakang
Tutorial Python
Alat analisis data Pandas: pelajari teknik penduaan dan tingkatkan kecekapan pemprosesan data
Alat analisis data Pandas: pelajari teknik penduaan dan tingkatkan kecekapan pemprosesan data


Panda artifak pemprosesan data: Kuasai kaedah pendua dan tingkatkan kecekapan analisis data
[Pengenalan]
Dalam proses analisis data, kita sering menghadapi situasi di mana data mengandungi nilai pendua. Nilai pendua ini bukan sahaja akan menjejaskan ketepatan keputusan analisis data, tetapi juga mengurangkan kecekapan analisis. Untuk menyelesaikan masalah ini, Pandas menyediakan banyak kaedah deduplikasi yang boleh membantu kita menangani nilai pendua dengan cekap. Artikel ini akan memperkenalkan beberapa kaedah penyahduplikasian yang biasa digunakan dan menyediakan contoh kod khusus, dengan harapan dapat membantu semua orang menguasai keupayaan pemprosesan data Panda dengan lebih baik dan meningkatkan kecekapan analisis data.
【Umum】
Artikel ini akan memfokuskan pada aspek berikut:
- Mengalih keluar baris pendua
- Mengalih keluar lajur pendua
- Penyahduplikasian berdasarkan nilai lajur
- Penyahduplikasi berdasarkan syarat
- Alih keluar baris pendua
- Semasa proses analisis data, kami sering menghadapi situasi di mana baris yang sama dimasukkan dalam set data. Untuk mengalih keluar baris pendua ini, anda boleh menggunakan kaedah
drop_duplicates()dalam Panda. Berikut ialah contoh:drop_duplicates()方法。下面是一个示例:
import pandas as pd
# 创建数据集
data = {'A': [1, 2, 3, 4, 1],
'B': [5, 6, 7, 8, 5]}
df = pd.DataFrame(data)
# 去除重复行
df.drop_duplicates(inplace=True)
print(df)运行结果如下所示:
A B 0 1 5 1 2 6 2 3 7 3 4 8
- 去除重复列
有时候,我们可能会遇到数据集中包含相同列的情况。为了去除这些重复列,可以使用Pandas中的T属性和drop_duplicates()方法。下面是一个示例:
import pandas as pd
# 创建数据集
data = {'A': [1, 2, 3, 4, 5],
'B': [5, 6, 7, 8, 9],
'C': [1, 2, 3, 4, 5]}
df = pd.DataFrame(data)
# 去除重复列
df = df.T.drop_duplicates().T
print(df)运行结果如下所示:
A B 0 1 5 1 2 6 2 3 7 3 4 8 4 5 9
- 基于列值的去重
有时候,我们需要根据某一列的值来进行去重操作。可以使用Pandas中的duplicated()方法和~运算符来实现。下面是一个示例:
import pandas as pd
# 创建数据集
data = {'A': [1, 2, 3, 1, 2],
'B': [5, 6, 7, 8, 9]}
df = pd.DataFrame(data)
# 基于列A的值进行去重
df = df[~df['A'].duplicated()]
print(df)运行结果如下所示:
A B 0 1 5 1 2 6 2 3 7
- 基于条件的去重
有时候,在进行数据分析时,我们可能需要根据某些条件对数据进行去重操作。Pandas提供了drop_duplicates()方法的subset参数,可以实现基于条件的去重操作。下面是一个示例:
import pandas as pd
# 创建数据集
data = {'A': [1, 2, 3, 1, 2],
'B': [5, 6, 7, 8, 9]}
df = pd.DataFrame(data)
# 基于列B的值进行去重,但只保留A列值为1的行
df = df.drop_duplicates(subset=['B'], keep='first')
print(df)运行结果如下所示:
A B 0 1 5 1 2 6
- 基于索引的去重
有时候,在对数据进行处理时,我们可能会遇到索引重复的情况。Pandas提供了duplicated()和drop_duplicates()方法的keepimport pandas as pd # 创建数据集 data = {'A': [1, 2, 3, 4, 5]} df = pd.DataFrame(data, index=[1, 1, 2, 2, 3]) # 基于索引进行去重,保留最后一次出现的数值 df = df[~df.index.duplicated(keep='last')] print(df)Salin selepas log masukHasil larian adalah seperti berikut:
A 1 2 2 4 3 5
Alih keluar lajur pendua
Kadangkala, kita mungkin menghadapi situasi di mana set data mengandungi lajur yang sama. Untuk mengalih keluar lajur pendua ini, anda boleh menggunakan kaedahT dan drop_duplicates() dalam Panda. Berikut adalah contoh:
rrreee
- 🎜Penyahduplikasi berdasarkan nilai lajur🎜Kadangkala, kita perlu melakukan penyahduplikasian berdasarkan nilai lajur tertentu. Ini boleh dicapai menggunakan kaedah
duplicated() dan operator ~ dalam Pandas. Berikut adalah contoh: 🎜🎜rrreee🎜Hasil berjalan adalah seperti berikut: 🎜rrreee- 🎜Penyahduplikasi berasaskan keadaan🎜Kadangkala, semasa melakukan analisis data, kita mungkin perlu menganalisis data berdasarkan syarat tertentu Laksanakan operasi deduplikasi. Pandas menyediakan parameter
subset kaedah drop_duplicates(), yang boleh melaksanakan operasi penyahduaan berasaskan syarat. Berikut ialah contoh: 🎜🎜rrreee🎜Hasil larian adalah seperti berikut: 🎜rrreee- 🎜Penyahduplikasi berasaskan indeks🎜Kadangkala, semasa memproses data, kita mungkin menghadapi keadaan indeks pendua. Pandas menyediakan parameter
simpan kaedah duplicated() dan drop_duplicates(), yang boleh melaksanakan operasi penduaan berasaskan indeks. Berikut adalah contoh: 🎜🎜rrreee🎜Hasil larian adalah seperti berikut: 🎜rrreee🎜[Kesimpulan]🎜Melalui pengenalan dan contoh kod artikel ini, kita dapat melihat bahawa Pandas menyediakan banyak kaedah penyahduplikasian yang boleh membantu kita memprosesnya dengan cekap Menduakan nilai dalam data. Menguasai kaedah ini dapat meningkatkan kecekapan dalam proses analisis data dan memperoleh hasil analisis yang tepat. Saya harap artikel ini akan membantu semua orang untuk mempelajari keupayaan pemprosesan data Pandas. 🎜Atas ialah kandungan terperinci Alat analisis data Pandas: pelajari teknik penduaan dan tingkatkan kecekapan pemprosesan data. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1662
1662
 14
1418
52
1311
25
1261
29
1234
24
14
1418
52
1311
25
1261
29
1234
24

 Menyelesaikan masalah pemasangan panda biasa: tafsiran dan penyelesaian kepada ralat pemasangan
Feb 19, 2024 am 09:19 AM
Menyelesaikan masalah pemasangan panda biasa: tafsiran dan penyelesaian kepada ralat pemasangan
Feb 19, 2024 am 09:19 AM
Tutorial pemasangan Pandas: Analisis ralat pemasangan biasa dan penyelesaiannya, contoh kod khusus diperlukan Pengenalan: Pandas ialah alat analisis data yang berkuasa yang digunakan secara meluas dalam pembersihan data, pemprosesan data dan visualisasi data, jadi ia sangat dihormati dalam bidang sains data. Walau bagaimanapun, disebabkan oleh konfigurasi persekitaran dan isu pergantungan, anda mungkin menghadapi beberapa kesukaran dan ralat semasa memasang panda. Artikel ini akan memberi anda tutorial pemasangan panda dan menganalisis beberapa ralat pemasangan biasa serta penyelesaiannya. 1. Pasang panda
 Petua praktikal untuk membaca fail txt menggunakan panda
Jan 19, 2024 am 09:49 AM
Petua praktikal untuk membaca fail txt menggunakan panda
Jan 19, 2024 am 09:49 AM
Petua praktikal untuk membaca fail txt menggunakan panda, contoh kod khusus diperlukan Dalam analisis data dan pemprosesan data, fail txt ialah format data biasa. Menggunakan panda untuk membaca fail txt membolehkan pemprosesan data yang cepat dan mudah. Artikel ini akan memperkenalkan beberapa teknik praktikal untuk membantu anda menggunakan panda dengan lebih baik untuk membaca fail txt, bersama-sama dengan contoh kod tertentu. Baca fail txt dengan pembatas Apabila menggunakan panda untuk membaca fail txt dengan pembatas, anda boleh menggunakan read_c
 Mendedahkan kaedah penduaan data yang cekap dalam Pandas: Petua untuk mengalih keluar data pendua dengan cepat
Jan 24, 2024 am 08:12 AM
Mendedahkan kaedah penduaan data yang cekap dalam Pandas: Petua untuk mengalih keluar data pendua dengan cepat
Jan 24, 2024 am 08:12 AM
Rahsia kaedah deduplikasi Pandas: cara yang cepat dan cekap untuk menyahduplikasi data, yang memerlukan contoh kod khusus Dalam proses analisis dan pemprosesan data, duplikasi dalam data sering ditemui. Data pendua mungkin mengelirukan keputusan analisis, jadi penduaan adalah langkah yang sangat penting. Pandas, pustaka pemprosesan data yang berkuasa, menyediakan pelbagai kaedah untuk mencapai penyahduplikasian data Artikel ini akan memperkenalkan beberapa kaedah penyahduplikasian yang biasa digunakan, dan melampirkan contoh kod tertentu. Kes penduaan yang paling biasa berdasarkan satu lajur adalah berdasarkan sama ada nilai lajur tertentu diduakan.
 Tutorial pemasangan panda mudah: Panduan terperinci tentang cara memasang panda pada sistem pengendalian yang berbeza
Feb 21, 2024 pm 06:00 PM
Tutorial pemasangan panda mudah: Panduan terperinci tentang cara memasang panda pada sistem pengendalian yang berbeza
Feb 21, 2024 pm 06:00 PM
Tutorial pemasangan panda mudah: Panduan terperinci tentang cara memasang panda pada sistem pengendalian yang berbeza, contoh kod khusus diperlukan Memandangkan permintaan untuk pemprosesan dan analisis data terus meningkat, panda telah menjadi salah satu alat pilihan bagi ramai saintis data dan penganalisis. panda ialah pustaka pemprosesan dan analisis data yang berkuasa yang boleh memproses dan menganalisis sejumlah besar data berstruktur dengan mudah. Artikel ini akan memperincikan cara memasang panda pada sistem pengendalian yang berbeza dan memberikan contoh kod khusus. Pasang pada sistem pengendalian Windows
 Soalan Lazim untuk panda membaca fail txt
Jan 19, 2024 am 09:19 AM
Soalan Lazim untuk panda membaca fail txt
Jan 19, 2024 am 09:19 AM
Pandas ialah alat analisis data untuk Python, terutamanya sesuai untuk membersihkan, memproses dan menganalisis data. Semasa proses analisis data, kita selalunya perlu membaca fail data dalam pelbagai format, seperti fail Txt. Walau bagaimanapun, beberapa masalah akan dihadapi semasa operasi tertentu. Artikel ini akan memperkenalkan jawapan kepada soalan biasa tentang membaca fail txt dengan panda dan memberikan contoh kod yang sepadan. Soalan 1: Bagaimana untuk membaca fail txt? fail txt boleh dibaca menggunakan fungsi read_csv() panda. Ini kerana
 Panduan pemasangan untuk PythonPandas: mudah difahami dan dikendalikan
Jan 24, 2024 am 09:39 AM
Panduan pemasangan untuk PythonPandas: mudah difahami dan dikendalikan
Jan 24, 2024 am 09:39 AM
Panduan pemasangan PythonPandas yang ringkas dan mudah difahami PythonPandas ialah perpustakaan manipulasi dan analisis data yang berkuasa Ia menyediakan struktur data dan alat analisis data yang fleksibel dan mudah digunakan, dan merupakan salah satu alat penting untuk analisis data Python. Artikel ini akan memberikan anda panduan pemasangan PythonPandas yang ringkas dan mudah difahami untuk membantu anda memasang Panda dengan cepat, dan melampirkan contoh kod khusus untuk memudahkan anda memulakan. Memasang Python Sebelum memasang Panda, anda perlu terlebih dahulu
 Alat pemprosesan data: teknik yang cekap untuk membaca fail Excel dengan panda
Jan 19, 2024 am 08:58 AM
Alat pemprosesan data: teknik yang cekap untuk membaca fail Excel dengan panda
Jan 19, 2024 am 08:58 AM
Dengan peningkatan populariti pemprosesan data, semakin ramai orang memberi perhatian kepada cara menggunakan data dengan cekap dan menjadikan data berfungsi untuk diri mereka sendiri. Dalam pemprosesan data harian, jadual Excel sudah pasti format data yang paling biasa. Walau bagaimanapun, apabila sejumlah besar data perlu diproses, pengendalian Excel secara manual jelas akan menjadi sangat memakan masa dan susah payah. Oleh itu, artikel ini akan memperkenalkan alat pemprosesan data yang cekap - panda, dan cara menggunakan alat ini untuk membaca fail Excel dengan cepat dan melaksanakan pemprosesan data. 1. Pengenalan kepada panda panda
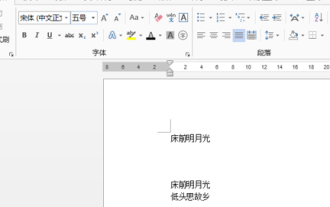 Bagaimana untuk membuang pendua dalam perkataan
Mar 20, 2024 pm 02:13 PM
Bagaimana untuk membuang pendua dalam perkataan
Mar 20, 2024 pm 02:13 PM
Kadang-kadang apabila kita menggunakan perisian pejabat perkataan untuk mengendalikan dan mengedit fail, sesetengah kandungan diulang. Mudah untuk mencari pendua dalam hamparan Excel, tetapi adakah anda akan menemui pendua dalam dokumen perkataan? Di bawah, kami akan berkongsi cara untuk mengalih keluar pendua dalam word, supaya anda boleh mencari kandungan pendua dengan cepat dan melakukan operasi penyuntingan. Mula-mula, buka dokumen Word baharu dan masukkan beberapa kandungan dalam dokumen tersebut. Pertimbangkan untuk memasukkan beberapa bahagian berulang untuk membantu menunjukkan operasi. 2. Untuk mencari kandungan pendua, kita perlu mengklik alat [Start]-[Search] dalam bar menu, pilih [Advanced Search] dalam menu drop-down, dan klik
