
 pembangunan bahagian belakang
Tutorial Python
Tangani masalah pengisihan data dengan mudah: panduan pengisihan panda yang ringkas dan mudah difahami
pembangunan bahagian belakang
Tutorial Python
Tangani masalah pengisihan data dengan mudah: panduan pengisihan panda yang ringkas dan mudah difahami
Tangani masalah pengisihan data dengan mudah: panduan pengisihan panda yang ringkas dan mudah difahami


Tutorial pengisihan panda yang ringkas dan mudah difahami: membolehkan anda menangani masalah pengisihan data dengan mudah, contoh kod khusus diperlukan
Dalam analisis dan pemprosesan data, selalunya perlu mengisih data agar lebih baik memahami ciri dan corak data . Dalam Python, perpustakaan panda adalah salah satu alat penting untuk analisis dan pemprosesan data. Tutorial ini menerangkan cara menggunakan panda untuk mengisih data dengan cepat dan fleksibel, serta menyediakan contoh kod khusus.
1. Konsep asas pengisihan data
Sebelum mengisih, kita perlu memahami konsep asas pengisihan data. Dalam panda, terdapat dua cara utama untuk mengisih data: mengisih mengikut baris dan mengisih mengikut lajur.
Isih mengikut baris: Isih keseluruhan baris data mengikut nilai lajur atau lajur tertentu. Ini dengan cepat boleh mengetahui kedudukan lajur atau lajur data tertentu.
Isih mengikut lajur: Isih keseluruhan lajur data mengikut saiz berangka. Ini menyusun data mengikut ciri tertentu, menjadikannya lebih mudah untuk difahami dan dianalisis.
2. Isih mengikut baris
1. Isih mengikut lajur tunggal
Pertama, kita perlu mencipta set data ringkas untuk menunjukkan proses pengisihan data.
import pandas as pd
data = {'姓名': ['张三', '李四', '王五', '赵六'],
'年龄': [25, 32, 28, 19],
'分数': [80, 90, 85, 75]}
df = pd.DataFrame(data)Seterusnya, kita boleh mengisih data menggunakan fungsi "sort_values". Secara lalai, fungsi ini mengisih tertib menaik mengikut lajur yang ditentukan.
df_sorted = df.sort_values(by='年龄') print(df_sorted)
Hasil larian adalah seperti berikut:
姓名 年龄 分数 3 赵六 19 75 0 张三 25 80 2 王五 28 85 1 李四 32 90
Anda boleh melihat bahawa selepas mengisih mengikut lajur "umur", data diisih dalam tertib menaik.
2 Isih mengikut berbilang lajur
Jika kita perlu mengisih mengikut berbilang lajur, kita hanya perlu menghantar berbilang nama lajur dalam parameter "mengikut".
df_sorted = df.sort_values(by=['年龄', '分数']) print(df_sorted)
Hasil larian adalah seperti berikut:
姓名 年龄 分数 3 赵六 19 75 0 张三 25 80 2 王五 28 85 1 李四 32 90
Anda dapat melihat bahawa data diisih terlebih dahulu mengikut lajur "umur", dan kemudian diisih mengikut lajur "skor".
3. Isih mengikut lajur
Isih mengikut lajur terutamanya mengisih keseluruhan lajur data mengikut saiz berangka untuk memahami dan menganalisis data dengan lebih baik.
1. Isih mengikut nama lajur
Kita boleh menggunakan fungsi "isih_indeks" untuk mengisih lajur. Secara lalai, fungsi ini mengisih mengikut abjad nama lajur.
df_sorted = df.sort_index(axis=1) print(df_sorted)
Hasil larian adalah seperti berikut:
分数 年龄 姓名 0 80 25 张三 1 90 32 李四 2 85 28 王五 3 75 19 赵六
Anda boleh melihat bahawa data disusun mengikut susunan abjad mengikut nama lajur "Skor", "Umur", dan "Nama".
2 Isih mengikut data lajur
Kita juga boleh mengisih berdasarkan saiz data lajur, hanya masukkan data lajur dalam parameter "mengikut".
df_sorted = df.sort_values(by='年龄', axis=1) print(df_sorted)
Hasil larian adalah seperti berikut:
姓名 分数 年龄 0 张三 80 25 1 李四 90 32 2 王五 85 28 3 赵六 75 19
Anda boleh melihat bahawa data diisih terlebih dahulu mengikut lajur "umur", dan kemudian diisih mengikut data lajur yang sepadan.
4. Parameter pengisihan lain
Selain kaedah pengisihan asas, panda juga menyediakan beberapa parameter pengisihan lain yang berguna, seperti pengisihan menaik, pengisihan menurun, pemprosesan nilai hilang, dsb.
Dalam fungsi "nilai_isih", kita boleh menggunakan parameter "menaik" untuk menentukan pengisihan menaik atau menurun. Secara lalai, parameter ini ialah "Benar", yang disusun dalam tertib menaik.
df_sorted = df.sort_values(by='年龄', ascending=False) print(df_sorted)
Keputusan larian adalah seperti berikut:
姓名 年龄 分数 1 李四 32 90 2 王五 28 85 0 张三 25 80 3 赵六 19 75
Anda boleh melihat bahawa data disusun mengikut tertib menurun mengikut lajur "umur".
Selain pengisihan menaik dan menurun, kami juga boleh mengendalikan nilai yang hilang semasa proses pengisihan. Dalam fungsi "sort_values", kita boleh menggunakan parameter "na_position" untuk menentukan cara nilai yang hilang dikendalikan. Secara lalai, parameter ini ialah "terakhir", yang mengisih nilai yang hilang terakhir apabila parameter ini ditetapkan kepada "pertama", ia mengisih nilai yang hilang dahulu.
data = {'姓名': ['张三', '李四', '王五', None],
'年龄': [25, None, 28, 19],
'分数': [80, 90, 85, 75]}
df = pd.DataFrame(data)
df_sorted = df.sort_values(by='年龄', na_position='first')
print(df_sorted)Hasil larian adalah seperti berikut:
姓名 年龄 分数 1 李四 NaN 90 3 None 19.0 75 0 张三 25.0 80 2 王五 28.0 85
Anda boleh melihat bahawa apabila mengisih mengikut lajur "umur", nilai yang hilang diletakkan dahulu.
Ringkasnya, tutorial ini memperkenalkan tutorial pengisihan panda yang ringkas dan mudah difahami, termasuk mengisih mengikut baris dan mengisih mengikut lajur serta menyediakan contoh kod khusus. Dengan mempelajari tutorial ini, saya percaya anda boleh menangani masalah pengisihan data dengan mudah dan menggunakannya secara fleksibel dalam analisis dan pemprosesan data.
Atas ialah kandungan terperinci Tangani masalah pengisihan data dengan mudah: panduan pengisihan panda yang ringkas dan mudah difahami. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1392
1392
 52
36
110
52
36
110

 Tutorial cara menggunakan Dewu
Mar 21, 2024 pm 01:40 PM
Tutorial cara menggunakan Dewu
Mar 21, 2024 pm 01:40 PM
Dewu APP pada masa ini merupakan perisian beli-belah jenama yang sangat popular, tetapi kebanyakan pengguna tidak tahu cara menggunakan fungsi dalam APP Dewu Panduan tutorial penggunaan yang paling terperinci Seterusnya, editor membawakan Dewuduo kepada pengguna tutorial. Pengguna yang berminat boleh datang dan lihat! Tutorial cara menggunakan Dewu [2024-03-20] Cara menggunakan pembelian ansuran Dewu [2024-03-20] Cara mendapatkan kupon Dewu [2024-03-20] Cara mencari perkhidmatan pelanggan manual Dewu [2024-03- 20] Cara menyemak kod pikap Dewu【2024-03-20】Di mana hendak mencari pembelian Dewu【2024-03-20】Cara membuka VIP Dewu【2024-03-20】Cara memohon pemulangan atau pertukaran Dewi
 Pada musim panas, anda mesti cuba menembak pelangi
Jul 21, 2024 pm 05:16 PM
Pada musim panas, anda mesti cuba menembak pelangi
Jul 21, 2024 pm 05:16 PM
Selepas hujan pada musim panas, anda sering dapat melihat pemandangan cuaca istimewa yang indah dan ajaib - pelangi. Ini juga merupakan pemandangan jarang yang boleh ditemui dalam fotografi, dan ia sangat fotogenik. Terdapat beberapa syarat untuk pelangi muncul: pertama, terdapat titisan air yang mencukupi di udara, dan kedua, matahari bersinar pada sudut yang lebih rendah. Oleh itu, adalah paling mudah untuk melihat pelangi pada sebelah petang selepas hujan reda. Walau bagaimanapun, pembentukan pelangi sangat dipengaruhi oleh cuaca, cahaya dan keadaan lain, jadi ia biasanya hanya bertahan untuk jangka masa yang singkat, dan masa tontonan dan penangkapan terbaik adalah lebih pendek. Jadi apabila anda menemui pelangi, bagaimanakah anda boleh merakamnya dengan betul dan mengambil gambar dengan kualiti? 1. Cari pelangi Selain keadaan yang dinyatakan di atas, pelangi biasanya muncul mengikut arah cahaya matahari, iaitu jika matahari bersinar dari barat ke timur, pelangi lebih cenderung muncul di timur.
 Tutorial tentang cara mematikan bunyi pembayaran di WeChat
Mar 26, 2024 am 08:30 AM
Tutorial tentang cara mematikan bunyi pembayaran di WeChat
Mar 26, 2024 am 08:30 AM
1. Mula-mula buka WeChat. 2. Klik [+] di penjuru kanan sebelah atas. 3. Klik kod QR untuk mengutip bayaran. 4. Klik tiga titik kecil di penjuru kanan sebelah atas. 5. Klik untuk menutup peringatan suara untuk ketibaan pembayaran.
 Apakah perisian photoshopcs5? -Tutorial penggunaan photoshopcs5
Mar 19, 2024 am 09:04 AM
Apakah perisian photoshopcs5? -Tutorial penggunaan photoshopcs5
Mar 19, 2024 am 09:04 AM
PhotoshopCS ialah singkatan daripada Photoshop Creative Suite Ia adalah perisian yang dihasilkan oleh Adobe Ia digunakan secara meluas dalam reka bentuk grafik dan pemprosesan imej Sebagai seorang pelajar baru yang belajar PS, hari ini biarkan editor menerangkan kepada anda apa itu perisian photoshopcs5. . 1. Apakah perisian photoshop cs5? Adobe Photoshop CS5 Extended sesuai untuk profesional dalam bidang filem, video dan multimedia, pereka grafik dan web yang menggunakan 3D dan animasi, dan profesional dalam bidang kejuruteraan dan saintifik. Paparkan imej 3D dan cantumkannya menjadi imej komposit 2D. Edit video dengan mudah
 Pakar mengajar anda! Cara Yang Betul untuk Memotong Gambar Panjang pada Telefon Mudah Alih Huawei
Mar 22, 2024 pm 12:21 PM
Pakar mengajar anda! Cara Yang Betul untuk Memotong Gambar Panjang pada Telefon Mudah Alih Huawei
Mar 22, 2024 pm 12:21 PM
Dengan perkembangan telefon pintar yang berterusan, fungsi telefon bimbit semakin berkuasa, antaranya fungsi mengambil gambar panjang menjadi salah satu fungsi penting yang digunakan oleh ramai pengguna dalam kehidupan seharian. Tangkapan skrin panjang boleh membantu pengguna menyimpan halaman web yang panjang, rekod perbualan atau gambar pada satu masa untuk memudahkan tontonan dan perkongsian. Di antara banyak jenama telefon bimbit, telefon bimbit Huawei juga merupakan salah satu jenama yang sangat dihormati oleh pengguna, dan fungsinya untuk memotong gambar panjang juga sangat dipuji. Artikel ini akan memperkenalkan anda kepada kaedah yang betul untuk mengambil gambar panjang pada telefon mudah alih Huawei, serta beberapa petua pakar untuk membantu anda menggunakan telefon mudah alih Huawei dengan lebih baik.
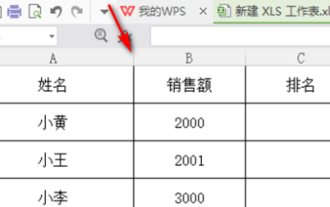 Bagaimana untuk mengisih markah WPS
Mar 20, 2024 am 11:28 AM
Bagaimana untuk mengisih markah WPS
Mar 20, 2024 am 11:28 AM
Dalam kerja kami, kami sering menggunakan perisian wps Terdapat banyak cara untuk memproses data dalam perisian wps, dan fungsinya juga sangat berkuasa Kami sering menggunakan fungsi untuk mencari purata, ringkasan, dan sebagainya kaedah yang boleh digunakan untuk data statistik telah disediakan untuk semua orang dalam perpustakaan perisian WPS Di bawah kami akan memperkenalkan langkah-langkah bagaimana untuk mengisih markah dalam WPS Selepas membaca ini, anda boleh belajar daripada pengalaman. 1. Mula-mula buka jadual yang perlu diberi ranking. Seperti yang ditunjukkan di bawah. 2. Kemudian masukkan formula =pangkat(B2, B2: B5, 0), dan pastikan anda memasukkan 0. Seperti yang ditunjukkan di bawah. 3. Selepas memasukkan formula, tekan kekunci F4 pada papan kekunci komputer Langkah ini adalah untuk menukar rujukan relatif kepada rujukan mutlak.
 Tutorial PHP: Bagaimana untuk menukar jenis int kepada rentetan
Mar 27, 2024 pm 06:03 PM
Tutorial PHP: Bagaimana untuk menukar jenis int kepada rentetan
Mar 27, 2024 pm 06:03 PM
Tutorial PHP: Cara Menukar Jenis Int kepada Rentetan Dalam PHP, menukar data integer kepada rentetan adalah operasi biasa. Tutorial ini akan memperkenalkan cara menggunakan fungsi terbina dalam PHP untuk menukar jenis int kepada rentetan, sambil memberikan contoh kod khusus. Gunakan cast: Dalam PHP, anda boleh menggunakan cast untuk menukar data integer kepada rentetan. Kaedah ini sangat mudah Anda hanya perlu menambah (rentetan) sebelum data integer untuk menukarnya menjadi rentetan. Di bawah ialah kod contoh mudah
 Tutorial peningkatan sistem Hongmeng telefon bimbit Honor
Mar 23, 2024 pm 12:45 PM
Tutorial peningkatan sistem Hongmeng telefon bimbit Honor
Mar 23, 2024 pm 12:45 PM
Telefon mudah alih Honor sentiasa digemari oleh pengguna kerana prestasi cemerlang dan sistem yang stabil. Baru-baru ini, telefon bimbit Honor telah mengeluarkan sistem Hongmeng baharu, yang telah menarik perhatian dan jangkaan ramai pengguna. Sistem Hongmeng dikenali sebagai sistem yang "menyatukan dunia". Ia mempunyai pengalaman operasi yang lebih lancar dan keselamatan yang lebih tinggi, membolehkan pengguna mengalami dunia telefon pintar yang serba baharu. Ramai pengguna telah menyatakan bahawa mereka ingin menaik taraf sistem telefon bimbit Honor mereka kepada sistem Hongmeng Jadi, mari kita lihat tutorial naik taraf sistem Hongmeng telefon bimbit Honor. pertama, saya
