

Langkah asas untuk membina rangkaian saraf konvolusi menggunakan PyTorch


Convolutional Neural Network (CNN) ialah model pembelajaran mendalam yang digunakan secara meluas dalam tugas penglihatan komputer. Berbanding dengan rangkaian saraf yang disambungkan sepenuhnya, CNN mempunyai lebih sedikit parameter dan keupayaan pengekstrakan ciri yang lebih berkuasa, dan berfungsi dengan baik dalam tugas seperti pengelasan imej, pengesanan sasaran dan pembahagian imej. Di bawah ini kami akan memperkenalkan cara membina model CNN asas.
Convolutional Neural Network (CNN) ialah model pembelajaran mendalam dengan berbilang lapisan konvolusi, lapisan gabungan, fungsi pengaktifan dan lapisan bersambung sepenuhnya. Lapisan konvolusi ialah komponen teras CNN dan digunakan untuk mengekstrak ciri imej input. Lapisan pengumpulan boleh mengurangkan saiz peta ciri dan mengekalkan ciri utama imej. Fungsi pengaktifan memperkenalkan transformasi tak linear untuk meningkatkan keupayaan ekspresif model. Lapisan yang disambungkan sepenuhnya menukar peta ciri kepada hasil keluaran. Dengan menggabungkan komponen ini, kita boleh membina rangkaian saraf konvolusi asas. CNN berfungsi dengan baik dalam tugas seperti klasifikasi imej, pengesanan sasaran, dan penjanaan imej, dan digunakan secara meluas dalam bidang penglihatan komputer.
Kedua, untuk struktur CNN, parameter setiap lapisan lilitan dan lapisan penyatuan perlu ditentukan. Parameter ini termasuk saiz isirong lilitan, bilangan isirung lilitan, dan saiz inti lilitan. Pada masa yang sama, ia juga perlu untuk menentukan dimensi data input dan dimensi data output. Pemilihan parameter ini biasanya perlu ditentukan secara eksperimen. Pendekatan biasa ialah membina model CNN yang mudah dahulu dan kemudian melaraskan parameter secara beransur-ansur sehingga prestasi optimum dicapai.
Apabila melatih model CNN, kita perlu menetapkan fungsi kehilangan dan pengoptimuman. Lazimnya, fungsi kehilangan entropi silang digunakan secara meluas, manakala pengoptimum turunan kecerunan stokastik juga merupakan pilihan biasa. Semasa proses latihan, kami memasukkan data latihan ke dalam model CNN secara berkelompok dan mengira nilai kerugian berdasarkan fungsi kerugian. Kemudian, gunakan pengoptimum untuk mengemas kini parameter model untuk mengurangkan nilai kerugian. Lazimnya, berbilang lelaran diperlukan untuk melengkapkan latihan, dengan setiap lelaran menggabungkan data latihan ke dalam model sehingga bilangan tempoh latihan yang telah ditetapkan dicapai atau kriteria prestasi tertentu dipenuhi.
Berikut ialah contoh kod untuk membina rangkaian neural convolutional asas (CNN) menggunakan PyTorch:
import torch
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5) # 3个输入通道,6个输出通道,5x5的卷积核
self.pool = nn.MaxPool2d(2, 2) # 2x2的最大池化层
self.conv2 = nn.Conv2d(6, 16, 5) # 6个输入通道,16个输出通道,5x5的卷积核
self.fc1 = nn.Linear(16 * 5 * 5, 120) # 全连接层1,输入大小为16x5x5,输出大小为120
self.fc2 = nn.Linear(120, 84) # 全连接层2,输入大小为120,输出大小为84
self.fc3 = nn.Linear(84, 10) # 全连接层3,输入大小为84,输出大小为10(10个类别)
def forward(self, x):
x = self.pool(torch.relu(self.conv1(x))) # 第一层卷积+激活函数+池化
x = self.pool(torch.relu(self.conv2(x))) # 第二层卷积+激活函数+池化
x = x.view(-1, 16 * 5 * 5) # 将特征图展开成一维向量
x = torch.relu(self.fc1(x)) # 第一层全连接+激活函数
x = torch.relu(self.fc2(x)) # 第二层全连接+激活函数
x = self.fc3(x) # 第三层全连接
return xKod di atas mentakrifkan kelas bernama Net, yang mewarisi daripada nn.Module. Kelas ini mengandungi lapisan konvolusi, lapisan pengumpulan dan lapisan bersambung sepenuhnya, serta kaedah ke hadapan, yang digunakan untuk menentukan proses perambatan ke hadapan model. Dalam kaedah __init__, kami mentakrifkan dua lapisan konvolusi, tiga lapisan bersambung sepenuhnya dan lapisan gabungan. Dalam kaedah ke hadapan, kami memanggil lapisan ini dalam turutan dan menggunakan fungsi pengaktifan ReLU untuk melakukan transformasi tak linear pada output lapisan konvolusi dan lapisan bersambung sepenuhnya. Akhir sekali, kami mengembalikan output lapisan terakhir yang disambungkan sepenuhnya sebagai ramalan model. Untuk menambah, input model CNN ini hendaklah berupa tensor empat dimensi dengan bentuk (saiz_kelompok, saluran, tinggi, lebar). Antaranya, batch_size ialah saiz kumpulan data input, saluran ialah bilangan saluran data input, dan ketinggian dan lebar ialah ketinggian dan lebar data input masing-masing. Dalam contoh ini, data input hendaklah imej warna RGB dengan kiraan saluran 3.
Atas ialah kandungan terperinci Langkah asas untuk membina rangkaian saraf konvolusi menggunakan PyTorch. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Terokai konsep, perbezaan, kebaikan dan keburukan RNN, LSTM dan GRU
Jan 22, 2024 pm 07:51 PM
Terokai konsep, perbezaan, kebaikan dan keburukan RNN, LSTM dan GRU
Jan 22, 2024 pm 07:51 PM
Dalam data siri masa, terdapat kebergantungan antara pemerhatian, jadi ia tidak bebas antara satu sama lain. Walau bagaimanapun, rangkaian saraf tradisional menganggap setiap pemerhatian sebagai bebas, yang mengehadkan keupayaan model untuk memodelkan data siri masa. Untuk menyelesaikan masalah ini, Rangkaian Neural Berulang (RNN) telah diperkenalkan, yang memperkenalkan konsep ingatan untuk menangkap ciri dinamik data siri masa dengan mewujudkan kebergantungan antara titik data dalam rangkaian. Melalui sambungan berulang, RNN boleh menghantar maklumat sebelumnya ke dalam pemerhatian semasa untuk meramalkan nilai masa hadapan dengan lebih baik. Ini menjadikan RNN alat yang berkuasa untuk tugasan yang melibatkan data siri masa. Tetapi bagaimanakah RNN mencapai ingatan seperti ini? RNN merealisasikan ingatan melalui gelung maklum balas dalam rangkaian saraf Ini adalah perbezaan antara RNN dan rangkaian saraf tradisional.
 Mengira operan titik terapung (FLOPS) untuk rangkaian saraf
Jan 22, 2024 pm 07:21 PM
Mengira operan titik terapung (FLOPS) untuk rangkaian saraf
Jan 22, 2024 pm 07:21 PM
FLOPS ialah salah satu piawaian untuk penilaian prestasi komputer, digunakan untuk mengukur bilangan operasi titik terapung sesaat. Dalam rangkaian saraf, FLOPS sering digunakan untuk menilai kerumitan pengiraan model dan penggunaan sumber pengkomputeran. Ia adalah penunjuk penting yang digunakan untuk mengukur kuasa pengkomputeran dan kecekapan komputer. Rangkaian saraf ialah model kompleks yang terdiri daripada berbilang lapisan neuron yang digunakan untuk tugas seperti klasifikasi data, regresi dan pengelompokan. Latihan dan inferens rangkaian saraf memerlukan sejumlah besar pendaraban matriks, konvolusi dan operasi pengiraan lain, jadi kerumitan pengiraan adalah sangat tinggi. FLOPS (FloatingPointOperationsperSecond) boleh digunakan untuk mengukur kerumitan pengiraan rangkaian saraf untuk menilai kecekapan penggunaan sumber pengiraan model. FLOP
 Kajian kes menggunakan model LSTM dwiarah untuk pengelasan teks
Jan 24, 2024 am 10:36 AM
Kajian kes menggunakan model LSTM dwiarah untuk pengelasan teks
Jan 24, 2024 am 10:36 AM
Model LSTM dwiarah ialah rangkaian saraf yang digunakan untuk pengelasan teks. Berikut ialah contoh mudah yang menunjukkan cara menggunakan LSTM dwiarah untuk tugasan pengelasan teks. Pertama, kita perlu mengimport perpustakaan dan modul yang diperlukan: importosimportnumpyasnpfromkeras.preprocessing.textimportTokenizerfromkeras.preprocessing.sequenceimportpad_sequencesfromkeras.modelsimportSequentialfromkeras.layersimportDense,Em
 Definisi dan analisis struktur rangkaian neural kabur
Jan 22, 2024 pm 09:09 PM
Definisi dan analisis struktur rangkaian neural kabur
Jan 22, 2024 pm 09:09 PM
Rangkaian saraf kabur ialah model hibrid yang menggabungkan logik kabur dan rangkaian saraf untuk menyelesaikan masalah kabur atau tidak pasti yang sukar dikendalikan dengan rangkaian saraf tradisional. Reka bentuknya diilhamkan oleh kekaburan dan ketidakpastian dalam kognisi manusia, jadi ia digunakan secara meluas dalam sistem kawalan, pengecaman corak, perlombongan data dan bidang lain. Seni bina asas rangkaian neural kabur terdiri daripada subsistem kabur dan subsistem saraf. Subsistem kabur menggunakan logik kabur untuk memproses data input dan menukarnya kepada set kabur untuk menyatakan kekaburan dan ketidakpastian data input. Subsistem saraf menggunakan rangkaian saraf untuk memproses set kabur untuk tugasan seperti pengelasan, regresi atau pengelompokan. Interaksi antara subsistem kabur dan subsistem saraf menjadikan rangkaian neural kabur mempunyai keupayaan pemprosesan yang lebih berkuasa dan boleh
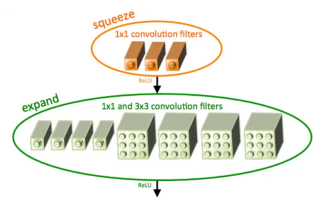 Pengenalan kepada SqueezeNet dan ciri-cirinya
Jan 22, 2024 pm 07:15 PM
Pengenalan kepada SqueezeNet dan ciri-cirinya
Jan 22, 2024 pm 07:15 PM
SqueezeNet ialah algoritma kecil dan tepat yang memberikan keseimbangan yang baik antara ketepatan tinggi dan kerumitan rendah, menjadikannya sesuai untuk sistem mudah alih dan terbenam dengan sumber terhad. Pada 2016, penyelidik dari DeepScale, University of California, Berkeley, dan Stanford University mencadangkan SqueezeNet, rangkaian neural convolutional (CNN) yang padat dan cekap. Dalam beberapa tahun kebelakangan ini, penyelidik telah membuat beberapa penambahbaikan pada SqueezeNet, termasuk SqueezeNetv1.1 dan SqueezeNetv2.0. Penambahbaikan dalam kedua-dua versi bukan sahaja meningkatkan ketepatan tetapi juga mengurangkan kos pengiraan. Ketepatan SqueezeNetv1.1 pada dataset ImageNet
 Penghapusan imej menggunakan rangkaian saraf konvolusi
Jan 23, 2024 pm 11:48 PM
Penghapusan imej menggunakan rangkaian saraf konvolusi
Jan 23, 2024 pm 11:48 PM
Rangkaian neural konvolusi berfungsi dengan baik dalam tugasan menghilangkan imej. Ia menggunakan penapis yang dipelajari untuk menapis bunyi dan dengan itu memulihkan imej asal. Artikel ini memperkenalkan secara terperinci kaedah denoising imej berdasarkan rangkaian neural convolutional. 1. Gambaran Keseluruhan Rangkaian Neural Konvolusi Rangkaian saraf konvolusi ialah algoritma pembelajaran mendalam yang menggunakan gabungan berbilang lapisan konvolusi, lapisan gabungan dan lapisan bersambung sepenuhnya untuk mempelajari dan mengelaskan ciri imej. Dalam lapisan konvolusi, ciri tempatan imej diekstrak melalui operasi konvolusi, dengan itu menangkap korelasi spatial dalam imej. Lapisan pengumpulan mengurangkan jumlah pengiraan dengan mengurangkan dimensi ciri dan mengekalkan ciri utama. Lapisan bersambung sepenuhnya bertanggungjawab untuk memetakan ciri dan label yang dipelajari untuk melaksanakan pengelasan imej atau tugas lain. Reka bentuk struktur rangkaian ini menjadikan rangkaian neural konvolusi berguna dalam pemprosesan dan pengecaman imej.
 Langkah-langkah untuk menulis rangkaian neural mudah menggunakan Rust
Jan 23, 2024 am 10:45 AM
Langkah-langkah untuk menulis rangkaian neural mudah menggunakan Rust
Jan 23, 2024 am 10:45 AM
Rust ialah bahasa pengaturcaraan peringkat sistem yang memfokuskan pada keselamatan, prestasi dan keselarasan. Ia bertujuan untuk menyediakan bahasa pengaturcaraan yang selamat dan boleh dipercayai yang sesuai untuk senario seperti sistem pengendalian, aplikasi rangkaian dan sistem terbenam. Keselamatan Rust datang terutamanya dari dua aspek: sistem pemilikan dan pemeriksa pinjaman. Sistem pemilikan membolehkan pengkompil menyemak kod untuk ralat memori pada masa penyusunan, dengan itu mengelakkan isu keselamatan memori biasa. Dengan memaksa menyemak pemindahan pemilikan berubah pada masa penyusunan, Rust memastikan sumber memori diurus dan dikeluarkan dengan betul. Penyemak pinjaman menganalisis kitaran hayat pembolehubah untuk memastikan pembolehubah yang sama tidak akan diakses oleh berbilang rangkaian pada masa yang sama, sekali gus mengelakkan isu keselamatan bersamaan yang biasa. Dengan menggabungkan kedua-dua mekanisme ini, Rust dapat menyediakan
 Rangkaian Neural Berkembar: Analisis Prinsip dan Aplikasi
Jan 24, 2024 pm 04:18 PM
Rangkaian Neural Berkembar: Analisis Prinsip dan Aplikasi
Jan 24, 2024 pm 04:18 PM
Rangkaian Neural Siam ialah struktur rangkaian saraf tiruan yang unik. Ia terdiri daripada dua rangkaian neural yang sama yang berkongsi parameter dan berat yang sama. Pada masa yang sama, kedua-dua rangkaian juga berkongsi data input yang sama. Reka bentuk ini diilhamkan oleh kembar, kerana kedua-dua rangkaian saraf adalah sama dari segi struktur. Prinsip rangkaian saraf Siam adalah untuk menyelesaikan tugas tertentu, seperti padanan imej, padanan teks dan pengecaman muka, dengan membandingkan persamaan atau jarak antara dua data input. Semasa latihan, rangkaian cuba untuk memetakan data yang serupa ke wilayah bersebelahan dan data yang tidak serupa ke wilayah yang jauh. Dengan cara ini, rangkaian boleh belajar cara mengklasifikasikan atau memadankan data yang berbeza dan mencapai yang sepadan
