

Kajian kes menggunakan model LSTM dwiarah untuk pengelasan teks


Model LSTM dwiarah ialah rangkaian saraf yang digunakan untuk pengelasan teks. Di bawah ialah contoh mudah yang menunjukkan cara menggunakan LSTM dwiarah untuk tugasan pengelasan teks.
Pertama, kita perlu mengimport perpustakaan dan modul yang diperlukan:
import os import numpy as np from keras.preprocessing.text import Tokenizer from keras.preprocessing.sequence import pad_sequences from keras.models import Sequential from keras.layers import Dense, Embedding, Bidirectional, LSTM from sklearn.model_selection import train_test_split
Seterusnya, kita perlu menyediakan set data. Di sini kami menganggap bahawa set data sudah wujud dalam laluan yang ditentukan dan mengandungi tiga fail: train.txt, dev.txt dan test.txt. Setiap fail mengandungi urutan teks dan tag yang sepadan. Kami boleh memuatkan set data menggunakan kod berikut:
def load_imdb_data(path):
assert os.path.exists(path)
trainset, devset, testset = [], [], []
with open(os.path.join(path, "train.txt"), "r") as fr:
for line in fr:
sentence_label, sentence = line.strip().lower().split("\t", maxsplit=1)
trainset.append((sentence, sentence_label))
with open(os.path.join(path, "dev.txt"), "r") as fr:
for line in fr:
sentence_label, sentence = line.strip().lower().split("\t", maxsplit=1)
devset.append((sentence, sentence_label))
with open(os.path.join(path, "test.txt"), "r") as fr:
for line in fr:
sentence_label, sentence = line.strip().lower().split("\t", maxsplit=1)
testset.append((sentence, sentence_label))
return trainset, devset, testsetSelepas memuatkan set data, kami boleh mempraproses dan menyusun teks. Di sini kami menggunakan Tokenizer untuk pembahagian teks, dan kemudian pad urutan indeks setiap perkataan pada panjang yang sama supaya ia boleh digunakan pada model LSTM.
max_features = 20000
maxlen = 80 # cut texts after this number of words (among top max_features most common words)
batch_size = 32
print('Pad & split data into training set and dev set')
x_train, y_train = [], []
for sent, label in trainset:
x_train.append(sent)
y_train.append(label)
x_train, y_train = pad_sequences(x_train, maxlen=maxlen), np.array(y_train)
x_train, y_train = np.array(x_train), np.array(y_train)
x_dev, y_dev = [], []
for sent, label in devset:
x_dev.append(sent)
y_dev.append(label)
x_dev, y_dev = pad_sequences(x_dev, maxlen=maxlen), np.array(y_dev)
x_dev, y_dev = np.array(x_dev), np.array(y_dev)Seterusnya, kita boleh membina model LSTM dua hala. Dalam model ini, kami menggunakan dua lapisan LSTM, satu untuk menghantar maklumat ke hadapan dan satu untuk menghantar maklumat ke belakang. Output dua lapisan LSTM ini digabungkan untuk membentuk vektor yang lebih berkuasa yang mewakili teks. Akhir sekali, kami menggunakan lapisan bersambung sepenuhnya untuk pengelasan.
print('Build model...') model = Sequential() model.add(Embedding(max_features, 128, input_length=maxlen)) model.add(Bidirectional(LSTM(64))) model.add(LSTM(64)) model.add(Dense(1, activation='sigmoid')) print('Compile model...') model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
Kini, kita boleh melatih model tersebut. Kami akan menggunakan set data dev sebagai data pengesahan untuk memastikan kami tidak terlalu muat semasa latihan.
epochs = 10 batch_size = 64 history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, validation_data=(x_dev, y_dev))
Selepas latihan selesai, kita boleh menilai prestasi model pada set ujian.
test_loss, test_acc = model.evaluate(x_test, y_test) print('Test accuracy:', test_acc)
Di atas ialah contoh pengelasan teks menggunakan model LSTM dua hala yang mudah. Anda juga boleh cuba melaraskan parameter model, seperti bilangan lapisan, bilangan neuron, pengoptimum, dsb., untuk mendapatkan prestasi yang lebih baik. Atau gunakan pembenaman perkataan yang telah dilatih (seperti Word2Vec atau GloVe) untuk menggantikan lapisan pembenaman untuk menangkap lebih banyak maklumat semantik.
Atas ialah kandungan terperinci Kajian kes menggunakan model LSTM dwiarah untuk pengelasan teks. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1393
1393
 52
37
110
52
37
110

 Terokai konsep, perbezaan, kebaikan dan keburukan RNN, LSTM dan GRU
Jan 22, 2024 pm 07:51 PM
Terokai konsep, perbezaan, kebaikan dan keburukan RNN, LSTM dan GRU
Jan 22, 2024 pm 07:51 PM
Dalam data siri masa, terdapat kebergantungan antara pemerhatian, jadi ia tidak bebas antara satu sama lain. Walau bagaimanapun, rangkaian saraf tradisional menganggap setiap pemerhatian sebagai bebas, yang mengehadkan keupayaan model untuk memodelkan data siri masa. Untuk menyelesaikan masalah ini, Rangkaian Neural Berulang (RNN) telah diperkenalkan, yang memperkenalkan konsep ingatan untuk menangkap ciri dinamik data siri masa dengan mewujudkan kebergantungan antara titik data dalam rangkaian. Melalui sambungan berulang, RNN boleh menghantar maklumat sebelumnya ke dalam pemerhatian semasa untuk meramalkan nilai masa hadapan dengan lebih baik. Ini menjadikan RNN alat yang berkuasa untuk tugasan yang melibatkan data siri masa. Tetapi bagaimanakah RNN mencapai ingatan seperti ini? RNN merealisasikan ingatan melalui gelung maklum balas dalam rangkaian saraf Ini adalah perbezaan antara RNN dan rangkaian saraf tradisional.
 Kajian kes menggunakan model LSTM dwiarah untuk pengelasan teks
Jan 24, 2024 am 10:36 AM
Kajian kes menggunakan model LSTM dwiarah untuk pengelasan teks
Jan 24, 2024 am 10:36 AM
Model LSTM dwiarah ialah rangkaian saraf yang digunakan untuk pengelasan teks. Berikut ialah contoh mudah yang menunjukkan cara menggunakan LSTM dwiarah untuk tugasan pengelasan teks. Pertama, kita perlu mengimport perpustakaan dan modul yang diperlukan: importosimportnumpyasnpfromkeras.preprocessing.textimportTokenizerfromkeras.preprocessing.sequenceimportpad_sequencesfromkeras.modelsimportSequentialfromkeras.layersimportDense,Em
 Mengira operan titik terapung (FLOPS) untuk rangkaian saraf
Jan 22, 2024 pm 07:21 PM
Mengira operan titik terapung (FLOPS) untuk rangkaian saraf
Jan 22, 2024 pm 07:21 PM
FLOPS ialah salah satu piawaian untuk penilaian prestasi komputer, digunakan untuk mengukur bilangan operasi titik terapung sesaat. Dalam rangkaian saraf, FLOPS sering digunakan untuk menilai kerumitan pengiraan model dan penggunaan sumber pengkomputeran. Ia adalah penunjuk penting yang digunakan untuk mengukur kuasa pengkomputeran dan kecekapan komputer. Rangkaian saraf ialah model kompleks yang terdiri daripada berbilang lapisan neuron yang digunakan untuk tugas seperti klasifikasi data, regresi dan pengelompokan. Latihan dan inferens rangkaian saraf memerlukan sejumlah besar pendaraban matriks, konvolusi dan operasi pengiraan lain, jadi kerumitan pengiraan adalah sangat tinggi. FLOPS (FloatingPointOperationsperSecond) boleh digunakan untuk mengukur kerumitan pengiraan rangkaian saraf untuk menilai kecekapan penggunaan sumber pengiraan model. FLOP
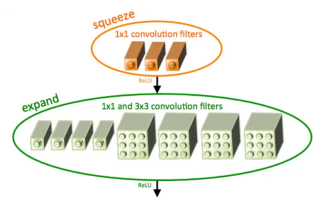 Pengenalan kepada SqueezeNet dan ciri-cirinya
Jan 22, 2024 pm 07:15 PM
Pengenalan kepada SqueezeNet dan ciri-cirinya
Jan 22, 2024 pm 07:15 PM
SqueezeNet ialah algoritma kecil dan tepat yang memberikan keseimbangan yang baik antara ketepatan tinggi dan kerumitan rendah, menjadikannya sesuai untuk sistem mudah alih dan terbenam dengan sumber terhad. Pada 2016, penyelidik dari DeepScale, University of California, Berkeley, dan Stanford University mencadangkan SqueezeNet, rangkaian neural convolutional (CNN) yang padat dan cekap. Dalam beberapa tahun kebelakangan ini, penyelidik telah membuat beberapa penambahbaikan pada SqueezeNet, termasuk SqueezeNetv1.1 dan SqueezeNetv2.0. Penambahbaikan dalam kedua-dua versi bukan sahaja meningkatkan ketepatan tetapi juga mengurangkan kos pengiraan. Ketepatan SqueezeNetv1.1 pada dataset ImageNet
 Definisi dan analisis struktur rangkaian neural kabur
Jan 22, 2024 pm 09:09 PM
Definisi dan analisis struktur rangkaian neural kabur
Jan 22, 2024 pm 09:09 PM
Rangkaian saraf kabur ialah model hibrid yang menggabungkan logik kabur dan rangkaian saraf untuk menyelesaikan masalah kabur atau tidak pasti yang sukar dikendalikan dengan rangkaian saraf tradisional. Reka bentuknya diilhamkan oleh kekaburan dan ketidakpastian dalam kognisi manusia, jadi ia digunakan secara meluas dalam sistem kawalan, pengecaman corak, perlombongan data dan bidang lain. Seni bina asas rangkaian neural kabur terdiri daripada subsistem kabur dan subsistem saraf. Subsistem kabur menggunakan logik kabur untuk memproses data input dan menukarnya kepada set kabur untuk menyatakan kekaburan dan ketidakpastian data input. Subsistem saraf menggunakan rangkaian saraf untuk memproses set kabur untuk tugasan seperti pengelasan, regresi atau pengelompokan. Interaksi antara subsistem kabur dan subsistem saraf menjadikan rangkaian neural kabur mempunyai keupayaan pemprosesan yang lebih berkuasa dan boleh
 Penghapusan imej menggunakan rangkaian saraf konvolusi
Jan 23, 2024 pm 11:48 PM
Penghapusan imej menggunakan rangkaian saraf konvolusi
Jan 23, 2024 pm 11:48 PM
Rangkaian neural konvolusi berfungsi dengan baik dalam tugasan menghilangkan imej. Ia menggunakan penapis yang dipelajari untuk menapis bunyi dan dengan itu memulihkan imej asal. Artikel ini memperkenalkan secara terperinci kaedah denoising imej berdasarkan rangkaian neural convolutional. 1. Gambaran Keseluruhan Rangkaian Neural Konvolusi Rangkaian saraf konvolusi ialah algoritma pembelajaran mendalam yang menggunakan gabungan berbilang lapisan konvolusi, lapisan gabungan dan lapisan bersambung sepenuhnya untuk mempelajari dan mengelaskan ciri imej. Dalam lapisan konvolusi, ciri tempatan imej diekstrak melalui operasi konvolusi, dengan itu menangkap korelasi spatial dalam imej. Lapisan pengumpulan mengurangkan jumlah pengiraan dengan mengurangkan dimensi ciri dan mengekalkan ciri utama. Lapisan bersambung sepenuhnya bertanggungjawab untuk memetakan ciri dan label yang dipelajari untuk melaksanakan pengelasan imej atau tugas lain. Reka bentuk struktur rangkaian ini menjadikan rangkaian neural konvolusi berguna dalam pemprosesan dan pengecaman imej.
 Bandingkan persamaan, perbezaan dan hubungan antara lilitan diluaskan dan lilitan atrus
Jan 22, 2024 pm 10:27 PM
Bandingkan persamaan, perbezaan dan hubungan antara lilitan diluaskan dan lilitan atrus
Jan 22, 2024 pm 10:27 PM
Konvolusi diluaskan dan lilitan diluaskan adalah operasi yang biasa digunakan dalam rangkaian neural konvolusi Artikel ini akan memperkenalkan perbezaan dan hubungannya secara terperinci. 1. Konvolusi diluaskan Konvolusi diluaskan, juga dikenali sebagai lilitan diluaskan atau lilitan diluaskan, ialah operasi dalam rangkaian neural konvolusi. Ia adalah lanjutan berdasarkan operasi lilitan tradisional dan meningkatkan medan penerimaan kernel lilitan dengan memasukkan lubang dalam kernel lilitan. Dengan cara ini, rangkaian boleh menangkap lebih banyak ciri yang lebih luas. Konvolusi dilatasi digunakan secara meluas dalam bidang pemprosesan imej dan boleh meningkatkan prestasi rangkaian tanpa menambah bilangan parameter dan jumlah pengiraan. Dengan meluaskan medan penerimaan kernel lilitan, lilitan diluaskan boleh memproses maklumat global dalam imej dengan lebih baik, sekali gus meningkatkan kesan pengekstrakan ciri. Idea utama lilitan diluaskan adalah untuk memperkenalkan beberapa
 rangkaian neural convolutional sebab
Jan 24, 2024 pm 12:42 PM
rangkaian neural convolutional sebab
Jan 24, 2024 pm 12:42 PM
Rangkaian neural convolutional kausal ialah rangkaian neural convolutional khas yang direka untuk masalah kausalitas dalam data siri masa. Berbanding dengan rangkaian neural convolutional konvensional, rangkaian neural convolutional kausal mempunyai kelebihan unik dalam mengekalkan hubungan kausal siri masa dan digunakan secara meluas dalam ramalan dan analisis data siri masa. Idea teras rangkaian neural convolutional kausal adalah untuk memperkenalkan kausalitas dalam operasi konvolusi. Rangkaian saraf konvolusional tradisional boleh melihat data secara serentak sebelum dan selepas titik masa semasa, tetapi dalam ramalan siri masa, ini mungkin membawa kepada masalah kebocoran maklumat. Kerana keputusan ramalan pada titik masa semasa akan dipengaruhi oleh data pada titik masa akan datang. Rangkaian saraf konvolusi penyebab menyelesaikan masalah ini Ia hanya dapat melihat titik masa semasa dan data sebelumnya, tetapi tidak dapat melihat data masa depan.
