
 Peranti teknologi
AI
TimePillars: Di manakah laluan pengesanan LiDAR 3D tulen boleh dilanjutkan? Liputan langsung 200m!
Peranti teknologi
AI
TimePillars: Di manakah laluan pengesanan LiDAR 3D tulen boleh dilanjutkan? Liputan langsung 200m!
TimePillars: Di manakah laluan pengesanan LiDAR 3D tulen boleh dilanjutkan? Liputan langsung 200m!

Pengesanan Objek 3D berdasarkan awan titik LiDAR adalah masalah yang sangat klasik, kedua-dua ahli akademik dan industri telah mencadangkan pelbagai model untuk meningkatkan ketepatan, kelajuan dan keteguhan. Walau bagaimanapun, disebabkan persekitaran luar yang kompleks, prestasi Pengesanan Objek untuk awan titik luar tidak begitu baik. Awan titik Lidar bersifat jarang Bagaimana untuk menyelesaikan masalah ini dengan cara yang disasarkan? Kertas itu memberikan jawapannya sendiri: mengekstrak maklumat berdasarkan pengagregatan maklumat siri masa. . Ini penting untuk memastikan kebolehpercayaan dan keselamatan kenderaan autonomi. Khususnya, kenderaan autonomi perlu dapat mengenali objek sekeliling, seperti kenderaan dan pejalan kaki, dan menentukan lokasi, saiz dan orientasinya dengan tepat. Biasanya, orang menggunakan rangkaian saraf dalam untuk memproses data LiDAR untuk menyelesaikan tugas ini.
Penyelidikan semasa tertumpu terutamanya pada kaedah bingkai tunggal, iaitu menggunakan data daripada satu imbasan sensor pada satu masa. Kaedah ini berfungsi dengan baik pada penanda aras klasik, mengesan objek pada jarak sehingga 75 meter. Walau bagaimanapun, jarang awan titik lidar amat ketara pada julat yang jauh. Oleh itu, penyelidik percaya bahawa bergantung semata-mata pada satu imbasan untuk pengesanan jarak jauh tidak mencukupi, contohnya, sehingga jarak 200 meter. Oleh itu, penyelidikan masa depan perlu memberi tumpuan kepada menangani cabaran ini. Untuk menyelesaikan masalah ini, salah satu caranya ialah menggunakan pengagregatan awan titik, iaitu menggabungkan satu siri data imbasan lidar untuk mendapatkan input yang lebih padat. Walau bagaimanapun, pendekatan ini adalah mahal dari segi pengiraan dan tidak memanfaatkan sepenuhnya pengagregatan dalam rangkaian. Untuk mengurangkan kos pengiraan dan menggunakan maklumat dengan lebih baik, pertimbangkan untuk menggunakan kaedah rekursif. Kaedah rekursif mengumpul maklumat dari semasa ke semasa dan menghasilkan output yang lebih tepat dengan menggabungkan input semasa secara berulang dengan hasil agregat sebelumnya. Kaedah ini bukan sahaja dapat meningkatkan kecekapan pengiraan, tetapi juga menggunakan maklumat sejarah dengan berkesan untuk meningkatkan ketepatan ramalan. Kaedah rekursif mempunyai aplikasi yang luas dalam masalah pengagregatan awan titik dan telah mencapai hasil yang memuaskan.
Artikel itu juga menyebut bahawa untuk meningkatkan julat pengesanan, beberapa operasi lanjutan boleh digunakan, seperti lilitan jarang, modul perhatian dan lilitan 3D. Walau bagaimanapun, operasi ini biasanya mengabaikan isu keserasian perkakasan sasaran. Apabila menggunakan dan melatih rangkaian saraf, perkakasan yang digunakan selalunya berbeza dengan ketara dalam operasi dan kependaman yang disokong. Contohnya, perkakasan sasaran seperti Nvidia Orin DLA selalunya tidak menyokong operasi seperti lilitan atau perhatian yang jarang. Selain itu, menggunakan lapisan seperti lilitan 3D selalunya tidak dapat dilaksanakan kerana keperluan kependaman masa nyata. Ini menekankan keperluan untuk menggunakan operasi mudah seperti lilitan 2D. 
Penjelasan terperinci tentang TimePillars
Input prapemprosesan
Dalam bahagian "Input Praprocessing" kertas ini, penulis menggunakan teknik yang dipanggil "pillarization" untuk memproses data awan titik input. Berbeza daripada vokselisasi konvensional, kaedah ini membahagikan awan titik ke dalam struktur kolumnar menegak, membahagikan hanya dalam arah mendatar (paksi x dan y) sambil mengekalkan ketinggian tetap dalam arah menegak (paksi z). Kelebihan kaedah pemprosesan ini ialah ia dapat mengekalkan ketekalan saiz input rangkaian dan boleh menggunakan lilitan 2D untuk pemprosesan yang cekap. Dengan cara ini, data awan titik boleh diproses dengan cekap, memberikan input yang lebih tepat dan boleh dipercayai untuk tugasan seterusnya.
Walau bagaimanapun, satu masalah dengan Pilarisasi ialah ia menghasilkan banyak lajur kosong, mengakibatkan data yang sangat jarang. Untuk menyelesaikan masalah ini, makalah ini mencadangkan penggunaan teknologi voxelisasi dinamik. Teknik ini mengelakkan keperluan untuk mempunyai bilangan mata yang telah ditetapkan untuk setiap lajur, dengan itu menghapuskan keperluan untuk operasi pemotongan atau pengisian pada setiap lajur. Sebaliknya, keseluruhan data awan titik diproses secara keseluruhan untuk memadankan jumlah mata yang diperlukan, di sini ditetapkan kepada 200,000 mata. Faedah kaedah prapemprosesan ini ialah ia meminimumkan kehilangan maklumat dan menjadikan perwakilan data yang dijana lebih stabil dan konsisten.
Seni bina model
Kemudian untuk seni bina Model, penulis memperkenalkan secara terperinci seni bina rangkaian saraf yang terdiri daripada pengekod ciri tiang (Pillar Feature Encoder), tulang belakang rangkaian neural convolutional (CNN) 2D dan kepala pengesan.
- Pillar Feature Encoder: Bahagian ini memetakan tensor input praproses ke dalam imej pseudo Bird's Eye View (BEV). Selepas menggunakan vokselisasi dinamik, PointNet yang dipermudahkan dilaraskan dengan sewajarnya. Input diproses oleh lilitan 1D, normalisasi kelompok dan fungsi pengaktifan ReLU, menghasilkan tensor dengan bentuk , di mana mewakili bilangan saluran. Sebelum lapisan maksimum serakan terakhir, pengumpulan maksimum digunakan pada saluran, membentuk ruang terpendam bentuk . Oleh kerana tensor awal dikodkan sebagai , yang menjadi selepas lapisan sebelumnya, operasi pengumpulan maksimum dialih keluar.
- Backbone: Menggunakan seni bina tulang belakang CNN 2D yang dicadangkan dalam kertas kolumnar asal kerana kecekapan kedalaman yang unggul. Ruang terpendam dikurangkan menggunakan tiga blok pensampelan rendah (Conv2D-BN-ReLU) dan dipulihkan menggunakan tiga blok pensampelan naik dan lilitan terbalik, dengan bentuk keluaran .
- Unit Memori: Modelkan memori sistem sebagai rangkaian saraf berulang (RNN), khususnya menggunakan GRU (convGRU), yang merupakan versi konvolusi bagi Unit Berulang Berpagar. Kelebihan GRU konvolusi ialah ia mengelakkan masalah kecerunan yang hilang dan meningkatkan kecekapan sambil mengekalkan ciri data spatial. Berbanding dengan pilihan lain seperti LSTM, GRU mempunyai lebih sedikit parameter boleh dilatih kerana bilangan getnya yang lebih kecil dan boleh dianggap sebagai teknik regularisasi memori (mengurangkan kerumitan keadaan tersembunyi). Dengan menggabungkan operasi yang serupa, bilangan lapisan konvolusi yang diperlukan dikurangkan, menjadikan unit lebih cekap.
- Kepala Pengesan: Pengubahsuaian ringkas kepada SSD (Pengesan MultiBox Pukulan Tunggal). Konsep teras SSD dikekalkan, iaitu pas tunggal tanpa cadangan wilayah, tetapi penggunaan kotak sauh dihapuskan. Mengeluarkan ramalan secara langsung untuk setiap sel dalam grid, walaupun kehilangan keupayaan pengesanan berbilang objek sel, mengelakkan pelarasan parameter kotak anchor yang membosankan dan selalunya tidak tepat dan memudahkan proses inferens. Lapisan linear mengendalikan keluaran klasifikasi dan penyetempatan (kedudukan, saiz dan sudut) regresi masing-masing. Hanya saiz yang menggunakan fungsi pengaktifan (ReLU) untuk mengelakkan mengambil nilai negatif. Di samping itu, tidak seperti kesusasteraan berkaitan, makalah ini mengelakkan masalah regresi sudut langsung dengan meramalkan komponen sinus dan kosinus arah pemanduan kenderaan secara bebas dan mengekstrak sudut daripadanya.
Ciri Pampasan Ego-Motion
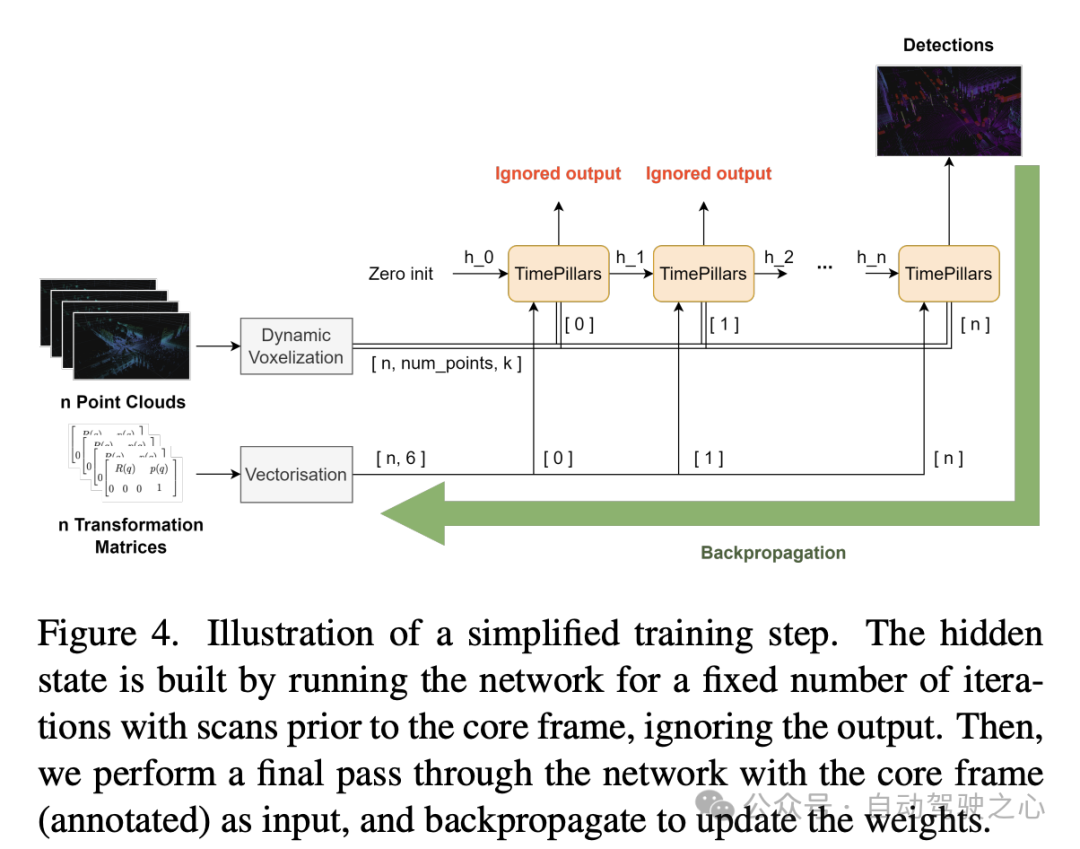
Dalam bahagian kertas ini, penulis membincangkan cara memproses output ciri keadaan tersembunyi oleh GRU konvolusi, yang diwakili oleh sistem koordinat bingkai sebelumnya. Jika disimpan terus dan digunakan untuk mengira ramalan seterusnya, ketidakpadanan spatial akan berlaku disebabkan oleh pergerakan ego.
Untuk penukaran, teknik yang berbeza boleh digunakan. Sebaik-baiknya, data yang diperbetulkan akan dimasukkan ke dalam rangkaian dan bukannya diubah dalam rangkaian. Walau bagaimanapun, ini bukan kaedah yang dicadangkan dalam kertas itu, kerana ia memerlukan penetapan semula keadaan tersembunyi pada setiap langkah dalam proses inferens, mengubah awan titik sebelumnya dan menyebarkannya ke seluruh rangkaian. Ini bukan sahaja tidak cekap, ia mengalahkan tujuan menggunakan RNN. Oleh itu, dalam konteks gelung, pampasan perlu dilakukan pada peringkat ciri. Ini menjadikan penyelesaian hipotesis lebih cekap, tetapi juga menjadikan masalah lebih kompleks. Kaedah interpolasi tradisional boleh digunakan untuk mendapatkan ciri dalam sistem koordinat yang diubah.
Sebaliknya, diilhamkan oleh kerja Chen et al., kertas kerja itu mencadangkan untuk menggunakan operasi konvolusi dan tugas tambahan untuk melaksanakan transformasi. Memandangkan butiran terhad bagi kerja yang disebutkan di atas, kertas kerja mencadangkan penyelesaian tersuai untuk masalah ini.
Pendekatan yang diambil oleh kertas itu adalah untuk menyediakan rangkaian dengan maklumat yang diperlukan untuk melakukan transformasi ciri melalui lapisan konvolusi tambahan. Matriks penjelmaan relatif antara dua bingkai berturut-turut mula-mula dikira, iaitu operasi yang diperlukan untuk berjaya mengubah ciri. Kemudian, ekstrak maklumat 2D (bahagian putaran dan terjemahan) daripadanya:
Pemudahan ini mengelakkan pemalar matriks utama dan berfungsi dalam domain 2D (imej pseudo), mengurangkan 16 nilai kepada 6. Matriks kemudiannya diratakan dan dibesarkan untuk dipadankan dengan bentuk ciri tersembunyi untuk diberi pampasan. Dimensi pertama mewakili bilangan bingkai yang perlu ditukar. Perwakilan ini menjadikannya sesuai untuk menggabungkan setiap tiang berpotensi dalam dimensi saluran ciri tersembunyi.
Akhir sekali, ciri keadaan tersembunyi dimasukkan ke dalam lapisan konvolusi 2D, yang disesuaikan dengan proses transformasi. Aspek utama yang perlu diberi perhatian ialah melakukan konvolusi tidak menjamin bahawa transformasi akan berlaku. Penggabungan saluran hanya menyediakan rangkaian maklumat tambahan tentang cara transformasi mungkin dilakukan. Dalam hal ini, penggunaan pembelajaran berbantu adalah sesuai. Semasa latihan, objektif pembelajaran tambahan (transformasi koordinat) ditambah selari dengan objektif utama (pengesan objek). Tugas tambahan direka bentuk yang tujuannya adalah untuk membimbing rangkaian melalui proses transformasi di bawah penyeliaan untuk memastikan ketepatan pampasan Tugas tambahan adalah terhad kepada proses latihan. Setelah rangkaian belajar mengubah ciri dengan betul, ia kehilangan kebolehgunaannya. Oleh itu, tugasan ini tidak dipertimbangkan semasa inferens. Dalam bahagian seterusnya eksperimen lanjut akan dijalankan untuk membandingkan kesannya.
Eksperimen
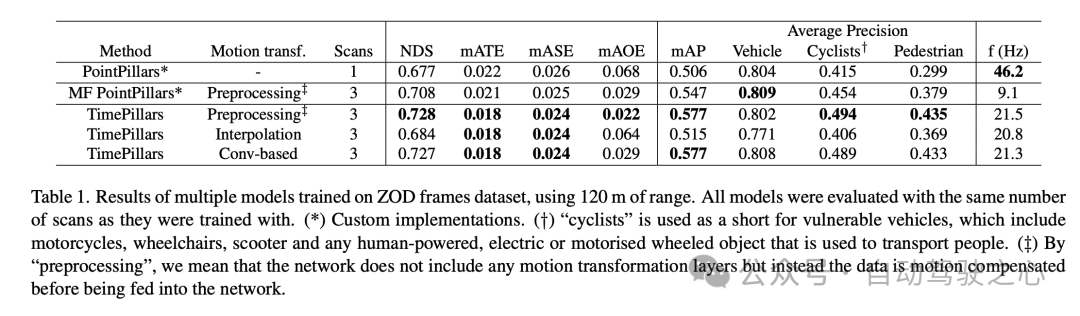
Hasil eksperimen menunjukkan bahawa model TimePillars berprestasi baik apabila memproses set data bingkai Zenseact Open Dataset (ZOD), terutamanya apabila memproses julat sehingga 120 meter. Keputusan ini menyerlahkan perbezaan prestasi TimePillars di bawah kaedah transformasi gerakan yang berbeza dan bandingkan dengan kaedah lain.
Selepas membandingkan PointPillars model garis dasar dan PointPillars berbilang bingkai (MF), dapat dilihat bahawa TimePillars telah mencapai peningkatan yang ketara dalam berbilang penunjuk prestasi utama. Terutama pada Skor Pengesanan NuScenes (NDS), TimePillars menunjukkan skor keseluruhan yang lebih tinggi, mencerminkan kelebihannya dalam prestasi pengesanan dan ketepatan kedudukan. Selain itu, TimePillars juga mencapai nilai yang lebih rendah dalam ralat penukaran purata (mATE), ralat skala purata (mASE) dan ralat orientasi purata (mAOE), menunjukkan bahawa ia lebih tepat dalam ketepatan kedudukan dan anggaran orientasi. Nota khusus ialah pelaksanaan TimePillars yang berbeza dari segi penukaran gerakan mempunyai kesan yang signifikan terhadap prestasi. Apabila menggunakan transformasi gerakan berasaskan lilitan (berasaskan Conv), TimePillars berprestasi baik pada NDS, mATE, mASE dan mAOE, membuktikan keberkesanan kaedah ini dalam pampasan gerakan dan meningkatkan ketepatan pengesanan. Sebaliknya, TimePillars menggunakan kaedah interpolasi juga mengatasi model garis dasar, tetapi lebih rendah daripada kaedah konvolusi dalam beberapa penunjuk. Keputusan ketepatan purata (mAP) menunjukkan bahawa TimePillars berprestasi baik dalam pengesanan kategori kenderaan, penunggang basikal dan pejalan kaki, terutamanya apabila berhadapan dengan kategori yang lebih mencabar seperti penunggang basikal dan pejalan kaki, peningkatan prestasinya adalah lebih ketara. Dari perspektif kekerapan pemprosesan (f (Hz)), walaupun TimePillars tidak sepantas PointPillars bingkai tunggal, ia lebih pantas daripada PointPillars berbilang bingkai sambil mengekalkan prestasi pengesanan yang tinggi. Ini menunjukkan bahawa TimePillars boleh melakukan pengesanan jarak jauh dan pampasan gerakan dengan berkesan sambil mengekalkan pemprosesan masa nyata. Dalam erti kata lain, model TimePillars menunjukkan kelebihan ketara dalam pengesanan jarak jauh, pampasan gerakan dan kelajuan pemprosesan, terutamanya apabila memproses data berbilang bingkai dan menggunakan teknologi penukaran gerakan berasaskan konvolusi. Keputusan ini menyerlahkan potensi aplikasi TimePillars dalam bidang pengesanan objek lidar 3D untuk kenderaan autonomi.

Keputusan percubaan di atas menunjukkan bahawa model TimePillars berprestasi cemerlang dalam prestasi pengesanan objek dalam julat jarak yang berbeza, terutamanya berbanding dengan model penanda aras PointPillars. Keputusan ini dibahagikan kepada tiga julat pengesanan utama: 0 hingga 50 meter, 50 hingga 100 meter dan ke atas 100 meter.
Pertama sekali, NuScenes Detection Score (NDS) dan Average Precision (mAP) ialah penunjuk prestasi keseluruhan. TimePillars mengatasi PointPillars pada kedua-dua metrik, menunjukkan keseluruhan keupayaan pengesanan yang lebih tinggi dan ketepatan kedudukan. Secara khusus, TimePillars' NDS ialah 0.723, yang jauh lebih tinggi daripada PointPillars' 0.657 dari segi mAP, TimePillars juga dengan ketara mengatasi PointPillars' 0.475 dengan 0.570.
Dalam perbandingan prestasi dalam julat jarak yang berbeza, dapat dilihat bahawa TimePillars berprestasi lebih baik dalam setiap julat. Bagi kategori kenderaan, ketepatan pengesanan TimePillars dalam julat 0 hingga 50 meter, 50 hingga 100 meter dan lebih 100 meter masing-masing ialah 0.884, 0.776 dan 0.591, yang semuanya lebih tinggi daripada prestasi PointPillars dalam julat yang sama. Ini menunjukkan bahawa TimePillars mempunyai ketepatan yang lebih tinggi dalam pengesanan kenderaan, baik pada jarak dekat dan jauh. TimePillars juga menunjukkan prestasi pengesanan yang lebih baik apabila berurusan dengan kenderaan yang terdedah (seperti motosikal, kerusi roda, skuter elektrik, dsb.). Terutamanya dalam julat lebih daripada 100 meter, ketepatan pengesanan TimePillars ialah 0.178, manakala PointPillars hanya 0.036, menunjukkan kelebihan ketara dalam pengesanan jarak jauh. Bagi pengesanan pejalan kaki, TimePillars juga menunjukkan prestasi yang lebih baik, terutamanya dalam julat 50 hingga 100 meter, dengan ketepatan pengesanan 0.350, manakala PointPillars hanya 0.211. Walaupun pada jarak yang lebih jauh (lebih 100 meter), TimePillars masih mencapai tahap pengesanan tertentu (ketepatan 0.032), manakala PointPillars melakukan sifar pada julat ini.
Keputusan percubaan ini menyerlahkan prestasi unggul TimePillars dalam mengendalikan tugas pengesanan objek dalam julat jarak yang berbeza. Sama ada pada jarak dekat atau pada jarak jauh yang lebih mencabar, TimePillars memberikan hasil pengesanan yang lebih tepat dan boleh dipercayai, yang penting untuk keselamatan dan kecekapan kenderaan autonomi.
Perbincangan

Pertama sekali, kelebihan utama model TimePillars ialah keberkesanannya untuk pengesanan objek jarak jauh. Dengan menggunakan vokselisasi dinamik dan struktur GRU konvolusi, model ini lebih mampu mengendalikan data lidar yang jarang, terutamanya dalam pengesanan objek jarak jauh. Ini penting untuk operasi selamat kenderaan autonomi dalam persekitaran jalan yang kompleks dan berubah-ubah. Di samping itu, model ini juga menunjukkan prestasi yang baik dari segi kelajuan pemprosesan, yang penting untuk aplikasi masa nyata. Sebaliknya, TimePillars menggunakan kaedah berasaskan konvolusi untuk Pampasan Pergerakan, yang merupakan peningkatan besar berbanding kaedah tradisional. Pendekatan ini memastikan ketepatan transformasi melalui tugas tambahan semasa latihan, meningkatkan ketepatan model semasa mengendalikan objek bergerak.
Walau bagaimanapun, penyelidikan kertas ini juga mempunyai beberapa batasan. Pertama, sementara TimePillars berprestasi baik dalam mengendalikan pengesanan objek jauh, peningkatan prestasi ini mungkin berlaku dengan mengorbankan beberapa kelajuan pemprosesan. Walaupun kelajuan model masih sesuai untuk aplikasi masa nyata, ia masih berkurangan berbanding kaedah bingkai tunggal. Di samping itu, kertas kerja ini tertumpu terutamanya pada data LiDAR dan tidak mempertimbangkan input sensor lain, seperti kamera atau radar, yang mungkin mengehadkan penggunaan model dalam persekitaran berbilang penderia yang lebih kompleks.
Maksudnya, TimePillars telah menunjukkan kelebihan ketara dalam pengesanan objek lidar 3D untuk kenderaan autonomi, terutamanya dalam pengesanan jarak jauh dan Pampasan Pergerakan. Walaupun terdapat sedikit pertukaran dalam kelajuan pemprosesan dan had dalam memproses data berbilang sensor, TimePillars masih mewakili kemajuan penting dalam bidang ini.
Kesimpulan
Kerja ini menunjukkan bahawa mempertimbangkan data sensor lepas adalah lebih baik daripada hanya memanfaatkan maklumat semasa. Mengakses maklumat persekitaran pemanduan terdahulu boleh mengatasi sifat jarang awan titik lidar dan membawa kepada ramalan yang lebih tepat. Kami menunjukkan bahawa rangkaian berulang sesuai sebagai cara untuk mencapai yang terakhir. Pemberian memori sistem membawa kepada penyelesaian yang lebih mantap berbanding kaedah pengagregatan awan titik yang mencipta perwakilan data yang lebih padat melalui pemprosesan yang meluas. Kaedah yang kami cadangkan, TimePillars, melaksanakan cara untuk menyelesaikan masalah rekursif. Dengan hanya menambah tiga lapisan konvolusional tambahan pada proses inferens, kami menunjukkan bahawa blok binaan rangkaian asas adalah mencukupi untuk mencapai hasil yang ketara dan memastikan kecekapan sedia ada dan spesifikasi penyepaduan perkakasan dipenuhi. Untuk pengetahuan terbaik kami, kerja ini menyediakan hasil penanda aras pertama untuk tugas pengesanan objek 3D pada set data terbuka Zenseact yang baru diperkenalkan. Kami berharap kerja kami dapat menyumbang kepada jalan raya yang lebih selamat dan lebih mampan pada masa hadapan.
Atas ialah kandungan terperinci TimePillars: Di manakah laluan pengesanan LiDAR 3D tulen boleh dilanjutkan? Liputan langsung 200m!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Bagaimana untuk menyelesaikan masalah ekor panjang dalam senario pemanduan autonomi?
Jun 02, 2024 pm 02:44 PM
Bagaimana untuk menyelesaikan masalah ekor panjang dalam senario pemanduan autonomi?
Jun 02, 2024 pm 02:44 PM
Semalam semasa temu bual, saya telah ditanya sama ada saya telah membuat sebarang soalan berkaitan ekor panjang, jadi saya fikir saya akan memberikan ringkasan ringkas. Masalah ekor panjang pemanduan autonomi merujuk kepada kes tepi dalam kenderaan autonomi, iaitu, kemungkinan senario dengan kebarangkalian yang rendah untuk berlaku. Masalah ekor panjang yang dirasakan adalah salah satu sebab utama yang kini mengehadkan domain reka bentuk pengendalian kenderaan autonomi pintar satu kenderaan. Seni bina asas dan kebanyakan isu teknikal pemanduan autonomi telah diselesaikan, dan baki 5% masalah ekor panjang secara beransur-ansur menjadi kunci untuk menyekat pembangunan pemanduan autonomi. Masalah ini termasuk pelbagai senario yang berpecah-belah, situasi yang melampau dan tingkah laku manusia yang tidak dapat diramalkan. "Ekor panjang" senario tepi dalam pemanduan autonomi merujuk kepada kes tepi dalam kenderaan autonomi (AVs) kes Edge adalah senario yang mungkin dengan kebarangkalian yang rendah untuk berlaku. kejadian yang jarang berlaku ini
 SOTA terbaharu nuScenes |. SparseAD: Pertanyaan jarang membantu pemanduan autonomi hujung ke hujung yang cekap!
Apr 17, 2024 pm 06:22 PM
SOTA terbaharu nuScenes |. SparseAD: Pertanyaan jarang membantu pemanduan autonomi hujung ke hujung yang cekap!
Apr 17, 2024 pm 06:22 PM
Ditulis di hadapan & titik permulaan Paradigma hujung ke hujung menggunakan rangka kerja bersatu untuk mencapai pelbagai tugas dalam sistem pemanduan autonomi. Walaupun kesederhanaan dan kejelasan paradigma ini, prestasi kaedah pemanduan autonomi hujung ke hujung pada subtugas masih jauh ketinggalan berbanding kaedah tugasan tunggal. Pada masa yang sama, ciri pandangan mata burung (BEV) padat yang digunakan secara meluas dalam kaedah hujung ke hujung sebelum ini menyukarkan untuk membuat skala kepada lebih banyak modaliti atau tugasan. Paradigma pemanduan autonomi hujung ke hujung (SparseAD) tertumpu carian jarang dicadangkan di sini, di mana carian jarang mewakili sepenuhnya keseluruhan senario pemanduan, termasuk ruang, masa dan tugas, tanpa sebarang perwakilan BEV yang padat. Khususnya, seni bina jarang bersatu direka bentuk untuk kesedaran tugas termasuk pengesanan, penjejakan dan pemetaan dalam talian. Di samping itu, berat
 FisheyeDetNet: algoritma pengesanan sasaran pertama berdasarkan kamera fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: algoritma pengesanan sasaran pertama berdasarkan kamera fisheye
Apr 26, 2024 am 11:37 AM
Pengesanan objek ialah masalah yang agak matang dalam sistem pemanduan autonomi, antaranya pengesanan pejalan kaki adalah salah satu algoritma terawal untuk digunakan. Penyelidikan yang sangat komprehensif telah dijalankan dalam kebanyakan kertas kerja. Walau bagaimanapun, persepsi jarak menggunakan kamera fisheye untuk pandangan sekeliling agak kurang dikaji. Disebabkan herotan jejari yang besar, perwakilan kotak sempadan standard sukar dilaksanakan dalam kamera fisheye. Untuk mengurangkan perihalan di atas, kami meneroka kotak sempadan lanjutan, elips dan reka bentuk poligon am ke dalam perwakilan kutub/sudut dan mentakrifkan metrik mIOU pembahagian contoh untuk menganalisis perwakilan ini. Model fisheyeDetNet yang dicadangkan dengan bentuk poligon mengatasi model lain dan pada masa yang sama mencapai 49.5% mAP pada set data kamera fisheye Valeo untuk pemanduan autonomi
 Pembinaan semula statik visual tulen pertama bagi pemanduan autonomi
Jun 02, 2024 pm 03:24 PM
Pembinaan semula statik visual tulen pertama bagi pemanduan autonomi
Jun 02, 2024 pm 03:24 PM
Penyelesaian anotasi visual semata-mata menggunakan penglihatan serta beberapa data daripada GPS, IMU dan penderia kelajuan roda untuk anotasi dinamik. Sudah tentu, untuk senario pengeluaran besar-besaran, ia tidak semestinya visual semata-mata. Sesetengah kenderaan yang dihasilkan secara besar-besaran akan mempunyai penderia seperti radar keadaan pepejal (AT128). Jika kami mencipta gelung tertutup data dari perspektif pengeluaran besar-besaran dan menggunakan semua penderia ini, kami boleh menyelesaikan masalah pelabelan objek dinamik dengan berkesan. Tetapi tiada radar keadaan pepejal dalam rancangan kami. Oleh itu, kami akan memperkenalkan penyelesaian pelabelan pengeluaran besar-besaran yang paling biasa ini. Teras penyelesaian anotasi visual semata-mata terletak pada pembinaan semula pose berketepatan tinggi. Kami menggunakan skema pembinaan semula pose Structure from Motion (SFM) untuk memastikan ketepatan pembinaan semula. Tetapi lulus
 Lihat masa lalu dan masa kini Occ dan pemanduan autonomi! Semakan pertama secara komprehensif meringkaskan tiga tema utama peningkatan ciri/pengeluaran besar-besaran/anotasi yang cekap.
May 08, 2024 am 11:40 AM
Lihat masa lalu dan masa kini Occ dan pemanduan autonomi! Semakan pertama secara komprehensif meringkaskan tiga tema utama peningkatan ciri/pengeluaran besar-besaran/anotasi yang cekap.
May 08, 2024 am 11:40 AM
Ditulis di atas & Pemahaman peribadi penulis Dalam beberapa tahun kebelakangan ini, pemanduan autonomi telah mendapat perhatian yang semakin meningkat kerana potensinya untuk mengurangkan beban pemandu dan meningkatkan keselamatan pemanduan. Ramalan penghunian tiga dimensi berasaskan penglihatan ialah tugas persepsi yang muncul yang sesuai untuk penyiasatan kos efektif dan komprehensif tentang keselamatan pemanduan autonomi. Walaupun banyak kajian telah menunjukkan keunggulan alat ramalan penghunian 3D berbanding tugas persepsi berpusatkan objek, masih terdapat ulasan khusus untuk bidang yang sedang berkembang pesat ini. Kertas kerja ini mula-mula memperkenalkan latar belakang ramalan penghunian 3D berasaskan penglihatan dan membincangkan cabaran yang dihadapi dalam tugasan ini. Seterusnya, kami membincangkan secara menyeluruh status semasa dan trend pembangunan kaedah ramalan penghunian 3D semasa daripada tiga aspek: peningkatan ciri, kemesraan penggunaan dan kecekapan pelabelan. akhirnya
 LLM sudah selesai! OmniDrive: Mengintegrasikan persepsi 3D dan perancangan penaakulan (terbaharu NVIDIA)
May 09, 2024 pm 04:55 PM
LLM sudah selesai! OmniDrive: Mengintegrasikan persepsi 3D dan perancangan penaakulan (terbaharu NVIDIA)
May 09, 2024 pm 04:55 PM
Ditulis di atas & pemahaman peribadi pengarang: Kertas kerja ini didedikasikan untuk menyelesaikan cabaran utama model bahasa besar multimodal semasa (MLLM) dalam aplikasi pemanduan autonomi, iaitu masalah melanjutkan MLLM daripada pemahaman 2D kepada ruang 3D. Peluasan ini amat penting kerana kenderaan autonomi (AV) perlu membuat keputusan yang tepat tentang persekitaran 3D. Pemahaman spatial 3D adalah penting untuk AV kerana ia memberi kesan langsung kepada keupayaan kenderaan untuk membuat keputusan termaklum, meramalkan keadaan masa depan dan berinteraksi dengan selamat dengan alam sekitar. Model bahasa besar berbilang mod semasa (seperti LLaVA-1.5) selalunya hanya boleh mengendalikan input imej resolusi rendah (cth.) disebabkan oleh had resolusi pengekod visual, had panjang jujukan LLM. Walau bagaimanapun, aplikasi pemanduan autonomi memerlukan
 Ke arah 'Gelung Tertutup' |. PlanAgent: SOTA baharu untuk perancangan gelung tertutup pemanduan autonomi berdasarkan MLLM!
Jun 08, 2024 pm 09:30 PM
Ke arah 'Gelung Tertutup' |. PlanAgent: SOTA baharu untuk perancangan gelung tertutup pemanduan autonomi berdasarkan MLLM!
Jun 08, 2024 pm 09:30 PM
Pasukan pembelajaran pengukuhan mendalam Institut Automasi, Akademi Sains China, bersama-sama dengan Li Auto dan lain-lain, mencadangkan rangka kerja perancangan gelung tertutup baharu untuk pemanduan autonomi berdasarkan model bahasa besar berbilang mod MLLM - PlanAgent. Kaedah ini mengambil pandangan mata dari tempat kejadian dan gesaan teks berasaskan graf sebagai input, dan menggunakan pemahaman pelbagai modal dan keupayaan penaakulan akal bagi model bahasa besar berbilang mod untuk melaksanakan penaakulan hierarki daripada pemahaman adegan kepada generasi. arahan pergerakan mendatar dan menegak, dan Selanjutnya menjana arahan yang diperlukan oleh perancang. Kaedah ini diuji pada penanda aras nuPlan berskala besar dan mencabar, dan eksperimen menunjukkan bahawa PlanAgent mencapai prestasi terkini (SOTA) pada kedua-dua senario biasa dan panjang. Berbanding dengan kaedah model bahasa besar (LLM) konvensional, PlanAgent
 Di luar BEVFusion! DifFUSER: Model resapan memasuki pelbagai tugas pemanduan autonomi (segmen BEV + pengesanan dwi SOTA)
Apr 22, 2024 pm 05:49 PM
Di luar BEVFusion! DifFUSER: Model resapan memasuki pelbagai tugas pemanduan autonomi (segmen BEV + pengesanan dwi SOTA)
Apr 22, 2024 pm 05:49 PM
Ditulis di atas & pemahaman peribadi penulis Pada masa ini, apabila teknologi pemanduan autonomi menjadi lebih matang dan permintaan untuk tugas persepsi pemanduan autonomi meningkat, industri dan akademia sangat berharap untuk model algoritma persepsi yang ideal yang boleh melengkapkan pengesanan sasaran tiga dimensi secara serentak dan berdasarkan tugasan segmentasi Semantik dalam ruang BEV. Untuk kenderaan yang mampu memandu autonomi, ia biasanya dilengkapi dengan penderia kamera pandangan sekeliling, penderia lidar dan penderia radar gelombang milimeter untuk mengumpul data dalam kaedah yang berbeza. Dengan cara ini, kelebihan pelengkap antara data modal yang berbeza boleh digunakan sepenuhnya, supaya kelebihan pelengkap data antara modaliti yang berbeza boleh dicapai Contohnya, data awan titik 3D boleh memberikan maklumat untuk tugas pengesanan sasaran 3D, manakala data imej berwarna boleh memberikan lebih banyak maklumat untuk tugasan segmentasi semantik maklumat yang tepat. jarum
