

Sistem pengurusan pangkalan data (DBMS) ialah bahagian penting dalam mana-mana aplikasi intensif data. Mereka boleh mengendalikan sejumlah besar data dan beban kerja yang kompleks, tetapi mereka juga sukar untuk diurus kerana terdapat ratusan atau ribuan "tombol" (pembolehubah konfigurasi) yang mengawal pelbagai faktor, seperti jumlah memori untuk digunakan untuk caching dan menulis ke cakera kekerapan. Organisasi selalunya perlu mengupah pakar untuk melakukan penalaan, dan pakar terlalu mahal untuk banyak organisasi. Pelajar dan penyelidik dalam Kumpulan Penyelidikan Pangkalan Data Universiti Carnegie Mellon sedang membangunkan alat baharu yang dipanggil OtterTune yang secara automatik boleh mencari tetapan yang betul untuk "tombol" DBMS. Tujuan alat ini adalah untuk membenarkan sesiapa sahaja menggunakan DBMS, walaupun tanpa sebarang kepakaran pentadbiran pangkalan data.
OtterTune berbeza daripada alatan persediaan DBMS yang lain kerana ia menggunakan pengetahuan tentang penalaan DBMS sebelumnya untuk menala DBMS baharu, yang mengurangkan masa dan sumber yang digunakan dengan ketara. OtterTune mencapai ini dengan mengekalkan pangkalan pengetahuan yang terkumpul daripada penalaan sebelumnya. Data terkumpul ini digunakan untuk membina model pembelajaran mesin (ML) untuk menangkap reaksi DBMS terhadap tetapan yang berbeza. OtterTune menggunakan model ini untuk membimbing percubaan dengan aplikasi baharu, mencadangkan konfigurasi yang meningkatkan matlamat akhir seperti mengurangkan kependaman dan meningkatkan daya pengeluaran.
Dalam artikel ini, kami akan membincangkan setiap komponen saluran paip pembelajaran mesin OtterTune dan cara ia berinteraksi untuk menyesuaikan persediaan DBMS anda. Kami kemudian menilai prestasi penalaan OtterTune pada MySQL dan Postgres, membandingkan konfigurasi optimumnya dengan DBA dan alat penalaan automatik yang lain.
OtterTune ialah alat sumber terbuka yang dibangunkan oleh pelajar dan penyelidik dalam Kumpulan Penyelidikan Pangkalan Data di Carnegie Mellon University Semua kod dihoskan pada Github dan dikeluarkan di bawah lesen Apache License 2.0.
Cara OtterTune berfungsiGambar di bawah menunjukkan komponen OtterTune dan aliran kerja
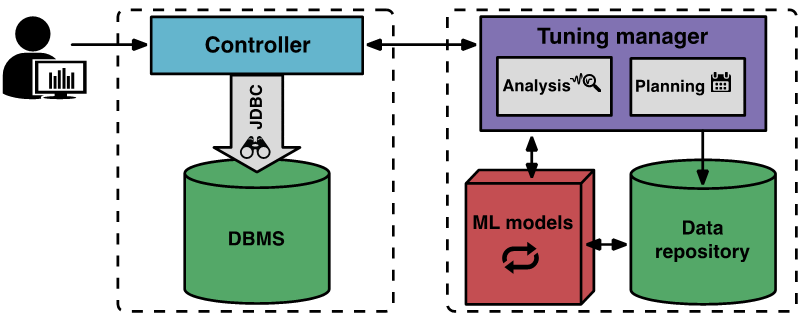
Proses penalaan bermula apabila pengguna memberitahu OtterTune matlamat akhir untuk ditala (contohnya, kependaman atau throughput), dan program pengawal klien menyambung kepada DBMS sasaran dan mengumpul jenis contoh Amazon EC2 dan konfigurasi semasa.
Kemudian, pengawal memulakan tempoh pemerhatian pertama untuk memerhati dan merekod sasaran akhir. Selepas pemerhatian, pengawal mengumpul metrik dalaman DBMS, seperti kiraan baca dan tulis halaman cakera MySQL. Pengawal mengembalikan data ini kepada program pengurus penalaan.
Pengurus penalaan OtterTune menyimpan data metrik yang diterima ke pangkalan pengetahuan. OtterTune menggunakan hasil ini untuk mengira konfigurasi seterusnya untuk DBMS sasaran dan mengembalikannya kepada pengawal bersama-sama dengan anggaran peningkatan prestasi. Pengguna boleh memutuskan sama ada untuk meneruskan atau menamatkan proses penalaan.
PerhatianOtterTune mengekalkan senarai hitam "tombol" untuk setiap versi DBMS yang disokong, termasuk versi yang tidak penting untuk penalaan (seperti laluan untuk menyimpan fail data), atau yang akan mempunyai akibat yang serius atau tersembunyi (seperti kehilangan data). OtterTune menyediakan senarai hitam ini kepada pengguna pada permulaan proses penalaan, dan pengguna boleh menambah "tombol" lain yang mereka mahu OtterTune elakkan.
OtterTune mempunyai beberapa andaian yang telah ditetapkan yang mungkin menyebabkan pengehadan tertentu untuk sesetengah pengguna. Sebagai contoh, ia menganggap bahawa pengguna mempunyai hak pentadbir supaya pengawal mengubah suai konfigurasi DBMS. Jika tidak, pengguna mesti menggunakan salinan pangkalan data pada perkakasan lain untuk OtterTune melakukan eksperimen penalaan. Ini memerlukan pengguna sama ada menghasilkan semula beban kerja atau memajukan pertanyaan kepada DBMS pengeluaran. Lihat kertas kami untuk pratetap dan sekatan yang lengkap.
Saluran Paip Pembelajaran MesinGambar di bawah menunjukkan proses data pemprosesan saluran paip OtterTune ML, dan semua pemerhatian disimpan dalam pangkalan pengetahuan.
OtterTune mula-mula menyuap data pemerhatian kepada komponen Pencirian Beban Kerja, yang boleh mengenal pasti set kecil metrik DBMS yang paling berkesan boleh menangkap perubahan prestasi dan ciri-ciri penting bagi beban kerja yang berbeza.
Langkah seterusnya, "Komponen Pengenalpastian Tombol" menjana senarai kedudukan tombol, termasuk tombol yang mempunyai kesan paling besar pada prestasi DBMS. OtterTune kemudiannya "menyuap" semua maklumat ini ke Penala Automatik, yang memetakan beban kerja DBMS sasaran kepada beban kerja terdekat dalam pangkalan pengetahuan dan menggunakan semula data beban kerja ini untuk menjana konfigurasi yang lebih baik.
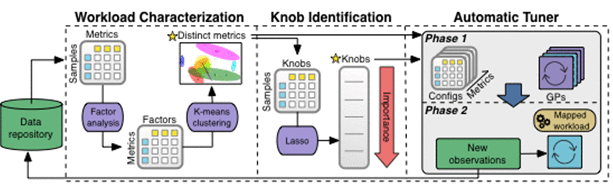
Mari kita mendalami setiap komponen saluran paip pembelajaran mesin di bawah.
Pencirian Beban Kerja: OtterTune memanfaatkan metrik masa jalan dalaman DBMS untuk mencirikan gelagat beban kerja tertentu Metrik ini mewakili beban kerja dengan tepat kerana ia menangkap pelbagai aspek kelakuan beban kerja. Walau bagaimanapun, banyak penunjuk adalah berlebihan: ada yang mewakili ukuran yang sama dalam unit yang berbeza, yang lain mewakili beberapa komponen bebas DBMS, tetapi nilainya sangat berkorelasi. Mengisih langkah berlebihan adalah penting untuk mengurangkan kerumitan model pembelajaran mesin. Oleh itu, kami mengumpulkan metrik DBMS berdasarkan korelasi dan memilih yang paling mewakili, khususnya yang paling hampir dengan median. Komponen pembelajaran mesin seterusnya akan menggunakan langkah-langkah ini.
Pengenalan tombol: DBMS boleh mempunyai ratusan tombol, tetapi hanya beberapa tombol yang mempengaruhi prestasi. OtterTune menggunakan teknik pemilihan ciri popular yang dipanggil Lasso untuk menentukan tombol yang mempunyai kesan paling besar pada prestasi keseluruhan sistem anda. Menggunakan teknik ini untuk memproses data dalam pangkalan pengetahuan, OtterTune dapat menentukan susunan kepentingan tombol DBMS.
Seterusnya, OtterTune mesti menentukan bilangan tombol untuk digunakan semasa membuat cadangan konfigurasi Menggunakan terlalu banyak tombol akan meningkatkan masa penalaan OtterTune dengan ketara, manakala menggunakan terlalu sedikit tombol akan menyukarkan untuk mencari konfigurasi terbaik. OtterTune menggunakan pendekatan tambahan untuk mengautomasikan proses ini, secara beransur-ansur meningkatkan bilangan tombol yang digunakan semasa sesi penalaan. Pendekatan ini membolehkan OtterTune meneroka dan memperhalusi konfigurasi dengan sebilangan kecil tombol terpenting dahulu, dan kemudian mengembangkan untuk mempertimbangkan tombol lain.
Auto-penala: Komponen penala automatik menggunakan kaedah analisis dua langkah untuk menentukan konfigurasi yang akan disyorkan selepas setiap fasa pemerhatian.
Pertama, sistem menggunakan data prestasi yang ditemui oleh komponen pencirian beban kerja untuk mengenal pasti proses penalaan sejarah yang paling hampir dengan beban kerja DBMS sasaran semasa, membandingkan dua metrik untuk mengesahkan nilai yang bertindak balas serupa kepada tetapan tombol yang berbeza.
OtterTune kemudian mencuba konfigurasi tombol lain, menggunakan model statistik pada data yang dikumpul dan data beban kerja terdekat dalam pangkalan pengetahuan. Model ini membolehkan OtterTune meramalkan prestasi DBMS di bawah setiap konfigurasi yang mungkin. OtterTune menala konfigurasi seterusnya, berselang seli antara penerokaan (mengumpul maklumat untuk menambah baik model) dan eksploitasi (menghampiri metrik sasaran dengan rakus).
TercapaiOtterTune ditulis dalam Python.
Untuk pencirian beban kerja dan komponen pengenalpastian tombol, prestasi masa jalan bukanlah pertimbangan utama, jadi kami menggunakan scikit-lear untuk melaksanakan algoritma pembelajaran mesin yang sepadan. Algoritma ini berjalan dalam proses latar belakang dan menyerap data yang baru dijana ke dalam pangkalan pengetahuan.
Untuk menala komponen secara automatik, algoritma pembelajaran mesin adalah sangat kritikal. Setiap fasa pemerhatian perlu dijalankan selepas selesai, menyerap data baharu supaya OtterTune boleh memilih tombol seterusnya untuk diuji. Memandangkan prestasi perlu dipertimbangkan, kami menggunakan TensorFlow untuk melaksanakannya.
Untuk mengumpul perkakasan DBMS, konfigurasi tombol dan metrik prestasi masa jalan, kami menyepadukan rangka kerja penanda aras OLTP-Bench ke dalam pengawal OtterTune.
Reka Bentuk EksperimenKami membandingkan konfigurasi OtterTune terbaik untuk MySQL dan Postgres dengan pilihan konfigurasi berikut untuk penilaian:
Lalai: Konfigurasi awal DBMS
Skrip penalaan: Konfigurasi dibuat oleh alat cadangan penalaan sumber terbuka
DBA: Konfigurasi dipilih oleh DBA manusia
RDS: Gunakan konfigurasi tersuai DBMS yang diuruskan oleh pembangun Amazon pada jenis contoh EC2 yang sama.
Kami melakukan semua percubaan pada contoh Amazon EC2 Spot. Setiap percubaan dijalankan pada dua keadaan, jenis m4.large dan m3.xlarge: satu untuk pengawal OtterTune dan satu untuk penempatan DBMS sasaran. Pengurus penalaan OtterTune dan pangkalan pengetahuan digunakan secara tempatan pada pelayan memori 128G 20-teras.
Beban kerja menggunakan TPC-C, iaitu piawaian industri untuk menilai prestasi sistem dagangan dalam talian.
PenilaianKami mengukur kependaman dan daya pemprosesan untuk setiap pangkalan data dalam percubaan - MySQL dan Postgres - dan carta di bawah menunjukkan hasilnya. Carta pertama menunjukkan bilangan "kependaman persentil ke-99", yang mewakili masa "kes terburuk" yang diperlukan untuk menyelesaikan transaksi. Carta kedua menunjukkan hasil pemprosesan, diukur sebagai purata bilangan transaksi yang dilakukan sesaat.
Hasil percubaan MySQLKonfigurasi optimum yang dihasilkan oleh OtterTune berbanding konfigurasi skrip penalaan dan RDS, OtterTune mengurangkan kependaman MySQL sebanyak lebih kurang 60% dan meningkatkan daya pengeluaran sebanyak 22% hingga 35%. OtterTune juga menjana konfigurasi yang hampir sama baiknya dengan DBA.
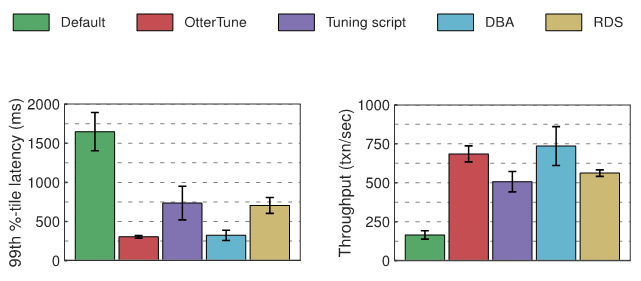
Di bawah bebanan TPC-C, hanya beberapa tombol MySQL yang mempengaruhi prestasi dengan ketara. Konfigurasi OtterTune dan DBA menetapkan tombol ini kepada nilai yang baik. Prestasi RDS lebih teruk sedikit kerana satu tombol diberikan nilai suboptimum. Skrip penalaan melakukan yang paling teruk kerana hanya satu tombol diubah suai.
Hasil percubaan postgres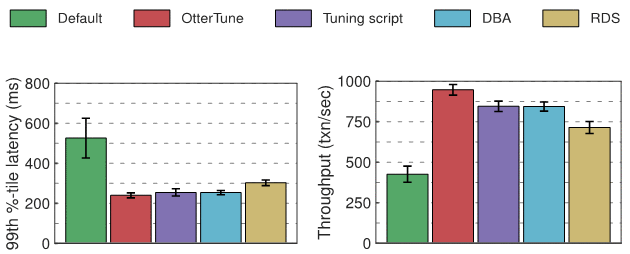
Dari segi kependaman, berbanding konfigurasi lalai Postgres, konfigurasi OtterTune, alat penalaan, DBA dan RDS telah mencapai peningkatan yang sama. Kita mungkin boleh mengaitkan ini kepada overhed rangkaian antara klien OLTP-Bench dan DBMS. Dari segi daya pengeluaran, Postgres adalah 12% lebih tinggi daripada DBA dan skrip penalaan apabila dikonfigurasikan dengan OtterTune, dan 32% lebih tinggi daripada RDS.
KesimpulanOtterTune mengautomasikan proses mencari nilai optimum untuk tombol konfigurasi DBMS. Ia menala DBMS yang baru digunakan dengan menggunakan semula data latihan yang dikumpul daripada proses penalaan sebelumnya. Oleh kerana OtterTune tidak perlu menjana set data permulaan untuk melatih model pembelajaran mesinnya, masa penalaan dikurangkan dengan banyak.
Apa seterusnya? Selaras dengan populariti DBaaS yang semakin meningkat (di mana log masuk jauh ke hos DBMS tidak boleh dilakukan), OtterTune tidak lama lagi akan dapat menyiasat secara automatik keupayaan perkakasan DBMS sasaran tanpa memerlukan log masuk jauh.
Untuk mengetahui lebih lanjut tentang OtterTune, lihat kertas dan kod kami di GitHub. Pantau tapak ini kerana kami akan menjadikan OtterTune sebagai perkhidmatan penalaan dalam talian tidak lama lagi.
Atas ialah kandungan terperinci Aplikasi pembelajaran mesin untuk operasi automatik dan penyelenggaraan DBMS. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



