
 Peranti teknologi
AI
Pengoptimuman LLM menggunakan teknologi SPIN untuk latihan penalaan halus permainan sendiri
Peranti teknologi
AI
Pengoptimuman LLM menggunakan teknologi SPIN untuk latihan penalaan halus permainan sendiri
Pengoptimuman LLM menggunakan teknologi SPIN untuk latihan penalaan halus permainan sendiri

2024 ialah tahun perkembangan pesat model bahasa besar (LLM). Dalam latihan LLM, kaedah penjajaran ialah cara teknikal yang penting, termasuk penyeliaan penalaan halus (SFT) dan pembelajaran pengukuhan dengan maklum balas manusia yang bergantung pada pilihan manusia (RLHF). Kaedah ini telah memainkan peranan penting dalam pembangunan LLM, tetapi kaedah penjajaran memerlukan sejumlah besar data beranotasi manual. Menghadapi cabaran ini, penalaan halus telah menjadi bidang penyelidikan yang rancak, dengan para penyelidik giat berusaha untuk membangunkan kaedah yang boleh mengeksploitasi data manusia dengan berkesan. Oleh itu, pembangunan kaedah penjajaran akan menggalakkan lagi kejayaan dalam teknologi LLM.
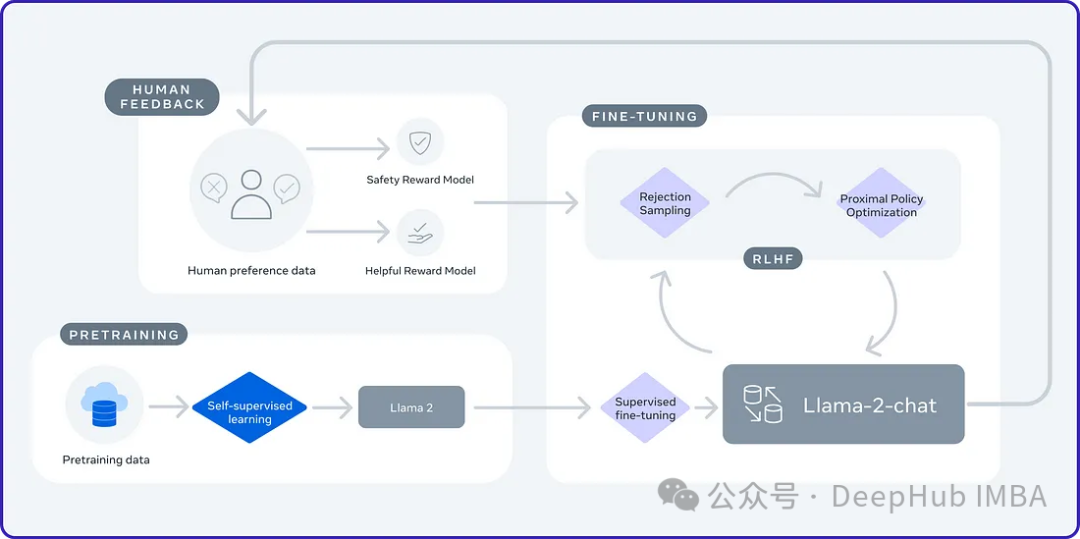
Universiti California baru-baru ini menjalankan kajian dan memperkenalkan teknologi baharu yang dipanggil SPIN (Self Play fIne tuNing). SPIN menggunakan mekanisme bermain sendiri yang berjaya dalam permainan seperti AlphaGo Zero dan AlphaZero untuk membolehkan LLM (Model Pembelajaran Bahasa) mengambil bahagian dalam bermain sendiri. Teknologi ini menghapuskan keperluan untuk anotasi profesional, sama ada manusia atau model yang lebih maju (seperti GPT-4). Proses latihan SPIN melibatkan latihan model bahasa baharu dan membezakan respons yang dijana sendiri daripada respons yang dijana manusia melalui satu siri lelaran. Matlamat utama adalah untuk membangunkan model bahasa yang menghasilkan respons yang tidak dapat dibezakan daripada respons manusia. Tujuan penyelidikan ini adalah untuk meningkatkan lagi keupayaan pembelajaran kendiri model bahasa dan menjadikannya lebih dekat dengan ekspresi dan pemikiran manusia. Hasil penyelidikan ini dijangka membawa penemuan baru kepada pembangunan pemprosesan bahasa semula jadi.
Permainan Kendiri
Permainan kendiri ialah teknik pembelajaran yang meningkatkan cabaran dan kerumitan persekitaran pembelajaran dengan bermain menentang salinan diri sendiri. Pendekatan ini membolehkan ejen berinteraksi dengan versi dirinya yang berbeza, dengan itu meningkatkan keupayaannya. AlphaGo Zero ialah kes permainan diri yang berjaya.

Permainan kendiri telah terbukti sebagai kaedah yang berkesan dalam pembelajaran pengukuhan pelbagai agen (MARL). Walau bagaimanapun, menerapkannya pada penambahan model bahasa besar (LLM) ialah pendekatan baharu. Dengan menggunakan permainan kendiri pada model bahasa yang besar, keupayaan mereka untuk menjana teks yang lebih koheren dan kaya dengan maklumat boleh dipertingkatkan lagi. Kaedah ini dijangka menggalakkan pembangunan dan penambahbaikan model bahasa selanjutnya.
Main kendiri boleh digunakan dalam tetapan kompetitif atau koperatif. Dalam persaingan, salinan algoritma bersaing antara satu sama lain untuk mencapai matlamat dalam kerjasama, salinan bekerja bersama untuk mencapai matlamat bersama. Ia boleh digabungkan dengan pembelajaran diselia, pembelajaran pengukuhan dan teknologi lain untuk meningkatkan prestasi.
SPIN
SPIN adalah seperti permainan dua pemain. Dalam permainan ini:
Peranan model induk (LLM baharu) adalah untuk belajar membezakan antara respons yang dihasilkan oleh model bahasa (LLM) dan respons yang dicipta oleh manusia. Dalam setiap lelaran, model induk secara aktif melatih LLM untuk meningkatkan keupayaannya untuk mengenali dan membezakan respons.
Model lawan (LLM lama) ditugaskan untuk menghasilkan tindak balas yang serupa dengan yang dihasilkan oleh manusia. Ia dijana melalui LLM lelaran sebelumnya, menggunakan mekanisme permainan sendiri untuk menjana output berdasarkan pengetahuan lepas. Matlamat model lawan adalah untuk mencipta respons yang begitu realistik sehingga LLM baharu tidak dapat memastikan ia dijana mesin.
Bukankah proses ini sangat serupa dengan GAN, tetapi ia masih tidak sama
Dinamik SPIN melibatkan penggunaan set data penalaan halus (SFT) yang diselia, yang terdiri daripada input (x) dan output (y ) berpasangan. Contoh-contoh ini diberi anotasi oleh manusia dan berfungsi sebagai asas untuk melatih model utama untuk mengenali respons seperti manusia. Beberapa set data SFT awam termasuk Dolly15K, Baize, Ultrachat, dsb.
Latihan model utama
Untuk melatih model utama membezakan antara model bahasa (LLM) dan tindak balas manusia, SPIN menggunakan fungsi objektif. Fungsi ini mengukur jurang nilai yang dijangkakan antara data sebenar dan tindak balas yang dihasilkan oleh model lawan. Matlamat model utama adalah untuk memaksimumkan jurang nilai yang dijangka ini. Ini melibatkan memberikan nilai tinggi kepada isyarat yang dipasangkan dengan respons daripada data sebenar, dan memberikan nilai rendah kepada pasangan respons yang dihasilkan oleh model lawan. Fungsi objektif ini dirumuskan sebagai masalah pengecilan.
Tugas model induk adalah untuk meminimumkan fungsi kehilangan, yang mengukur perbezaan antara nilai tugasan berpasangan daripada data sebenar dan nilai tugasan berpasangan daripada respons model lawan. Sepanjang proses latihan, model induk melaraskan parameternya untuk meminimumkan fungsi kehilangan ini. Proses berulang ini berterusan sehingga model induk mahir dalam membezakan tindak balas LLM secara berkesan daripada tindak balas manusia.
Kemas kini model lawan
Mengemas kini model lawan melibatkan peningkatan keupayaan model induk, yang semasa latihan telah belajar membezakan antara data sebenar dan tindak balas model bahasa. Apabila model induk bertambah baik dan pemahamannya tentang kelas fungsi tertentu dipertingkatkan, kami juga perlu mengemas kini parameter seperti model lawan. Apabila pemain induk berhadapan dengan gesaan yang sama, ia menggunakan diskriminasi yang dipelajari untuk menilai nilai mereka.
Matlamat pemain model lawan adalah untuk meningkatkan model bahasa supaya responsnya tidak dapat dibezakan daripada data sebenar pemain induk. Ini memerlukan penyediaan proses untuk melaraskan parameter model bahasa. Matlamatnya adalah untuk memaksimumkan penilaian model induk terhadap tindak balas model bahasa sambil mengekalkan kestabilan. Ini melibatkan tindakan mengimbangi, memastikan bahawa penambahbaikan tidak tersasar terlalu jauh daripada model bahasa asal.
Kedengarannya agak mengelirukan, mari kita ringkaskan secara ringkas:
Hanya ada satu model semasa latihan, tetapi model tersebut dibahagikan kepada model pusingan sebelumnya (model LLM/lawan lama) dan model utama (sedang dilatih), penggunaan Output model yang dilatih dibandingkan dengan output pusingan model sebelumnya untuk mengoptimumkan latihan model semasa. Tetapi di sini kita dikehendaki mempunyai model terlatih sebagai model lawan, jadi algoritma SPIN hanya sesuai untuk memperhalusi hasil latihan.
Algoritma SPIN
SPIN menjana data sintetik daripada model pra-latihan. Data sintetik ini kemudiannya digunakan untuk memperhalusi model pada tugasan baharu.

Di atas ialah kod pseudo algoritma Spin dalam kertas asal Nampaknya agak sukar untuk difahami.
1. Parameter permulaan dan set data SFT
Kertas asal menggunakan Zephyr-7B-SFT-Full sebagai model asas. Untuk set data, mereka menggunakan subset korpus Ultrachat200k yang lebih besar, yang terdiri daripada kira-kira 1.4 juta perbualan yang dijana menggunakan API Turbo OpenAI. Mereka mengambil sampel 50k isyarat secara rawak dan menggunakan model asas untuk menjana tindak balas sintetik.
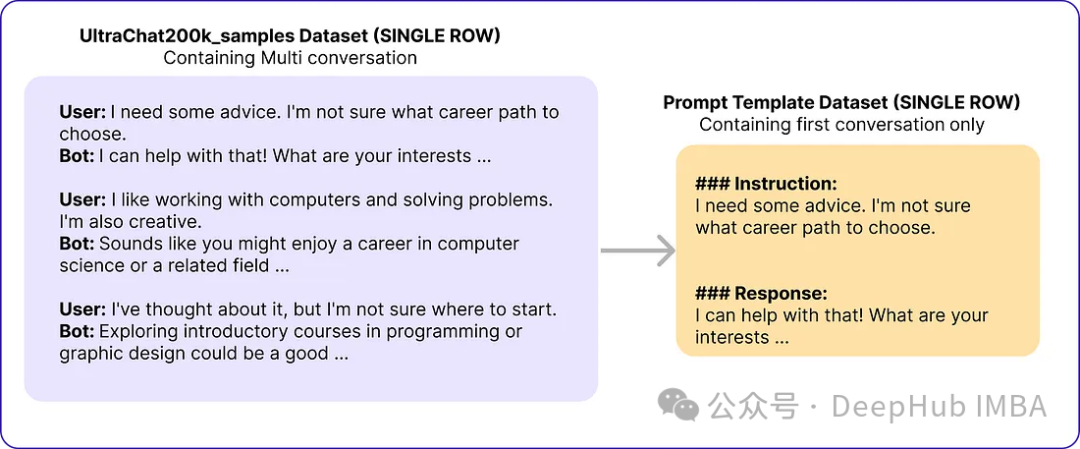
# Import necessary libraries from datasets import load_dataset import pandas as pd # Load the Ultrachat 200k dataset ultrachat_dataset = load_dataset("HuggingFaceH4/ultrachat_200k") # Initialize an empty DataFrame combined_df = pd.DataFrame() # Loop through all the keys in the Ultrachat dataset for key in ultrachat_dataset.keys():# Convert each dataset key to a pandas DataFrame and concatenate it with the existing DataFramecombined_df = pd.concat([combined_df, pd.DataFrame(ultrachat_dataset[key])]) # Shuffle the combined DataFrame and reset the index combined_df = combined_df.sample(frac=1, random_state=123).reset_index(drop=True) # Select the first 50,000 rows from the shuffled DataFrame ultrachat_50k_sample = combined_df.head(50000)Templat gesaan pengarang "### Arahan: {prompt}nn### Respons:"
# for storing each template in a list templates_data = [] for index, row in ultrachat_50k_sample.iterrows():messages = row['messages'] # Check if there are at least two messages (user and assistant)if len(messages) >= 2:user_message = messages[0]['content']assistant_message = messages[1]['content'] # Create the templateinstruction_response_template = f"### Instruction: {user_message}\n\n### Response: {assistant_message}" # Append the template to the listtemplates_data.append({'Template': instruction_response_template}) # Create a new DataFrame with the generated templates (ground truth) ground_truth_df = pd.DataFrame(templates_data)Kemudian kami mendapat data yang serupa dengan yang berikut:
Algoritma SPIN mengemas kini model bahasa (LLM) mengikut parameter lelaran untuk memastikannya konsisten dengan tindak balas ground-truth. Proses ini berterusan sehingga sukar untuk membezakan tindak balas yang dihasilkan daripada kebenaran asas, sekali gus mencapai tahap persamaan yang tinggi (kehilangan berkurangan).
Algoritma SPIN mempunyai dua gelung. Gelung dalam dijalankan berdasarkan bilangan sampel yang kami gunakan, dan gelung luar dijalankan untuk sejumlah 3 lelaran, kerana pengarang mendapati prestasi model tidak berubah selepas ini. Pustaka Buku Panduan Alignment digunakan sebagai perpustakaan kod untuk kaedah penalaan halus, digabungkan dengan modul DeepSpeed untuk mengurangkan kos latihan. Mereka melatih Zephyr-7B-SFT-Full dengan pengoptimum RMSProp, tanpa pereputan berat untuk semua lelaran, seperti yang biasanya digunakan untuk memperhalusi llm. Saiz kelompok global ditetapkan kepada 64, menggunakan ketepatan bfloat16. Kadar pembelajaran puncak untuk lelaran 0 dan 1 ditetapkan kepada 5e-7, dan kadar pembelajaran puncak untuk lelaran 2 dan 3 mereput kepada 1e-7 apabila gelung menghampiri penghujung penalaan halus bermain sendiri. Akhirnya β = 0.1 dipilih dan panjang jujukan maksimum ditetapkan kepada 2048 token. Berikut adalah parameter ini
# Importing the PyTorch library import torch # Importing the neural network module from PyTorch import torch.nn as nn # Importing the DeepSpeed library for distributed training import deepspeed # Importing the AutoTokenizer and AutoModelForCausalLM classes from the transformers library from transformers import AutoTokenizer, AutoModelForCausalLM # Loading the zephyr-7b-sft-full model from HuggingFace tokenizer = AutoTokenizer.from_pretrained("alignment-handbook/zephyr-7b-sft-full") model = AutoModelForCausalLM.from_pretrained("alignment-handbook/zephyr-7b-sft-full") # Initializing DeepSpeed Zero with specific configuration settings deepspeed_config = deepspeed.config.Config(train_batch_size=64, train_micro_batch_size_per_gpu=4) model, optimizer, _, _ = deepspeed.initialize(model=model, config=deepspeed_config, model_parameters=model.parameters()) # Defining the optimizer and setting the learning rate using RMSprop optimizer = deepspeed.optim.RMSprop(optimizer, lr=5e-7) # Setting up a learning rate scheduler using LambdaLR from PyTorch scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lambda epoch: 0.2 ** epoch) # Setting hyperparameters for training num_epochs = 3 max_seq_length = 2048 beta = 0.12 Hasilkan data sintetik (gelung dalaman algoritma SPIN)
Gelung dalaman ini bertanggungjawab untuk menghasilkan respons yang perlu konsisten dengan data sebenar, iaitu kod kumpulan latihan
# zephyr-sft-dataframe (that contains output that will be improved while training) zephyr_sft_output = pd.DataFrame(columns=['prompt', 'generated_output']) # Looping through each row in the 'ultrachat_50k_sample' dataframe for index, row in ultrachat_50k_sample.iterrows():# Extracting the 'prompt' column value from the current rowprompt = row['prompt'] # Generating output for the current prompt using the Zephyr modelinput_ids = tokenizer(prompt, return_tensors="pt").input_idsoutput = model.generate(input_ids, max_length=200, num_beams=5, no_repeat_ngram_size=2, top_k=50, top_p=0.95) # Decoding the generated output to human-readable textgenerated_text = tokenizer.decode(output[0], skip_special_tokens=True) # Appending the current prompt and its generated output to the new dataframe 'zephyr_sft_output'zephyr_sft_output = zephyr_sft_output.append({'prompt': prompt, 'generated_output': generated_text}, ignore_index=True)Ini ialah peringatan Contoh nilai sebenar dan keluaran model.

df zephyr_sft_output baharu, yang mengandungi petunjuk dan output sepadannya yang dijana oleh model asas Zephyr-7B-SFT-Full.
3. Peraturan Kemas Kini
Sebelum pengekodan masalah pengecilan, adalah penting untuk memahami cara mengira taburan kebarangkalian bersyarat bagi output yang dijana oleh llm. Kertas asal menggunakan proses Markov, di mana taburan kebarangkalian bersyarat pθ (y|x) boleh dinyatakan melalui penguraian sebagai:

Penguraian ini bermakna kebarangkalian jujukan output yang diberi jujukan input boleh dinyatakan dengan membahagikan. jujukan input yang diberikan Setiap token keluaran dikira dengan mendarab kebarangkalian token keluaran sebelumnya. Sebagai contoh, urutan output ialah "Saya seronok membaca buku" dan urutan input ialah "Saya seronok". akan menjadi Taburan kebarangkalian yang digunakan untuk mengira kebenaran asas dan tindak balas Zephyr LLM, yang kemudiannya digunakan untuk mengira fungsi kerugian. Tetapi pertama-tama kita perlu mengekod fungsi kebarangkalian bersyarat.
# Conditional Probability Function of input text def compute_conditional_probability(tokenizer, model, input_text):# Tokenize the input text and convert it to PyTorch tensorsinputs = tokenizer([input_text], return_tensors="pt") # Generate text using the model, specifying additional parametersoutputs = model.generate(**inputs, return_dict_in_generate=True, output_scores=True) # Assuming 'transition_scores' is the logits for the generated tokenstransition_scores = model.compute_transition_scores(outputs.sequences, outputs.scores, normalize_logits=True) # Get the length of the input sequenceinput_length = inputs.input_ids.shape[1] # Assuming 'transition_scores' is the logits for the generated tokenslogits = torch.tensor(transition_scores) # Apply softmax to obtain probabilitiesprobs = torch.nn.functional.softmax(logits, dim=-1) # Extract the generated tokens from the outputgenerated_tokens = outputs.sequences[:, input_length:] # Compute conditional probabilityconditional_probability = 1.0for prob in probs[0]:token_probability = prob.item()conditional_probability *= token_probability return conditional_probability
Fungsi kehilangan Ia mengandungi empat pembolehubah kebarangkalian bersyarat yang penting. Setiap pembolehubah ini bergantung pada data sebenar asas atau data sintetik yang dibuat sebelum ini. 
而lambda是一个正则化参数,用于控制偏差。在KL正则化项中使用它来惩罚对手模型的分布与目标数据分布之间的差异。论文中没有明确提到lambda的具体值,因为它可能会根据所使用的特定任务和数据集进行调优。
def LSPIN_loss(model, updated_model, tokenizer, input_text, lambda_val=0.01):# Initialize conditional probability using the original model and input textcp = compute_conditional_probability(tokenizer, model, input_text) # Update conditional probability using the updated model and input textcp_updated = compute_conditional_probability(tokenizer, updated_model, input_text) # Calculate conditional probabilities for ground truth datap_theta_ground_truth = cp(tokenizer, model, input_text)p_theta_t_ground_truth = cp(tokenizer, model, input_text) # Calculate conditional probabilities for synthetic datap_theta_synthetic = cp_updated(tokenizer, updated_model, input_text)p_theta_t_synthetic = cp_updated(tokenizer, updated_model, input_text) # Calculate likelihood ratioslr_ground_truth = p_theta_ground_truth / p_theta_t_ground_truthlr_synthetic = p_theta_synthetic / p_theta_t_synthetic # Compute the LSPIN lossloss = lambda_val * torch.log(lr_ground_truth) - lambda_val * torch.log(lr_synthetic) return loss
如果你有一个大的数据集,可以使用一个较小的lambda值,或者如果你有一个小的数据集,则可能需要使用一个较大的lambda值来防止过拟合。由于我们数据集大小为50k,所以可以使用0.01作为lambda的值。
4、训练(SPIN算法外循环)
这就是Pytorch训练的一个基本流程,就不详细解释了:
# Training loop for epoch in range(num_epochs): # Model with initial parametersinitial_model = AutoModelForCausalLM.from_pretrained("alignment-handbook/zephyr-7b-sft-full") # Update the learning ratescheduler.step() # Initialize total loss for the epochtotal_loss = 0.0 # Generating Synthetic Data (Inner loop)for index, row in ultrachat_50k_sample.iterrows(): # Rest of the code ... # Output == prompt response dataframezephyr_sft_output # Computing loss using LSPIN functionfor (index1, row1), (index2, row2) in zip(ultrachat_50k_sample.iterrows(), zephyr_sft_output.iterrows()):# Assuming 'prompt' and 'generated_output' are the relevant columns in zephyr_sft_outputprompt = row1['prompt']generated_output = row2['generated_output'] # Compute LSPIN lossupdated_model = model # It will be replacing with updated modelloss = LSPIN_loss(initial_model, updated_model, tokenizer, prompt) # Accumulate the losstotal_loss += loss.item() # Backward passloss.backward() # Update the parametersoptimizer.step() # Update the value of betaif epoch == 2:beta = 5.0我们运行3个epoch,它将进行训练并生成最终的Zephyr SFT LLM版本。官方实现还没有在GitHub上开源,这个版本将能够在某种程度上产生类似于人类反应的输出。我们看看他的运行流程
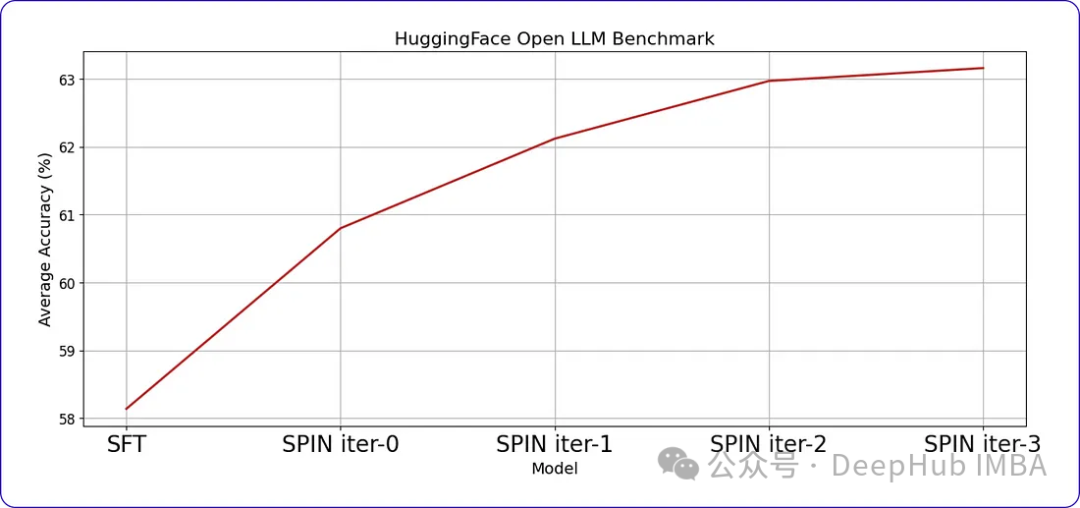
表现及结果
SPIN可以显著提高LLM在各种基准测试中的性能,甚至超过通过直接偏好优化(DPO)补充额外的GPT-4偏好数据训练的模型。
当我们继续训练时,随着时间的推移,进步会变得越来越小。这表明模型达到了一个阈值,进一步的迭代不会带来显著的收益。这是我们训练数据中样本提示符每次迭代后的响应。

Atas ialah kandungan terperinci Pengoptimuman LLM menggunakan teknologi SPIN untuk latihan penalaan halus permainan sendiri. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1375
1375
 52
52

 Bytedance Cutting melancarkan keahlian super SVIP: 499 yuan untuk langganan tahunan berterusan, menyediakan pelbagai fungsi AI
Jun 28, 2024 am 03:51 AM
Bytedance Cutting melancarkan keahlian super SVIP: 499 yuan untuk langganan tahunan berterusan, menyediakan pelbagai fungsi AI
Jun 28, 2024 am 03:51 AM
Laman web ini melaporkan pada 27 Jun bahawa Jianying ialah perisian penyuntingan video yang dibangunkan oleh FaceMeng Technology, anak syarikat ByteDance Ia bergantung pada platform Douyin dan pada asasnya menghasilkan kandungan video pendek untuk pengguna platform tersebut Windows , MacOS dan sistem pengendalian lain. Jianying secara rasmi mengumumkan peningkatan sistem keahliannya dan melancarkan SVIP baharu, yang merangkumi pelbagai teknologi hitam AI, seperti terjemahan pintar, penonjolan pintar, pembungkusan pintar, sintesis manusia digital, dsb. Dari segi harga, yuran bulanan untuk keratan SVIP ialah 79 yuan, yuran tahunan ialah 599 yuan (nota di laman web ini: bersamaan dengan 49.9 yuan sebulan), langganan bulanan berterusan ialah 59 yuan sebulan, dan langganan tahunan berterusan ialah 499 yuan setahun (bersamaan dengan 41.6 yuan sebulan) . Di samping itu, pegawai yang dipotong juga menyatakan bahawa untuk meningkatkan pengalaman pengguna, mereka yang telah melanggan VIP asal
 Pembantu pengekodan AI yang ditambah konteks menggunakan Rag dan Sem-Rag
Jun 10, 2024 am 11:08 AM
Pembantu pengekodan AI yang ditambah konteks menggunakan Rag dan Sem-Rag
Jun 10, 2024 am 11:08 AM
Tingkatkan produktiviti, kecekapan dan ketepatan pembangun dengan menggabungkan penjanaan dipertingkatkan semula dan memori semantik ke dalam pembantu pengekodan AI. Diterjemah daripada EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, pengarang JanakiramMSV. Walaupun pembantu pengaturcaraan AI asas secara semulajadi membantu, mereka sering gagal memberikan cadangan kod yang paling relevan dan betul kerana mereka bergantung pada pemahaman umum bahasa perisian dan corak penulisan perisian yang paling biasa. Kod yang dijana oleh pembantu pengekodan ini sesuai untuk menyelesaikan masalah yang mereka bertanggungjawab untuk menyelesaikannya, tetapi selalunya tidak mematuhi piawaian pengekodan, konvensyen dan gaya pasukan individu. Ini selalunya menghasilkan cadangan yang perlu diubah suai atau diperhalusi agar kod itu diterima ke dalam aplikasi
 Tujuh Soalan Temuduga Teknikal GenAI & LLM yang Cool
Jun 07, 2024 am 10:06 AM
Tujuh Soalan Temuduga Teknikal GenAI & LLM yang Cool
Jun 07, 2024 am 10:06 AM
Untuk mengetahui lebih lanjut tentang AIGC, sila layari: 51CTOAI.x Komuniti https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou berbeza daripada bank soalan tradisional yang boleh dilihat di mana-mana sahaja di Internet memerlukan pemikiran di luar kotak. Model Bahasa Besar (LLM) semakin penting dalam bidang sains data, kecerdasan buatan generatif (GenAI) dan kecerdasan buatan. Algoritma kompleks ini meningkatkan kemahiran manusia dan memacu kecekapan dan inovasi dalam banyak industri, menjadi kunci kepada syarikat untuk kekal berdaya saing. LLM mempunyai pelbagai aplikasi Ia boleh digunakan dalam bidang seperti pemprosesan bahasa semula jadi, penjanaan teks, pengecaman pertuturan dan sistem pengesyoran. Dengan belajar daripada sejumlah besar data, LLM dapat menjana teks
 Bolehkah penalaan halus benar-benar membolehkan LLM mempelajari perkara baharu: memperkenalkan pengetahuan baharu boleh menjadikan model menghasilkan lebih banyak halusinasi
Jun 11, 2024 pm 03:57 PM
Bolehkah penalaan halus benar-benar membolehkan LLM mempelajari perkara baharu: memperkenalkan pengetahuan baharu boleh menjadikan model menghasilkan lebih banyak halusinasi
Jun 11, 2024 pm 03:57 PM
Model Bahasa Besar (LLM) dilatih pada pangkalan data teks yang besar, di mana mereka memperoleh sejumlah besar pengetahuan dunia sebenar. Pengetahuan ini dibenamkan ke dalam parameter mereka dan kemudiannya boleh digunakan apabila diperlukan. Pengetahuan tentang model ini "diperbaharui" pada akhir latihan. Pada akhir pra-latihan, model sebenarnya berhenti belajar. Selaraskan atau perhalusi model untuk mempelajari cara memanfaatkan pengetahuan ini dan bertindak balas dengan lebih semula jadi kepada soalan pengguna. Tetapi kadangkala pengetahuan model tidak mencukupi, dan walaupun model boleh mengakses kandungan luaran melalui RAG, ia dianggap berfaedah untuk menyesuaikan model kepada domain baharu melalui penalaan halus. Penalaan halus ini dilakukan menggunakan input daripada anotasi manusia atau ciptaan LLM lain, di mana model menemui pengetahuan dunia sebenar tambahan dan menyepadukannya
 Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) set data memainkan peranan penting dalam mempromosikan penyelidikan pemprosesan bahasa semula jadi (NLP). Set data QA berkualiti tinggi bukan sahaja boleh digunakan untuk memperhalusi model, tetapi juga menilai dengan berkesan keupayaan model bahasa besar (LLM), terutamanya keupayaan untuk memahami dan menaakul tentang pengetahuan saintifik. Walaupun pada masa ini terdapat banyak set data QA saintifik yang meliputi bidang perubatan, kimia, biologi dan bidang lain, set data ini masih mempunyai beberapa kekurangan. Pertama, borang data adalah agak mudah, kebanyakannya adalah soalan aneka pilihan. Ia mudah dinilai, tetapi mengehadkan julat pemilihan jawapan model dan tidak dapat menguji sepenuhnya keupayaan model untuk menjawab soalan saintifik. Sebaliknya, Soal Jawab terbuka
 Lima sekolah pembelajaran mesin yang anda tidak tahu
Jun 05, 2024 pm 08:51 PM
Lima sekolah pembelajaran mesin yang anda tidak tahu
Jun 05, 2024 pm 08:51 PM
Pembelajaran mesin ialah cabang penting kecerdasan buatan yang memberikan komputer keupayaan untuk belajar daripada data dan meningkatkan keupayaan mereka tanpa diprogramkan secara eksplisit. Pembelajaran mesin mempunyai pelbagai aplikasi dalam pelbagai bidang, daripada pengecaman imej dan pemprosesan bahasa semula jadi kepada sistem pengesyoran dan pengesanan penipuan, dan ia mengubah cara hidup kita. Terdapat banyak kaedah dan teori yang berbeza dalam bidang pembelajaran mesin, antaranya lima kaedah yang paling berpengaruh dipanggil "Lima Sekolah Pembelajaran Mesin". Lima sekolah utama ialah sekolah simbolik, sekolah sambungan, sekolah evolusi, sekolah Bayesian dan sekolah analogi. 1. Simbolisme, juga dikenali sebagai simbolisme, menekankan penggunaan simbol untuk penaakulan logik dan ekspresi pengetahuan. Aliran pemikiran ini percaya bahawa pembelajaran adalah proses penolakan terbalik, melalui sedia ada
 Prestasi SOTA, kaedah AI ramalan pertalian protein-ligan pelbagai mod Xiamen, menggabungkan maklumat permukaan molekul buat kali pertama
Jul 17, 2024 pm 06:37 PM
Prestasi SOTA, kaedah AI ramalan pertalian protein-ligan pelbagai mod Xiamen, menggabungkan maklumat permukaan molekul buat kali pertama
Jul 17, 2024 pm 06:37 PM
Editor |. KX Dalam bidang penyelidikan dan pembangunan ubat, meramalkan pertalian pengikatan protein dan ligan dengan tepat dan berkesan adalah penting untuk pemeriksaan dan pengoptimuman ubat. Walau bagaimanapun, kajian semasa tidak mengambil kira peranan penting maklumat permukaan molekul dalam interaksi protein-ligan. Berdasarkan ini, penyelidik dari Universiti Xiamen mencadangkan rangka kerja pengekstrakan ciri berbilang mod (MFE) novel, yang buat pertama kalinya menggabungkan maklumat mengenai permukaan protein, struktur dan jujukan 3D, dan menggunakan mekanisme perhatian silang untuk membandingkan ciri modaliti yang berbeza penjajaran. Keputusan eksperimen menunjukkan bahawa kaedah ini mencapai prestasi terkini dalam meramalkan pertalian mengikat protein-ligan. Tambahan pula, kajian ablasi menunjukkan keberkesanan dan keperluan maklumat permukaan protein dan penjajaran ciri multimodal dalam rangka kerja ini. Penyelidikan berkaitan bermula dengan "S
 Meletakkan pasaran seperti AI, GlobalFoundries memperoleh teknologi gallium nitrida Tagore Technology dan pasukan berkaitan
Jul 15, 2024 pm 12:21 PM
Meletakkan pasaran seperti AI, GlobalFoundries memperoleh teknologi gallium nitrida Tagore Technology dan pasukan berkaitan
Jul 15, 2024 pm 12:21 PM
Menurut berita dari laman web ini pada 5 Julai, GlobalFoundries mengeluarkan kenyataan akhbar pada 1 Julai tahun ini, mengumumkan pemerolehan teknologi power gallium nitride (GaN) Tagore Technology dan portfolio harta intelek, dengan harapan dapat mengembangkan bahagian pasarannya dalam kereta dan Internet of Things dan kawasan aplikasi pusat data kecerdasan buatan untuk meneroka kecekapan yang lebih tinggi dan prestasi yang lebih baik. Memandangkan teknologi seperti AI generatif terus berkembang dalam dunia digital, galium nitrida (GaN) telah menjadi penyelesaian utama untuk pengurusan kuasa yang mampan dan cekap, terutamanya dalam pusat data. Laman web ini memetik pengumuman rasmi bahawa semasa pengambilalihan ini, pasukan kejuruteraan Tagore Technology akan menyertai GLOBALFOUNDRIES untuk membangunkan lagi teknologi gallium nitride. G
