
 Peranti teknologi
AI
Kerja pecah tanah Transformer ditentang, semakan ICLR menimbulkan persoalan! Orang ramai menuduh operasi kotak hitam, LeCun mendedahkan pengalaman serupa
Peranti teknologi
AI
Kerja pecah tanah Transformer ditentang, semakan ICLR menimbulkan persoalan! Orang ramai menuduh operasi kotak hitam, LeCun mendedahkan pengalaman serupa
Kerja pecah tanah Transformer ditentang, semakan ICLR menimbulkan persoalan! Orang ramai menuduh operasi kotak hitam, LeCun mendedahkan pengalaman serupa

Pada Disember tahun lalu, dua penyelidik dari CMU dan Princeton mengeluarkan seni bina Mamba, yang serta-merta mengejutkan komuniti AI!
Akibatnya, kertas kerja yang dijangka "menumbangkan hegemoni Transformer" ini didedahkan hari ini untuk disyaki ditolak? !
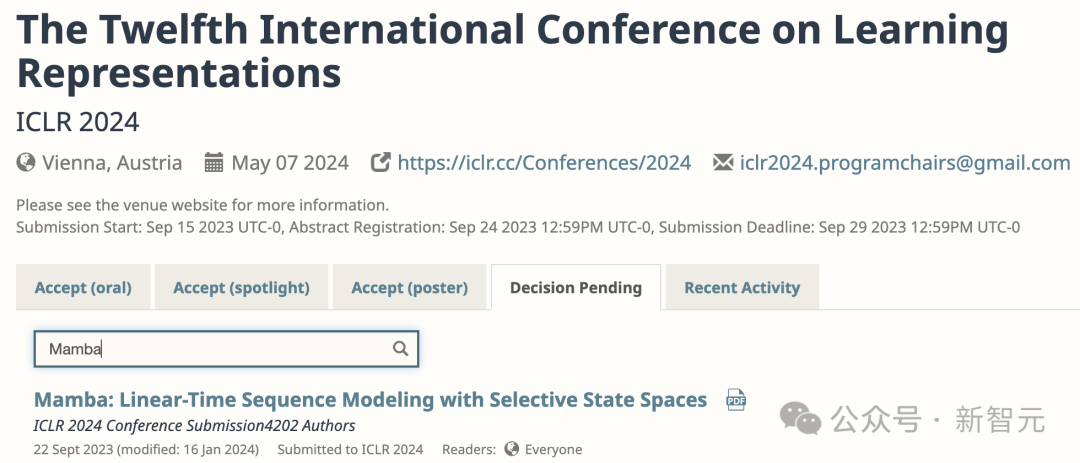
Pagi ini, Sasha Rush, profesor madya di Cornell University, mula-mula mendapati bahawa kertas kerja yang dijangka menjadi karya asas ini nampaknya ditolak oleh ICLR 2024.
dan berkata, "Sejujurnya, saya tidak faham. Jika ditolak, apa peluang yang kita ada".
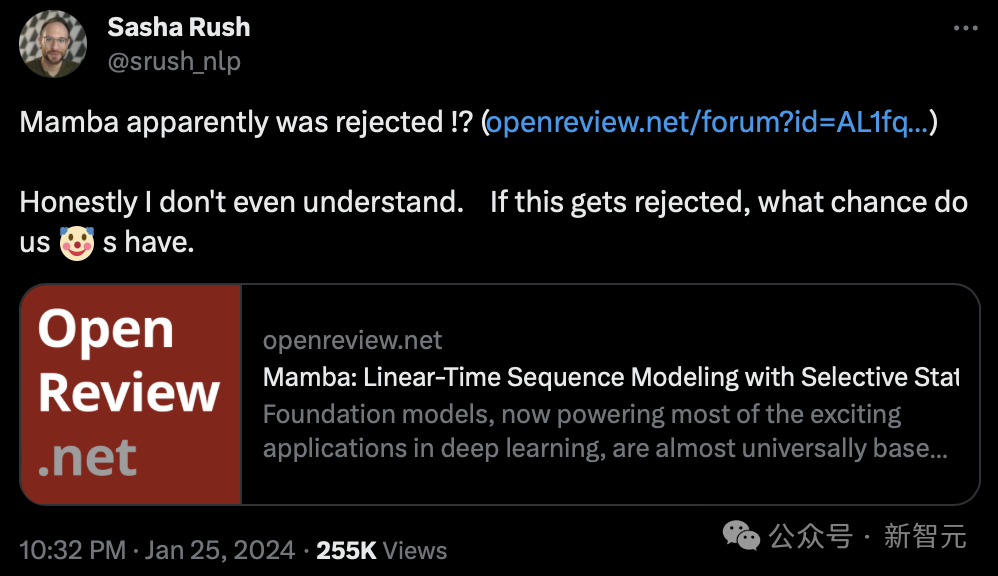
Seperti yang anda lihat di OpenReview, markah yang diberikan oleh empat pengulas ialah 3, 6, 8 dan 8.
Walaupun markah ini mungkin tidak menyebabkan kertas ditolak, markah serendah 3 mata juga keterlaluan.
Niu Wen menjaringkan 3 mata, dan LeCun juga keluar untuk menangis
Kertas kerja yang diterbitkan oleh dua penyelidik dari CMU dan Princeton University mencadangkan Mamba seni bina baharu.
Seni bina SSM ini setanding dengan Transformers dalam pemodelan bahasa, dan juga boleh skala secara linear, sambil mempunyai 5 kali daya pemprosesan inferens!

Alamat kertas: https://arxiv.org/pdf/2312.00752.pdf
Sebaik sahaja kertas itu keluar, ia secara langsung mengejutkan komuniti AI Transformer yang terbalik itu akhirnya dilahirkan.
Kini, kertas Mamba berkemungkinan ditolak, yang tidak dapat difahami oleh ramai orang.
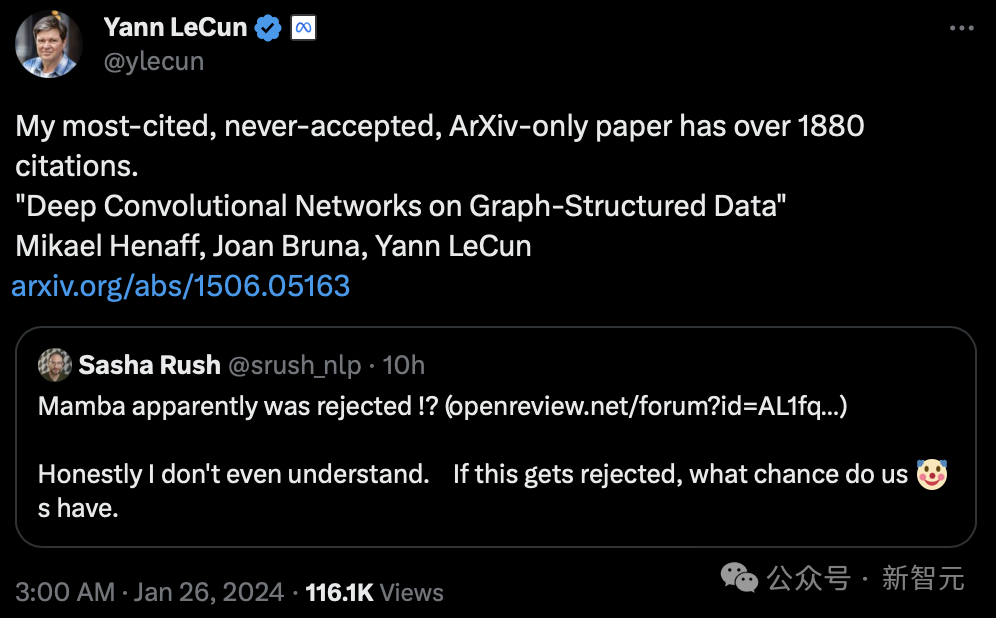
Malah gergasi Turing LeCun turut serta dalam perbincangan ini, mengatakan bahawa dia telah menghadapi "ketidakadilan" yang serupa.
"Saya fikir ketika itu, saya mempunyai paling banyak petikan. Kertas yang saya serahkan di Arxiv sahaja telah dipetik lebih daripada 1880 kali, tetapi ia tidak pernah diterima."
LeCun terkenal dengan karyanya dalam pengecaman aksara optik dan penglihatan komputer menggunakan rangkaian neural convolutional (CNN), yang mana beliau memenangi Anugerah Turing pada 2019.
Walau bagaimanapun, kertas kerjanya "Deep Convolutional Network Based on Graph Structure Data" yang diterbitkan pada 2015 tidak pernah diterima oleh persidangan itu.

Alamat kertas: https://arxiv.org/pdf/1506.05163.pdf
Pembelajaran mendalam penyelidik AI Sebastian Raschka berkata walaupun demikian, Mamba telah memberi impak yang mendalam kepada komuniti .
Gelombang besar penyelidikan baru-baru ini diperoleh daripada seni bina Mamba, seperti MoE-Mamba dan Vision Mamba.

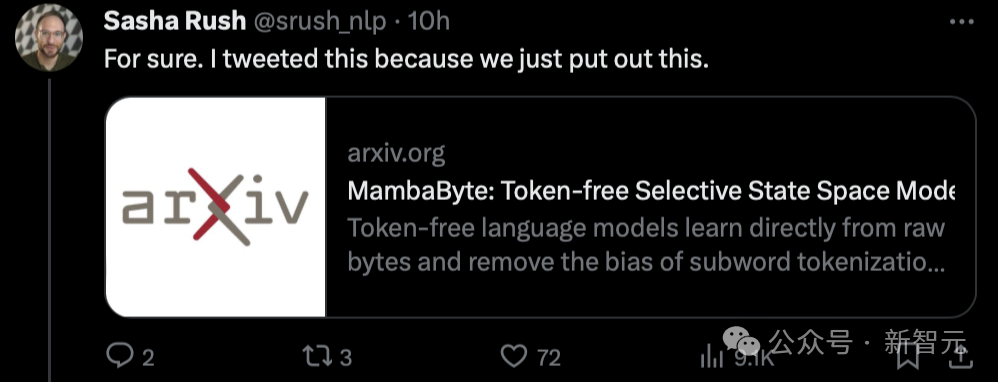
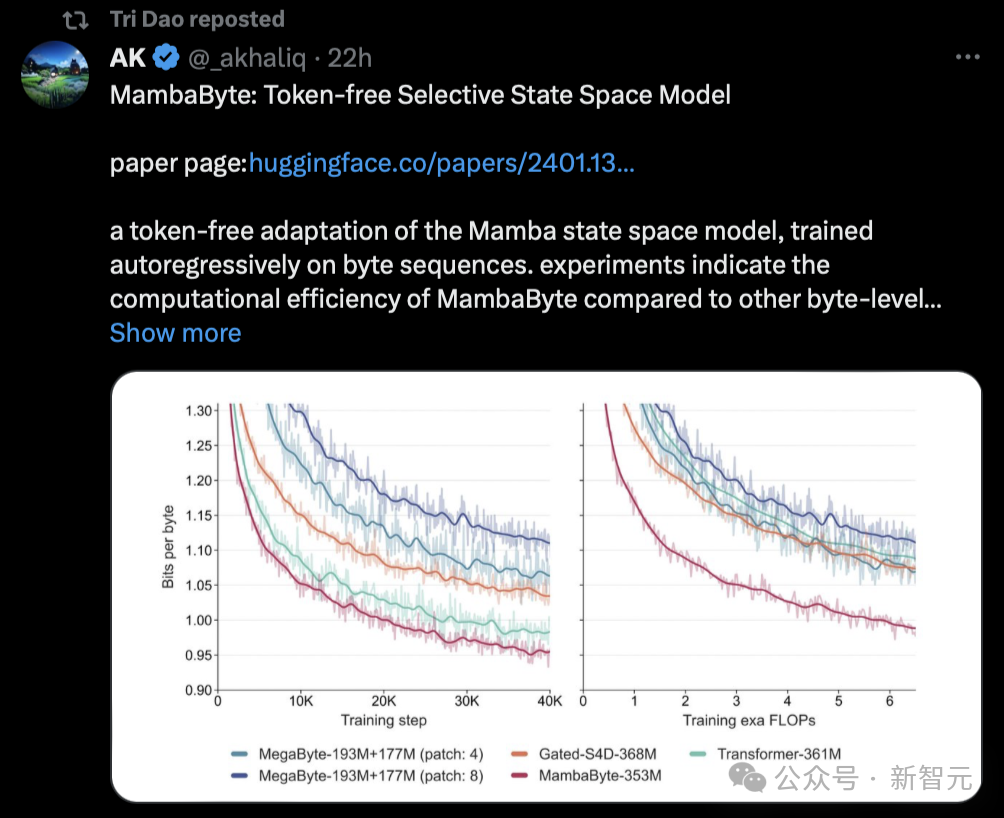
Menariknya, Sasha Rush, yang menyampaikan berita bahawa Mamba diberi markah rendah, turut menerbitkan kertas kerja baharu berdasarkan penyelidikan sedemikian hari ini - MambaByte.

Malah, seni bina Mamba telah pun mencapai status "satu percikan api boleh memulakan api padang rumput", dan pengaruhnya dalam lingkungan akademik semakin meluas.
Sesetengah netizen berkata bahawa kertas Mamba akan mula menduduki arXiv.
"Sebagai contoh, saya baru saja melihat kertas ini mencadangkan MambaByte, model ruang keadaan terpilih tanpa token. Pada asasnya, ia menyesuaikan Mamba SSM untuk belajar terus daripada token asal." Mamba Papers juga memajukan penyelidikan ini hari ini.

Makalah yang begitu popular diberi markah rendah Sesetengah orang berkata nampaknya peer review benar-benar tidak mempedulikan pemasaran.
Sebab kertas Mamba diberi markah 3
 Apakah sebab memberi markah rendah kepada kertas Mamba?
Apakah sebab memberi markah rendah kepada kertas Mamba?
Anda boleh lihat bahawa pengulas yang memberikan ulasan skor 3 mempunyai tahap keyakinan 5, bermakna dia sangat yakin dengan skor ini.
Dalam ulasan, soalan yang dibangkitkannya terbahagi kepada dua bahagian: satu mempersoalkan reka bentuk model, dan satu lagi mempersoalkan eksperimen.

- Motivasi reka bentuk Mamba adalah untuk menyelesaikan kekurangan model gelung sambil meningkatkan kecekapan model berasaskan Transformer. Terdapat banyak kajian sepanjang arah ini: S4-pepenjuru [1], SGConv [2], MEGA [3], SPADE [4], dan banyak model Transformer yang cekap (seperti [5]). Semua model ini mencapai kerumitan hampir linear, dan pengarang perlu membandingkan Mamba dengan karya ini dari segi prestasi dan kecekapan model. Berkenaan prestasi model, beberapa eksperimen mudah (seperti pemodelan bahasa di Wikitext-103) sudah memadai. - Banyak model Transformer berasaskan perhatian mempamerkan keupayaan generalisasi panjang, iaitu model boleh dilatih pada panjang jujukan yang lebih pendek dan kemudian diuji pada panjang jujukan yang lebih panjang. Beberapa contoh termasuk pengekodan kedudukan relatif (T5) dan Alibi [6]. Memandangkan SSM secara amnya berterusan, adakah Mamba mempunyai keupayaan generalisasi panjang ini?
Eksperimen

- Pengarang perlu membandingkan dengan garis dasar yang lebih kukuh. Penulis mengakui bahawa H3 digunakan sebagai motivasi untuk seni bina model. Walau bagaimanapun, mereka tidak membandingkan dengan H3 secara eksperimen. Seperti yang boleh dilihat daripada Jadual 4 dalam [7], pada set data Pile, ppl H3 masing-masing ialah 8.8 (125M), 7.1 (355M) dan 6.0 (1.3B), yang jauh lebih baik daripada Mamba. Penulis perlu menunjukkan perbandingan dengan H3. - Untuk model pra-latihan, penulis hanya menunjukkan keputusan inferens pukulan sifar. Persediaan ini agak terhad dan hasilnya tidak berfungsi dengan baik untuk menunjukkan keberkesanan Mamba. Saya mengesyorkan pengarang untuk menjalankan lebih banyak eksperimen dengan jujukan yang panjang, seperti ringkasan dokumen, di mana jujukan input secara semula jadi akan menjadi sangat panjang (cth., panjang jujukan purata set data arXiv lebih besar daripada 8k).
- Penulis mendakwa bahawa salah satu sumbangan utamanya ialah pemodelan urutan panjang. Penulis harus membandingkan dengan lebih banyak garis dasar pada LRA (Long Range Arena), yang pada asasnya merupakan penanda aras standard untuk pemahaman urutan panjang.
- Tanda aras ingatan hilang. Walaupun Bahagian 4.5 bertajuk "Tanda Aras Kelajuan dan Memori," ia hanya merangkumi perbandingan kelajuan. Di samping itu, pengarang harus menyediakan tetapan yang lebih terperinci di sebelah kiri Rajah 8, seperti lapisan model, saiz model, butiran konvolusi, dsb. Bolehkah penulis memberikan beberapa penjelasan intuitif tentang mengapa FlashAttention paling perlahan apabila panjang jujukan adalah sangat besar (Rajah 8 kiri)?
Sebagai tindak balas kepada keraguan pengulas, pengarang juga kembali membuat kerja rumahnya dan menghasilkan beberapa data percubaan untuk disangkal.
Sebagai contoh, mengenai soalan pertama mengenai reka bentuk model, penulis menyatakan bahawa pasukan itu berhasrat untuk menumpukan perhatian kepada kerumitan pra-latihan berskala besar dan bukannya penanda aras berskala kecil.
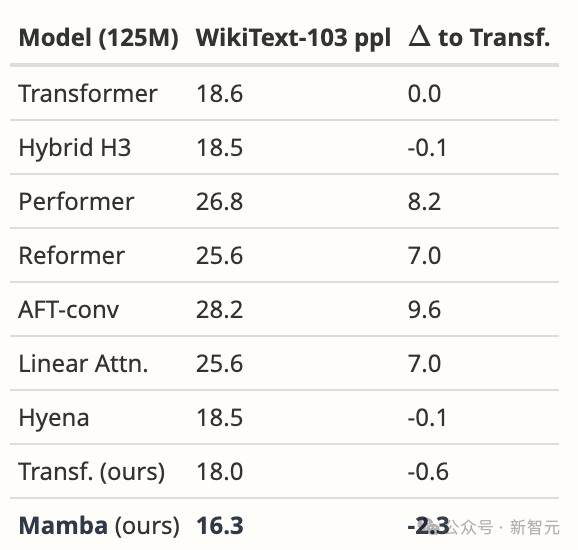
Walau bagaimanapun, Mamba mengatasi semua model yang dicadangkan dengan ketara dan lebih banyak lagi pada WikiText-103, yang kami jangkakan daripada keputusan umum kami dalam bahasa.
Pertama, kami membandingkan Mamba dalam persekitaran yang sama seperti kertas Hyena [Poli, Jadual 4.3]. Sebagai tambahan kepada data yang dilaporkan, kami juga menala garis dasar Transformer kami yang kukuh.
Kemudian, kami menukar model kepada Mamba, yang meningkatkan 1.7 ppl berbanding Transformer kami dan 2.3 ppl berbanding Transformer garis dasar yang asal. Bagi kebanyakan model jujukan dalam (termasuk FlashAttention), penggunaan memori hanya sebesar tensor pengaktifan. Malah, Mamba sangat cekap memori; kami juga mengukur keperluan memori latihan model 125M pada GPU A100 80GB. Setiap kumpulan terdiri daripada urutan panjang 2048. Kami membandingkan ini dengan pelaksanaan Transformer yang paling cekap memori yang kami ketahui (penyatuan kernel dan FlashAttention-2 menggunakan torch.compile).
Untuk butiran sanggahan lanjut, sila semak https://openreview.net/forum?id=AL1fq05o7H
Secara umum, ulasan pengulas telah diselesaikan oleh pengarang Namun, bantahan ini mereka semua tidak diendahkan oleh pengulas.
 Seseorang menemui "titik" pada pendapat pengulas ini: Mungkin dia tidak faham apa itu rnn?
Seseorang menemui "titik" pada pendapat pengulas ini: Mungkin dia tidak faham apa itu rnn?
Netizen yang menonton keseluruhan proses itu berkata bahawa keseluruhan proses itu terlalu menyakitkan untuk dibaca oleh penulis kertas itu, tetapi pengulas tidak goyah dan tidak menilai semula.
Nilai 3 dengan tahap keyakinan 5 dan abaikan sanggahan pengarang yang berasas ini terlalu menjengkelkan. 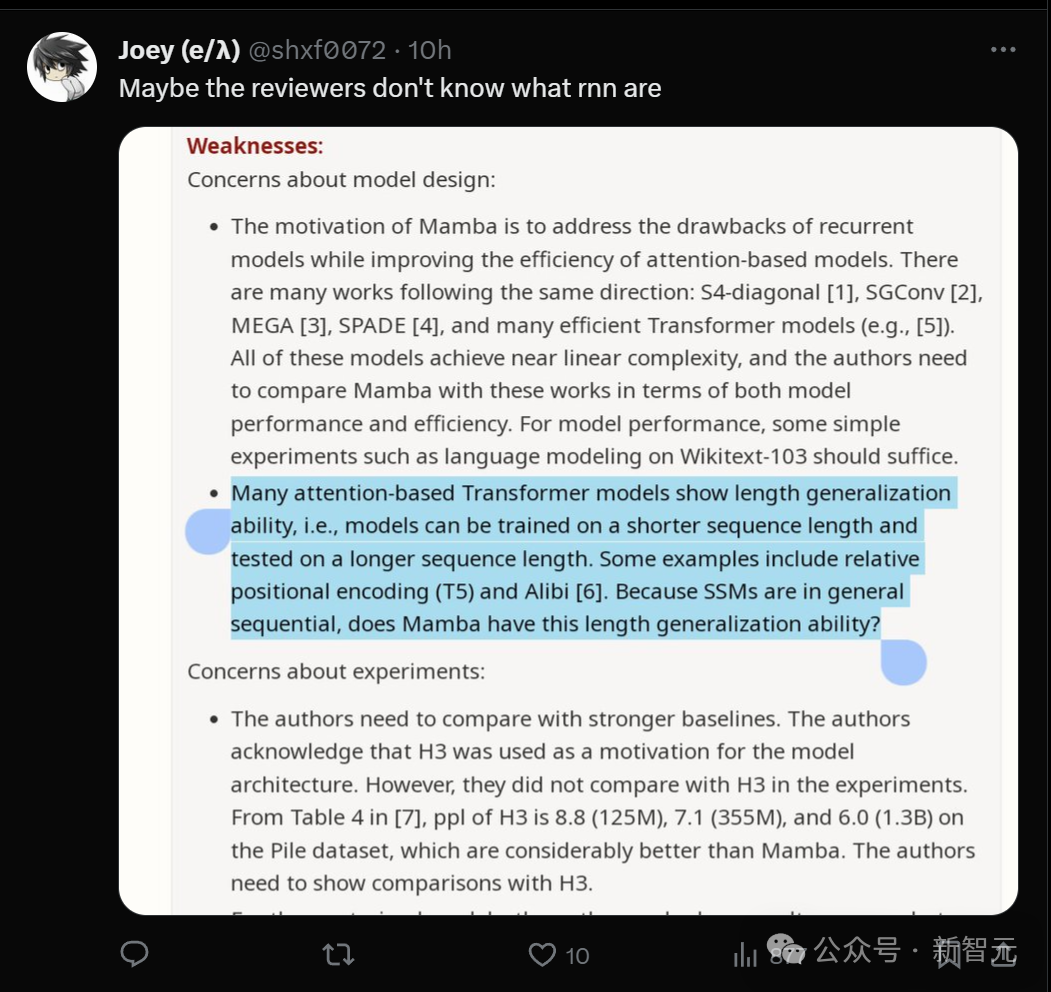
Tiga pengulas yang lain memberikan markah tinggi 6, 8 dan 8. 
Pengulas yang mendapat 6 mata menegaskan bahawa kelemahannya ialah "model masih memerlukan memori sekunder seperti Transformer semasa latihan".
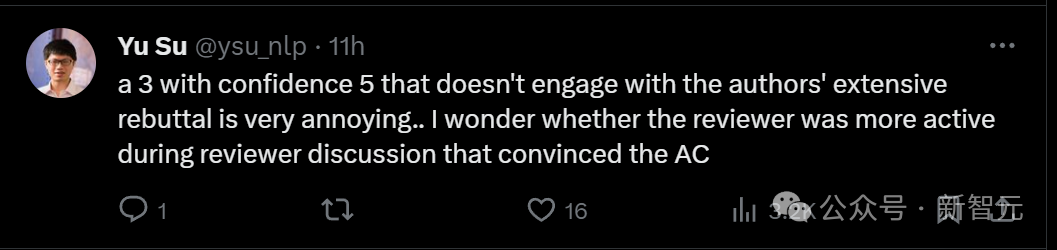
Pengulas yang mendapat 8 mata mengatakan bahawa kelemahan artikel tersebut hanyalah "kekurangan petikan kepada beberapa karya berkaitan".
Seorang lagi pengulas yang memberikan 8 mata memuji kertas tersebut sambil berkata "bahagian empirikalnya sangat teliti dan hasilnya kukuh". 
Tak jumpa pun Kelemahan.
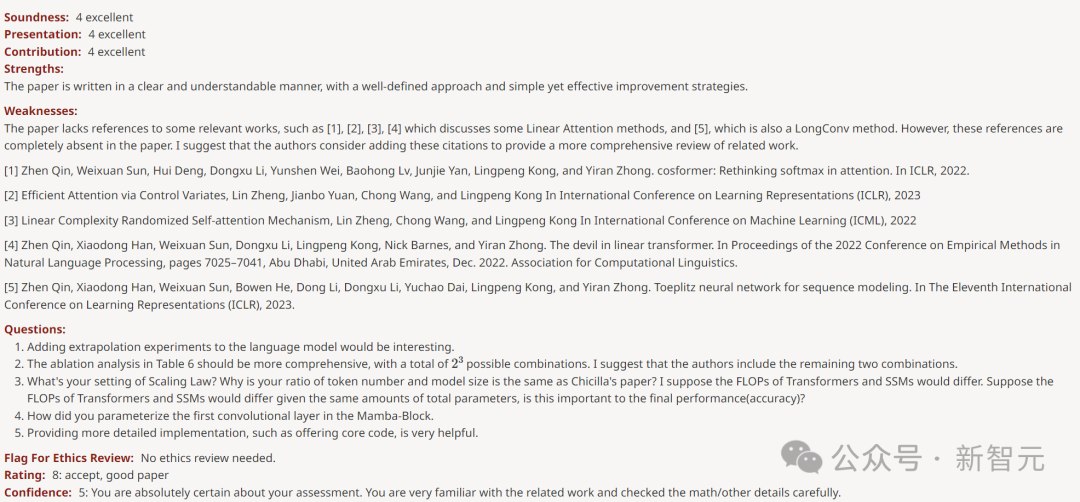
Perlu ada penjelasan untuk klasifikasi yang berbeza secara meluas. Tetapi belum ada ulasan pengulas meta.
Netizen menjerit: Dunia akademik juga merosot!
Di ruangan komen, ada yang bertanya tentang penyeksaan jiwa Siapa yang mendapat markah 3 yang rendah? ?

Jelas sekali, kertas ini telah mencapai hasil yang lebih baik dengan parameter yang sangat rendah, dan kod GitHub juga sangat jelas dan semua orang boleh mengujinya, jadi ia telah mendapat pujian di kalangan orang ramai, jadi semua orang Rasanya keterlaluan.
Sesetengah orang hanya menjerit WTF, walaupun seni bina Mamba tidak dapat mengubah corak LLM, ia adalah model yang boleh dipercayai dengan pelbagai kegunaan pada jujukan panjang. Untuk mendapatkan markah ini, adakah ia bermakna dunia akademik hari ini telah merosot?
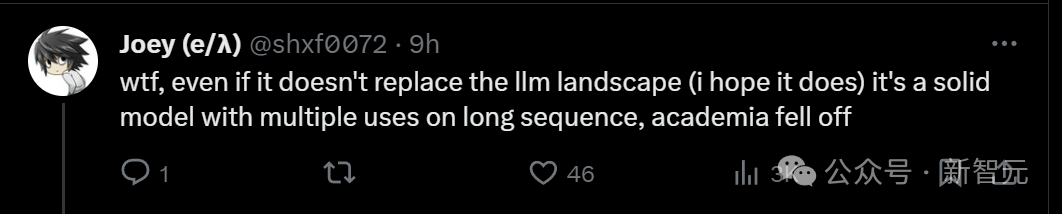
Semua orang berkata dengan penuh emosi bahawa mujurlah ini hanyalah salah satu daripada empat komen Pengulas lain memberikan markah yang tinggi dan keputusan muktamad belum dibuat lagi.
Sesetengah orang membuat spekulasi bahawa pengulas mungkin terlalu letih dan hilang pertimbangannya.
Sebab lain ialah hala tuju penyelidikan baharu seperti model State Space mungkin mengancam beberapa pengulas dan pakar yang telah mencapai pencapaian hebat dalam bidang Transformer Keadaan ini sangat rumit.
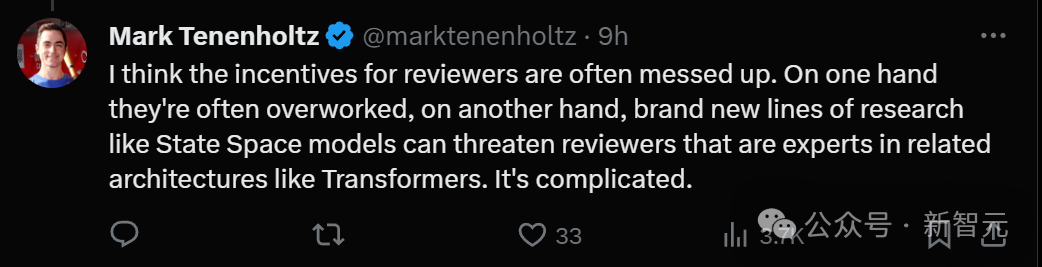
Sesetengah orang mengatakan bahawa kertas Mamba mendapat 3 mata hanyalah gurauan dalam industri.
Mereka begitu tertumpu untuk membandingkan penanda aras yang sangat halus, tetapi bahagian kertas yang benar-benar menarik ialah kejuruteraan dan kecekapan. Penyelidikan hampir mati kerana kami hanya mementingkan SOTA, walaupun pada penanda aras lapuk untuk subset medan yang sangat sempit.
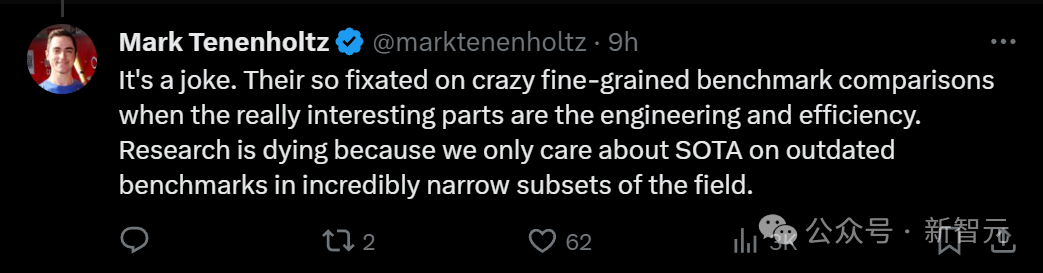
"Teori tidak mencukupi, terlalu banyak projek."
Atas ialah kandungan terperinci Kerja pecah tanah Transformer ditentang, semakan ICLR menimbulkan persoalan! Orang ramai menuduh operasi kotak hitam, LeCun mendedahkan pengalaman serupa. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Cara Melaksanakan Penyortiran Fail oleh Debian Readdir
Apr 13, 2025 am 09:06 AM
Cara Melaksanakan Penyortiran Fail oleh Debian Readdir
Apr 13, 2025 am 09:06 AM
Dalam sistem Debian, fungsi Readdir digunakan untuk membaca kandungan direktori, tetapi urutan yang dikembalikannya tidak ditentukan sebelumnya. Untuk menyusun fail dalam direktori, anda perlu membaca semua fail terlebih dahulu, dan kemudian menyusunnya menggunakan fungsi QSORT. Kod berikut menunjukkan cara menyusun fail direktori menggunakan ReadDir dan QSORT dalam sistem Debian:#termasuk#termasuk#termasuk#termasuk // fungsi perbandingan adat, yang digunakan untuk qSortintCompare (Constvoid*A, Constvoid*b) {Returnstrcmp (*(*(*(*(*(*(*(*(*(*(*(*(*(*(*(*(*(
 Cara Mengoptimumkan Prestasi Debian Readdir
Apr 13, 2025 am 08:48 AM
Cara Mengoptimumkan Prestasi Debian Readdir
Apr 13, 2025 am 08:48 AM
Dalam sistem Debian, panggilan sistem Readdir digunakan untuk membaca kandungan direktori. Jika prestasinya tidak baik, cuba strategi pengoptimuman berikut: Memudahkan bilangan fail direktori: Split direktori besar ke dalam pelbagai direktori kecil sebanyak mungkin, mengurangkan bilangan item yang diproses setiap panggilan readdir. Dayakan Caching Kandungan Direktori: Bina mekanisme cache, kemas kini cache secara teratur atau apabila kandungan direktori berubah, dan mengurangkan panggilan kerap ke Readdir. Cafh memori (seperti memcached atau redis) atau cache tempatan (seperti fail atau pangkalan data) boleh dipertimbangkan. Mengamalkan struktur data yang cekap: Sekiranya anda melaksanakan traversal direktori sendiri, pilih struktur data yang lebih cekap (seperti jadual hash dan bukannya carian linear) untuk menyimpan dan mengakses maklumat direktori
 Cara Menetapkan Tahap Log Debian Apache
Apr 13, 2025 am 08:33 AM
Cara Menetapkan Tahap Log Debian Apache
Apr 13, 2025 am 08:33 AM
Artikel ini menerangkan cara menyesuaikan tahap pembalakan pelayan Apacheweb dalam sistem Debian. Dengan mengubah suai fail konfigurasi, anda boleh mengawal tahap maklumat log yang direkodkan oleh Apache. Kaedah 1: Ubah suai fail konfigurasi utama untuk mencari fail konfigurasi: Fail konfigurasi apache2.x biasanya terletak di direktori/etc/apache2/direktori. Nama fail mungkin apache2.conf atau httpd.conf, bergantung pada kaedah pemasangan anda. Edit Fail Konfigurasi: Buka Fail Konfigurasi dengan Kebenaran Root Menggunakan Editor Teks (seperti Nano): Sudonano/ETC/APACHE2/APACHE2.CONF
 Bagaimana Debian OpenSSL Menghalang Serangan Man-dalam-Middle
Apr 13, 2025 am 10:30 AM
Bagaimana Debian OpenSSL Menghalang Serangan Man-dalam-Middle
Apr 13, 2025 am 10:30 AM
Dalam sistem Debian, OpenSSL adalah perpustakaan penting untuk pengurusan penyulitan, penyahsulitan dan sijil. Untuk mengelakkan serangan lelaki-dalam-pertengahan (MITM), langkah-langkah berikut boleh diambil: Gunakan HTTPS: Pastikan semua permintaan rangkaian menggunakan protokol HTTPS dan bukannya HTTP. HTTPS menggunakan TLS (Protokol Keselamatan Lapisan Pengangkutan) untuk menyulitkan data komunikasi untuk memastikan data tidak dicuri atau diganggu semasa penghantaran. Sahkan Sijil Pelayan: Sahkan secara manual Sijil Pelayan pada klien untuk memastikan ia boleh dipercayai. Pelayan boleh disahkan secara manual melalui kaedah perwakilan urlSession
 Kaedah pemasangan sijil SSL Server Server Debian
Apr 13, 2025 am 11:39 AM
Kaedah pemasangan sijil SSL Server Server Debian
Apr 13, 2025 am 11:39 AM
Langkah -langkah untuk memasang sijil SSL pada pelayan mel Debian adalah seperti berikut: 1. Pasang OpenSSL Toolkit terlebih dahulu, pastikan bahawa OpenSSL Toolkit telah dipasang pada sistem anda. Jika tidak dipasang, anda boleh menggunakan arahan berikut untuk memasang: sudoapt-getupdateudoapt-getinstallopenssl2. Menjana permintaan kunci dan sijil peribadi seterusnya, gunakan OpenSSL untuk menjana kunci peribadi RSA 2048-bit dan permintaan sijil (CSR): Membuka
 Petua Konfigurasi Firewall Pelayan Mel Debian
Apr 13, 2025 am 11:42 AM
Petua Konfigurasi Firewall Pelayan Mel Debian
Apr 13, 2025 am 11:42 AM
Mengkonfigurasi firewall pelayan Mail Debian adalah langkah penting dalam memastikan keselamatan pelayan. Berikut adalah beberapa kaedah konfigurasi firewall yang biasa digunakan, termasuk penggunaan iptables dan firewalld. Gunakan iptables untuk mengkonfigurasi firewall untuk memasang iptables (jika belum dipasang): sudoapt-getupdateudoapt-getinstalliplesview peraturan iptables semasa: konfigurasi sudoiptable-l
 Bagaimana Debian Readdir Bersepadu Dengan Alat Lain
Apr 13, 2025 am 09:42 AM
Bagaimana Debian Readdir Bersepadu Dengan Alat Lain
Apr 13, 2025 am 09:42 AM
Fungsi Readdir dalam sistem Debian adalah panggilan sistem yang digunakan untuk membaca kandungan direktori dan sering digunakan dalam pengaturcaraan C. Artikel ini akan menerangkan cara mengintegrasikan Readdir dengan alat lain untuk meningkatkan fungsinya. Kaedah 1: Menggabungkan Program Bahasa C dan Pipeline Pertama, tulis program C untuk memanggil fungsi Readdir dan output hasilnya:#termasuk#termasuk#includeintMain (intargc, char*argv []) {dir*dir; structdirent*entry; if (argc! = 2) {
 Cara Melakukan Pengurusan Log Debian Hadoop
Apr 13, 2025 am 10:45 AM
Cara Melakukan Pengurusan Log Debian Hadoop
Apr 13, 2025 am 10:45 AM
Menguruskan Log Hadoop pada Debian, anda boleh mengikuti langkah-langkah berikut dan amalan terbaik: Agregasi log membolehkan pengagregatan log: tetapkan benang.log-agregasi-enable untuk benar dalam fail benang-site.xml untuk membolehkan pengagregatan log. Konfigurasikan dasar pengekalan log: tetapkan yarn.log-aggregasi.Retain-seconds Untuk menentukan masa pengekalan log, seperti 172800 saat (2 hari). Nyatakan Laluan Penyimpanan Log: Melalui Benang
