
 Peranti teknologi
AI
Mengapa ICLR tidak menerima kertas Mamba? Komuniti AI telah mencetuskan perbincangan besar
Peranti teknologi
AI
Mengapa ICLR tidak menerima kertas Mamba? Komuniti AI telah mencetuskan perbincangan besar
Mengapa ICLR tidak menerima kertas Mamba? Komuniti AI telah mencetuskan perbincangan besar

Pada tahun 2023, status Transformer, pemain dominan dalam bidang model besar AI, akan mula dicabar. Seni bina baharu yang dipanggil "Mamba" telah muncul Ia adalah model ruang keadaan terpilih yang setanding dengan Transformer dalam pemodelan bahasa, dan mungkin mengatasinya. Pada masa yang sama, Mamba boleh mencapai penskalaan linear apabila panjang konteks meningkat, yang membolehkannya mengendalikan jujukan panjang jutaan perkataan dan meningkatkan daya pemprosesan inferens sebanyak 5 kali apabila memproses data sebenar. Peningkatan prestasi terobosan ini menarik perhatian dan membawa kemungkinan baharu kepada pembangunan bidang AI.
Lebih sebulan selepas dikeluarkan, Mamba mula menunjukkan pengaruhnya secara beransur-ansur dan melahirkan banyak projek seperti MoE-Mamba, Vision Mamba, VMamba, U-Mamba, MambaByte, dll. Mamba telah menunjukkan potensi yang besar dalam mengatasi kelemahan Transformer secara berterusan. Perkembangan ini menunjukkan perkembangan dan kemajuan berterusan Mamba, membawa kemungkinan baharu kepada bidang kecerdasan buatan.
Walau bagaimanapun, "bintang" yang semakin meningkat ini menghadapi kemunduran pada mesyuarat ICLR 2024. Keputusan awam terkini menunjukkan bahawa kertas Mamba masih belum selesai Kami hanya dapat melihat namanya dalam lajur keputusan yang belum selesai, dan kami tidak dapat menentukan sama ada ia ditangguhkan atau ditolak.

Secara keseluruhan, Mamba menerima penilaian daripada empat pengulas, iaitu 8/8/6/3 masing-masing. Sesetengah orang berkata ia benar-benar membingungkan untuk masih ditolak selepas menerima penarafan sedemikian.

Untuk memahami sebabnya, kita perlu melihat apa yang dikatakan oleh pengulas yang memberi markah rendah.
Halaman semakan kertas: https://openreview.net/forum?id=AL1fq05o7H
Kenapa "tidak cukup bagus"?
Dalam maklum balas ulasan, pengulas yang memberi skor "3: tolak, tidak cukup bagus" menjelaskan beberapa pendapat tentang Mamba:
Pemikiran tentang reka bentuk model:
- alamat motivasi Mamba is to's kelemahan model rekursif sambil meningkatkan kecekapan model berasaskan perhatian. Terdapat banyak kajian sepanjang arah ini: S4-pepenjuru [1], SGConv [2], MEGA [3], SPADE [4], dan banyak model Transformer yang cekap (cth. [5]). Kesemua model ini mencapai kerumitan hampir linear dan penulis perlu membandingkan Mamba dengan karya ini dari segi prestasi dan kecekapan model. Berkenaan prestasi model, beberapa eksperimen mudah (seperti pemodelan bahasa Wikitext-103) adalah mencukupi.
- Banyak model Transformer berasaskan perhatian menunjukkan keupayaan generalisasi panjang, iaitu model boleh dilatih pada panjang jujukan yang lebih pendek dan diuji pada panjang jujukan yang lebih panjang. Contohnya termasuk pengekodan kedudukan relatif (T5) dan Alibi [6]. Memandangkan SSM secara amnya berterusan, adakah Mamba mempunyai keupayaan generalisasi panjang ini?
Pemikiran tentang eksperimen:
- Pengarang perlu membandingkan dengan garis dasar yang lebih kukuh. Penulis menyatakan bahawa H3 digunakan sebagai motivasi untuk seni bina model, namun mereka tidak membandingkan dengan H3 dalam eksperimen. Menurut Jadual 4 dalam [7], pada dataset Pile, ppl H3 masing-masing ialah 8.8 (1.25 M), 7.1 (3.55 M), dan 6.0 (1.3B), yang jauh lebih baik daripada Mamba. Penulis perlu menunjukkan perbandingan dengan H3.
- Untuk model pra-latihan, penulis hanya menunjukkan keputusan inferens sampel sifar. Persediaan ini agak terhad dan hasilnya tidak menyokong keberkesanan Mamba dengan baik. Saya mengesyorkan agar pengarang menjalankan lebih banyak percubaan dengan jujukan yang panjang, seperti ringkasan dokumen, dengan jujukan input secara semula jadi sangat panjang (cth., panjang jujukan purata set data arXiv ialah >8k).
- Pengarang mendakwa bahawa salah satu sumbangan utamanya ialah pemodelan urutan panjang. Penulis harus membandingkan dengan lebih banyak garis dasar pada LRA (Long Range Arena), yang pada asasnya merupakan penanda aras standard untuk pemahaman urutan panjang.
- Tiada tanda aras ingatan. Walaupun Bahagian 4.5 bertajuk "Tanda Aras Kelajuan dan Memori," hanya perbandingan kelajuan dibentangkan. Di samping itu, pengarang harus menyediakan tetapan yang lebih terperinci di sebelah kiri Rajah 8, seperti lapisan model, saiz model, butiran konvolusi, dsb. Bolehkah penulis memberikan sedikit intuisi tentang mengapa FlashAttention paling perlahan apabila panjang jujukan adalah sangat besar (Rajah 8 kiri)?
Di samping itu, pengulas lain juga menunjukkan kelemahan Mamba: model itu masih mempunyai keperluan memori sekunder semasa latihan seperti Transformers.
Pengarang: Disemak, sila semak semula
Selepas merumuskan pendapat semua pengulas, pasukan pengarang juga menyemak dan menambah baik kandungan kertas kerja, dan menambah keputusan dan analisis eksperimen baharu:
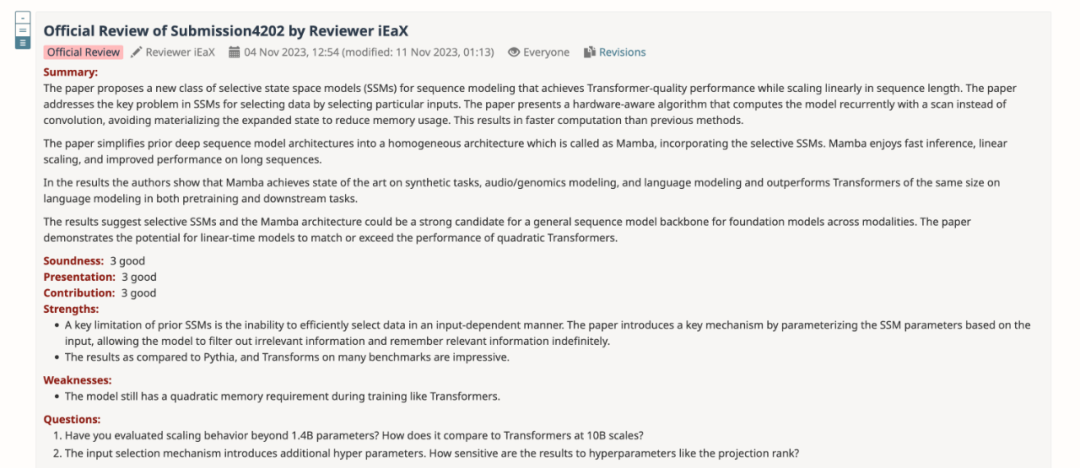
- Keputusan Penilaian Tambahan Model H3
Pengarang memuat turun model H3 terlatih dengan saiz parameter 125M-2.7B dan menjalankan beberapa siri penilaian. Mamba adalah jauh lebih baik dalam semua penilaian bahasa Perlu diingat bahawa model H3 ini adalah model hibrid menggunakan perhatian kuadratik, manakala model tulen pengarang hanya menggunakan lapisan Mamba masa linear adalah lebih baik dalam semua penunjuk.
Perbandingan penilaian dengan model H3 pra-terlatih adalah seperti berikut:
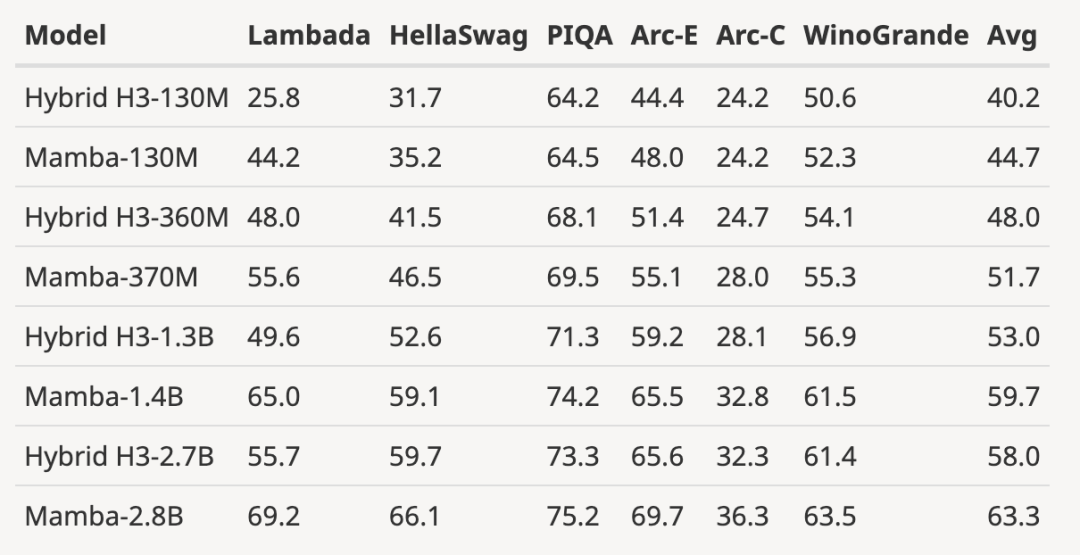
- Menskalakan model terlatih sepenuhnya kepada saiz model yang lebih besar seperti yang ditunjukkan di bawah
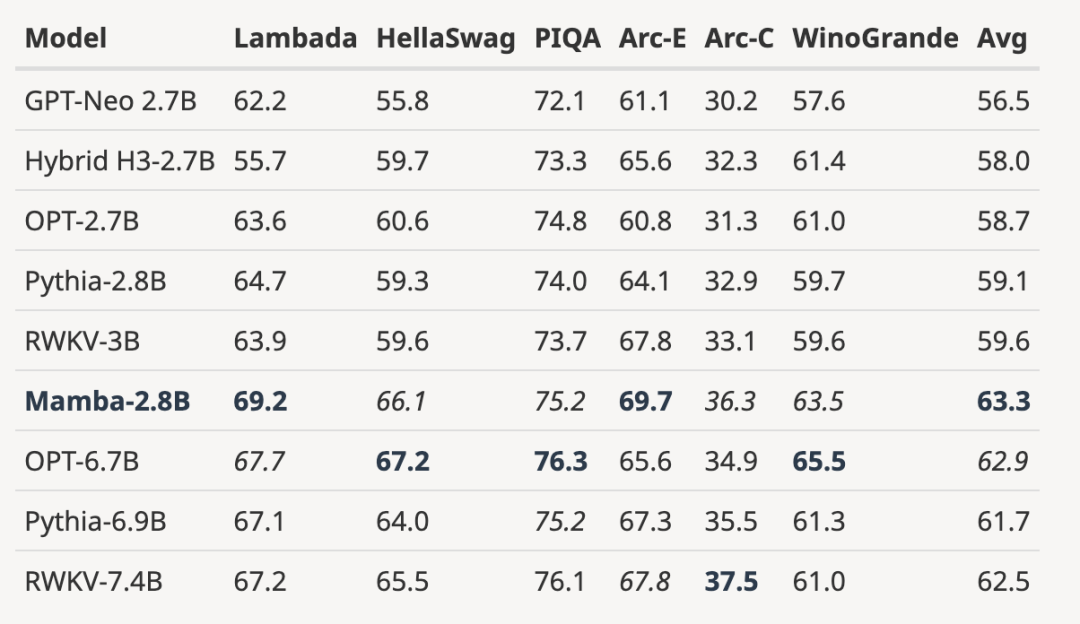
, berbanding dengan Berbanding dengan model sumber terbuka 3B yang dilatih dengan bilangan token yang sama (300B), Mamba lebih unggul dalam setiap keputusan penilaian. Ia juga setanding dengan model skala 7B: apabila membandingkan Mamba (2.8B) dengan OPT, Pythia dan RWKV (7B), Mamba mencapai skor purata terbaik dan terbaik/saat terbaik pada setiap Skor penanda aras.
- Menunjukkan hasil ekstrapolasi panjang di luar panjang latihan
Penulis telah melampirkan angka yang menilai panjang ekstrapolasi model bahasa parametrik 3B pra-terlatih:
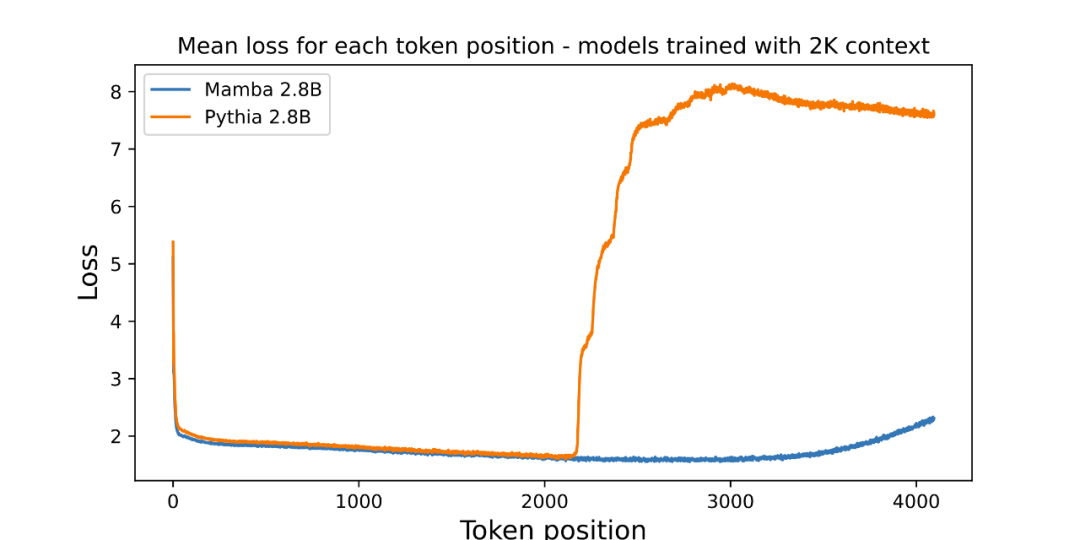
Graf memplot purata kerugian setiap kedudukan (kebolehbacaan log). Kebingungan token pertama adalah tinggi kerana ia tidak mempunyai konteks, manakala kebingungan kedua-dua Mamba dan Transformer garis dasar (Pythia) meningkat sebelum panjang konteks latihan (2048). Menariknya, kebolehlarutan Mamba bertambah baik dengan ketara di luar konteks latihannya, sehingga panjang sekitar 3000.
Pengarang menekankan bahawa ekstrapolasi panjang bukanlah motivasi langsung model dalam artikel ini, tetapi menganggapnya sebagai ciri tambahan:
- Model garis dasar (Pythia) di sini tidak menganggap ekstrapolasi panjang semasa latihan, Mungkin terdapat varian Transformer lain yang lebih serba boleh (seperti pengekodan kedudukan relatif T5 atau Alibi).
- Tidak menemui sebarang model 3B sumber terbuka yang dilatih pada Pile menggunakan pengekodan kedudukan relatif, jadi perbandingan ini tidak boleh dibuat.
- Mamba, seperti Pythia, tidak menganggap ekstrapolasi panjang semasa latihan, jadi ia tidak dapat dibandingkan. Sama seperti Transformers mempunyai banyak teknik (seperti benam kedudukan yang berbeza) untuk meningkatkan keupayaan mereka pada isometrik generalisasi panjang, mungkin menarik dalam kerja masa hadapan untuk memperoleh teknik khusus SSM untuk keupayaan yang serupa. .
Walaupun begitu, dua bulan telah berlalu, dan kertas kerja ini masih dalam proses "Decision Pending", tanpa keputusan yang jelas "penerimaan" atau "penolakan".
Kertas kerja yang ditolak oleh persidangan teratas
Dalam persidangan teratas AI utama, "letupan dalam bilangan penyerahan" adalah masalah yang menyusahkan, jadi pengulas yang mempunyai tenaga terhad pasti akan melakukan kesilapan. Ini telah menyebabkan penolakan banyak kertas terkenal dalam sejarah, termasuk YOLO, transformer XL, Dropout, mesin vektor sokongan (SVM), penyulingan pengetahuan, SIFT, dan algoritma ranking halaman web enjin carian Google PageRank (lihat: "YOLO dan PageRank yang terkenal penyelidikan yang berpengaruh telah ditolak oleh persidangan CS teratas").
Malah Yann LeCun, salah satu daripada tiga gergasi pembelajaran mendalam, juga merupakan pembuat kertas utama yang sering ditolak. Baru-baru ini, dia menulis tweet bahawa kertas kerjanya "Deep Convolutional Networks on Graph-Structured Data", yang telah dipetik sebanyak 1887 kali, juga telah ditolak oleh persidangan teratas.
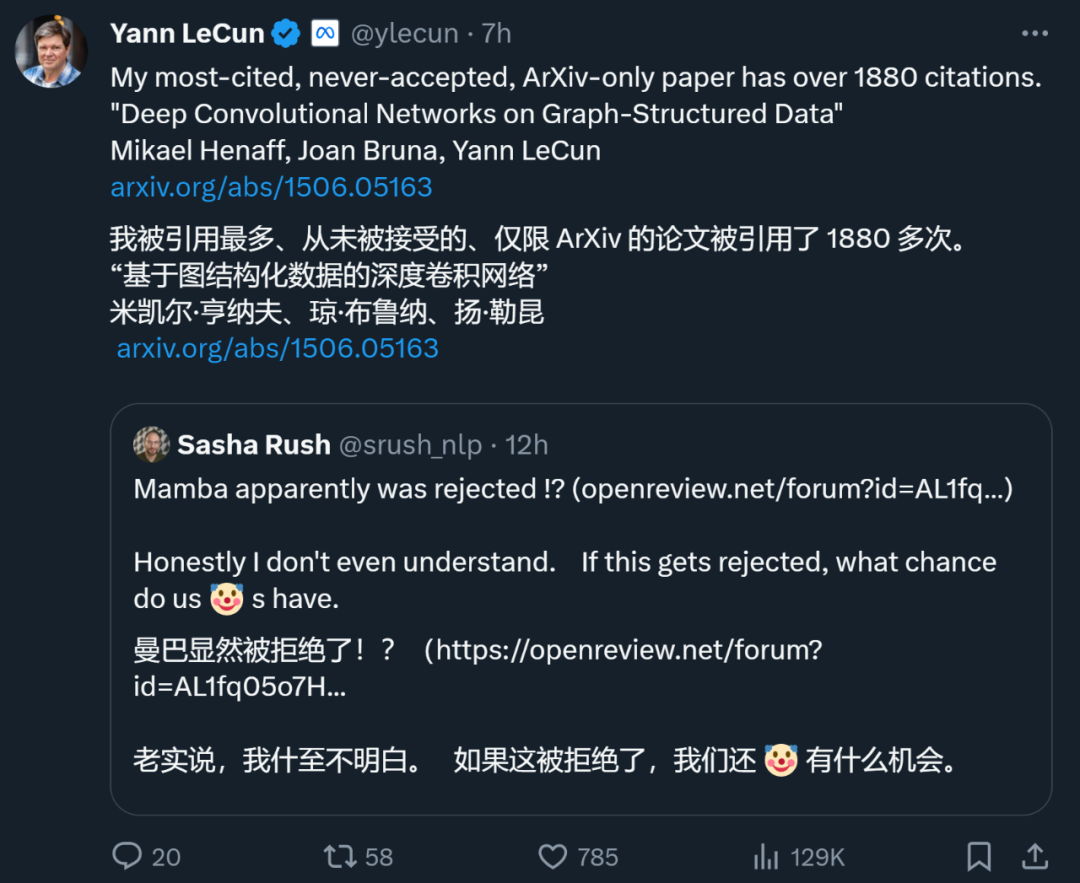
Semasa ICML 2022, dia juga "menyerahkan tiga artikel dan tiga telah ditolak."

Jadi, hanya kerana kertas itu ditolak oleh persidangan tertentu tidak bermakna ia tidak mempunyai nilai. Di antara kertas yang ditolak yang disebutkan di atas, ramai yang memilih untuk berpindah ke persidangan lain dan akhirnya diterima. Oleh itu, netizen mencadangkan agar Mamba bertukar kepada COLM yang ditubuhkan oleh ulama muda seperti Chen Danqi. COLM ialah tempat akademik yang dikhususkan untuk penyelidikan pemodelan bahasa, menumpukan pada pemahaman, penambahbaikan dan mengulas tentang pembangunan teknologi model bahasa, dan mungkin pilihan yang lebih baik untuk kertas kerja seperti Mamba.
Walau bagaimanapun, tidak kira sama ada Mamba akhirnya diterima oleh ICLR, ia telah menjadi karya yang berpengaruh, dan ia juga telah memberi harapan kepada masyarakat untuk menembusi belenggu Transformer, menyuntik harapan kepada penerokaan di luar tradisi tradisional. Model pengubah.
Atas ialah kandungan terperinci Mengapa ICLR tidak menerima kertas Mamba? Komuniti AI telah mencetuskan perbincangan besar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1382
1382
 52
52

 Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Perintah shutdown CentOS adalah penutupan, dan sintaks adalah tutup [pilihan] [maklumat]. Pilihan termasuk: -h menghentikan sistem dengan segera; -P mematikan kuasa selepas penutupan; -r mulakan semula; -T Waktu Menunggu. Masa boleh ditentukan sebagai segera (sekarang), minit (minit), atau masa tertentu (HH: mm). Maklumat tambahan boleh dipaparkan dalam mesej sistem.
 Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Dasar sandaran dan pemulihan Gitlab di bawah sistem CentOS untuk memastikan keselamatan data dan pemulihan, Gitlab pada CentOS menyediakan pelbagai kaedah sandaran. Artikel ini akan memperkenalkan beberapa kaedah sandaran biasa, parameter konfigurasi dan proses pemulihan secara terperinci untuk membantu anda menubuhkan strategi sandaran dan pemulihan GitLab lengkap. 1. Backup Manual Gunakan Gitlab-Rakegitlab: Backup: Buat Perintah untuk Melaksanakan Backup Manual. Perintah ini menyokong maklumat utama seperti repositori Gitlab, pangkalan data, pengguna, kumpulan pengguna, kunci, dan kebenaran. Fail sandaran lalai disimpan dalam direktori/var/opt/gitlab/sandaran. Anda boleh mengubah suai /etc /gitlab
 Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Panduan Lengkap untuk Memeriksa Konfigurasi HDFS Dalam Sistem CentOS Artikel ini akan membimbing anda bagaimana untuk memeriksa konfigurasi dan menjalankan status HDFS secara berkesan pada sistem CentOS. Langkah -langkah berikut akan membantu anda memahami sepenuhnya persediaan dan operasi HDFS. Sahkan Pembolehubah Alam Sekitar Hadoop: Pertama, pastikan pembolehubah persekitaran Hadoop ditetapkan dengan betul. Di terminal, laksanakan arahan berikut untuk mengesahkan bahawa Hadoop dipasang dan dikonfigurasi dengan betul: Hadoopversion Semak fail konfigurasi HDFS: Fail konfigurasi teras HDFS terletak di/etc/hadoop/conf/direktori, di mana core-site.xml dan hdfs-site.xml adalah kritikal. gunakan
 Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Membolehkan pecutan GPU pytorch pada sistem CentOS memerlukan pemasangan cuda, cudnn dan GPU versi pytorch. Langkah-langkah berikut akan membimbing anda melalui proses: Pemasangan CUDA dan CUDNN Tentukan keserasian versi CUDA: Gunakan perintah NVIDIA-SMI untuk melihat versi CUDA yang disokong oleh kad grafik NVIDIA anda. Sebagai contoh, kad grafik MX450 anda boleh menyokong CUDA11.1 atau lebih tinggi. Muat turun dan pasang Cudatoolkit: Lawati laman web rasmi Nvidiacudatoolkit dan muat turun dan pasang versi yang sepadan mengikut versi CUDA tertinggi yang disokong oleh kad grafik anda. Pasang Perpustakaan Cudnn:
 Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Docker menggunakan ciri -ciri kernel Linux untuk menyediakan persekitaran berjalan yang cekap dan terpencil. Prinsip kerjanya adalah seperti berikut: 1. Cermin digunakan sebagai templat baca sahaja, yang mengandungi semua yang anda perlukan untuk menjalankan aplikasi; 2. Sistem Fail Kesatuan (Unionfs) menyusun pelbagai sistem fail, hanya menyimpan perbezaan, menjimatkan ruang dan mempercepatkan; 3. Daemon menguruskan cermin dan bekas, dan pelanggan menggunakannya untuk interaksi; 4. Ruang nama dan cgroups melaksanakan pengasingan kontena dan batasan sumber; 5. Pelbagai mod rangkaian menyokong interkoneksi kontena. Hanya dengan memahami konsep -konsep teras ini, anda boleh menggunakan Docker dengan lebih baik.
 CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
Memasang MySQL pada CentOS melibatkan langkah -langkah berikut: Menambah sumber MySQL YUM yang sesuai. Jalankan YUM Pasang Perintah MySQL-Server untuk memasang pelayan MySQL. Gunakan perintah mysql_secure_installation untuk membuat tetapan keselamatan, seperti menetapkan kata laluan pengguna root. Sesuaikan fail konfigurasi MySQL seperti yang diperlukan. Tune parameter MySQL dan mengoptimumkan pangkalan data untuk prestasi.
 CentOS8 memulakan semula SSH
Apr 14, 2025 pm 09:00 PM
CentOS8 memulakan semula SSH
Apr 14, 2025 pm 09:00 PM
Perintah untuk memulakan semula perkhidmatan SSH ialah: Sistem Restart SSHD. Langkah -langkah terperinci: 1. Akses terminal dan sambungkan ke pelayan; 2. Masukkan arahan: SistemCtl Restart SSHD; 3. Sahkan Status Perkhidmatan: Status Sistem SSHD.
 Cara Mengendalikan Latihan Pittorch Diagihkan di Centos
Apr 14, 2025 pm 06:36 PM
Cara Mengendalikan Latihan Pittorch Diagihkan di Centos
Apr 14, 2025 pm 06:36 PM
Latihan yang diedarkan Pytorch pada sistem CentOS memerlukan langkah -langkah berikut: Pemasangan Pytorch: Premisnya ialah Python dan PIP dipasang dalam sistem CentOS. Bergantung pada versi CUDA anda, dapatkan arahan pemasangan yang sesuai dari laman web rasmi Pytorch. Untuk latihan CPU sahaja, anda boleh menggunakan arahan berikut: PipinstallToRchTorchVisionTorchaudio Jika anda memerlukan sokongan GPU, pastikan versi CUDA dan CUDNN yang sama dipasang dan gunakan versi pytorch yang sepadan untuk pemasangan. Konfigurasi Alam Sekitar Teragih: Latihan yang diedarkan biasanya memerlukan pelbagai mesin atau mesin berbilang mesin tunggal. Tempat
