

Gabungan pelbagai model besar heterogen membawa hasil yang menakjubkan

Dengan kejayaan model bahasa besar seperti LLaMA dan Mistral, banyak syarikat telah mula mencipta model bahasa besar mereka sendiri. Walau bagaimanapun, melatih model baharu dari awal adalah mahal dan mungkin mempunyai keupayaan yang berlebihan.
Baru-baru ini, penyelidik dari Universiti Sun Yat-sen dan Tencent AI Lab mencadangkan FuseLLM, yang digunakan untuk "menggabungkan berbilang model besar heterogen."
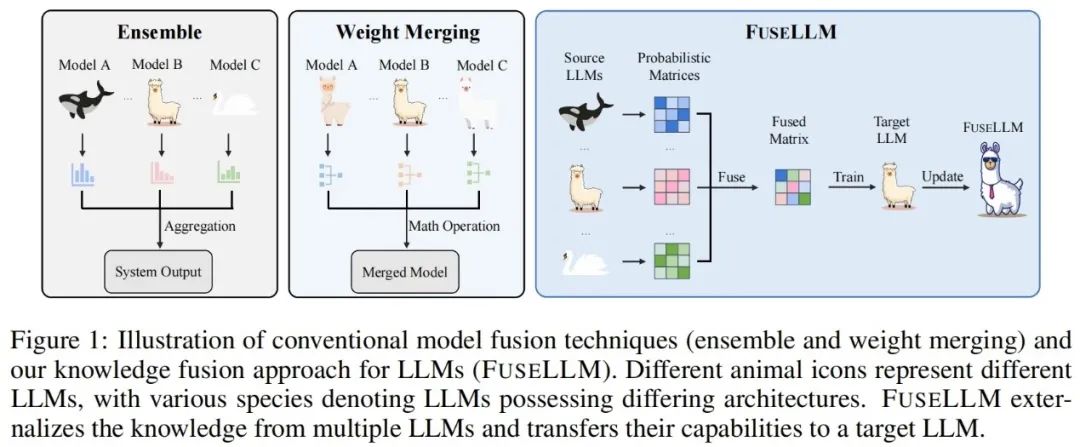
Berbeza daripada kaedah penyepaduan model tradisional dan penggabungan berat, FuseLLM menyediakan cara baharu untuk menggabungkan pengetahuan pelbagai model bahasa besar yang heterogen. Daripada menggunakan berbilang model bahasa besar pada masa yang sama atau memerlukan penggabungan hasil model, FuseLLM menggunakan kaedah latihan berterusan yang ringan untuk memindahkan pengetahuan dan keupayaan model individu ke dalam model bahasa besar yang digabungkan. Apa yang unik tentang pendekatan ini ialah keupayaannya untuk menggunakan pelbagai model bahasa besar yang heterogen pada masa inferens dan mengeksternalkan pengetahuan mereka ke dalam model bercantum. Dengan cara ini, FuseLLM meningkatkan prestasi dan kecekapan model dengan berkesan.
Makalah ini baru sahaja diterbitkan di arXiv dan telah menarik perhatian dan kiriman daripada netizen.

Seseorang fikir ia menarik untuk melatih model dalam bahasa lain dan saya telah memikirkannya.
Pada masa ini kertas kerja ini telah diterima oleh ICLR 2024.

- Tajuk kertas: Gabungan Pengetahuan Model Bahasa Besar
- Alamat kertas: https://absxiv/4
- Gudang Kertas: https://github.com/fanqiwan/FuseLLM
Kunci kepada FuseLLM ialah meneroka gabungan model bahasa besar dari perspektif kebarangkalian input yang sama teks, pengarang Perwakilan yang dihasilkan oleh model bahasa besar yang berbeza dianggap mencerminkan pengetahuan intrinsik mereka dalam memahami teks ini. Oleh itu, FuseLLM mula-mula menggunakan model bahasa besar berbilang sumber untuk menjana perwakilan, mengeksternalkan pengetahuan kolektif mereka dan kelebihan masing-masing, kemudian menyepadukan berbilang perwakilan yang dijana untuk saling melengkapi, dan akhirnya berhijrah ke model bahasa besar sasaran melalui latihan berterusan yang ringan. Rajah di bawah menunjukkan gambaran keseluruhan pendekatan FuseLLM.
Untuk menggabungkan pengetahuan kolektif berbilang model bahasa besar sambil mengekalkan kelebihan masing-masing, strategi untuk perwakilan yang dijana model gabungan perlu direka dengan teliti. Secara khususnya, FuseLLM menilai sejauh mana model bahasa besar yang berbeza memahami teks ini dengan mengira entropi silang antara perwakilan yang dijana dan teks label, dan kemudian memperkenalkan dua fungsi gabungan berasaskan entropi silang:
- MinCE: Input Berbilang besar model menjana perwakilan untuk teks semasa, dan mengeluarkan perwakilan dengan entropi silang terkecil
- AvgCE: Masukkan perwakilan yang dijana oleh berbilang model besar untuk teks semasa dan keluarkan perwakilan purata wajaran berdasarkan berat yang diperoleh dengan silang; entropi;
Hasil eksperimen
Dalam bahagian eksperimen, penulis mempertimbangkan senario gabungan model bahasa besar yang umum tetapi mencabar, di mana model sumber mempunyai persamaan kecil dalam struktur atau keupayaan. Secara khusus, ia menjalankan eksperimen pada skala 7B dan memilih tiga model sumber terbuka yang mewakili: Llama-2, OpenLLaMA dan MPT sebagai model besar untuk digabungkan.
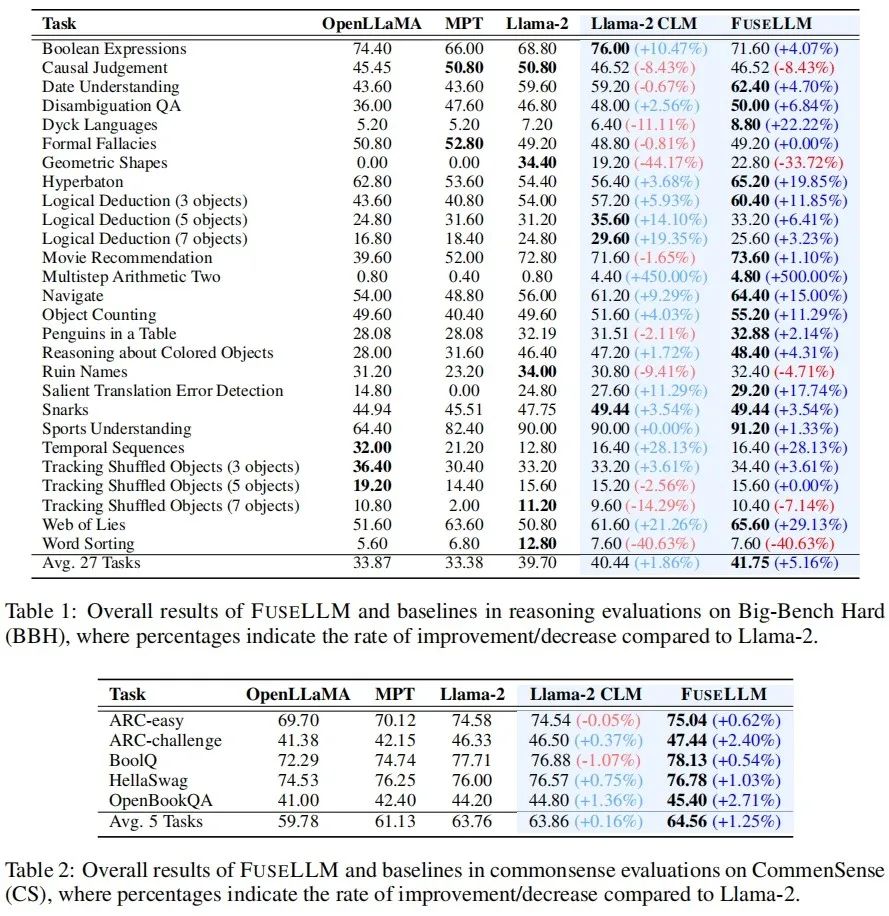
Pengarang menilai FuseLLM dalam senario seperti penaakulan umum, penaakulan akal, penjanaan kod, penjanaan teks dan arahan yang mengikuti, dan mendapati ia mencapai peningkatan prestasi yang ketara berbanding semua model sumber dan model garis dasar latihan yang berterusan. . peningkatan purata sebanyak 1.86% telah dicapai pada setiap tugas, manakala FuseLLM telah mencapai peningkatan 5.16% berbanding Llama-2, yang jauh lebih baik daripada Llama-2 CLM, menunjukkan bahawa FuseLLM boleh menggabungkan kelebihan berbilang model bahasa besar untuk mencapai penambahbaikan prestasi.
Pada Penanda Aras Common Sense, yang menguji keupayaan penaakulan akal, FuseLLM mengatasi semua model sumber dan model asas, mencapai prestasi terbaik pada semua tugas. . 6.36%. Sebab mengapa FuseLLM tidak mengatasi MPT dan OpenLLaMA mungkin disebabkan oleh penggunaan Llama-2 sebagai model bahasa besar sasaran, yang mempunyai keupayaan penjanaan kod yang lemah dan bahagian data kod yang rendah dalam korpus latihan berterusan, menyumbang hanya kira-kira 7.59%. Pada tanda aras penjanaan berbilang teks yang mengukur jawapan soalan pengetahuan (TrivialQA), pemahaman bacaan (DROP), analisis kandungan (LAMBADA), terjemahan mesin (IWSLT2017) dan aplikasi teorem (SciBench), FuseLLM juga mengatasi semua tugas mengatasi semua sumber model dan mengatasi prestasi Llama-2 CLM dalam 80% tugasan.
Oleh kerana FuseLLM hanya perlu mengekstrak perwakilan model berbilang sumber untuk gabungan, dan kemudian terus melatih model sasaran yang besar, ia juga boleh digunakan secara berterusan untuk memperhalusi model bahasa dengan arahan. Pada Penanda Aras Vicuna, yang menilai keupayaan mengikut arahan, FuseLLM juga mencapai prestasi cemerlang, mengatasi semua model sumber dan CLM. FuseLLM lwn. Penyulingan Pengetahuan & integrasi model & penggabungan berat

Memandangkan penyulingan pengetahuan juga merupakan satu kaedah untuk mempertingkatkan penyulingan pengetahuan untuk mempertingkatkan penggunaan bahasa LLM. dan Llama- 2 13B suling Llama-2 KD dibandingkan. Keputusan menunjukkan bahawa FuseLLM mengatasi penyulingan daripada model 13B tunggal dengan menggabungkan tiga model 7B dengan seni bina yang berbeza.
Untuk membandingkan FuseLLM dengan kaedah gabungan sedia ada (seperti model ensembel dan penggabungan berat), penulis mensimulasikan senario di mana pelbagai model sumber datang daripada model asas struktur yang sama, tetapi dilatih secara berterusan pada korpora yang berbeza , dan menguji kebingungan pelbagai kaedah pada penanda aras ujian yang berbeza. Ia boleh dilihat bahawa walaupun semua teknik gabungan boleh menggabungkan kelebihan model berbilang sumber, FuseLLM boleh mencapai kebingungan purata terendah, menunjukkan bahawa FuseLLM mempunyai potensi untuk menggabungkan pengetahuan kolektif model sumber dengan lebih berkesan daripada kaedah ensembel model dan penggabungan berat.
Akhirnya, walaupun masyarakat kini memberi perhatian kepada gabungan model besar, pendekatan semasa kebanyakannya berdasarkan penggabungan berat dan tidak boleh diperluaskan kepada model senario gabungan struktur dan saiz yang berbeza. Walaupun FuseLLM hanyalah penyelidikan awal mengenai gabungan model heterogen, memandangkan pada masa ini terdapat sebilangan besar model besar bahasa, visual, audio dan pelbagai mod struktur dan saiz yang berbeza dalam komuniti teknikal, apakah gabungan model heterogen ini. meletus pada masa hadapan? Mari tunggu dan lihat! 
Atas ialah kandungan terperinci Gabungan pelbagai model besar heterogen membawa hasil yang menakjubkan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!
Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Apakah carta analisis struktur produk bitcoin? Bagaimana melukis?
Apr 21, 2025 pm 07:42 PM
Apakah carta analisis struktur produk bitcoin? Bagaimana melukis?
Apr 21, 2025 pm 07:42 PM
Langkah -langkah untuk menarik carta analisis struktur bitcoin termasuk: 1. Tentukan tujuan dan penonton lukisan, 2 Pilih alat yang betul, 3. Reka bentuk rangka kerja dan isikan komponen teras, 4. Langkah -langkah lengkap memastikan bahawa carta adalah tepat dan mudah difahami.
 Apakah yang dimaksudkan dengan transaksi rantaian rantaian? Apakah urus niaga salib?
Apr 21, 2025 pm 11:39 PM
Apakah yang dimaksudkan dengan transaksi rantaian rantaian? Apakah urus niaga salib?
Apr 21, 2025 pm 11:39 PM
Pertukaran yang menyokong urus niaga rantaian: 1. Binance, 2. Uniswap, 3 Sushiswap, 4. Kewangan Curve, 5. Thorchain, 6. 1 inci Pertukaran, 7.
 Aavenomics adalah cadangan untuk mengubah suai token protokol AAVE dan memperkenalkan pembelian semula token, yang telah mencapai bilangan kuorum orang.
Apr 21, 2025 pm 06:24 PM
Aavenomics adalah cadangan untuk mengubah suai token protokol AAVE dan memperkenalkan pembelian semula token, yang telah mencapai bilangan kuorum orang.
Apr 21, 2025 pm 06:24 PM
Aavenomics adalah cadangan untuk mengubah token protokol AAVE dan memperkenalkan repos token, yang telah melaksanakan kuorum untuk Aavedao. Marc Zeller, pengasas Rantaian Projek AAVE (ACI), mengumumkan ini pada X, dengan menyatakan bahawa ia menandakan era baru untuk perjanjian itu. Marc Zeller, pengasas Inisiatif Rantaian AAVE (ACI), mengumumkan pada X bahawa cadangan aavenomik termasuk mengubah token protokol AAVE dan memperkenalkan repos token, telah mencapai kuorum untuk Aavedao. Menurut Zeller, ini menandakan era baru untuk perjanjian itu. Ahli -ahli Aavedao mengundi untuk menyokong cadangan itu, yang 100 seminggu pada hari Rabu
 Sepuluh cadangan platform percuma untuk data masa nyata mengenai pasaran bulatan mata wang dikeluarkan
Apr 22, 2025 am 08:12 AM
Sepuluh cadangan platform percuma untuk data masa nyata mengenai pasaran bulatan mata wang dikeluarkan
Apr 22, 2025 am 08:12 AM
Platform data cryptocurrency yang sesuai untuk pemula termasuk coinmarketcap dan sangkakala bukan kecil. 1. CoinMarketCap menyediakan harga masa nyata global, nilai pasaran, dan kedudukan volum perdagangan untuk keperluan analisis pemula dan asas. 2. Petikan bukan kecil menyediakan antara muka yang mesra Cina, sesuai untuk pengguna Cina untuk cepat menyaring projek berpotensi berisiko rendah.
 Kedudukan pertukaran leverage dalam lingkaran mata wang Cadangan terkini sepuluh pertukaran leverage dalam lingkaran mata wang
Apr 21, 2025 pm 11:24 PM
Kedudukan pertukaran leverage dalam lingkaran mata wang Cadangan terkini sepuluh pertukaran leverage dalam lingkaran mata wang
Apr 21, 2025 pm 11:24 PM
Platform yang mempunyai prestasi cemerlang dalam perdagangan, keselamatan dan pengalaman pengguna yang dimanfaatkan pada tahun 2025 adalah: 1. Okx, sesuai untuk peniaga frekuensi tinggi, menyediakan sehingga 100 kali leverage; 2. Binance, sesuai untuk peniaga berbilang mata wang di seluruh dunia, memberikan 125 kali leverage tinggi; 3. Gate.io, sesuai untuk pemain derivatif profesional, menyediakan 100 kali leverage; 4. Bitget, sesuai untuk orang baru dan peniaga sosial, menyediakan sehingga 100 kali leverage; 5. Kraken, sesuai untuk pelabur mantap, menyediakan 5 kali leverage; 6. Bybit, sesuai untuk penjelajah altcoin, menyediakan 20 kali leverage; 7. Kucoin, sesuai untuk peniaga kos rendah, menyediakan 10 kali leverage; 8. Bitfinex, sesuai untuk bermain senior
 Apakah platform perdagangan blockchain hibrid?
Apr 21, 2025 pm 11:36 PM
Apakah platform perdagangan blockchain hibrid?
Apr 21, 2025 pm 11:36 PM
Cadangan untuk memilih pertukaran cryptocurrency: 1. Untuk keperluan kecairan, keutamaan adalah Binance, Gate.io atau Okx, kerana kedalaman pesanannya dan rintangan volatilitas yang kuat. 2. Pematuhan dan Keselamatan, Coinbase, Kraken dan Gemini mempunyai sokongan pengawalseliaan yang ketat. 3. Fungsi inovatif, reka bentuk derivatif Kucoin yang lembut dan Bybit sesuai untuk pengguna lanjutan.
 Platform Pertukaran Cryptocurrency Top 10 senarai pertukaran mata wang digital terbesar di dunia
Apr 21, 2025 pm 07:15 PM
Platform Pertukaran Cryptocurrency Top 10 senarai pertukaran mata wang digital terbesar di dunia
Apr 21, 2025 pm 07:15 PM
Pertukaran memainkan peranan penting dalam pasaran cryptocurrency hari ini. Mereka bukan sahaja platform untuk pelabur untuk berdagang, tetapi juga sumber kecairan pasaran dan penemuan harga. Pertukaran mata wang maya terbesar di dunia di kalangan sepuluh teratas, dan pertukaran ini bukan sahaja jauh ke hadapan dalam jumlah dagangan, tetapi juga mempunyai kelebihan mereka sendiri dalam pengalaman pengguna, perkhidmatan keselamatan dan inovatif. Pertukaran yang atas senarai biasanya mempunyai pangkalan pengguna yang besar dan pengaruh pasaran yang luas, dan jumlah dagangan dan jenis aset mereka sering sukar dicapai oleh bursa lain.
 Senarai perkhidmatan khas untuk platform perdagangan mata wang maya utama
Apr 22, 2025 am 08:09 AM
Senarai perkhidmatan khas untuk platform perdagangan mata wang maya utama
Apr 22, 2025 am 08:09 AM
Pelabur institusi harus memilih platform yang mematuhi seperti Coinbase Pro dan Perdagangan Kejadian, yang memberi tumpuan kepada nisbah penyimpanan sejuk dan ketelusan audit; Pelabur runcit harus memilih platform besar seperti Binance dan Huobi, yang memberi tumpuan kepada pengalaman pengguna dan keselamatan; Pengguna di kawasan sensitif pematuhan boleh menjalankan perdagangan mata wang fiat melalui perdagangan Circle dan Huobi Global, dan pengguna tanah besar Cina perlu melalui saluran yang mematuhi kaunter.
