
 Peranti teknologi
AI
Membongkar tongkat ajaib ahli sihir LLM, pasukan Cina UIUC mendedahkan tiga kelebihan utama data kod
Peranti teknologi
AI
Membongkar tongkat ajaib ahli sihir LLM, pasukan Cina UIUC mendedahkan tiga kelebihan utama data kod
Membongkar tongkat ajaib ahli sihir LLM, pasukan Cina UIUC mendedahkan tiga kelebihan utama data kod

Saiz model bahasa (LLM) dan data latihan dalam era model besar telah meningkat, termasuk bahasa semula jadi dan kod.
Kod ialah perantara antara manusia dan komputer, menukar matlamat peringkat tinggi kepada langkah perantaraan yang boleh dilaksanakan. Ia mempunyai ciri-ciri standard tatabahasa, ketekalan logik, abstraksi dan modulariti.
Sebuah pasukan penyelidik di University of Illinois di Urbana-Champaign baru-baru ini menerbitkan laporan semakan yang meringkaskan pelbagai faedah menggabungkan kod ke dalam data latihan LLM.

Pautan kertas: https://arxiv.org/abs/2401.00812v1
Secara khusus, selain meningkatkan keupayaan LLM dalam penjanaan kod, tiga perkara berikut: juga termasuk tiga perkara berikut:
1. Membantu membuka kunci keupayaan penaakulan LLM, membolehkannya digunakan pada satu siri tugasan bahasa semula jadi yang lebih kompleks
2 fungsi cara untuk menyambung ke pelaksanaan luaran tamat;
3.
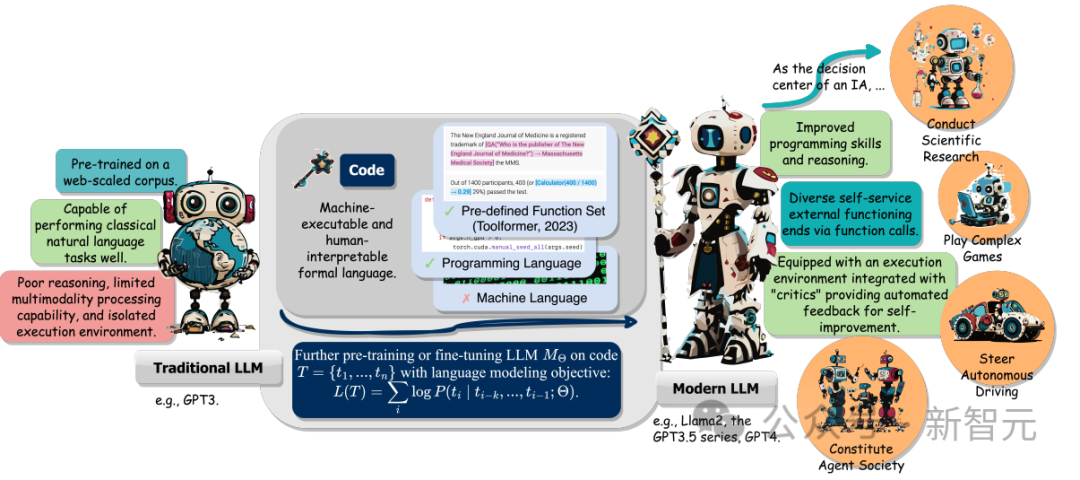
Selain itu, penyelidik juga menjejaki keupayaan LLM untuk memahami arahan, menguraikan matlamat, merancang dan melaksanakan tindakan, dan mengekstrak daripada maklum balas apabila bertindak sebagai ejen pintar (IA).
Akhir sekali, artikel itu juga mencadangkan cabaran utama dan hala tuju penyelidikan masa depan dalam bidang "meningkatkan LLM dengan kod". Kod Pra-Latihan Meningkatkan Prestasi LLM Mengambil Codex GPT OpenAI sebagai contoh, selepas pra-latihan kod untuk LLM, skop tugas LLM dapat diperluaskan. juga boleh digunakan untuk teori matematik Menjana kod, melaksanakan tugas pengaturcaraan biasa, mendapatkan data dan banyak lagi.
 Tugas penjanaan kod mempunyai dua ciri: 1) urutan kod perlu dilaksanakan dengan berkesan, jadi ia mesti mempunyai logik koheren, 2) setiap langkah perantaraan boleh tertakluk kepada pengesahan logik langkah demi langkah.
Tugas penjanaan kod mempunyai dua ciri: 1) urutan kod perlu dilaksanakan dengan berkesan, jadi ia mesti mempunyai logik koheren, 2) setiap langkah perantaraan boleh tertakluk kepada pengesahan logik langkah demi langkah.
Menggunakan dan membenamkan kod dalam pra-latihan boleh meningkatkan prestasi teknologi Rantaian Pemikiran (CoT) LLM dalam tugas hiliran bahasa semula jadi tradisional, menunjukkan bahawa latihan kod boleh meningkatkan keupayaan LLM untuk melakukan penaakulan yang kompleks.
Dengan belajar secara tersirat daripada bentuk kod berstruktur, Kod LLM juga menunjukkan prestasi yang lebih baik dalam tugasan penaakulan struktur akal, seperti yang berkaitan dengan penandaan, HTML dan pemahaman rajah. .
Tujuan fungsian ini membolehkan LLM memperoleh pengetahuan luaran, mengambil bahagian dalam berbilang data modal dan berinteraksi secara berkesan dengan persekitaran.
Daripada kerja yang berkaitan, penyelidik telah memerhatikan trend biasa, iaitu, LLM menjana bahasa pengaturcaraanatau menggunakan fungsi yang telah ditetapkan untuk mewujudkan sambungan dengan terminal berfungsi lain, iaitu, "kod-centric" paradigma .
Bertentangan dengan proses praktikal tetap bagi panggilan alat berkod keras dalam mekanisme inferens LLM, paradigma berpusatkan kod membolehkan LLM menjana token dan modul pelaksanaan panggilan secara dinamik dengan parameter yang boleh disesuaikan, menyediakan LLM dengan interaksi terminal Fungsian yang lain menyediakan kaedah mudah dan jelas yang meningkatkan fleksibiliti dan kebolehskalaan aplikasinya.
Yang penting, paradigma ini membolehkan LLM berinteraksi dengan banyak terminal berfungsi merentas modaliti dan domain yang berbeza dengan mengembangkan bilangan dan kepelbagaian terminal berfungsi yang boleh diakses, LLM boleh mengendalikan tugas yang lebih kompleks.
Artikel ini terutamanya mengkaji teks dan alatan berbilang modal yang disambungkan kepada LLM, serta penghujung dunia fizikal yang berfungsi, termasuk robotik dan pemanduan autonomi, menunjukkan kepelbagaian LLM dalam menyelesaikan masalah dalam pelbagai mod dan domain.
Persekitaran boleh laksana yang menyediakan maklum balas automatik
LLM mempamerkan prestasi melebihi parameter latihan mereka, sebahagiannya disebabkan oleh keupayaan model untuk menyerap isyarat maklum balas, terutamanya dalam aplikasi dunia sebenar bukan statik.
Walau bagaimanapun, pilihan isyarat maklum balas mesti berhati-hati, kerana isyarat bising mungkin menghalang prestasi LLM pada tugas hiliran.
Di samping itu, memandangkan kos buruh adalah tinggi, adalah penting untuk mengumpul maklum balas secara automatik sambil mengekalkan kesetiaan.
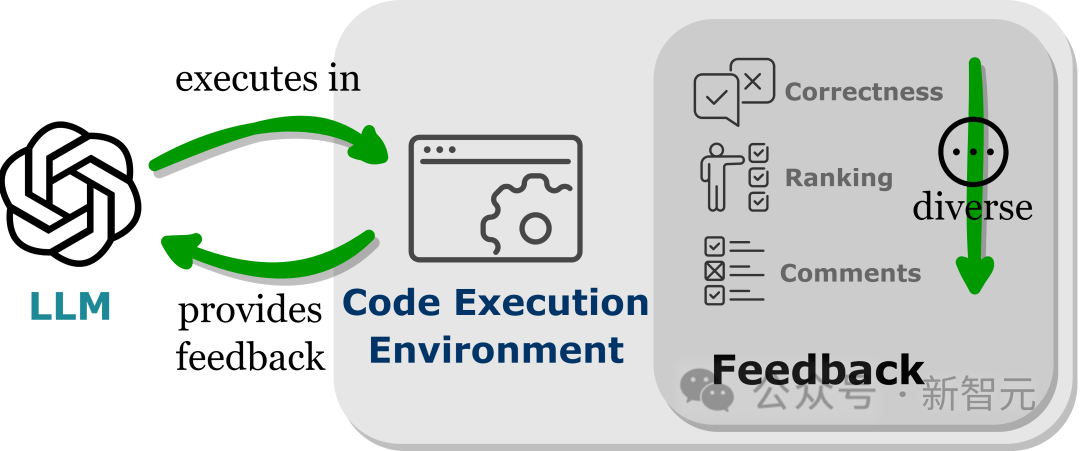
Membenamkan LLM ke dalam persekitaran pelaksanaan kod boleh mencapai maklum balas automatik bagi syarat di atas.
Memandangkan pelaksanaan kod sebahagian besarnya bersifat deterministik, maklum balas yang diperoleh LLM daripada hasil pelaksanaan kod tetap setia kepada tugas sasaran, jurubahasa kod juga menyediakan laluan automatik untuk LLM untuk menanyakan maklum balas dalaman tanpa memerlukan Anotasi buruh manual; boleh digunakan untuk nyahpepijat dan mengoptimumkan kod ralat yang dihasilkan oleh LLM.
Selain itu, persekitaran kod membenarkan LLM untuk menyepadukan pelbagai bentuk maklum balas luaran, termasuk tetapi tidak terhad kepada maklum balas ketepatan binari, penjelasan bahasa semula jadi hasil dan kedudukan nilai ganjaran, sekali gus membolehkan pendekatan yang sangat disesuaikan untuk meningkatkan prestasi. . sejauh mana kesannya terhadap peningkatan kemahiran penaakulan masih tidak jelas.
 Dalam langkah kerja penyelidikan seterusnya, adalah penting untuk mengkaji sama ada atribut kod ini sebenarnya boleh meningkatkan keupayaan inferens LLM terlatih dalam data latihan.
Dalam langkah kerja penyelidikan seterusnya, adalah penting untuk mengkaji sama ada atribut kod ini sebenarnya boleh meningkatkan keupayaan inferens LLM terlatih dalam data latihan.
Sekiranya benar bahawa pra-latihan tentang sifat khusus kod boleh secara langsung meningkatkan keupayaan penaakulan LLM, maka memahami fenomena ini akan menjadi kunci untuk meningkatkan lagi keupayaan penaakulan kompleks model semasa.
Keupayaan penaakulan tidak terhad kepada kod
Walaupun peningkatan keupayaan penaakulan dicapai melalui pra-latihan kod, model asas masih tidak mempunyai keupayaan penaakulan seperti manusia yang diharapkan daripada kecerdasan buatan am sebenar.
Selain kod, sejumlah besar sumber data teks lain berpotensi untuk meningkatkan keupayaan inferens LLM, di mana ciri-ciri kod yang wujud, seperti kekurangan kekaburan, kebolehlaksanaan dan struktur jujukan logik, menyediakan garis panduan untuk mengumpul atau mencipta set data ini.
Tetapi jika kita terus berpegang pada paradigma melatih model bahasa pada korpora besar dengan matlamat pemodelan bahasa, sukar untuk mempunyai bahasa yang boleh dibaca secara berurutan yang lebih abstrak daripada bahasa formal: sangat berstruktur, berkait rapat dengan bahasa simbolik, dan Wujud dalam jumlah besar dalam persekitaran rangkaian digital. Para penyelidik membayangkan bahawa meneroka corak data alternatif, objektif latihan yang pelbagai dan seni bina baru akan memberikan lebih banyak peluang untuk meningkatkan lagi keupayaan inferens model. . (fungsi) terminal dan menghantar hujah yang betul pada masa yang sesuai.
Sebagai contoh, untuk tugasan mudah (navigasi halaman web), diberikan set primitif tindakan terhad, seperti pergerakan tetikus, klik dan menatal halaman, dan kemudian berikan beberapa contoh (beberapa tangkapan), asas LLM yang kukuh selalunya memerlukan LLM untuk menguasai penggunaan primitif ini dengan tepat.
Untuk tugasan yang lebih kompleks dalam bidang intensif data seperti kimia, biologi dan astronomi, yang melibatkan panggilan ke perpustakaan python khusus domain yang mengandungi banyak fungsi kompleks dengan fungsi berbeza, tingkatkan pembelajaran LLM untuk memanggil fungsi fungsi ini dengan betul. hala tuju yang berpandangan ke hadapan yang membolehkan LLM melaksanakan tugas peringkat pakar dalam domain yang terperinci.
Belajar daripada pelbagai pusingan interaksi dan maklum balas
LLM selalunya memerlukan berbilang interaksi dengan pengguna dan persekitaran, sentiasa membetulkan diri mereka sendiri untuk menambah baik penyelesaian tugas yang rumit.
Walaupun pelaksanaan kod memberikan maklum balas yang boleh dipercayai dan boleh disesuaikan, cara terbaik untuk mengeksploitasi maklum balas ini sepenuhnya masih belum diwujudkan.
Walaupun kaedah berasaskan pemilihan semasa berguna, ia tidak dapat menjamin prestasi yang lebih baik dan tidak cekap; telah membuat peningkatan kemajuan yang berterusan, tetapi pengumpulan data dan penalaan halus adalah intensif sumber dan sukar untuk digunakan dalam amalan.
Penyelidik percaya bahawa pembelajaran pengukuhan mungkin merupakan cara yang lebih berkesan untuk memanfaatkan maklum balas dan menambah baik, menyediakan cara dinamik untuk menyesuaikan diri dengan maklum balas melalui fungsi ganjaran yang direka dengan teliti, yang berpotensi menangani batasan teknologi semasa.
Tetapi banyak penyelidikan masih diperlukan untuk memahami cara mereka bentuk fungsi ganjaran dan cara mengintegrasikan pembelajaran pengukuhan dengan LLM secara optimum untuk menyelesaikan tugas yang kompleks.
Atas ialah kandungan terperinci Membongkar tongkat ajaib ahli sihir LLM, pasukan Cina UIUC mendedahkan tiga kelebihan utama data kod. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1382
1382
 52
52

 Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Perintah shutdown CentOS adalah penutupan, dan sintaks adalah tutup [pilihan] [maklumat]. Pilihan termasuk: -h menghentikan sistem dengan segera; -P mematikan kuasa selepas penutupan; -r mulakan semula; -T Waktu Menunggu. Masa boleh ditentukan sebagai segera (sekarang), minit (minit), atau masa tertentu (HH: mm). Maklumat tambahan boleh dipaparkan dalam mesej sistem.
 Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Dasar sandaran dan pemulihan Gitlab di bawah sistem CentOS untuk memastikan keselamatan data dan pemulihan, Gitlab pada CentOS menyediakan pelbagai kaedah sandaran. Artikel ini akan memperkenalkan beberapa kaedah sandaran biasa, parameter konfigurasi dan proses pemulihan secara terperinci untuk membantu anda menubuhkan strategi sandaran dan pemulihan GitLab lengkap. 1. Backup Manual Gunakan Gitlab-Rakegitlab: Backup: Buat Perintah untuk Melaksanakan Backup Manual. Perintah ini menyokong maklumat utama seperti repositori Gitlab, pangkalan data, pengguna, kumpulan pengguna, kunci, dan kebenaran. Fail sandaran lalai disimpan dalam direktori/var/opt/gitlab/sandaran. Anda boleh mengubah suai /etc /gitlab
 Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Panduan Lengkap untuk Memeriksa Konfigurasi HDFS Dalam Sistem CentOS Artikel ini akan membimbing anda bagaimana untuk memeriksa konfigurasi dan menjalankan status HDFS secara berkesan pada sistem CentOS. Langkah -langkah berikut akan membantu anda memahami sepenuhnya persediaan dan operasi HDFS. Sahkan Pembolehubah Alam Sekitar Hadoop: Pertama, pastikan pembolehubah persekitaran Hadoop ditetapkan dengan betul. Di terminal, laksanakan arahan berikut untuk mengesahkan bahawa Hadoop dipasang dan dikonfigurasi dengan betul: Hadoopversion Semak fail konfigurasi HDFS: Fail konfigurasi teras HDFS terletak di/etc/hadoop/conf/direktori, di mana core-site.xml dan hdfs-site.xml adalah kritikal. gunakan
 Apakah kaedah penalaan prestasi zookeeper di CentOS
Apr 14, 2025 pm 03:18 PM
Apakah kaedah penalaan prestasi zookeeper di CentOS
Apr 14, 2025 pm 03:18 PM
Penalaan prestasi zookeeper pada centOs boleh bermula dari pelbagai aspek, termasuk konfigurasi perkakasan, pengoptimuman sistem operasi, pelarasan parameter konfigurasi, pemantauan dan penyelenggaraan, dan lain -lain. Memori yang cukup: memperuntukkan sumber memori yang cukup untuk zookeeper untuk mengelakkan cakera kerap membaca dan menulis. CPU multi-teras: Gunakan CPU multi-teras untuk memastikan bahawa zookeeper dapat memprosesnya selari.
 Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Membolehkan pecutan GPU pytorch pada sistem CentOS memerlukan pemasangan cuda, cudnn dan GPU versi pytorch. Langkah-langkah berikut akan membimbing anda melalui proses: Pemasangan CUDA dan CUDNN Tentukan keserasian versi CUDA: Gunakan perintah NVIDIA-SMI untuk melihat versi CUDA yang disokong oleh kad grafik NVIDIA anda. Sebagai contoh, kad grafik MX450 anda boleh menyokong CUDA11.1 atau lebih tinggi. Muat turun dan pasang Cudatoolkit: Lawati laman web rasmi Nvidiacudatoolkit dan muat turun dan pasang versi yang sepadan mengikut versi CUDA tertinggi yang disokong oleh kad grafik anda. Pasang Perpustakaan Cudnn:
 Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Docker menggunakan ciri -ciri kernel Linux untuk menyediakan persekitaran berjalan yang cekap dan terpencil. Prinsip kerjanya adalah seperti berikut: 1. Cermin digunakan sebagai templat baca sahaja, yang mengandungi semua yang anda perlukan untuk menjalankan aplikasi; 2. Sistem Fail Kesatuan (Unionfs) menyusun pelbagai sistem fail, hanya menyimpan perbezaan, menjimatkan ruang dan mempercepatkan; 3. Daemon menguruskan cermin dan bekas, dan pelanggan menggunakannya untuk interaksi; 4. Ruang nama dan cgroups melaksanakan pengasingan kontena dan batasan sumber; 5. Pelbagai mod rangkaian menyokong interkoneksi kontena. Hanya dengan memahami konsep -konsep teras ini, anda boleh menggunakan Docker dengan lebih baik.
 CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
Memasang MySQL pada CentOS melibatkan langkah -langkah berikut: Menambah sumber MySQL YUM yang sesuai. Jalankan YUM Pasang Perintah MySQL-Server untuk memasang pelayan MySQL. Gunakan perintah mysql_secure_installation untuk membuat tetapan keselamatan, seperti menetapkan kata laluan pengguna root. Sesuaikan fail konfigurasi MySQL seperti yang diperlukan. Tune parameter MySQL dan mengoptimumkan pangkalan data untuk prestasi.
 CentOS8 memulakan semula SSH
Apr 14, 2025 pm 09:00 PM
CentOS8 memulakan semula SSH
Apr 14, 2025 pm 09:00 PM
Perintah untuk memulakan semula perkhidmatan SSH ialah: Sistem Restart SSHD. Langkah -langkah terperinci: 1. Akses terminal dan sambungkan ke pelayan; 2. Masukkan arahan: SistemCtl Restart SSHD; 3. Sahkan Status Perkhidmatan: Status Sistem SSHD.
