
 Java
javaTutorial
Flume vs. Kafka: Alat manakah yang lebih baik untuk mengendalikan aliran data anda?
Java
javaTutorial
Flume vs. Kafka: Alat manakah yang lebih baik untuk mengendalikan aliran data anda?
Flume vs. Kafka: Alat manakah yang lebih baik untuk mengendalikan aliran data anda?


Flume vs Kafka: Alat manakah yang lebih baik untuk pemprosesan aliran data anda?
Ikhtisar
Flume dan Kafka ialah kedua-dua alat pemprosesan strim data popular yang digunakan untuk mengumpul, mengagregat dan menghantar sejumlah besar data masa nyata. Kedua-duanya mempunyai ciri pemprosesan tinggi, kependaman rendah dan kebolehpercayaan, tetapi ia mempunyai beberapa perbezaan dalam fungsi, seni bina dan senario yang berkenaan.
Flume
Flume ialah sistem pengumpulan, pengagregatan dan penghantaran data yang diedarkan, boleh dipercayai dan sangat tersedia yang boleh mengumpul data daripada pelbagai sumber dan kemudian menyimpannya dalam HDFS, HBase atau sistem storan lain. Flume terdiri daripada berbilang komponen, termasuk:
- Agen: Ejen Flume bertanggungjawab untuk mengumpul data daripada sumber data.
- Saluran: Saluran Flume bertanggungjawab untuk menyimpan dan menimbal data.
- Sink: Flume sink bertanggungjawab untuk menulis data ke sistem storan.
Kelebihan Flume termasuk:
- Mudah digunakan: Flume mempunyai antara muka yang mesra pengguna dan konfigurasi mudah, menjadikannya mudah untuk dipasang dan digunakan.
- Keupayaan tinggi: Flume boleh mengendalikan sejumlah besar data, menjadikannya sesuai untuk senario pemprosesan data besar.
- Kebolehpercayaan: Flume mempunyai mekanisme penghantaran data yang boleh dipercayai untuk memastikan data tidak akan hilang.
Kelemahan Flume termasuk:
- Latensi rendah: Flume mempunyai kependaman tinggi dan tidak sesuai untuk senario yang memerlukan pemprosesan data masa nyata.
- Skalabiliti: Flume mempunyai skalabiliti terhad dan tidak sesuai untuk senario yang memerlukan pemprosesan data yang banyak.
Kafka
Kafka ialah sistem pemesejan teragih, berskala dan bertolak ansur terhadap kesalahan yang boleh menyimpan dan memproses sejumlah besar data masa nyata. Kafka terdiri daripada berbilang komponen, termasuk:
- Broker: Broker Kafka bertanggungjawab untuk menyimpan dan mengurus data.
- Topik: Topik Kafka ialah partition data logik, yang boleh mengandungi berbilang partition.
- Partition: Kafka partition ialah unit penyimpanan data fizikal yang boleh menyimpan sejumlah data.
- Pengguna: Pengguna Kafka bertanggungjawab untuk menggunakan data daripada topik Kafka.
Kelebihan Kafka termasuk:
- Kemampuan tinggi: Kafka boleh mengendalikan sejumlah besar data, menjadikannya sesuai untuk senario pemprosesan data besar.
- Latensi rendah: Kafka mempunyai kependaman rendah, menjadikannya sesuai untuk senario yang memerlukan pemprosesan data masa nyata.
- Skalabiliti: Kafka mempunyai kebolehskalaan yang baik, membolehkannya dikembangkan dengan mudah untuk mengendalikan lebih banyak data.
Kelemahan Kafka termasuk:
- Kerumitan: Konfigurasi dan pengurusan Kafka adalah lebih kompleks dan memerlukan pengalaman teknikal tertentu.
- Kebolehpercayaan: Mekanisme storan data Kafka tidak boleh dipercayai dan data mungkin hilang.
Senario terpakai
Kedua-dua Flume dan Kafka sesuai untuk senario pemprosesan data besar, tetapi ia berbeza dalam senario terpakai tertentu.
Flume sesuai untuk senario berikut:
- Perlu mengumpul dan mengagregat data daripada sumber yang berbeza.
- Memerlukan data untuk disimpan dalam HDFS, HBase atau sistem storan lain.
- Memerlukan pemprosesan dan transformasi data yang mudah.
Kafka sesuai untuk senario berikut:
- Perlu memproses sejumlah besar data masa nyata.
- Memerlukan pemprosesan dan analisis data yang kompleks.
- Memerlukan data untuk disimpan dalam sistem fail yang diedarkan.
Contoh Kod
Flume
# 创建一个Flume代理 agent1.sources = r1 agent1.sinks = hdfs agent1.channels = c1 # 配置数据源 r1.type = exec r1.command = tail -F /var/log/messages # 配置数据通道 c1.type = memory c1.capacity = 1000 c1.transactionCapacity = 100 # 配置数据汇 hdfs.type = hdfs hdfs.hdfsUrl = hdfs://localhost:9000 hdfs.fileName = /flume/logs hdfs.rollInterval = 3600 hdfs.rollSize = 10485760
Kafka
# 创建一个Kafka主题 kafka-topics --create --topic my-topic --partitions 3 --replication-factor 2 # 启动一个Kafka代理 kafka-server-start config/server.properties # 启动一个Kafka生产者 kafka-console-producer --topic my-topic # 启动一个Kafka消费者 kafka-console-consumer --topic my-topic --from-beginning
Kesimpulan
Flume dan Kafka ialah kedua-dua alat pemprosesan strim data yang popular, dan ia mempunyai fungsi, seni bina dan senario yang boleh digunakan. Apabila memilih, anda perlu menilai keperluan khusus anda.
Atas ialah kandungan terperinci Flume vs. Kafka: Alat manakah yang lebih baik untuk mengendalikan aliran data anda?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

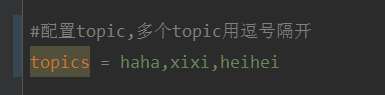 Cara untuk menentukan berbilang topik secara dinamik dengan @KafkaListener dalam springboot+kafka
May 20, 2023 pm 08:58 PM
Cara untuk menentukan berbilang topik secara dinamik dengan @KafkaListener dalam springboot+kafka
May 20, 2023 pm 08:58 PM
Jelaskan bahawa projek ini ialah projek penyepaduan springboot+kafak, jadi ia menggunakan anotasi penggunaan @KafkaListener untuk kafak dalam springboot Pertama, konfigurasikan berbilang topik yang dipisahkan dengan koma dalam application.properties. Kaedah: Gunakan ungkapan SpEl Spring untuk mengkonfigurasi topik sebagai: @KafkaListener(topics="#{'${topics}'.split(',')}") untuk menjalankan program Kesan pencetakan konsol adalah seperti berikut
 Bagaimana untuk melaksanakan analisis saham masa nyata menggunakan PHP dan Kafka
Jun 28, 2023 am 10:04 AM
Bagaimana untuk melaksanakan analisis saham masa nyata menggunakan PHP dan Kafka
Jun 28, 2023 am 10:04 AM
Dengan perkembangan Internet dan teknologi, pelaburan digital telah menjadi topik yang semakin membimbangkan. Ramai pelabur terus meneroka dan mengkaji strategi pelaburan, dengan harapan memperoleh pulangan pelaburan yang lebih tinggi. Dalam perdagangan saham, analisis saham masa nyata adalah sangat penting untuk membuat keputusan, dan penggunaan baris gilir mesej masa nyata Kafka dan teknologi PHP adalah cara yang cekap dan praktikal. 1. Pengenalan kepada Kafka Kafka ialah sistem pemesejan terbitan dan langgan yang diedarkan tinggi yang dibangunkan oleh LinkedIn. Ciri-ciri utama Kafka ialah
 Lima pilihan alat visualisasi untuk meneroka Kafka
Feb 01, 2024 am 08:03 AM
Lima pilihan alat visualisasi untuk meneroka Kafka
Feb 01, 2024 am 08:03 AM
Lima pilihan untuk alat visualisasi Kafka ApacheKafka ialah platform pemprosesan strim teragih yang mampu memproses sejumlah besar data masa nyata. Ia digunakan secara meluas untuk membina saluran paip data masa nyata, baris gilir mesej dan aplikasi dipacu peristiwa. Alat visualisasi Kafka boleh membantu pengguna memantau dan mengurus kelompok Kafka serta lebih memahami aliran data Kafka. Berikut ialah pengenalan kepada lima alat visualisasi Kafka yang popular: ConfluentControlCenterConfluent
 Analisis perbandingan alat visualisasi kafka: Bagaimana untuk memilih alat yang paling sesuai?
Jan 05, 2024 pm 12:15 PM
Analisis perbandingan alat visualisasi kafka: Bagaimana untuk memilih alat yang paling sesuai?
Jan 05, 2024 pm 12:15 PM
Bagaimana untuk memilih alat visualisasi Kafka yang betul? Analisis perbandingan lima alat Pengenalan: Kafka ialah sistem baris gilir mesej teragih berprestasi tinggi dan tinggi yang digunakan secara meluas dalam bidang data besar. Dengan populariti Kafka, semakin banyak perusahaan dan pembangun memerlukan alat visual untuk memantau dan mengurus kelompok Kafka dengan mudah. Artikel ini akan memperkenalkan lima alat visualisasi Kafka yang biasa digunakan dan membandingkan ciri serta fungsinya untuk membantu pembaca memilih alat yang sesuai dengan keperluan mereka. 1. KafkaManager
 Cara membina aplikasi pemprosesan data masa nyata menggunakan React dan Apache Kafka
Sep 27, 2023 pm 02:25 PM
Cara membina aplikasi pemprosesan data masa nyata menggunakan React dan Apache Kafka
Sep 27, 2023 pm 02:25 PM
Cara menggunakan React dan Apache Kafka untuk membina aplikasi pemprosesan data masa nyata Pengenalan: Dengan peningkatan data besar dan pemprosesan data masa nyata, membina aplikasi pemprosesan data masa nyata telah menjadi usaha ramai pembangun. Gabungan React, rangka kerja bahagian hadapan yang popular dan Apache Kafka, sistem pemesejan teragih berprestasi tinggi, boleh membantu kami membina aplikasi pemprosesan data masa nyata. Artikel ini akan memperkenalkan cara menggunakan React dan Apache Kafka untuk membina aplikasi pemprosesan data masa nyata, dan
 Bagaimana untuk memasang Apache Kafka pada Rocky Linux?
Mar 01, 2024 pm 10:37 PM
Bagaimana untuk memasang Apache Kafka pada Rocky Linux?
Mar 01, 2024 pm 10:37 PM
Untuk memasang ApacheKafka pada RockyLinux, anda boleh mengikuti langkah di bawah: Kemas kini sistem: Pertama, pastikan sistem RockyLinux anda dikemas kini, laksanakan arahan berikut untuk mengemas kini pakej sistem: sudoyumupdate Pasang Java: ApacheKafka bergantung pada Java, jadi anda perlu memasang Java Development Kit (JDK) terlebih dahulu ). OpenJDK boleh dipasang melalui arahan berikut: sudoyuminstalljava-1.8.0-openjdk-devel Muat turun dan nyahmampat: Lawati laman web rasmi ApacheKafka () untuk memuat turun pakej binari terkini. Pilih versi yang stabil
 Contoh kod untuk projek springboot untuk mengkonfigurasi berbilang kafka
May 14, 2023 pm 12:28 PM
Contoh kod untuk projek springboot untuk mengkonfigurasi berbilang kafka
May 14, 2023 pm 12:28 PM
1.spring-kafkaorg.springframework.kafkaspring-kafka1.3.5.RELEASE2. Maklumat berkaitan fail konfigurasi kafka.bootstrap-servers=localhost:9092kafka.consumer.group.id=20230321#Bilangan utas yang boleh digunakan secara serentak (biasanya dengan bilangan partition )kafka.consumer.concurrency=10kafka.consumer.enable.auto.commit=falsekafka.boo
 Amalan go-zero dan Kafka+Avro: membina sistem pemprosesan data interaktif berprestasi tinggi
Jun 23, 2023 am 09:04 AM
Amalan go-zero dan Kafka+Avro: membina sistem pemprosesan data interaktif berprestasi tinggi
Jun 23, 2023 am 09:04 AM
Dalam tahun-tahun kebelakangan ini, dengan peningkatan data besar dan komuniti sumber terbuka yang aktif, semakin banyak perusahaan telah mula mencari sistem pemprosesan data interaktif berprestasi tinggi untuk memenuhi keperluan data yang semakin meningkat. Dalam gelombang peningkatan teknologi ini, go-zero dan Kafka+Avro sedang diberi perhatian dan diterima pakai oleh semakin banyak perusahaan. go-zero ialah rangka kerja mikroperkhidmatan yang dibangunkan berdasarkan bahasa Golang Ia mempunyai ciri-ciri prestasi tinggi, kemudahan penggunaan, pengembangan mudah dan penyelenggaraan yang mudah. Ia direka untuk membantu perusahaan membina sistem aplikasi perkhidmatan mikro yang cekap. pertumbuhannya yang pesat
