

Pada April tahun lalu, penyelidik dari University of Wisconsin-Madison, Microsoft Research dan Columbia University bersama-sama mengeluarkan LLaVA (Pembantu Bahasa dan Penglihatan Besar). Walaupun LLaVA hanya dilatih dengan set data arahan berbilang modal yang kecil, ia menunjukkan keputusan inferens yang hampir sama dengan GPT-4 pada beberapa sampel. Kemudian pada bulan Oktober, mereka melancarkan LLaVA-1.5, yang menyegarkan SOTA dalam 11 penanda aras dengan pengubahsuaian mudah kepada LLaVA asal. Hasil peningkatan ini sangat mengujakan, membawa kejayaan baharu kepada bidang pembantu AI berbilang modal.
Pasukan penyelidik mengumumkan pelancaran versi LLaVA-1.6, yang telah membuat peningkatan prestasi utama dalam penaakulan, OCR dan pengetahuan dunia. Versi LLaVA-1.6 ini malah mengatasi prestasi Gemini Pro dalam berbilang penanda aras.
Alamat projek: https://LL
VAGunakan SGLang untuk penggunaan dan inferens yang cekap. 
Sumber imej: https://twitter.com/imhaotian/status/1752621754273472927
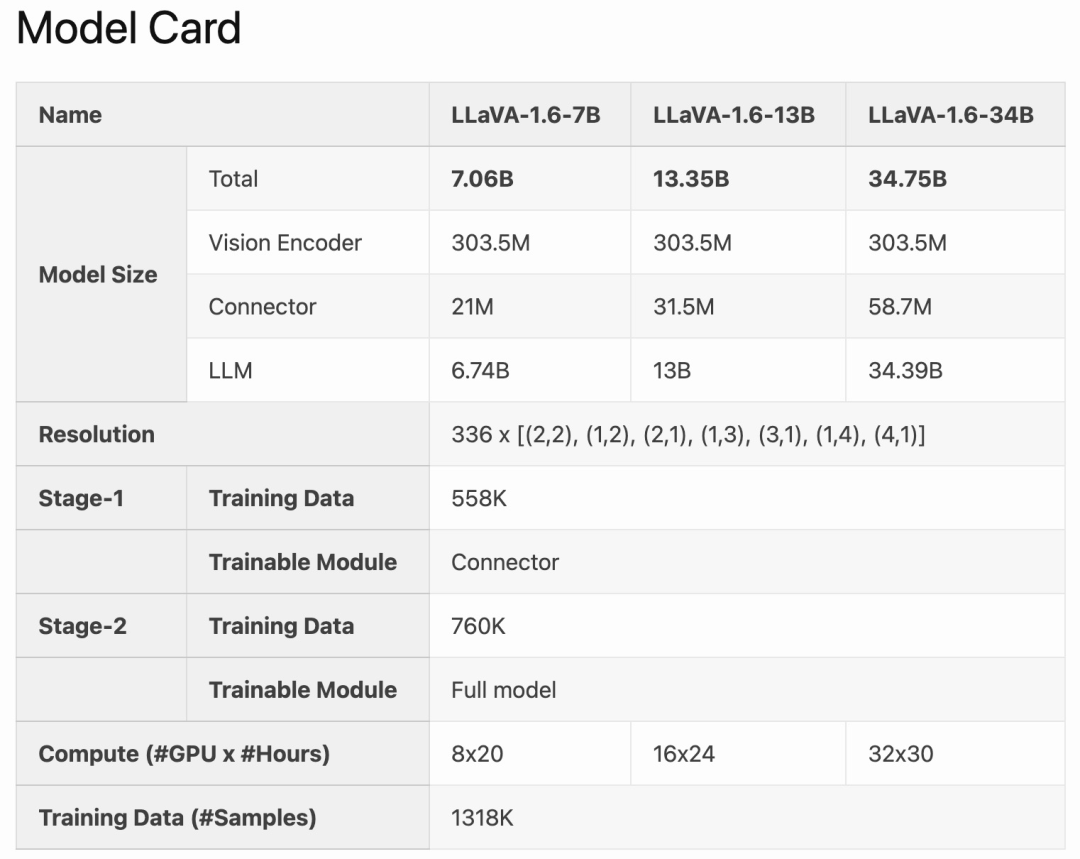 LLaVA-1.6 dioptimumkan berdasarkan LLAVA-1.6 dan dioptimumkan Ia mengekalkan reka bentuk ringkas dan keupayaan pemprosesan data yang cekap LLaVA-1.5, dan terus menggunakan kurang daripada 1M sampel penalaan arahan visual. Dengan menggunakan 32 kad grafik A100, model 34B terbesar telah dilatih dalam masa lebih kurang 1 hari. Di samping itu, LLaVA-1.6 menggunakan 1.3 juta sampel data, dan kos data pengiraan/latihannya hanya 100-1000 kali ganda daripada kaedah lain. Penambahbaikan ini menjadikan LLaVA-1.6 versi yang lebih cekap dan kos efektif.
LLaVA-1.6 dioptimumkan berdasarkan LLAVA-1.6 dan dioptimumkan Ia mengekalkan reka bentuk ringkas dan keupayaan pemprosesan data yang cekap LLaVA-1.5, dan terus menggunakan kurang daripada 1M sampel penalaan arahan visual. Dengan menggunakan 32 kad grafik A100, model 34B terbesar telah dilatih dalam masa lebih kurang 1 hari. Di samping itu, LLaVA-1.6 menggunakan 1.3 juta sampel data, dan kos data pengiraan/latihannya hanya 100-1000 kali ganda daripada kaedah lain. Penambahbaikan ini menjadikan LLaVA-1.6 versi yang lebih cekap dan kos efektif.
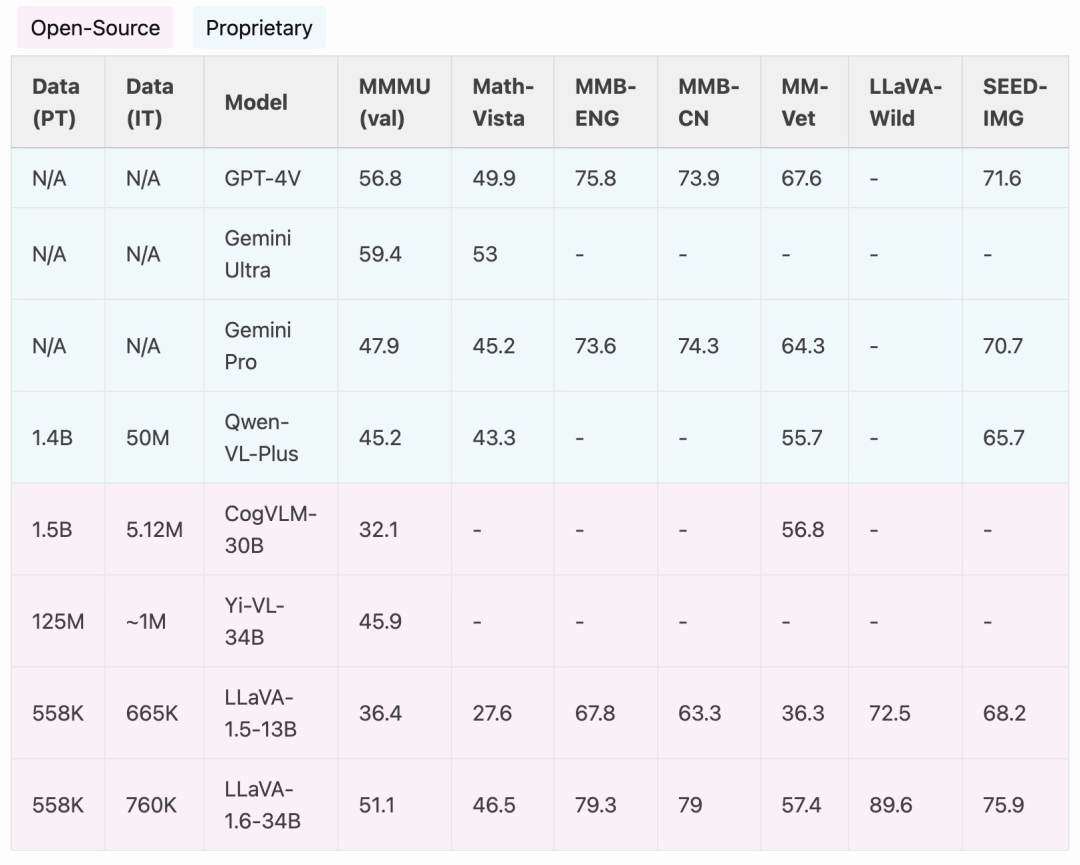 Berbanding dengan LMM sumber terbuka seperti CogVLM atau Yi-VL, LLaVA-1.6 mencapai prestasi SOTA. Berbanding dengan produk komersial, LLaVA-1.6 adalah setanding dengan Gemini Pro dan lebih baik daripada Qwen-VL-Plus dalam penanda aras terpilih.
Berbanding dengan LMM sumber terbuka seperti CogVLM atau Yi-VL, LLaVA-1.6 mencapai prestasi SOTA. Berbanding dengan produk komersial, LLaVA-1.6 adalah setanding dengan Gemini Pro dan lebih baik daripada Qwen-VL-Plus dalam penanda aras terpilih.
Penambahbaikan Kaedah
Resolusi Tinggi Dinamik
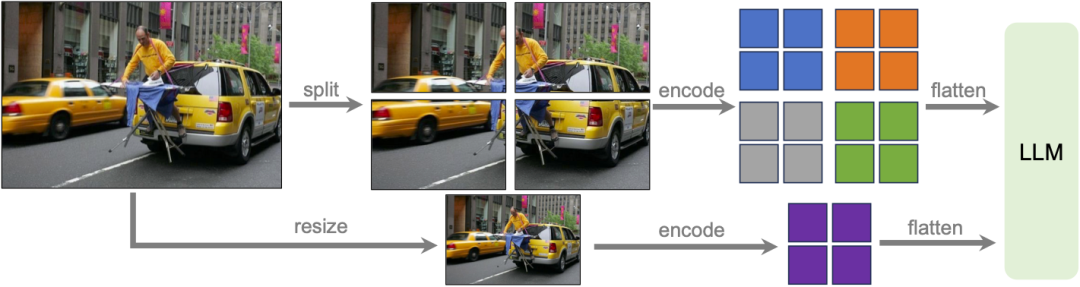 Pasukan penyelidik mereka model LLaVA-1.6 pada resolusi tinggi, bertujuan untuk mengekalkan kecekapan datanya. Apabila dibekalkan dengan imej beresolusi tinggi dan representasi yang mengekalkan butiran, keupayaan model untuk melihat butiran kompleks dalam imej bertambah baik dengan ketara. Ia mengurangkan halusinasi model apabila berhadapan dengan imej resolusi rendah, iaitu meneka kandungan visual yang dibayangkan.
Pasukan penyelidik mereka model LLaVA-1.6 pada resolusi tinggi, bertujuan untuk mengekalkan kecekapan datanya. Apabila dibekalkan dengan imej beresolusi tinggi dan representasi yang mengekalkan butiran, keupayaan model untuk melihat butiran kompleks dalam imej bertambah baik dengan ketara. Ia mengurangkan halusinasi model apabila berhadapan dengan imej resolusi rendah, iaitu meneka kandungan visual yang dibayangkan.
Pencampuran Data
Data arahan pengguna berkualiti tinggi.Takrifan kajian tentang arahan visual berkualiti tinggi mengikut data bergantung pada dua kriteria utama: pertama, kepelbagaian arahan tugas, memastikan perwakilan yang mencukupi bagi julat luas niat pengguna yang mungkin dihadapi dalam senario kehidupan sebenar, terutamanya semasa peringkat penggunaan model. Kedua, keutamaan respons adalah kritikal, bertujuan untuk mendapatkan maklum balas pengguna yang menggalakkan.
Oleh itu, kajian mempertimbangkan dua sumber data:
🎜🎜🎜Data GPT-V sedia ada (LAION-GPT-V dan ShareGPT-4V);Untuk terus mempromosikan dialog visual yang lebih baik dalam lebih banyak senario, pasukan penyelidik mengumpulkan set data penalaan arahan visual 15K kecil yang meliputi aplikasi berbeza, sampel yang ditapis dengan teliti yang mungkin mempunyai isu privasi atau mungkin berbahaya, dan menggunakan GPT- 4V menjana tindak balas.
Data dokumen/carta berbilang mod. (1) Alih keluar TextCap daripada data latihan kerana pasukan penyelidik menyedari bahawa TextCap menggunakan set imej latihan yang sama seperti TextVQA. Ini membolehkan pasukan penyelidik memahami dengan lebih baik keupayaan OCR tangkapan sifar model apabila menilai TextVQA. Untuk mengekalkan dan menambah baik lagi keupayaan OCR model, kajian ini menggantikan TextCap dengan DocVQA dan SynDog-EN. (2) Dengan Qwen-VL-7B-Chat, kajian ini menambahkan lagi ChartQA, DVQA, dan AI2D untuk pemahaman yang lebih baik tentang plot dan carta.
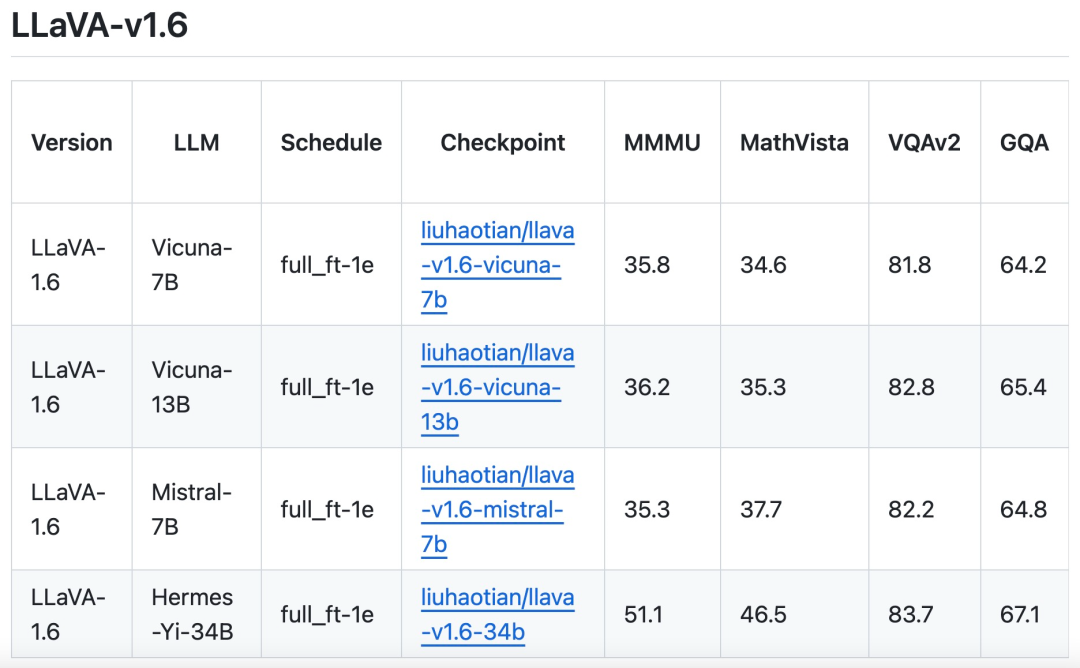
Pasukan penyelidik juga menyatakan bahawa sebagai tambahan kepada Vicuna-1.5 (7B dan 13B), ia juga sedang mempertimbangkan untuk mengguna pakai lebih banyak penyelesaian LLM, termasuk Mistral-7B dan Nous-Hermes-2-Yi-34B, untuk membolehkan LLaVA menyokong julat pengguna yang lebih luas dan lebih banyak adegan.
Atas ialah kandungan terperinci LLaVA-1.6, yang mengejar Gemini Pro dan meningkatkan keupayaan penaakulan dan OCR, terlalu berkuasa. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apakah yang perlu saya lakukan jika video web tidak boleh dibuka?
Apakah yang perlu saya lakukan jika video web tidak boleh dibuka?
 Bagaimana untuk menaik taraf sistem Hongmeng pada telefon bimbit Honor
Bagaimana untuk menaik taraf sistem Hongmeng pada telefon bimbit Honor
 Bagaimana penderia suhu berfungsi
Bagaimana penderia suhu berfungsi
 Pemalam tv mangga
Pemalam tv mangga
 Adakah kertas A5 lebih besar atau kertas B5 lebih besar?
Adakah kertas A5 lebih besar atau kertas B5 lebih besar?
 Bagaimana untuk menjana fail bin dengan mdk
Bagaimana untuk menjana fail bin dengan mdk
 Kedai Apple tidak boleh bersambung
Kedai Apple tidak boleh bersambung
 Nilai input Excel adalah haram
Nilai input Excel adalah haram








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



