
 Peranti teknologi
AI
Jarang model besar berbilang modal, dan model 3B MoE-LLaVA adalah setanding dengan LLaVA-1.5-7B
Peranti teknologi
AI
Jarang model besar berbilang modal, dan model 3B MoE-LLaVA adalah setanding dengan LLaVA-1.5-7B
Jarang model besar berbilang modal, dan model 3B MoE-LLaVA adalah setanding dengan LLaVA-1.5-7B

Model Bahasa Visual Skala Besar (LVLM) boleh meningkatkan prestasi dengan menskalakan model. Walau bagaimanapun, meningkatkan saiz parameter meningkatkan kos latihan dan inferens kerana pengiraan setiap token mengaktifkan semua parameter model.
Penyelidik dari Universiti Peking, Universiti Sun Yat-sen dan institusi lain bersama-sama mencadangkan strategi latihan baharu yang dipanggil MoE-Tuning untuk menyelesaikan masalah kemerosotan prestasi yang berkaitan dengan pembelajaran pelbagai mod dan jarang model. MoE-Tuning mampu membina model jarang dengan bilangan parameter yang mengejutkan tetapi kos pengiraan yang berterusan. Di samping itu, penyelidik juga mencadangkan seni bina LVLM jarang baharu berdasarkan MoE, yang dipanggil rangka kerja MoE-LLaVA. Dalam rangka kerja ini, hanya pakar k teratas diaktifkan melalui algoritma penghalaan, dan pakar selebihnya kekal tidak aktif. Dengan cara ini, rangka kerja MoE-LLaVA boleh menggunakan sumber rangkaian pakar dengan lebih cekap semasa proses penempatan. Hasil penyelidikan ini menyediakan penyelesaian baharu untuk menyelesaikan cabaran pembelajaran pelbagai mod dan jarang model model LVLM.

Alamat kertas: https://arxiv.org/abs/2401.15947
Alamat projek: https://github.com/PKU-YuanGroup/MoE-LLa
- DemoVA/MoE-LLa https://huggingface.co/spaces/LanguageBind/MoE-LLaVA
- Tajuk kertas: MoE-LLaVA: Campuran Pakar untuk Model Bahasa Penglihatan Besar
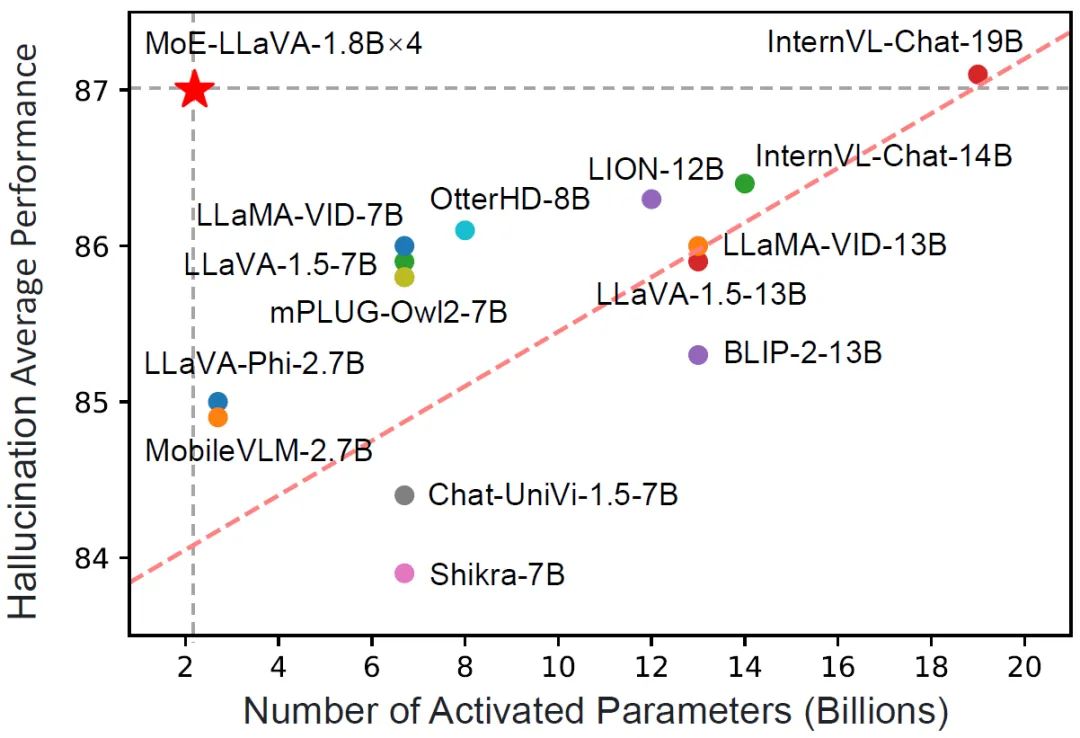
Rajah 4 Prestasi MoE-LLaVA pada 9 penanda aras
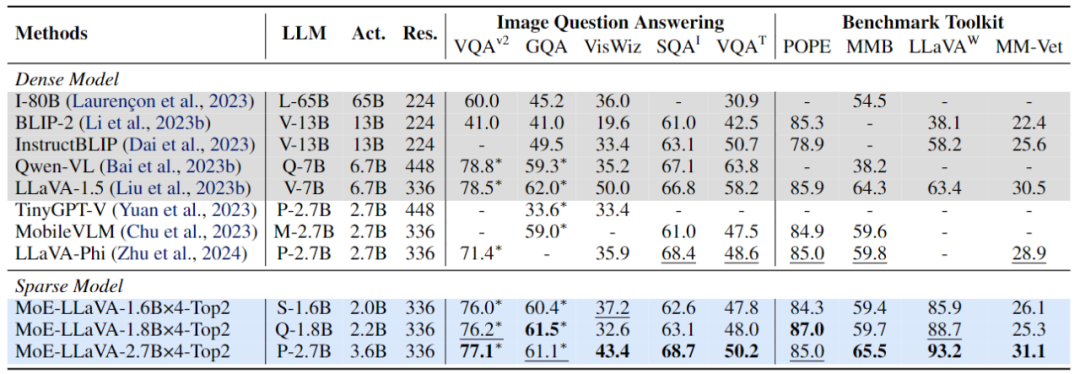
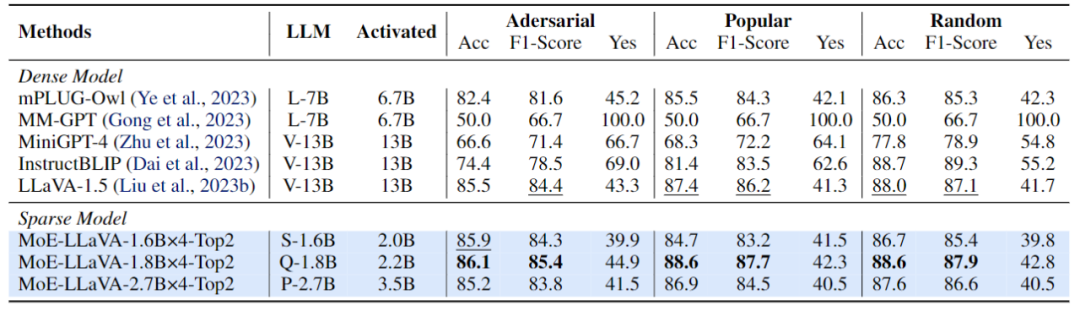
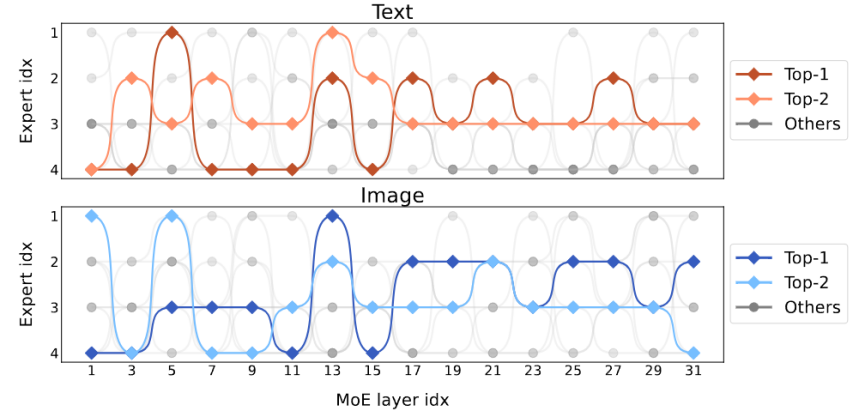
Atas ialah kandungan terperinci Jarang model besar berbilang modal, dan model 3B MoE-LLaVA adalah setanding dengan LLaVA-1.5-7B. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1379
1379
 52
52

 Robot DeepMind bermain pingpong, dan pukulan depan dan pukulan kilasnya tergelincir ke udara, mengalahkan manusia pemula sepenuhnya
Aug 09, 2024 pm 04:01 PM
Robot DeepMind bermain pingpong, dan pukulan depan dan pukulan kilasnya tergelincir ke udara, mengalahkan manusia pemula sepenuhnya
Aug 09, 2024 pm 04:01 PM
Tetapi mungkin dia tidak dapat mengalahkan lelaki tua di taman itu? Sukan Olimpik Paris sedang rancak berlangsung, dan pingpong telah menarik perhatian ramai. Pada masa yang sama, robot juga telah membuat penemuan baru dalam bermain pingpong. Sebentar tadi, DeepMind mencadangkan ejen robot pembelajaran pertama yang boleh mencapai tahap pemain amatur manusia dalam pingpong yang kompetitif. Alamat kertas: https://arxiv.org/pdf/2408.03906 Sejauh manakah robot DeepMind bermain pingpong? Mungkin setanding dengan pemain amatur manusia: kedua-dua pukulan depan dan pukulan kilas: pihak lawan menggunakan pelbagai gaya permainan, dan robot juga boleh bertahan: servis menerima dengan putaran yang berbeza: Walau bagaimanapun, keamatan permainan nampaknya tidak begitu sengit seperti lelaki tua di taman itu. Untuk robot, pingpong
 Cakar mekanikal pertama! Yuanluobao muncul di Persidangan Robot Dunia 2024 dan mengeluarkan robot catur pertama yang boleh memasuki rumah
Aug 21, 2024 pm 07:33 PM
Cakar mekanikal pertama! Yuanluobao muncul di Persidangan Robot Dunia 2024 dan mengeluarkan robot catur pertama yang boleh memasuki rumah
Aug 21, 2024 pm 07:33 PM
Pada 21 Ogos, Persidangan Robot Dunia 2024 telah diadakan dengan megah di Beijing. Jenama robot rumah SenseTime "Yuanluobot SenseRobot" telah memperkenalkan seluruh keluarga produknya, dan baru-baru ini mengeluarkan robot permainan catur AI Yuanluobot - Edisi Profesional Catur (selepas ini dirujuk sebagai "Yuanluobot SenseRobot"), menjadi robot catur A pertama di dunia untuk rumah. Sebagai produk robot permainan catur ketiga Yuanluobo, robot Guoxiang baharu telah melalui sejumlah besar peningkatan teknikal khas dan inovasi dalam AI dan jentera kejuruteraan Buat pertama kalinya, ia telah menyedari keupayaan untuk mengambil buah catur tiga dimensi melalui cakar mekanikal pada robot rumah, dan melaksanakan Fungsi mesin manusia seperti bermain catur, semua orang bermain catur, semakan notasi, dsb.
 Claude pun dah jadi malas! Netizen: Belajar untuk memberi percutian kepada diri sendiri
Sep 02, 2024 pm 01:56 PM
Claude pun dah jadi malas! Netizen: Belajar untuk memberi percutian kepada diri sendiri
Sep 02, 2024 pm 01:56 PM
Permulaan sekolah akan bermula, dan bukan hanya pelajar yang akan memulakan semester baharu yang harus menjaga diri mereka sendiri, tetapi juga model AI yang besar. Beberapa ketika dahulu, Reddit dipenuhi oleh netizen yang mengadu Claude semakin malas. "Tahapnya telah banyak menurun, ia sering berhenti seketika, malah output menjadi sangat singkat. Pada minggu pertama keluaran, ia boleh menterjemah dokumen penuh 4 halaman sekaligus, tetapi kini ia tidak dapat mengeluarkan separuh halaman pun. !" https:// www.reddit.com/r/ClaudeAI/comments/1by8rw8/something_just_feels_wrong_with_claude_in_the/ dalam siaran bertajuk "Totally disappointed with Claude", penuh dengan
 Pada Persidangan Robot Sedunia, robot domestik yang membawa 'harapan penjagaan warga tua masa depan' ini telah dikepung
Aug 22, 2024 pm 10:35 PM
Pada Persidangan Robot Sedunia, robot domestik yang membawa 'harapan penjagaan warga tua masa depan' ini telah dikepung
Aug 22, 2024 pm 10:35 PM
Pada Persidangan Robot Dunia yang diadakan di Beijing, paparan robot humanoid telah menjadi tumpuan mutlak di gerai Stardust Intelligent, pembantu robot AI S1 mempersembahkan tiga persembahan utama dulcimer, seni mempertahankan diri dan kaligrafi dalam. satu kawasan pameran, berkebolehan kedua-dua sastera dan seni mempertahankan diri, menarik sejumlah besar khalayak profesional dan media. Permainan elegan pada rentetan elastik membolehkan S1 menunjukkan operasi halus dan kawalan mutlak dengan kelajuan, kekuatan dan ketepatan. CCTV News menjalankan laporan khas mengenai pembelajaran tiruan dan kawalan pintar di sebalik "Kaligrafi Pengasas Syarikat Lai Jie menjelaskan bahawa di sebalik pergerakan sutera, bahagian perkakasan mengejar kawalan daya terbaik dan penunjuk badan yang paling menyerupai manusia (kelajuan, beban). dll.), tetapi di sisi AI, data pergerakan sebenar orang dikumpulkan, membolehkan robot menjadi lebih kuat apabila ia menghadapi situasi yang kuat dan belajar untuk berkembang dengan cepat. Dan tangkas
 Anugerah ACL 2024 Diumumkan: Salah satu Kertas Terbaik mengenai Pentafsiran Oracle oleh HuaTech, Anugerah Ujian Masa GloVe
Aug 15, 2024 pm 04:37 PM
Anugerah ACL 2024 Diumumkan: Salah satu Kertas Terbaik mengenai Pentafsiran Oracle oleh HuaTech, Anugerah Ujian Masa GloVe
Aug 15, 2024 pm 04:37 PM
Pada persidangan ACL ini, para penyumbang telah mendapat banyak keuntungan. ACL2024 selama enam hari diadakan di Bangkok, Thailand. ACL ialah persidangan antarabangsa teratas dalam bidang linguistik pengiraan dan pemprosesan bahasa semula jadi Ia dianjurkan oleh Persatuan Antarabangsa untuk Linguistik Pengiraan dan diadakan setiap tahun. ACL sentiasa menduduki tempat pertama dalam pengaruh akademik dalam bidang NLP, dan ia juga merupakan persidangan yang disyorkan CCF-A. Persidangan ACL tahun ini adalah yang ke-62 dan telah menerima lebih daripada 400 karya termaju dalam bidang NLP. Petang semalam, persidangan itu mengumumkan kertas kerja terbaik dan anugerah lain. Kali ini, terdapat 7 Anugerah Kertas Terbaik (dua tidak diterbitkan), 1 Anugerah Kertas Tema Terbaik, dan 35 Anugerah Kertas Cemerlang. Persidangan itu turut menganugerahkan 3 Anugerah Kertas Sumber (ResourceAward) dan Anugerah Impak Sosial (
 Hongmeng Smart Travel S9 dan persidangan pelancaran produk baharu senario penuh, beberapa produk baharu blockbuster dikeluarkan bersama-sama
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 dan persidangan pelancaran produk baharu senario penuh, beberapa produk baharu blockbuster dikeluarkan bersama-sama
Aug 08, 2024 am 07:02 AM
Petang ini, Hongmeng Zhixing secara rasmi mengalu-alukan jenama baharu dan kereta baharu. Pada 6 Ogos, Huawei mengadakan persidangan pelancaran produk baharu Hongmeng Smart Xingxing S9 dan senario penuh Huawei, membawakan sedan perdana pintar panoramik Xiangjie S9, M7Pro dan Huawei novaFlip baharu, MatePad Pro 12.2 inci, MatePad Air baharu, Huawei Bisheng With banyak produk pintar semua senario baharu termasuk pencetak laser siri X1, FreeBuds6i, WATCHFIT3 dan skrin pintar S5Pro, daripada perjalanan pintar, pejabat pintar kepada pakaian pintar, Huawei terus membina ekosistem pintar senario penuh untuk membawa pengguna pengalaman pintar Internet Segala-galanya. Hongmeng Zhixing: Pemerkasaan mendalam untuk menggalakkan peningkatan industri kereta pintar Huawei berganding bahu dengan rakan industri automotif China untuk menyediakan
 Pasukan Li Feifei mencadangkan ReKep untuk memberi robot kecerdasan spatial dan mengintegrasikan GPT-4o
Sep 03, 2024 pm 05:18 PM
Pasukan Li Feifei mencadangkan ReKep untuk memberi robot kecerdasan spatial dan mengintegrasikan GPT-4o
Sep 03, 2024 pm 05:18 PM
Penyepaduan mendalam penglihatan dan pembelajaran robot. Apabila dua tangan robot bekerja bersama-sama dengan lancar untuk melipat pakaian, menuang teh dan mengemas kasut, ditambah pula dengan 1X robot humanoid NEO yang telah menjadi tajuk berita baru-baru ini, anda mungkin mempunyai perasaan: kita seolah-olah memasuki zaman robot. Malah, pergerakan sutera ini adalah hasil teknologi robotik canggih + reka bentuk bingkai yang indah + model besar berbilang modal. Kami tahu bahawa robot yang berguna sering memerlukan interaksi yang kompleks dan indah dengan alam sekitar, dan persekitaran boleh diwakili sebagai kekangan dalam domain spatial dan temporal. Sebagai contoh, jika anda ingin robot menuang teh, robot terlebih dahulu perlu menggenggam pemegang teko dan memastikannya tegak tanpa menumpahkan teh, kemudian gerakkannya dengan lancar sehingga mulut periuk sejajar dengan mulut cawan. , dan kemudian condongkan teko pada sudut tertentu. ini
 Persidangan Kecerdasan Buatan Teragih DAI 2024 Call for Papers: Hari Agen, Richard Sutton, bapa pembelajaran pengukuhan, akan hadir! Yan Shuicheng, Sergey Levine dan saintis DeepMind akan memberikan ucaptama
Aug 22, 2024 pm 08:02 PM
Persidangan Kecerdasan Buatan Teragih DAI 2024 Call for Papers: Hari Agen, Richard Sutton, bapa pembelajaran pengukuhan, akan hadir! Yan Shuicheng, Sergey Levine dan saintis DeepMind akan memberikan ucaptama
Aug 22, 2024 pm 08:02 PM
Pengenalan Persidangan Dengan perkembangan pesat sains dan teknologi, kecerdasan buatan telah menjadi kuasa penting dalam menggalakkan kemajuan sosial. Dalam era ini, kami bertuah untuk menyaksikan dan mengambil bahagian dalam inovasi dan aplikasi Kecerdasan Buatan Teragih (DAI). Kecerdasan buatan yang diedarkan adalah cabang penting dalam bidang kecerdasan buatan, yang telah menarik lebih banyak perhatian dalam beberapa tahun kebelakangan ini. Agen berdasarkan model bahasa besar (LLM) tiba-tiba muncul Dengan menggabungkan pemahaman bahasa yang kuat dan keupayaan penjanaan model besar, mereka telah menunjukkan potensi besar dalam interaksi bahasa semula jadi, penaakulan pengetahuan, perancangan tugas, dsb. AIAgent mengambil alih model bahasa besar dan telah menjadi topik hangat dalam kalangan AI semasa. Au
