

Membongkar rangka kerja inferens model besar NVIDIA: TensorRT-LLM

1. Kedudukan produk TensorRT-LLM
TensorRT-LLM ialah penyelesaian inferens berskala yang dibangunkan oleh NVIDIA untuk model bahasa besar (LLM). Ia membina, menyusun dan melaksanakan graf pengiraan berdasarkan rangka kerja kompilasi pembelajaran mendalam TensorRT dan menggunakan pelaksanaan Kernel yang cekap dalam FastTransformer. Selain itu, ia menggunakan NCCL untuk komunikasi antara peranti. Pembangun boleh menyesuaikan operator untuk memenuhi keperluan khusus berdasarkan pembangunan teknologi dan perbezaan permintaan, seperti membangunkan GEMM tersuai berdasarkan cutlass. TensorRT-LLM ialah penyelesaian inferens rasmi NVIDIA, komited untuk menyediakan prestasi tinggi dan terus meningkatkan kepraktisannya.

TensorRT-LLM ialah sumber terbuka di GitHub dan dibahagikan kepada dua cawangan: Cawangan keluaran dan cawangan Dev. Cawangan Keluaran dikemas kini sekali sebulan, manakala cawangan Dev akan mengemas kini ciri daripada sumber rasmi atau komuniti dengan lebih kerap untuk memudahkan pembangun mengalami dan menilai ciri terkini. Rajah di bawah menunjukkan struktur rangka kerja TensorRT-LLM Kecuali bahagian kompilasi TensorRT hijau dan kernel yang melibatkan maklumat perkakasan, bahagian lain adalah sumber terbuka.

TensorRT-LLM juga menyediakan API yang serupa dengan Pytorch untuk mengurangkan kos pembelajaran pembangun, dan menyediakan banyak model pratakrif untuk digunakan oleh pengguna.

Disebabkan saiz model bahasa yang besar, inferens mungkin tidak dapat diselesaikan pada satu kad grafik, jadi TensorRT-LLM menyediakan dua mekanisme selari: Tensor Parallelism dan Pipeline Parallelism untuk menyokong berbilang kad atau beberapa mesin penaakulan . Mekanisme ini membolehkan model dibahagikan kepada beberapa bahagian dan diedarkan merentasi berbilang kad grafik atau mesin untuk pengiraan selari bagi meningkatkan prestasi inferens. Tensor Parallelism mencapai pengkomputeran selari dengan mengedarkan parameter model pada peranti yang berbeza dan mengira output bahagian yang berbeza pada masa yang sama. Paralelisme Saluran Paip membahagikan model kepada beberapa peringkat Setiap peringkat dikira secara selari pada peranti yang berbeza dan menghantar output ke peringkat seterusnya, dengan itu mencapai keseluruhan

Sepuluh ciri Import. LLM
TensorRT-LLM ialah alat berkuasa dengan sokongan model yang kaya dan keupayaan inferens berketepatan rendah. Pertama sekali, TensorRT-LLM menyokong model bahasa besar arus perdana, termasuk penyesuaian model yang disiapkan oleh pembangun, seperti Qwen (Qianwen), dan telah disertakan dalam sokongan rasmi. Ini bermakna pengguna boleh melanjutkan atau menyesuaikan model yang dipratentukan ini dengan mudah dan menggunakannya pada projek mereka sendiri dengan cepat dan mudah. Kedua, TensorRT-LLM menggunakan kaedah inferens ketepatan FP16/BF16 secara lalai. Penaakulan ketepatan rendah ini bukan sahaja dapat meningkatkan prestasi penaakulan, tetapi juga menggunakan kaedah pengkuantitian industri untuk terus mengoptimumkan daya pemprosesan perkakasan. Dengan mengurangkan ketepatan model, TensorRT-LLM boleh meningkatkan kelajuan dan kecekapan inferens dengan sangat baik tanpa mengorbankan terlalu banyak ketepatan. Ringkasnya, sokongan model kaya TensorRT-LLM dan keupayaan inferens ketepatan rendah menjadikannya alat yang sangat praktikal. Sama ada untuk pembangun atau penyelidik, TensorRT-LLM boleh menyediakan penyelesaian inferens yang cekap untuk membantu mereka mencapai prestasi yang lebih baik dalam aplikasi pembelajaran mendalam.


Inti satu lagi ialah MMHA (Masked Multi-Head Attention). FMHA digunakan terutamanya untuk pengiraan dalam fasa konteks, manakala MMHA terutamanya menyediakan pecutan perhatian dalam fasa penjanaan dan menyediakan sokongan untuk Volta dan seni bina seterusnya. Berbanding dengan pelaksanaan FastTransformer, TensorRT-LLM dioptimumkan lagi dan prestasinya dipertingkatkan sehingga 2x.

Satu lagi ciri penting ialah teknologi kuantisasi, yang mencapai pecutan inferens dengan ketepatan yang lebih rendah. Kaedah pengkuantitian yang biasa digunakan terbahagi kepada PTQ (Kuantisasi Pasca Latihan) dan QAT (Latihan sedar Kuantisasi Untuk TensorRT-LLM, logik penaakulan kedua-dua kaedah pengkuantitian ini adalah sama. Untuk teknologi kuantifikasi LLM, ciri penting ialah reka bentuk bersama reka bentuk algoritma dan pelaksanaan kejuruteraan, iaitu ciri perkakasan mesti dipertimbangkan pada permulaan reka bentuk kaedah kuantifikasi yang sepadan. Jika tidak, peningkatan kelajuan inferens yang dijangkakan mungkin tidak dapat dicapai.

Langkah kuantifikasi PTQ dalam TensorRT secara amnya dibahagikan kepada langkah-langkah berikut Pertama, model dikira, dan kemudian pemberat dan model ditukar kepada perwakilan TensorRT-LLM. Untuk beberapa operasi tersuai, pengguna juga perlu menulis kernel mereka sendiri. Kaedah pengiraan PTQ yang biasa digunakan termasuk INT8 berat sahaja, SmoothQuant, GPTQ dan AWQ, yang merupakan kaedah reka bentuk bersama biasa.

berat INT8-sahaja mengkuantifikasikan berat secara langsung kepada INT8, tetapi nilai pengaktifan kekal sebagai FP16. Kelebihan kaedah ini ialah storan model dikurangkan sebanyak 2x dan lebar jalur storan untuk pemberat pemuatan dikurangkan separuh, mencapai tujuan meningkatkan prestasi inferens. Kaedah ini dipanggil W8A16 dalam industri, iaitu, beratnya ialah INT8 dan nilai pengaktifan ialah FP16/BF16 - disimpan dengan ketepatan INT8 dan dikira dalam format FP16/BF16. Kaedah ini intuitif, tidak mengubah berat, mudah dilaksanakan dan mempunyai prestasi generalisasi yang baik.

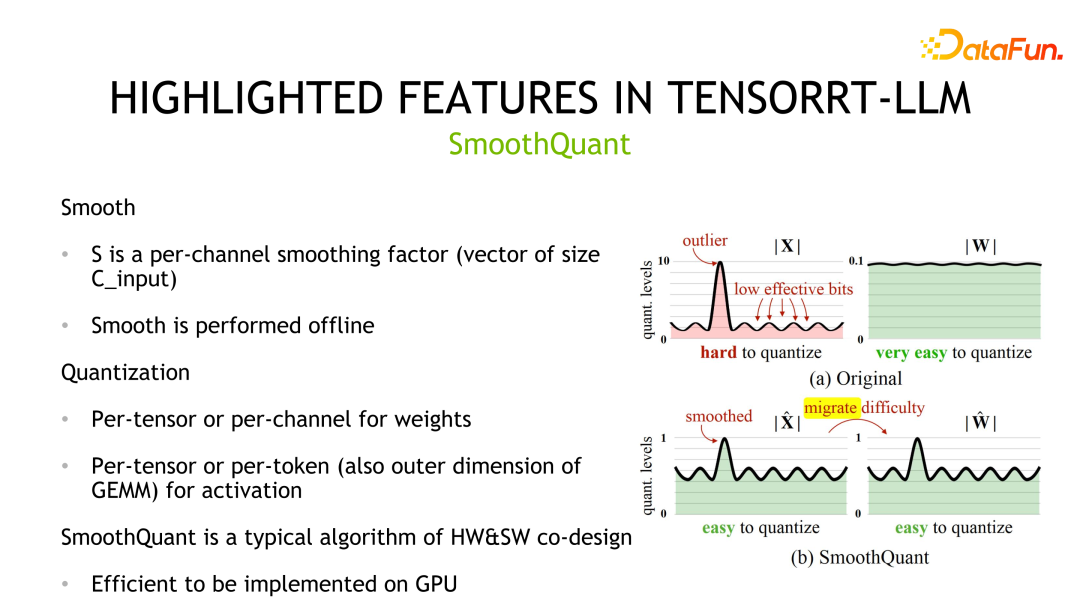
Kaedah pengiraan kedua ialah SmoothQuant, yang direka bentuk bersama oleh NVIDIA dan komuniti. Adalah diperhatikan bahawa pemberat biasanya mematuhi taburan Gaussian dan mudah untuk dikuantisasi, tetapi terdapat outlier dalam nilai pengaktifan, dan penggunaan bit kuantisasi tidak tinggi.

SmoothQuant memampatkan taburan yang sepadan dengan terlebih dahulu melicinkan nilai pengaktifan, iaitu membahagikannya dengan skala Pada masa yang sama, untuk memastikan kesetaraan, pemberat perlu didarab dengan skala yang sama. Selepas itu, kedua-dua berat dan pengaktifan boleh dikira. Penyimpanan dan ketepatan pengiraan yang sepadan boleh menjadi INT8 atau FP8, dan INT8 atau FP8 TensorCore boleh digunakan untuk pengiraan. Dari segi butiran pelaksanaan, pemberat menyokong kuantiti Per-tensor dan Per-saluran, dan nilai pengaktifan menyokong kuantifikasi Per-tensor dan Per-token.
Kaedah pengkuantitian ketiga ialah GPTQ, kaedah pengkuantitian lapisan demi lapisan yang dilaksanakan dengan meminimumkan kerugian pembinaan semula. GPTQ ialah kaedah berat sahaja, dan pengiraan menggunakan format data FP16. Kaedah ini digunakan apabila mengira model besar Memandangkan pengkuantasi itu sendiri agak mahal, pengarang mereka bentuk beberapa helah untuk mengurangkan kos pengkuantitian itu sendiri, seperti Lazy batch-updates dan mengkuantisasi berat semua baris dalam susunan yang sama. GPTQ juga boleh digunakan bersama dengan kaedah lain seperti strategi pengelompokan. Selain itu, TensorRT-LLM menyediakan prestasi pengoptimuman pelaksanaan yang berbeza untuk situasi yang berbeza. Khususnya, apabila saiz kelompok kecil, teras cuda digunakan untuk melaksanakannya, sebaliknya, apabila saiz kelompok besar, teras tensor digunakan untuk melaksanakannya.

Kaedah kuantifikasi keempat ialah AWQ. Kaedah ini menganggap bahawa tidak semua pemberat adalah sama penting, hanya 0.1%-1% daripada pemberat (berat ketara) menyumbang lebih kepada ketepatan model, dan pemberat ini bergantung pada pengagihan nilai pengaktifan dan bukannya pengagihan berat. Proses kuantifikasi kaedah ini adalah serupa dengan SmoothQuant Perbezaan utama ialah skala dikira berdasarkan taburan nilai pengaktifan.


Selain kaedah kuantifikasi, cara lain untuk meningkatkan prestasi TensorRT-LLM adalah dengan menggunakan inferens berbilang mesin dan berbilang kad. Dalam sesetengah senario, model besar terlalu besar untuk diletakkan pada satu GPU untuk inferens, atau ia boleh diletakkan tetapi kecekapan pengkomputeran terjejas, memerlukan berbilang kad atau berbilang mesin untuk inferens.

TensorRT-LLM pada masa ini menyediakan dua strategi selari, Tensor Parallelism dan Pipeline Parallelism. TP membahagikan model secara menegak dan meletakkan setiap bahagian pada peranti yang berbeza Ini akan memperkenalkan komunikasi data yang kerap antara peranti dan biasanya digunakan dalam senario dengan sambungan tinggi antara peranti, seperti NVLINK. Kaedah pembahagian lain ialah pembahagian mendatar Pada masa ini, hanya terdapat satu bahagian hadapan mendatar, dan kaedah komunikasi yang sepadan ialah komunikasi titik ke titik, yang sesuai untuk senario di mana jalur lebar komunikasi peranti adalah lemah.

Ciri terakhir untuk diserlahkan ialah batching dalam penerbangan. Batching ialah amalan biasa untuk meningkatkan prestasi inferens, tetapi dalam senario inferens LLM, panjang output setiap sampel/permintaan dalam satu kelompok tidak dapat diramalkan. Jika anda mengikuti kaedah batching statik, kelewatan kumpulan bergantung pada output terpanjang dalam sampel/permintaan. Oleh itu, walaupun output sampel/permintaan yang lebih pendek telah tamat, sumber pengkomputeran belum dikeluarkan, dan kelewatannya adalah sama dengan kelewatan sampel/permintaan output terpanjang. Kaedah batching dalam penerbangan adalah dengan memasukkan sampel/permintaan baharu pada penghujung sampel/permintaan. Dengan cara ini, ia bukan sahaja mengurangkan kelewatan satu sampel/permintaan dan mengelakkan pembaziran sumber, tetapi juga meningkatkan daya pemprosesan keseluruhan sistem.

3. Proses Penggunaan Tensorrt-LLM
Tensorrt-LLM adalah serupa dengan penggunaan Tensorrt. TensorRT-LLM API yang disediakan menulis semula dan membina semula graf pengiraan model, kemudian menggunakan TensorRT untuk penyusunan dan pengoptimuman, dan kemudian menyimpannya sebagai enjin bersiri untuk penggunaan inferens.

Mengambil Llama sebagai contoh, mula-mula pasang TensorRT-LLM, kemudian muat turun model pra-latihan, kemudian gunakan TensorRT-LLM untuk menyusun model, dan akhirnya lakukan inferens.

Untuk penyahpepijatan inferens model, kaedah penyahpepijatan TensorRT-LLM adalah konsisten dengan TensorRT. Salah satu pengoptimuman yang disediakan terima kasih kepada pengkompil pembelajaran mendalam, iaitu TensorRT, ialah gabungan lapisan. Oleh itu, jika anda ingin mengeluarkan hasil lapisan tertentu, anda perlu menandakan lapisan yang sepadan sebagai lapisan keluaran untuk mengelakkannya daripada dioptimumkan oleh pengkompil, dan kemudian membandingkan dan menganalisisnya dengan garis dasar. Pada masa yang sama, setiap kali lapisan keluaran baharu ditanda, enjin TensorRT mesti disusun semula.

Untuk lapisan tersuai, TensorRT-LLM menyediakan banyak pengendali seperti Pytorch untuk membantu pengguna melaksanakan fungsi tanpa perlu menulis kernel itu sendiri. Seperti yang ditunjukkan dalam contoh, API yang disediakan oleh TensorRT-LLM digunakan untuk melaksanakan logik norma rms, dan TensorRT secara automatik akan menjana kod pelaksanaan yang sepadan pada GPU.

Jika pengguna mempunyai keperluan prestasi yang lebih tinggi atau TensorRT-LLM tidak menyediakan blok binaan untuk melaksanakan fungsi yang sepadan, pengguna perlu menyesuaikan kernel dan membungkusnya sebagai pemalam untuk digunakan TensorRT-LLM. Kod sampel ialah kod sampel yang melaksanakan GEMM tersuai SmoothQuant dan merangkumnya ke dalam pemalam untuk TensorRT-LLM memanggil.

4. Prestasi inferens TensorRT-LLM
Butiran seperti prestasi dan konfigurasi boleh dilihat di laman web rasmi, dan di sini tidak akan diperkenalkan secara terperinci Produk ini telah bekerjasama dengan banyak pengeluar domestik utama sejak penubuhannya. Melalui maklum balas, secara amnya, TensorRT-LLM ialah penyelesaian terbaik pada masa ini dari perspektif prestasi. Memandangkan banyak faktor seperti lelaran teknologi, kaedah pengoptimuman dan pengoptimuman sistem akan menjejaskan prestasi dan berubah dengan cepat, data prestasi TensorRT-LLM tidak akan diperkenalkan secara terperinci di sini. Jika anda berminat, anda boleh pergi ke laman web rasmi untuk mendapatkan butiran persembahan ini semuanya boleh dibuat semula.
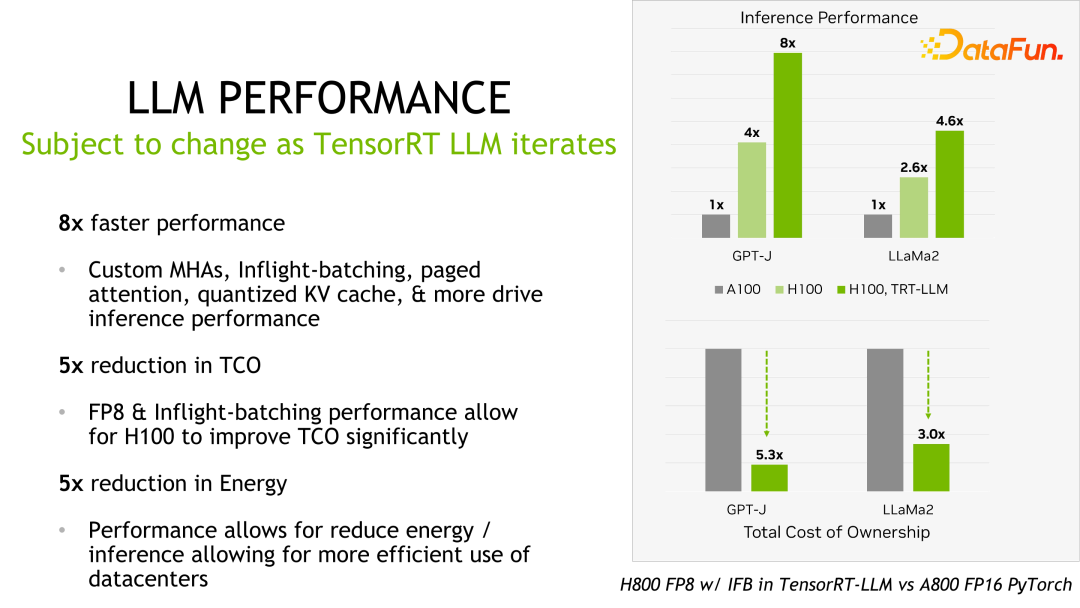
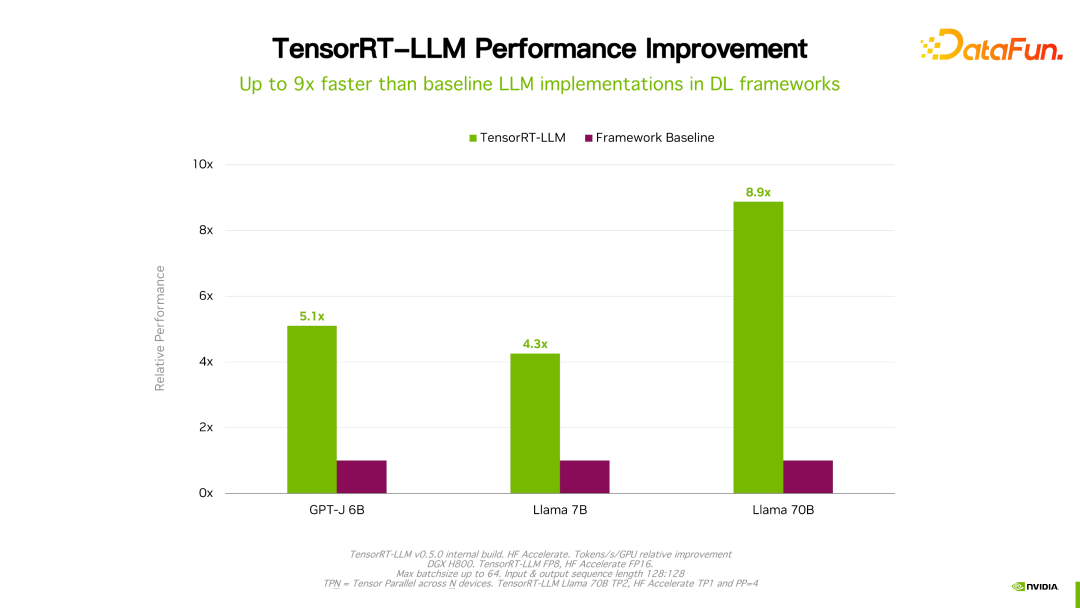
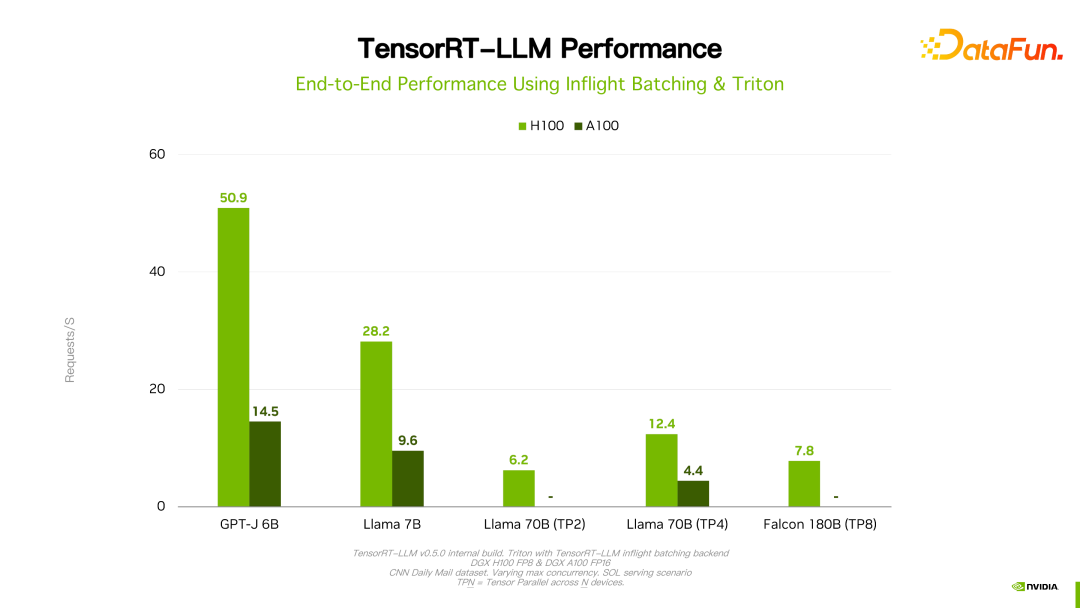
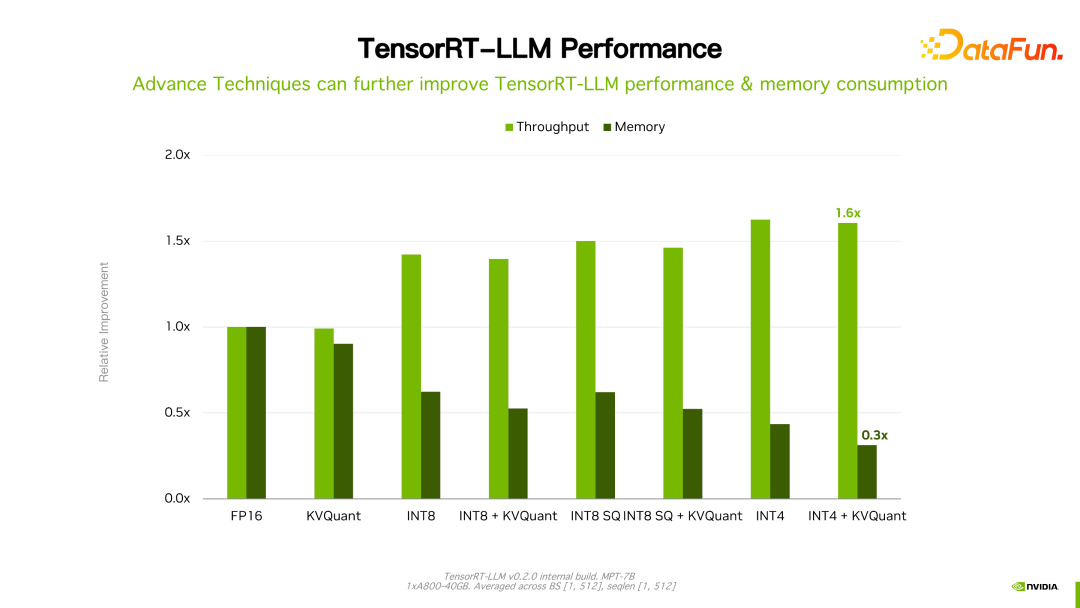
Perlu dinyatakan bahawa berbanding dengan versi sebelumnya, prestasi TensorRT-LLM terus meningkat. Seperti yang ditunjukkan dalam rajah di atas, berdasarkan FP16, selepas menggunakan KVQuant, penggunaan memori video dikurangkan sambil mengekalkan kelajuan yang sama. Menggunakan INT8, anda boleh melihat peningkatan yang ketara dalam pemprosesan, dan pada masa yang sama, penggunaan memori dikurangkan lagi. Dapat dilihat bahawa dengan evolusi berterusan teknologi pengoptimuman TensorRT-LLM, prestasi akan terus bertambah baik. Trend ini akan berterusan.
5. Prospek masa depan TensorRT-LLM
LLM ialah senario dengan kos inferens yang tinggi dan sensitif kos. Kami percaya bahawa untuk mencapai kesan pecutan seratus kali ganda seterusnya, lelaran bersama algoritma dan perkakasan diperlukan, dan matlamat ini boleh dicapai melalui reka bentuk bersama antara perisian dan perkakasan. Perkakasan menyediakan pengkuantitian ketepatan yang lebih rendah, manakala perspektif perisian menggunakan algoritma seperti pengkuantitian dioptimumkan dan pemangkasan rangkaian untuk meningkatkan lagi prestasi.

TensorRT-LLM, NVIDIA akan terus berusaha untuk meningkatkan prestasi TensorRT-LLM pada masa hadapan. Pada masa yang sama, melalui sumber terbuka, kami mengumpul maklum balas dan pendapat untuk meningkatkan kemudahan penggunaannya. Selain itu, memfokuskan pada kemudahan penggunaan, kami akan membangunkan dan membuka sumber lebih banyak alat aplikasi, seperti zon model atau alat kuantitatif, dsb., untuk meningkatkan keserasian dengan rangka kerja arus perdana dan menyediakan penyelesaian hujung ke hujung daripada latihan kepada inferens dan penggunaan .

6. Sesi Soal Jawab
S1: Adakah setiap output pengiraan perlu dinyahkuantisasi? Apakah yang perlu saya lakukan jika limpahan ketepatan berlaku semasa kuantisasi?
A1: Pada masa ini TensorRT-LLM menyediakan dua jenis kaedah, iaitu FP8 dan kaedah pengkuantitian INT4/INT8 yang baru sahaja disebut. Ketepatan rendah Jika INT8 digunakan sebagai GEMM, penumpuk akan menggunakan jenis data berketepatan tinggi, seperti fp16, atau bahkan fp32 untuk mengelakkan limpahan. Berkenaan kuantisasi songsang, mengambil kuantisasi fp8 sebagai contoh, apabila TensorRT-LLM mengoptimumkan graf pengiraan, ia mungkin secara automatik menggerakkan nod kuantisasi songsang dan menggabungkannya ke dalam operasi lain untuk mencapai tujuan pengoptimuman. Walau bagaimanapun, GPTQ dan QAT yang diperkenalkan sebelum ini sedang ditulis dalam kernel melalui pengekodan keras, dan tiada pemprosesan bersatu nod pengkuantitian atau penyahkuansian.
S2: Adakah anda sedang melakukan pengkuantitian songsang khusus untuk model tertentu?
A2: Kuantifikasi semasa memang seperti ini, memberikan sokongan untuk model yang berbeza. Kami mempunyai rancangan untuk membuat API yang lebih bersih atau untuk menyokong kuantiti model secara seragam melalui item konfigurasi.
S3: Untuk amalan terbaik, patutkah TensorRT-LLM digunakan secara terus atau digabungkan dengan Pelayan Inferens Triton? Adakah terdapat ciri yang hilang jika digunakan bersama?
A3: Kerana sesetengah fungsi bukan sumber terbuka, jika ia adalah hidangan anda sendiri, anda perlu melakukan kerja penyesuaian Jika ia adalah triton, ia akan menjadi penyelesaian yang lengkap.
S4: Terdapat beberapa kaedah kuantitatif untuk penentukuran kuantitatif, dan apakah nisbah pecutan? Berapa banyak mata yang terdapat dalam kesan skim kuantifikasi ini? Panjang keluaran bagi setiap contoh dalam percabangan dalam penerbangan tidak diketahui Bagaimana untuk melakukan batching dinamik?
A4: Anda boleh bercakap secara persendirian mengenai prestasi kuantiti. Faktor tidak terkawal, seperti set data yang digunakan untuk kuantifikasi dan kesannya. Berkenaan batching dalam penerbangan, ia merujuk kepada mengesan dan menilai sama ada output sampel/permintaan tertentu telah tamat semasa masa jalan. Jika ya, dan kemudian masukkan permintaan lain yang tiba, TensorRT-LLM tidak akan dan tidak boleh meramalkan panjang output yang diramalkan.
S5: Adakah antara muka C++ dan antara muka ular sawa bagi percabangan Dalam penerbangan kekal konsisten? Kos pemasangan TensorRT-LLM adalah tinggi Adakah terdapat sebarang rancangan penambahbaikan pada masa hadapan? Adakah TensorRT-LLM mempunyai perspektif pembangunan yang berbeza daripada VLLM?
A5: Kami akan cuba yang terbaik untuk menyediakan antara muka yang konsisten antara masa jalan c++ dan masa jalan python, yang sudah dalam perancangan. Sebelum ini, pasukan memberi tumpuan kepada meningkatkan prestasi dan menambah baik fungsi, dan akan terus meningkatkan kebolehgunaan pada masa hadapan. Bukan mudah untuk membandingkan secara langsung dengan vllm di sini, tetapi NVIDIA akan terus meningkatkan pelaburan dalam pembangunan TensorRT-LLM, komuniti dan sokongan pelanggan untuk menyediakan industri dengan penyelesaian inferens LLM yang terbaik.
Atas ialah kandungan terperinci Membongkar rangka kerja inferens model besar NVIDIA: TensorRT-LLM. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Adakah pengeluaran halaman H5 adalah pembangunan front-end?
Apr 05, 2025 pm 11:42 PM
Adakah pengeluaran halaman H5 adalah pembangunan front-end?
Apr 05, 2025 pm 11:42 PM
Ya, pengeluaran halaman H5 adalah kaedah pelaksanaan penting untuk pembangunan front-end, yang melibatkan teknologi teras seperti HTML, CSS dan JavaScript. Pemaju membina halaman H5 yang dinamik dan berkuasa dengan bijak menggabungkan teknologi ini, seperti menggunakan & lt; kanvas & gt; Tag untuk menarik grafik atau menggunakan JavaScript untuk mengawal tingkah laku interaksi.
 Bagaimana untuk menyesuaikan simbol saiz semula melalui CSS dan menjadikannya seragam dengan warna latar belakang?
Apr 05, 2025 pm 02:30 PM
Bagaimana untuk menyesuaikan simbol saiz semula melalui CSS dan menjadikannya seragam dengan warna latar belakang?
Apr 05, 2025 pm 02:30 PM
Kaedah penyesuaian simbol saiz semula dalam CSS bersatu dengan warna latar belakang. Dalam perkembangan harian, kita sering menghadapi situasi di mana kita perlu menyesuaikan butiran antara muka pengguna, seperti menyesuaikan ...
 Kenapa unsur-unsur blok sebaris tidak disengajakan? Bagaimana menyelesaikan masalah ini?
Apr 04, 2025 pm 10:39 PM
Kenapa unsur-unsur blok sebaris tidak disengajakan? Bagaimana menyelesaikan masalah ini?
Apr 04, 2025 pm 10:39 PM
Mengenai sebab-sebab dan penyelesaian untuk memaparkan unsur-unsur blok sebaris. Apabila menulis susun atur laman web, kami sering menghadapi masalah paparan yang kelihatan aneh. Bandingkan ...
 Harga terbaru Bitcoin pada 2018-2024 USD
Feb 15, 2025 pm 07:12 PM
Harga terbaru Bitcoin pada 2018-2024 USD
Feb 15, 2025 pm 07:12 PM
Harga USD Bitcoin masa nyata Faktor yang menjejaskan harga bitcoin Petunjuk untuk meramalkan harga bitcoin masa depan Berikut adalah beberapa maklumat penting mengenai harga Bitcoin pada 2018-2024:
 Bagaimana cara menggunakan atribut clip-path CSS untuk mencapai kesan lengkung 45 darjah segmen?
Apr 04, 2025 pm 11:45 PM
Bagaimana cara menggunakan atribut clip-path CSS untuk mencapai kesan lengkung 45 darjah segmen?
Apr 04, 2025 pm 11:45 PM
Bagaimana untuk mencapai kesan lengkung 45 darjah segmen? Dalam proses melaksanakan segmen, bagaimana membuat sempadan yang betul berubah menjadi lengkung 45 darjah ketika mengklik butang kiri, dan titik ...
 Bagaimana untuk mengawal bahagian atas dan akhir halaman dalam tetapan percetakan penyemak imbas melalui JavaScript atau CSS?
Apr 05, 2025 pm 10:39 PM
Bagaimana untuk mengawal bahagian atas dan akhir halaman dalam tetapan percetakan penyemak imbas melalui JavaScript atau CSS?
Apr 05, 2025 pm 10:39 PM
Cara menggunakan JavaScript atau CSS untuk mengawal bahagian atas dan akhir halaman dalam tetapan percetakan penyemak imbas. Dalam tetapan percetakan penyemak imbas, ada pilihan untuk mengawal sama ada paparan ...
 Bagaimana untuk mencapai kesan segmentasi dengan sempadan lengkung 45 darjah?
Apr 04, 2025 pm 11:48 PM
Bagaimana untuk mencapai kesan segmentasi dengan sempadan lengkung 45 darjah?
Apr 04, 2025 pm 11:48 PM
Petua untuk melaksanakan kesan segmen dalam reka bentuk antara muka pengguna, Segmenter adalah elemen navigasi biasa, terutamanya dalam aplikasi mudah alih dan laman web responsif. …
 Teks di bawah susun atur flex ditinggalkan tetapi bekas dibuka? Bagaimana menyelesaikannya?
Apr 05, 2025 pm 11:00 PM
Teks di bawah susun atur flex ditinggalkan tetapi bekas dibuka? Bagaimana menyelesaikannya?
Apr 05, 2025 pm 11:00 PM
Masalah pembukaan kontena kerana peninggalan teks yang berlebihan di bawah susun atur flex dan penyelesaian digunakan ...
