
 Peranti teknologi
AI
GPT-4 enggan menerima dan telah diambil alih oleh Bard: model terbaru telah memasuki pasaran
Peranti teknologi
AI
GPT-4 enggan menerima dan telah diambil alih oleh Bard: model terbaru telah memasuki pasaran
GPT-4 enggan menerima dan telah diambil alih oleh Bard: model terbaru telah memasuki pasaran

Senarai berwibawa "Pertandingan Kelayakan Model Besar" Chatbot Arena telah dimuat semula:
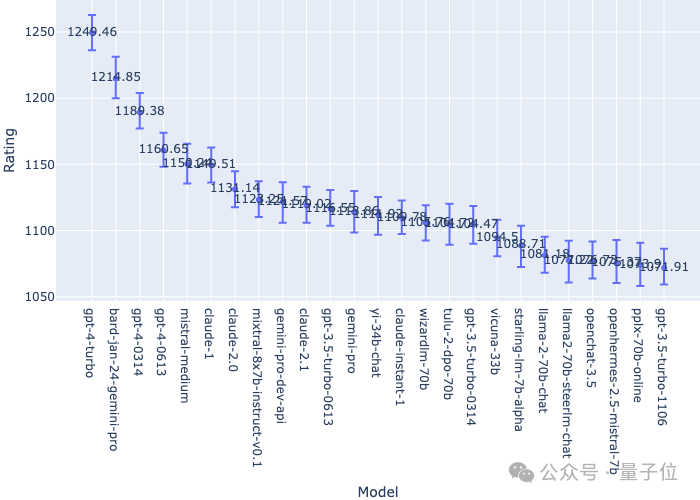
Google Bard melepasi GPT-4 dan menduduki tempat kedua, kedua selepas GPT-4 Turbo.
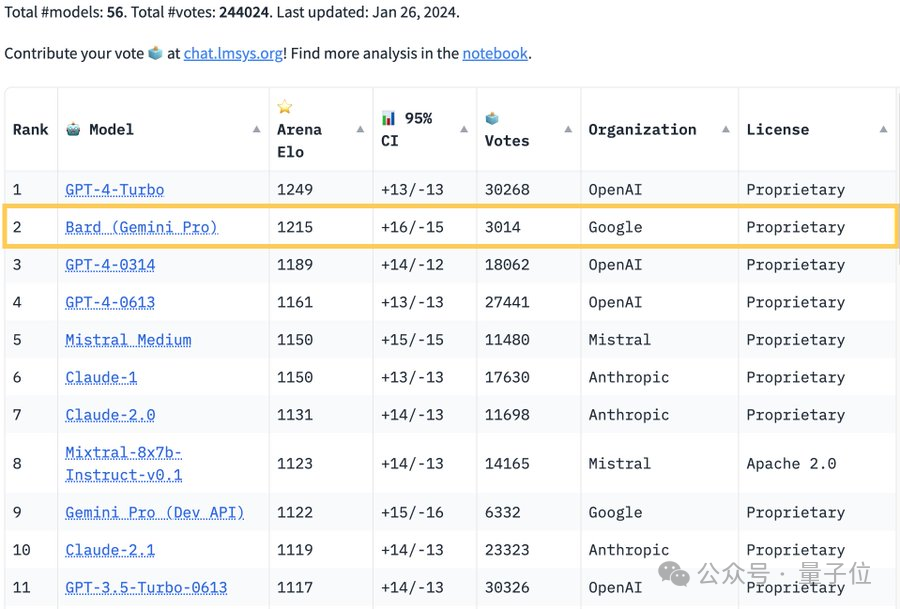
Namun, ramai netizen menyatakan "tidak puas hati" dan "tidak adil" mengenai perkara ini.
Ternyata Jeff Dean, ketua Google AI, mendedahkan bahawa prestasi Bard telah bertambah baik kerana ia dilengkapi dengan versi baharu model besar-Gemini Pro-skala.

Ini juga bermakna Bard bermain dalam "perlawanan peringkat" mempunyai keupayaan untuk menyambung ke Internet.
Ragu-ragu netizen berkisar tentang perkara ini:
Sangat mudah untuk menimbulkan salah faham dengan mencampurkan model besar dalam talian dan luar talian pada senarai kedudukan yang sama. .
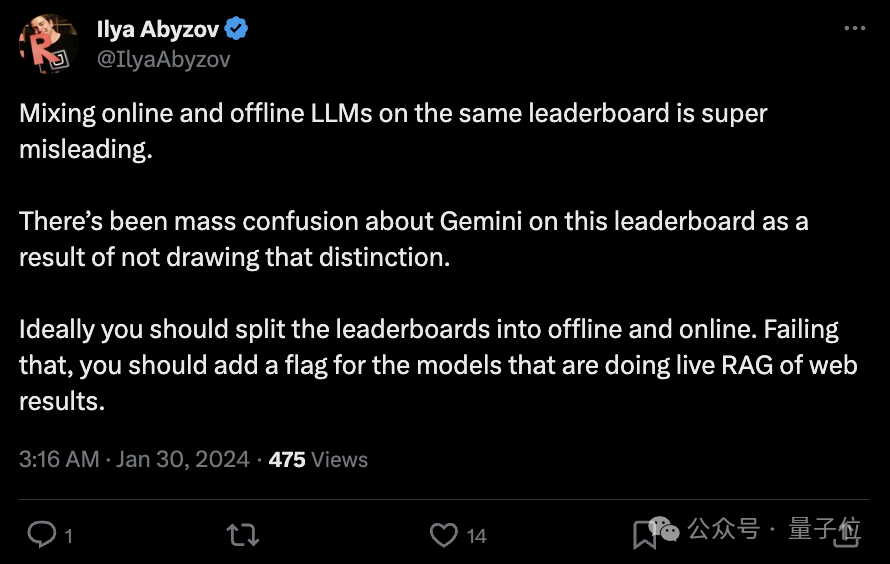
Dalam pelbagai keraguan, Imsys secara rasmi bertindak balas, menyatakan:
arena kedudukan adalah masa nyata adalah terbuka dan telus, dan penyelidikan mengenai kepelbagaian segera pengguna dan kualiti pengundian serta set data yang sepadan akan dikeluarkan tidak lama lagi
Berkenaan isu yang paling dibimbangkan oleh netizen, GPT-4, yang diatasi oleh Bard, adalah satu; versi luar talian, Imsys berkata " Jika akses kepada data masa nyata boleh meningkatkan pengalaman pengguna, kedudukan akan mencerminkannya." 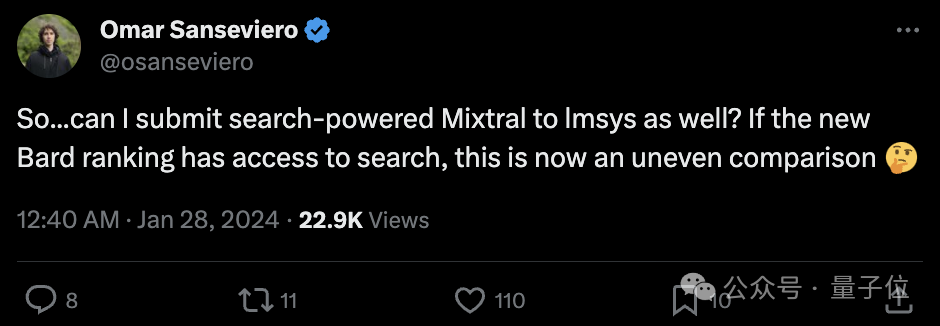
- Bagaimana Bard mengatasi GPT-4?
Chatbot Arena ialah senarai model besar yang berwibawa, dicipta oleh organisasi Imsys (Organisasi Sistem Model Besar) yang diketuai oleh penyelidik UC Berkeley.
Kedudukan ini menggunakan peraturan undian 1V1pertempuran tanpa nama dan disenaraikan berdasarkan sistem penilaian Elo.
Secara khusus, halaman undian adalah seperti berikut Kedua-dua model, Model A dan B, kedua-duanya tanpa nama. dan A dan B. Kedua-dua A dan B adalah sama baik.
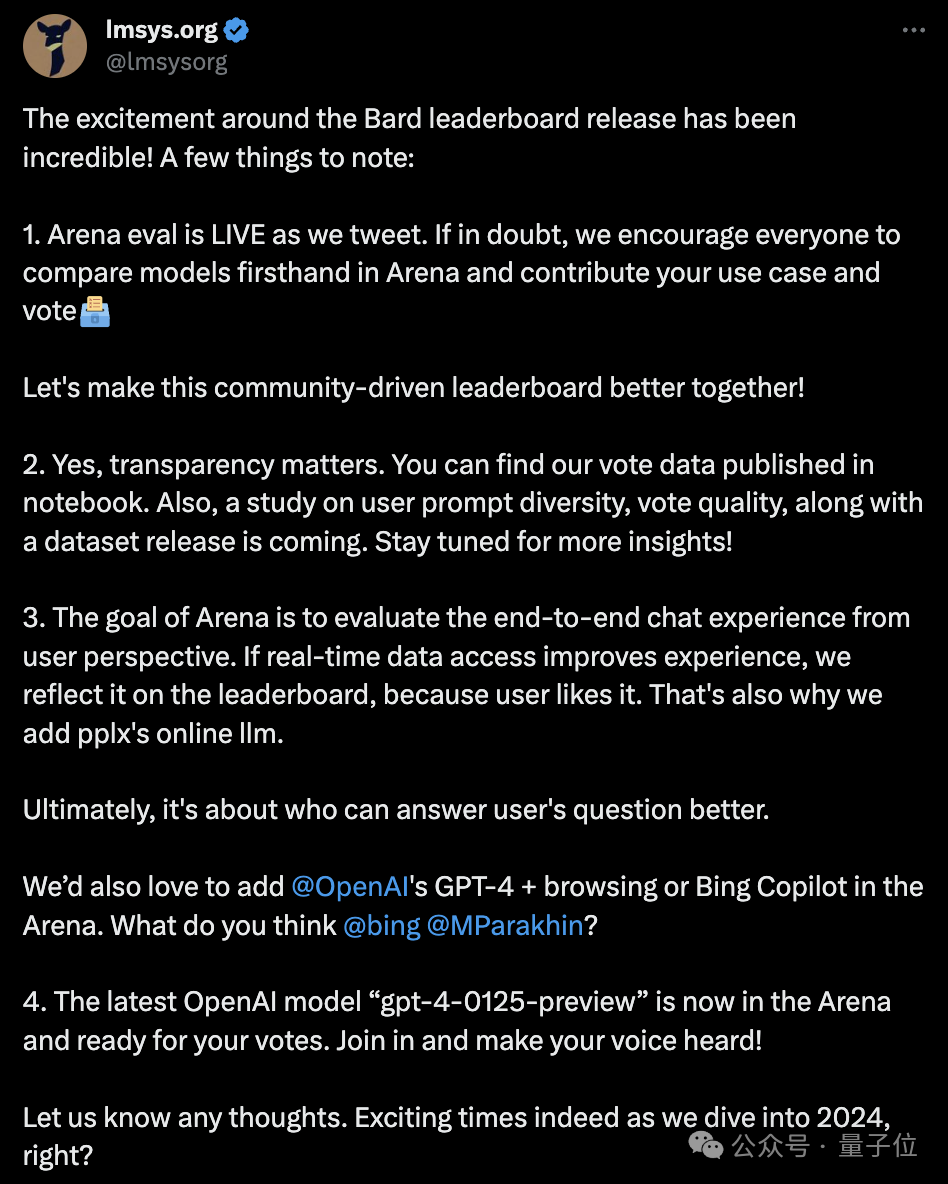
Perlu dinyatakan bahawa jika identiti model dibocorkan semasa proses soal jawab, undian akan menjadi tidak sah.
Mengikut senarai semasa, terdapat 56 model besar dalam arena: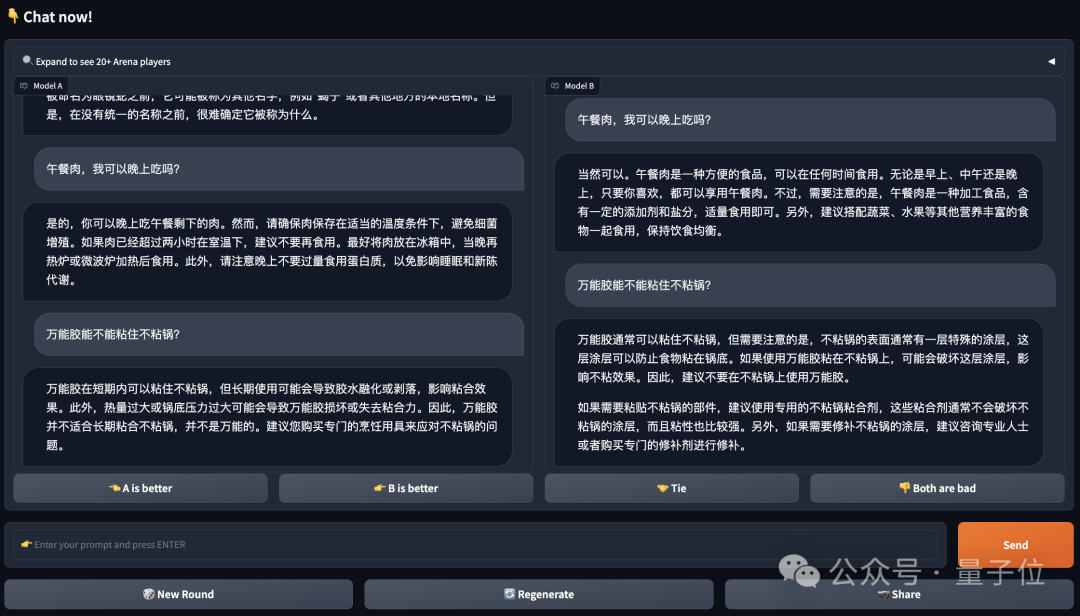

(tiada seri) 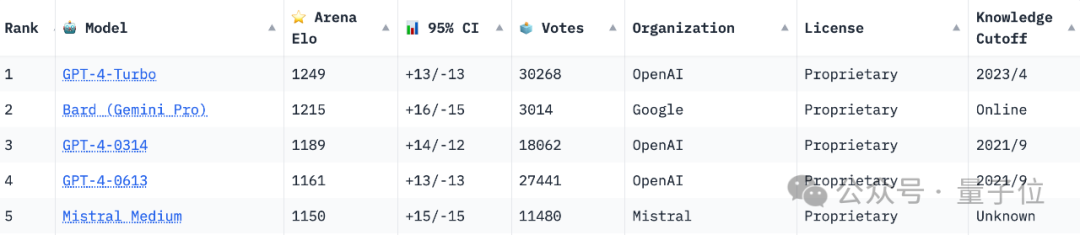 :
:
Selain itu, papan pendahulu Arena Chatbot menggunakan bootstrap untuk mencuba secara rawak anggaran skor Elo sebanyak 1,000 kali untuk menilai selang keyakinan dan banyak lagi.
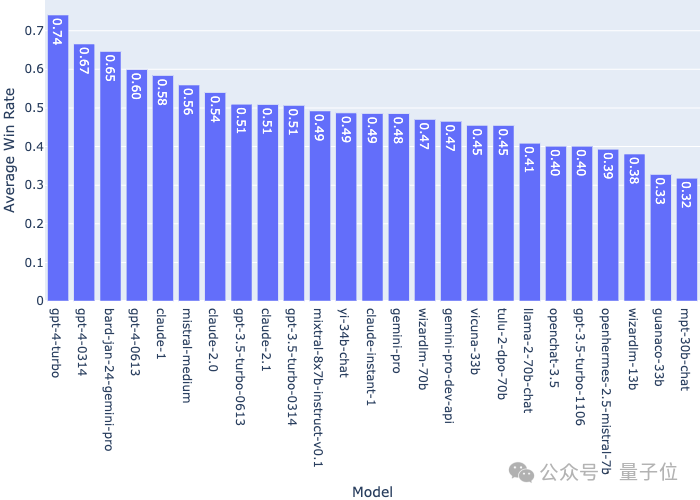
Kadar kemenangan purata bagi model tunggal berbanding semua model lain adalah seperti berikut:
Walau bagaimanapun, perlu diperhatikan bahawa kedudukan Arena adalah masa nyata, dan walaupun Bard kini berada di kedudukan kedua, ia hanya mempunyai jumlah lebih daripada 3,000 undi.
Sebagai perbandingan, jumlah undian untuk GPT-4 Turbo telah mencecah 30,000+, dan undian kedua-dua versi yang diatasi juga beberapa kali ganda berbanding undian Bard.

Sekarang versi terkini GPT-4 telah memasuki pasaran (walaupun masih belum dikemas kini mengenai ranking), kita perlu menunggu keputusan seterusnya~
Pautan rujukan: https:// twitter.com/lmsysorg /status/1752035632489300239.
Atas ialah kandungan terperinci GPT-4 enggan menerima dan telah diambil alih oleh Bard: model terbaru telah memasuki pasaran. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Cara Mengulas DeepSeek
Feb 19, 2025 pm 05:42 PM
Cara Mengulas DeepSeek
Feb 19, 2025 pm 05:42 PM
DeepSeek adalah alat pengambilan maklumat yang kuat. .
 Cara Mencari DeepSeek
Feb 19, 2025 pm 05:39 PM
Cara Mencari DeepSeek
Feb 19, 2025 pm 05:39 PM
DeepSeek adalah enjin carian proprietari yang hanya mencari dalam pangkalan data atau sistem tertentu, lebih cepat dan lebih tepat. Apabila menggunakannya, pengguna dinasihatkan untuk membaca dokumen itu, cuba strategi carian yang berbeza, dapatkan bantuan dan maklum balas mengenai pengalaman pengguna untuk memanfaatkan kelebihan mereka.
 Sesame Open Door Exchange Web Pautan Pautan Gerbang Perdagangan Laman Web Pendaftaran Terkini
Feb 28, 2025 am 11:06 AM
Sesame Open Door Exchange Web Pautan Pautan Gerbang Perdagangan Laman Web Pendaftaran Terkini
Feb 28, 2025 am 11:06 AM
Artikel ini memperkenalkan proses pendaftaran versi web Web Open Exchange (GATE.IO) dan aplikasi Perdagangan Gate secara terperinci. Sama ada pendaftaran web atau pendaftaran aplikasi, anda perlu melawat laman web rasmi atau App Store untuk memuat turun aplikasi tulen, kemudian isi nama pengguna, kata laluan, e -mel, nombor telefon bimbit dan maklumat lain, dan lengkap e -mel atau pengesahan telefon bimbit.
 Mengapa pautan Bybit Exchange tidak dimuat turun dan dipasang secara langsung?
Feb 21, 2025 pm 10:57 PM
Mengapa pautan Bybit Exchange tidak dimuat turun dan dipasang secara langsung?
Feb 21, 2025 pm 10:57 PM
Mengapa pautan Bybit Exchange tidak dimuat turun dan dipasang secara langsung? Bybit adalah pertukaran cryptocurrency yang menyediakan perkhidmatan perdagangan kepada pengguna. Aplikasi mudah alih Exchange tidak boleh dimuat turun terus melalui AppStore atau GooglePlay untuk sebab -sebab berikut: 1. Aplikasi pertukaran cryptocurrency sering tidak memenuhi keperluan ini kerana ia melibatkan perkhidmatan kewangan dan memerlukan peraturan dan standard keselamatan tertentu. 2. Undang -undang dan Peraturan Pematuhan di banyak negara, aktiviti yang berkaitan dengan urus niaga cryptocurrency dikawal atau terhad. Untuk mematuhi peraturan ini, aplikasi bybit hanya boleh digunakan melalui laman web rasmi atau saluran yang diberi kuasa lain
 Platform Perdagangan Pintu Terbuka Sesame Muat turun Versi Mudah Alih Platform Perdagangan Platform Perdagangan Alamat Muat Turun
Feb 28, 2025 am 10:51 AM
Platform Perdagangan Pintu Terbuka Sesame Muat turun Versi Mudah Alih Platform Perdagangan Platform Perdagangan Alamat Muat Turun
Feb 28, 2025 am 10:51 AM
Adalah penting untuk memilih saluran rasmi untuk memuat turun aplikasi dan memastikan keselamatan akaun anda.
 Top 10 Disyorkan untuk App Perdagangan Aset Digital Crypto (2025 Global Ranking)
Mar 18, 2025 pm 12:15 PM
Top 10 Disyorkan untuk App Perdagangan Aset Digital Crypto (2025 Global Ranking)
Mar 18, 2025 pm 12:15 PM
Artikel ini mencadangkan sepuluh platform perdagangan cryptocurrency teratas yang memberi perhatian kepada, termasuk Binance, OKX, Gate.io, Bitflyer, Kucoin, Bybit, Coinbase Pro, Kraken, BYDFI dan Xbit yang desentralisasi. Platform ini mempunyai kelebihan mereka sendiri dari segi kuantiti mata wang transaksi, jenis urus niaga, keselamatan, pematuhan, dan ciri khas. Memilih platform yang sesuai memerlukan pertimbangan yang komprehensif berdasarkan pengalaman perdagangan anda sendiri, toleransi risiko dan keutamaan pelaburan. Semoga artikel ini membantu anda mencari saman terbaik untuk diri sendiri
 Portal Log Masuk Versi Rasmi Binance Binance
Feb 21, 2025 pm 05:42 PM
Portal Log Masuk Versi Rasmi Binance Binance
Feb 21, 2025 pm 05:42 PM
Untuk mengakses versi Login Laman Web Binance yang terkini, ikuti langkah mudah ini. Pergi ke laman web rasmi dan klik butang "Login" di sudut kanan atas. Pilih kaedah log masuk anda yang sedia ada. Masukkan nombor mudah alih berdaftar atau e -mel dan kata laluan anda dan pengesahan lengkap (seperti kod pengesahan mudah alih atau Google Authenticator). Selepas pengesahan yang berjaya, anda boleh mengakses Portal Log masuk laman web rasmi Binance.
 Alamat muat turun terbaru Bitget pada tahun 2025: Langkah -langkah untuk mendapatkan aplikasi rasmi
Feb 25, 2025 pm 02:54 PM
Alamat muat turun terbaru Bitget pada tahun 2025: Langkah -langkah untuk mendapatkan aplikasi rasmi
Feb 25, 2025 pm 02:54 PM
Panduan ini menyediakan langkah muat turun dan pemasangan terperinci untuk aplikasi Bitget Exchange rasmi, sesuai untuk sistem Android dan iOS. Panduan ini mengintegrasikan maklumat dari pelbagai sumber yang berwibawa, termasuk laman web rasmi, App Store, dan Google Play, dan menekankan pertimbangan semasa muat turun dan pengurusan akaun. Pengguna boleh memuat turun aplikasinya dari saluran rasmi, termasuk App Store, muat turun APK laman web rasmi dan melompat laman web rasmi, dan lengkap pendaftaran, pengesahan identiti dan tetapan keselamatan. Di samping itu, panduan itu merangkumi soalan dan pertimbangan yang sering ditanya, seperti
