

GPT-4V OpenAI dan model bahasa besar berbilang modal Gemini Google telah menarik perhatian meluas daripada industri dan akademia. Model ini menunjukkan pemahaman mendalam tentang video dalam berbilang domain, menunjukkan potensinya dari perspektif yang berbeza. Kemajuan ini dilihat secara meluas sebagai langkah penting ke arah kecerdasan am buatan (AGI).
Tetapi jika saya memberitahu anda bahawa GPT-4V boleh salah membaca tingkah laku watak dalam komik, izinkan saya bertanya: Yuanfang, apa pendapat anda?
Mari kita lihat siri komik mini ini:
 Gambar
Gambar
Jika anda membiarkan kecerdasan tertinggi dalam dunia biologi - manusia, iaitu, rakan-rakan pembaca, akan menerangkannya. mungkin akan berkata:
 Gambar
Gambar
Kemudian mari kita lihat apakah kecerdasan tertinggi dalam dunia mesin - iaitu, GPT-4V - akan menerangkan apabila ia datang kepada siri komik mini ini?
 Gambar - 4V, sebagai perisikan mesin yang diiktiraf sebagai berdiri di bahagian atas rantai penghinaan, sebenarnya secara terang-terangan berbohong.
Gambar - 4V, sebagai perisikan mesin yang diiktiraf sebagai berdiri di bahagian atas rantai penghinaan, sebenarnya secara terang-terangan berbohong.
 Contoh ini datang daripada keputusan terkini pasukan penyelidik di University of Maryland dan North Carolina Chapel Hill, yang melancarkan Mementos, penanda aras inferens untuk jujukan imej yang direka khusus untuk MLLM.
Contoh ini datang daripada keputusan terkini pasukan penyelidik di University of Maryland dan North Carolina Chapel Hill, yang melancarkan Mementos, penanda aras inferens untuk jujukan imej yang direka khusus untuk MLLM.
 Gambar
Gambar
 Ia melibatkan pelbagai jenis gambar, meliputi tiga kategori utama: imej dunia sebenar, imej robot dan imej animasi. Dan mengandungi 4,761 jujukan imej yang pelbagai dengan panjang yang berbeza, setiap satu dengan anotasi manusia yang menerangkan objek utama dan kelakuannya dalam jujukan itu.
Ia melibatkan pelbagai jenis gambar, meliputi tiga kategori utama: imej dunia sebenar, imej robot dan imej animasi. Dan mengandungi 4,761 jujukan imej yang pelbagai dengan panjang yang berbeza, setiap satu dengan anotasi manusia yang menerangkan objek utama dan kelakuannya dalam jujukan itu.
Gambar
Data pada masa ini adalah sumber terbuka dan masih dikemas kini. Jenis halusinasi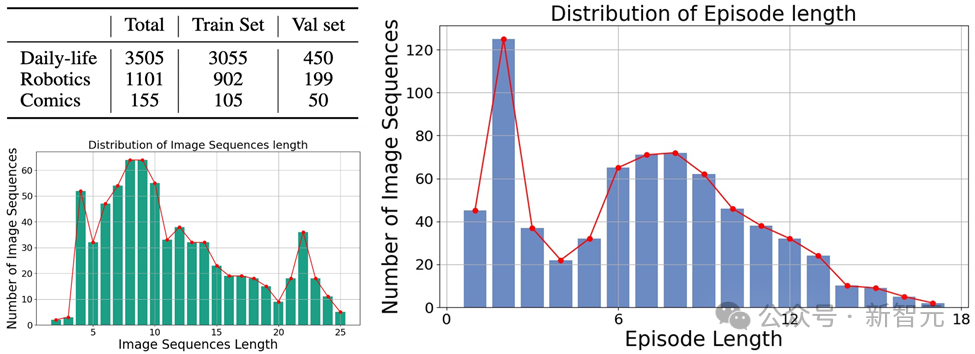 Dalam kertas kerja, penulis menerangkan dua jenis halusinasi yang akan dihasilkan oleh MLLM dalam Mementos: halusinasi objek dan halusinasi tingkah laku. Seperti namanya, halusinasi objek ialah membayangkan objek (objek) yang tidak wujud, manakala halusinasi tingkah laku ialah membayangkan tindakan dan tingkah laku yang tidak dilakukan oleh objek tersebut.
Dalam kertas kerja, penulis menerangkan dua jenis halusinasi yang akan dihasilkan oleh MLLM dalam Mementos: halusinasi objek dan halusinasi tingkah laku. Seperti namanya, halusinasi objek ialah membayangkan objek (objek) yang tidak wujud, manakala halusinasi tingkah laku ialah membayangkan tindakan dan tingkah laku yang tidak dilakukan oleh objek tersebut.
Kaedah penilaian
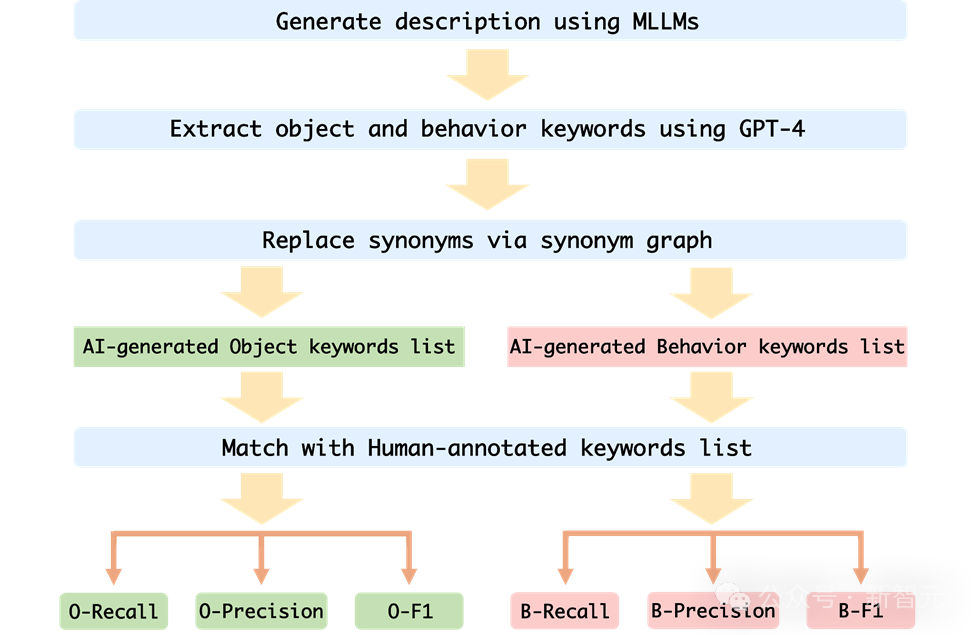
Untuk menilai dengan tepat halusinasi tingkah laku dan halusinasi objek MLLM pada Mementos, pasukan penyelidik memilih untuk memadankan kata kunci dengan perihalan imej yang dihasilkan oleh MLLM dan perihalan anotasi manusia.
Untuk menilai prestasi setiap MLLM secara automatik, pengarang menggunakan kaedah ujian tambahan GPT-4 untuk menilai:
 Gambar
Gambar
1. Pengarang mengambil jujukan imej dan perkataan gesaan sebagai input kepada MLLM, dan menjana Perihalan yang sepadan dengan jujukan imej
2 Minta GPT-4 untuk mengekstrak kata kunci objek dan tingkah laku dalam perihalan yang dijana oleh AI
3 Senarai perkataan kunci tingkah laku yang dijana oleh AI;
4 Kira kadar ingatan semula, kadar ketepatan dan indeks F1 senarai kata kunci objek dan senarai kata kunci tingkah laku yang dijana oleh AI dan senarai kata kunci beranotasi manusia.
Pengarang menilai prestasi MLLM dalam penaakulan imej urutan pada Mementos, dan menjalankan penilaian terperinci terhadap sembilan MLLM terkini termasuk GPT4V dan Gemini.
MLLM diminta untuk menerangkan peristiwa yang berlaku dalam jujukan imej untuk menilai keupayaan penaakulan MLLM untuk imej berterusan.
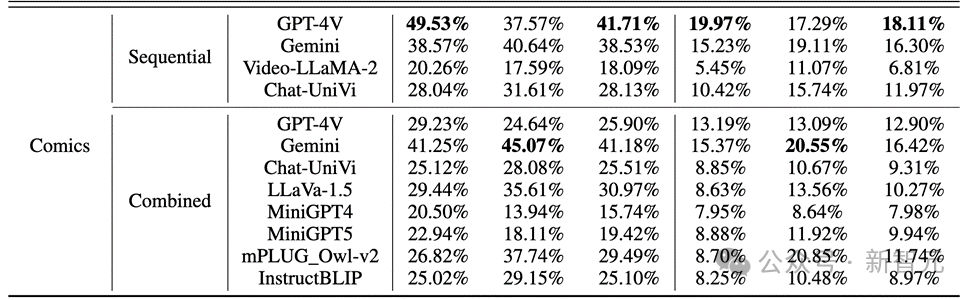
Hasilnya mendapati, seperti yang ditunjukkan dalam rajah di bawah, ketepatan GPT-4V dan Gemini untuk tingkah laku watak dalam set data komik adalah kurang daripada 20%.
 Gambar
Gambar
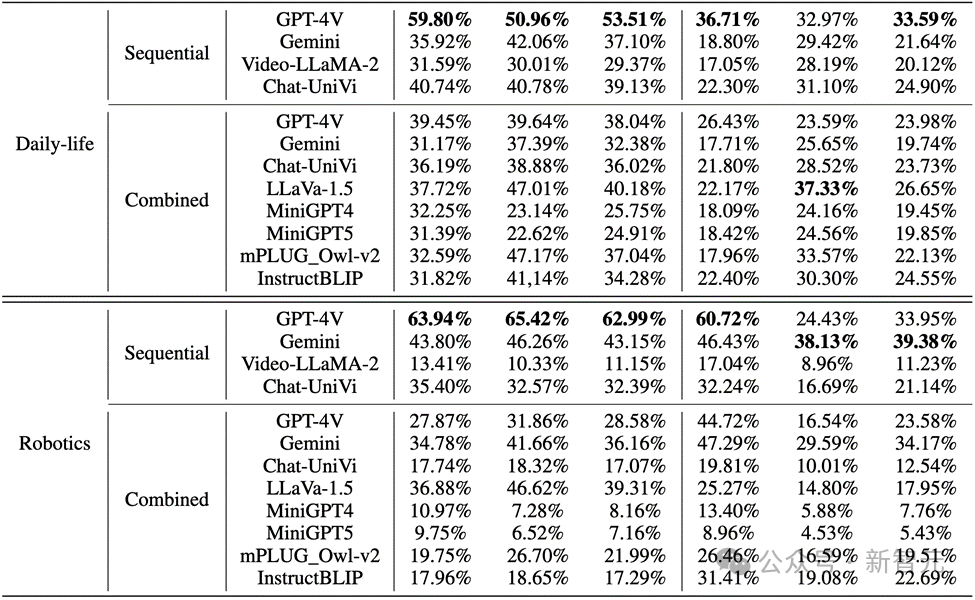
Dalam imej dunia sebenar dan imej robot, prestasi GPT-4V dan Gemini tidak memuaskan:
 Gambar
Gambar
 Gambar
Gambar
Sebagai contoh, selepas mengalami halusinasi objek "gelanggang tenis", MLLM kemudian menunjukkan halusinasi tingkah laku "memegang raket tenis" (kaitan antara halusinasi objek dan halusinasi tingkah laku) dan tingkah laku bersama "nampak bermain tenis" . .
Fenomena ini mendedahkan bahawa MLLM juga boleh menghasilkan ilusi bahawa beberapa tindakan telah berlaku pada objek untuk objek statik dalam jujukan imej. 
Dalam paparan jujukan imej di atas lengan robot, lengan robot mencapai sebelah pemegang, dan MLLM tersilap percaya bahawa lengan robot telah memegang pemegang, akan membuktikan bahawa imej Gabungan tingkah laku biasa dalam penaakulan urutan, dengan itu menghasilkan halusinasi.
 Gambar
Gambar
Dalam kes di atas, tuan lama tidak memimpin anjing itu secara tersilap percaya bahawa berjalan dengan anjing itu memerlukan memimpin anjing itu, dan "anjing lompat tiang" diiktiraf sebagai "Pancuran air. diciptakan."
Jumlah ralat yang besar mencerminkan ketidakbiasaan MLLM dengan bidang komik Dalam bidang animasi dua dimensi, MLLM mungkin memerlukan pengoptimuman dan pra-latihan yang ketara 
3. Kesan kumulatif halusinasi tingkah laku.
Penemuan ini sangat penting untuk memahami dan meningkatkan keupayaan MLLM dalam memproses maklumat visual dinamik. Penanda aras Mementos bukan sahaja mendedahkan batasan MLLM semasa, tetapi juga menyediakan arahan untuk penyelidikan dan penambahbaikan masa hadapan.
Dengan perkembangan pesat teknologi kecerdasan buatan, aplikasi MLLM dalam bidang pemahaman pelbagai modal akan menjadi lebih meluas dan mendalam. Pengenalan penanda aras Mementos bukan sahaja menggalakkan penyelidikan dalam bidang ini, tetapi juga memberikan kita perspektif baharu untuk memahami dan menambah baik cara sistem AI maju ini memproses dan memahami dunia kita yang kompleks dan sentiasa berubah.
Rujukan:
https://github.com/umd-huanglab/Mementos
Atas ialah kandungan terperinci Kadar ketepatan kurang daripada 20%, GPT-4V/Gemini tidak boleh membaca komik! Penanda aras jujukan imej sumber terbuka pertama. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



