
 Peranti teknologi
AI
UCLA Chinese mencadangkan mekanisme bermain sendiri yang baharu! LLM melatih dirinya sendiri, dan kesannya lebih baik daripada bimbingan pakar GPT-4.
Peranti teknologi
AI
UCLA Chinese mencadangkan mekanisme bermain sendiri yang baharu! LLM melatih dirinya sendiri, dan kesannya lebih baik daripada bimbingan pakar GPT-4.
UCLA Chinese mencadangkan mekanisme bermain sendiri yang baharu! LLM melatih dirinya sendiri, dan kesannya lebih baik daripada bimbingan pakar GPT-4.

Data sintetik telah menjadi asas terpenting dalam evolusi model bahasa yang besar.
Pada penghujung tahun lalu, beberapa netizen mendedahkan bahawa bekas ketua saintis OpenAI Ilya berulang kali menyatakan bahawa tiada kesesakan data dalam pembangunan LLM, dan data sintetik boleh menyelesaikan kebanyakan masalah.
 Gambar
Gambar
Selepas mengkaji kumpulan kertas terbaharu, Jim Fan, seorang saintis kanan di Nvidia, membuat kesimpulan bahawa menggabungkan data sintetik dengan permainan tradisional dan teknologi penjanaan imej boleh membolehkan LLM mencapai evolusi diri yang besar.
 Gambar
Gambar
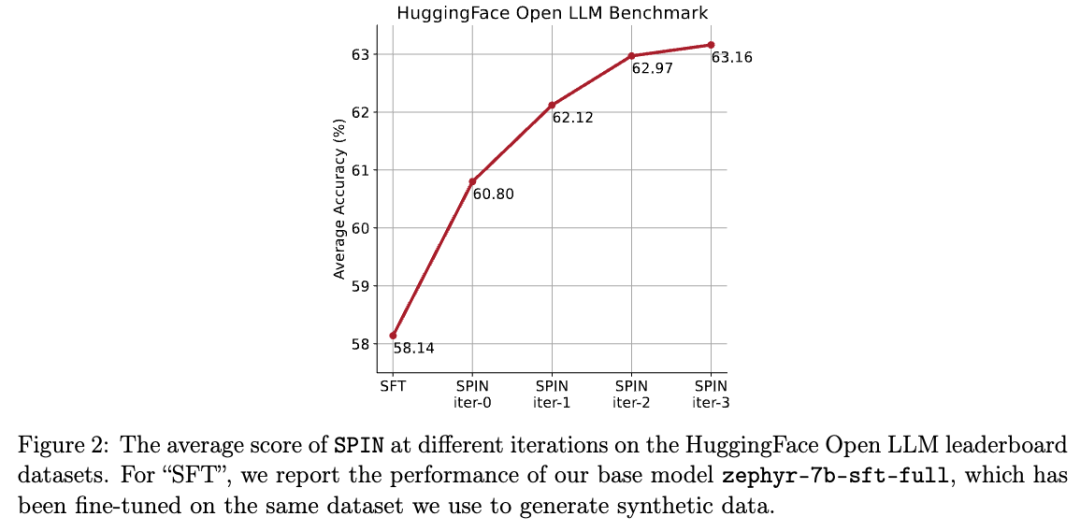
Kertas yang secara rasmi mencadangkan kaedah ini ditulis oleh pasukan Cina dari UCLA. . dan melalui kendiri kaedah penalaan halus, tidak Bergantung pada set data baharu, skor purata LLM yang lebih lemah pada Penanda Aras Papan Pendahulu LLM Terbuka ditingkatkan daripada 58.14 kepada 63.16.

Gambar
Dengan cara ini, evolusi kendiri model boleh diselesaikan tanpa memerlukan data anotasi manusia tambahan atau maklum balas daripada model bahasa peringkat tinggi. 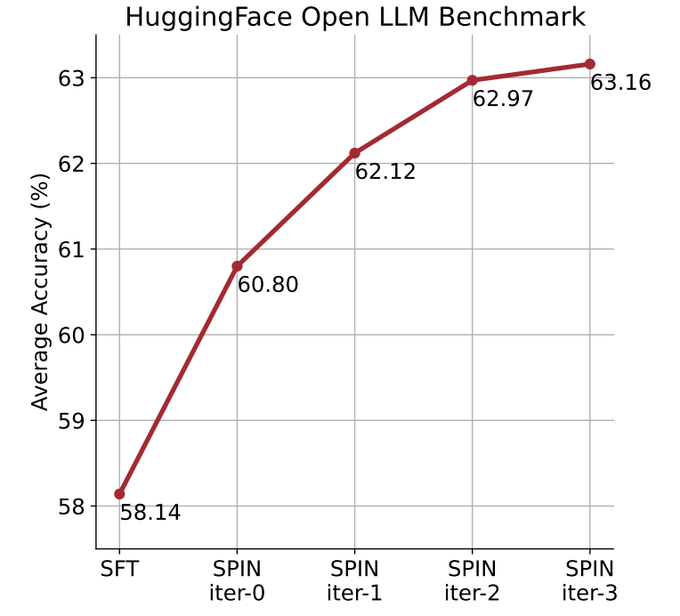
Parameter model utama dan model lawan adalah sama. Bermain menentang diri anda dengan dua versi berbeza.
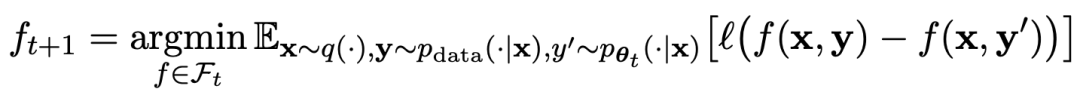 Proses permainan boleh diringkaskan dengan formula:
Proses permainan boleh diringkaskan dengan formula:
Gambar
Kaedah latihan bermain sendiri Secara ringkasnya, ideanya adalah lebih kurang seperti ini:
yang menarik. yang dihasilkan oleh model lawan dengan melatih model utama dan tindak balas sasaran manusia, model lawan ialah model bahasa yang diperoleh secara berulang dalam pusingan, dengan matlamat untuk menghasilkan respons yang tidak dapat dibezakan mungkin.Andaikan bahawa parameter model bahasa yang diperoleh dalam lelaran ke-t ialah θt, kemudian dalam lelaran t+1, gunakan θt sebagai pemain lawan, dan gunakan θt untuk menjana respons y' bagi setiap gesaan x dalam set data penalaan halus diselia.
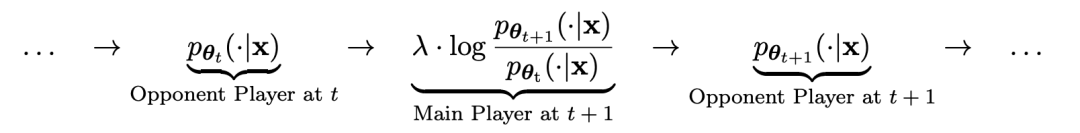 Kemudian optimumkan parameter model bahasa baharu θt+1 supaya ia boleh membezakan y' daripada respons manusia y dalam set data penalaan halus yang diselia. Ini boleh membentuk proses beransur-ansur dan secara beransur-ansur menghampiri pengedaran tindak balas sasaran.
Kemudian optimumkan parameter model bahasa baharu θt+1 supaya ia boleh membezakan y' daripada respons manusia y dalam set data penalaan halus yang diselia. Ini boleh membentuk proses beransur-ansur dan secara beransur-ansur menghampiri pengedaran tindak balas sasaran.
Di sini, fungsi kehilangan model utama menggunakan kehilangan logaritma, dengan mengambil kira perbezaan dalam nilai fungsi antara y dan y'.
Tambah KL divergence regularization kepada model lawan untuk mengelakkan parameter model daripada menyimpang terlalu banyak.
Objektif latihan permainan lawan yang khusus ditunjukkan dalam Formula 4.7. Ia dapat dilihat daripada analisis teori bahawa apabila taburan tindak balas model bahasa adalah sama dengan taburan tindak balas sasaran, proses pengoptimuman menumpu.
Jika anda menggunakan data sintetik yang dijana selepas permainan untuk latihan, dan kemudian menggunakan SPIN untuk penalaan kendiri, prestasi LLM boleh dipertingkatkan dengan berkesan.
Gambar
Tetapi hanya penalaan halus semula pada data penalaan halus awal akan menyebabkan kemerosotan prestasi.
SPIN hanya memerlukan model awal itu sendiri dan set data diperhalusi sedia ada, supaya LLM boleh memperbaiki dirinya melalui SPIN. Khususnya, SPIN malah mengatasi prestasi model yang dilatih dengan data keutamaan GPT-4 tambahan melalui DPO. Dan eksperimen juga menunjukkan bahawa latihan berulang boleh meningkatkan prestasi model dengan lebih berkesan daripada latihan dengan lebih banyak zaman. Memanjangkan tempoh latihan satu lelaran tidak akan mengurangkan prestasi SPIN, tetapi ia akan mencapai hadnya. Semakin banyak lelaran, semakin jelas kesan SPIN. Selepas membaca kertas ini, netizen mengeluh: Data sintetik akan mendominasi pembangunan model bahasa besar, yang akan menjadi berita yang sangat baik untuk penyelidik model bahasa besar! . Matlamat seterusnya adalah untuk mencari LLM baharu yang mampu membezakan antara respons y yang dihasilkan dan respons y' yang dijana oleh manusia. Pemain utama atau LLM baru Dalam lelaran seterusnya, LLM yang baru diperolehi Cara menggunakan SPIN untuk meningkatkan prestasi model Para penyelidik mereka bentuk permainan dua pemain, di mana matlamat model utama adalah untuk membezakan antara respons yang dijana LLM dan respons yang dijana manusia. Pada masa yang sama, peranan musuh adalah untuk menghasilkan tindak balas yang tidak dapat dibezakan daripada manusia. Pusat kepada pendekatan penyelidik ialah melatih model utama. Terangkan dahulu cara melatih model utama untuk membezakan respons LLM daripada respons manusia. Di tengah-tengah pendekatan penyelidik ialah mekanisme permainan sendiri, di mana kedua-dua pemain utama dan lawan adalah LLM yang sama, tetapi daripada lelaran yang berbeza. Secara lebih khusus, lawan ialah LLM lama daripada lelaran sebelumnya, dan pemain utama ialah LLM baharu untuk belajar dalam lelaran semasa. Lelaran t+1 merangkumi dua langkah berikut: (1) melatih model utama, (2) mengemas kini model lawan. Melatih model induk Pertama, penyelidik akan menerangkan cara melatih pemain induk untuk membezakan antara tindak balas LLM dan tindak balas manusia. Diilhamkan oleh ukuran kebarangkalian integral (IPM), para penyelidik merumuskan fungsi objektif: Kemas kini model lawan matlamat untuk mencari LLM yang lebih baik menghasilkan Tindak balas daripada tidak berbeza daripada data p model utama.
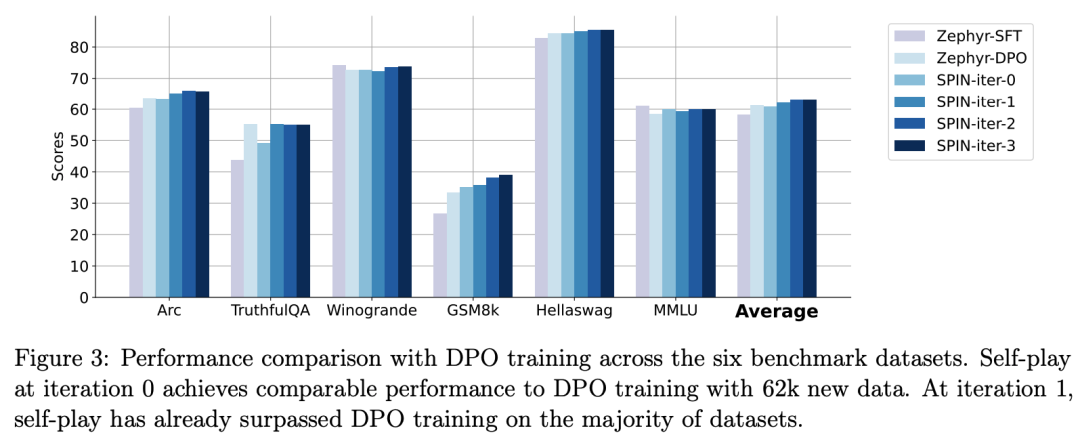
Para penyelidik menggunakan HuggingFace Open LLM Leaderboard sebagai penilaian yang meluas untuk membuktikan keberkesanan SPIN. Dalam rajah di bawah, penyelidik membandingkan prestasi model yang diperhalusi oleh SPIN selepas 0 hingga 3 lelaran dengan model asas zephyr-7b-sft-full. Para penyelidik dapat memerhatikan bahawa SPIN menunjukkan hasil yang ketara dalam meningkatkan prestasi model dengan memanfaatkan lagi set data SFT, di mana model asas telah diperhalusi sepenuhnya. Dalam lelaran 0, tindak balas model dihasilkan daripada zephyr-7b-sft-full, dan penyelidik memerhatikan peningkatan keseluruhan sebanyak 2.66% dalam skor purata. Peningkatan ini amat ketara pada penanda aras TruthfulQA dan GSM8k, dengan peningkatan masing-masing lebih 5% dan 10%. Dalam Lelaran 1, para penyelidik menggunakan model LLM daripada Lelaran 0 untuk menjana respons baharu untuk SPIN, mengikut proses yang digariskan dalam Algoritma 1. Lelaran ini menghasilkan peningkatan lagi sebanyak 1.32% secara purata, yang amat ketara pada Arc Challenge dan tanda aras TruthfulQA. Lelaran seterusnya meneruskan aliran peningkatan tambahan untuk pelbagai tugas. Pada masa yang sama, peningkatan pada lelaran t+1 adalah lebih kecil secara semula jadi terlatih. Para penyelidik mendapati bahawa DPO memerlukan input manusia atau maklum balas model bahasa peringkat tinggi untuk menentukan pilihan, jadi penjanaan data adalah proses yang agak mahal. Selain itu, tidak seperti DPO yang memerlukan sumber data baharu, pendekatan penyelidik memanfaatkan sepenuhnya set data SFT sedia ada. Rajah di bawah menunjukkan perbandingan prestasi SPIN dengan latihan DPO pada lelaran 0 dan 1 (menggunakan data SFT 50k). Para penyelidik dapat memerhatikan bahawa walaupun DPO menggunakan lebih banyak data daripada sumber baharu, SPIN berdasarkan data SFT sedia ada bermula dari lelaran 1. SPIN malah melebihi prestasi DPO dan kedudukan SPIN dalam kedudukan ujian penanda aras malah melebihi DPO. Rujukan: 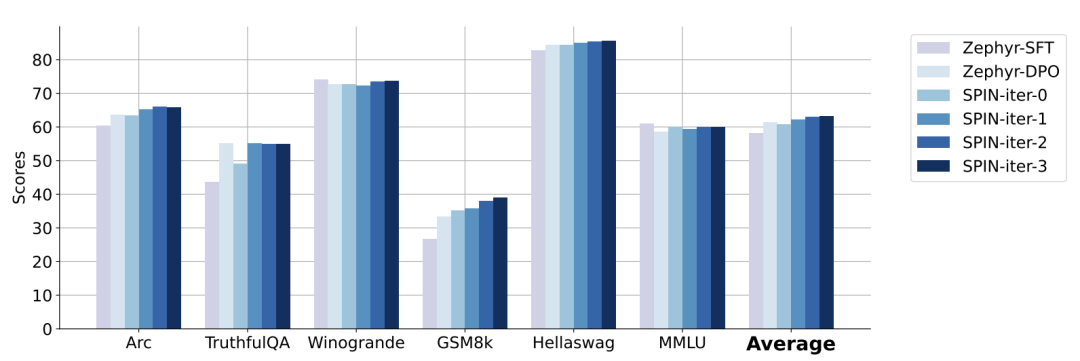 Gambar
Gambar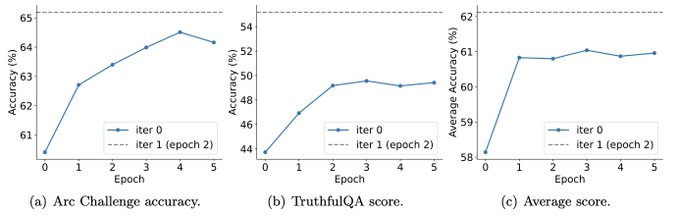 Gambar
Gambar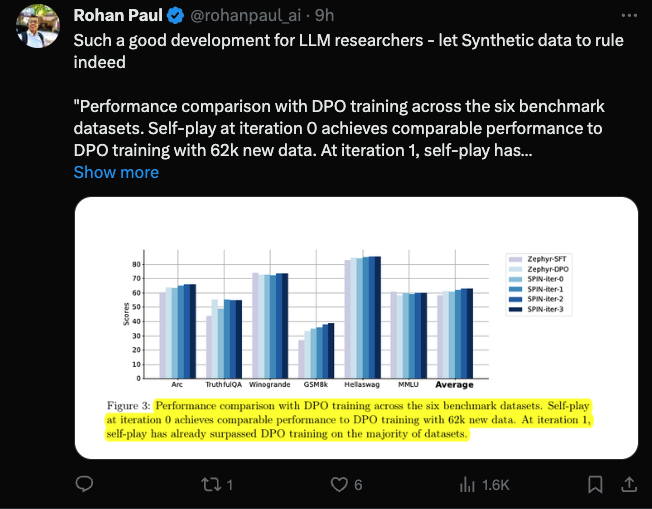 dilambangkan dengan
dilambangkan dengan 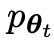 Proses ini boleh dilihat sebagai permainan dua pemain:
Proses ini boleh dilihat sebagai permainan dua pemain: 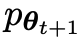 cuba untuk melihat tindak balas pemain lawan dan tindak balas yang dihasilkan oleh manusia, manakala pihak lawan atau LLM
cuba untuk melihat tindak balas pemain lawan dan tindak balas yang dihasilkan oleh manusia, manakala pihak lawan atau LLM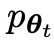 lama menjana Respons adalah sama yang mungkin dengan data dalam set data SFT beranotasi secara manual. .
lama menjana Respons adalah sama yang mungkin dengan data dalam set data SFT beranotasi secara manual. . 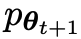 menjadi lawan yang dijana tindak balas, dan matlamat proses bermain sendiri ialah LLM akhirnya menumpu kepada
menjadi lawan yang dijana tindak balas, dan matlamat proses bermain sendiri ialah LLM akhirnya menumpu kepada 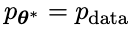 , supaya LLM yang paling kuat tidak lagi mampu untuk membezakan antara versi respons yang dijana sebelum ini dan versi janaan Manusia.
, supaya LLM yang paling kuat tidak lagi mampu untuk membezakan antara versi respons yang dijana sebelum ini dan versi janaan Manusia. 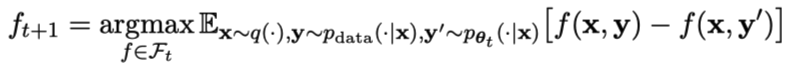 Gambar
Gambar SPIN berkesan meningkatkan prestasi penanda aras
 Gambar
Gambar
Atas ialah kandungan terperinci UCLA Chinese mencadangkan mekanisme bermain sendiri yang baharu! LLM melatih dirinya sendiri, dan kesannya lebih baik daripada bimbingan pakar GPT-4.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Panduan langkah demi langkah untuk menggunakan Groq Llama 3 70B secara tempatan
Jun 10, 2024 am 09:16 AM
Panduan langkah demi langkah untuk menggunakan Groq Llama 3 70B secara tempatan
Jun 10, 2024 am 09:16 AM
Penterjemah |. Tinjauan Bugatti |. Chonglou Artikel ini menerangkan cara menggunakan enjin inferens GroqLPU untuk menjana respons sangat pantas dalam JanAI dan VSCode. Semua orang sedang berusaha membina model bahasa besar (LLM) yang lebih baik, seperti Groq yang memfokuskan pada bahagian infrastruktur AI. Sambutan pantas daripada model besar ini adalah kunci untuk memastikan model besar ini bertindak balas dengan lebih cepat. Tutorial ini akan memperkenalkan enjin parsing GroqLPU dan cara mengaksesnya secara setempat pada komputer riba anda menggunakan API dan JanAI. Artikel ini juga akan menyepadukannya ke dalam VSCode untuk membantu kami menjana kod, kod refactor, memasukkan dokumentasi dan menjana unit ujian. Artikel ini akan mencipta pembantu pengaturcaraan kecerdasan buatan kami sendiri secara percuma. Pengenalan kepada enjin inferens GroqLPU Groq
 Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Bayangkan model kecerdasan buatan yang bukan sahaja mempunyai keupayaan untuk mengatasi pengkomputeran tradisional, tetapi juga mencapai prestasi yang lebih cekap pada kos yang lebih rendah. Ini bukan fiksyen sains, DeepSeek-V2[1], model MoE sumber terbuka paling berkuasa di dunia ada di sini. DeepSeek-V2 ialah gabungan model bahasa pakar (MoE) yang berkuasa dengan ciri-ciri latihan ekonomi dan inferens yang cekap. Ia terdiri daripada 236B parameter, 21B daripadanya digunakan untuk mengaktifkan setiap penanda. Berbanding dengan DeepSeek67B, DeepSeek-V2 mempunyai prestasi yang lebih kukuh, sambil menjimatkan 42.5% kos latihan, mengurangkan cache KV sebanyak 93.3% dan meningkatkan daya pemprosesan penjanaan maksimum kepada 5.76 kali. DeepSeek ialah sebuah syarikat yang meneroka kecerdasan buatan am
 Caltech Cina menggunakan AI untuk menumbangkan bukti matematik! Mempercepatkan 5 kali terkejut Tao Zhexuan, 80% langkah matematik adalah automatik sepenuhnya
Apr 23, 2024 pm 03:01 PM
Caltech Cina menggunakan AI untuk menumbangkan bukti matematik! Mempercepatkan 5 kali terkejut Tao Zhexuan, 80% langkah matematik adalah automatik sepenuhnya
Apr 23, 2024 pm 03:01 PM
LeanCopilot, alat matematik formal yang telah dipuji oleh ramai ahli matematik seperti Terence Tao, telah berkembang semula? Sebentar tadi, profesor Caltech Anima Anandkumar mengumumkan bahawa pasukan itu mengeluarkan versi diperluaskan kertas LeanCopilot dan mengemas kini pangkalan kod. Alamat kertas imej: https://arxiv.org/pdf/2404.12534.pdf Percubaan terkini menunjukkan bahawa alat Copilot ini boleh mengautomasikan lebih daripada 80% langkah pembuktian matematik! Rekod ini adalah 2.3 kali lebih baik daripada aesop garis dasar sebelumnya. Dan, seperti sebelum ini, ia adalah sumber terbuka di bawah lesen MIT. Dalam gambar, dia ialah Song Peiyang, seorang budak Cina
 Daripada 'manusia + RPA' kepada 'manusia + generatif AI + RPA', bagaimanakah LLM mempengaruhi interaksi manusia-komputer RPA?
Jun 05, 2023 pm 12:30 PM
Daripada 'manusia + RPA' kepada 'manusia + generatif AI + RPA', bagaimanakah LLM mempengaruhi interaksi manusia-komputer RPA?
Jun 05, 2023 pm 12:30 PM
Sumber imej@visualchinesewen|Wang Jiwei Daripada "manusia + RPA" kepada "manusia + generatif AI + RPA", bagaimanakah LLM mempengaruhi interaksi manusia-komputer RPA? Dari perspektif lain, bagaimanakah LLM mempengaruhi RPA dari perspektif interaksi manusia-komputer? RPA, yang menjejaskan interaksi manusia-komputer dalam pembangunan program dan automasi proses, kini akan turut diubah oleh LLM? Bagaimanakah LLM mempengaruhi interaksi manusia-komputer? Bagaimanakah AI generatif mengubah interaksi manusia-komputer RPA? Ketahui lebih lanjut mengenainya dalam satu artikel: Era model besar akan datang, dan AI generatif berdasarkan LLM sedang mengubah interaksi manusia-komputer RPA dengan pantas mentakrifkan semula interaksi manusia-komputer, dan LLM mempengaruhi perubahan dalam seni bina perisian RPA. Jika anda bertanya apakah sumbangan RPA kepada pembangunan program dan automasi, salah satu jawapannya ialah ia telah mengubah interaksi manusia-komputer (HCI, h
 Plaud melancarkan perakam boleh pakai NotePin AI untuk $169
Aug 29, 2024 pm 02:37 PM
Plaud melancarkan perakam boleh pakai NotePin AI untuk $169
Aug 29, 2024 pm 02:37 PM
Plaud, syarikat di belakang Perakam Suara AI Plaud Note (tersedia di Amazon dengan harga $159), telah mengumumkan produk baharu. Digelar NotePin, peranti ini digambarkan sebagai kapsul memori AI, dan seperti Pin AI Humane, ini boleh dipakai. NotePin ialah
 Tujuh Soalan Temuduga Teknikal GenAI & LLM yang Cool
Jun 07, 2024 am 10:06 AM
Tujuh Soalan Temuduga Teknikal GenAI & LLM yang Cool
Jun 07, 2024 am 10:06 AM
Untuk mengetahui lebih lanjut tentang AIGC, sila layari: 51CTOAI.x Komuniti https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou berbeza daripada bank soalan tradisional yang boleh dilihat di mana-mana sahaja di Internet memerlukan pemikiran di luar kotak. Model Bahasa Besar (LLM) semakin penting dalam bidang sains data, kecerdasan buatan generatif (GenAI) dan kecerdasan buatan. Algoritma kompleks ini meningkatkan kemahiran manusia dan memacu kecekapan dan inovasi dalam banyak industri, menjadi kunci kepada syarikat untuk kekal berdaya saing. LLM mempunyai pelbagai aplikasi Ia boleh digunakan dalam bidang seperti pemprosesan bahasa semula jadi, penjanaan teks, pengecaman pertuturan dan sistem pengesyoran. Dengan belajar daripada sejumlah besar data, LLM dapat menjana teks
 Ameca generasi kedua ada di sini! Dia boleh berkomunikasi dengan penonton dengan lancar, ekspresi mukanya lebih realistik, dan dia boleh bercakap berpuluh-puluh bahasa.
Mar 04, 2024 am 09:10 AM
Ameca generasi kedua ada di sini! Dia boleh berkomunikasi dengan penonton dengan lancar, ekspresi mukanya lebih realistik, dan dia boleh bercakap berpuluh-puluh bahasa.
Mar 04, 2024 am 09:10 AM
Robot humanoid Ameca telah dinaik taraf kepada generasi kedua! Baru-baru ini, di Persidangan Komunikasi Mudah Alih Sedunia MWC2024, robot Ameca paling canggih di dunia muncul semula. Di sekitar venue, Ameca menarik sejumlah besar penonton. Dengan restu GPT-4, Ameca boleh bertindak balas terhadap pelbagai masalah dalam masa nyata. "Jom kita menari." Apabila ditanya sama ada dia mempunyai emosi, Ameca menjawab dengan beberapa siri mimik muka yang kelihatan sangat hidup. Hanya beberapa hari yang lalu, EngineeredArts, syarikat robotik British di belakang Ameca, baru sahaja menunjukkan hasil pembangunan terkini pasukan itu. Dalam video tersebut, robot Ameca mempunyai keupayaan visual dan boleh melihat serta menerangkan keseluruhan bilik dan objek tertentu. Perkara yang paling menakjubkan ialah dia juga boleh
 GraphRAG dipertingkatkan untuk mendapatkan semula graf pengetahuan (dilaksanakan berdasarkan kod Neo4j)
Jun 12, 2024 am 10:32 AM
GraphRAG dipertingkatkan untuk mendapatkan semula graf pengetahuan (dilaksanakan berdasarkan kod Neo4j)
Jun 12, 2024 am 10:32 AM
Penjanaan Dipertingkatkan Pengambilan Graf (GraphRAG) secara beransur-ansur menjadi popular dan telah menjadi pelengkap hebat kepada kaedah carian vektor tradisional. Kaedah ini mengambil kesempatan daripada ciri-ciri struktur pangkalan data graf untuk menyusun data dalam bentuk nod dan perhubungan, dengan itu mempertingkatkan kedalaman dan perkaitan kontekstual bagi maklumat yang diambil. Graf mempunyai kelebihan semula jadi dalam mewakili dan menyimpan maklumat yang pelbagai dan saling berkaitan, dan dengan mudah boleh menangkap hubungan dan sifat yang kompleks antara jenis data yang berbeza. Pangkalan data vektor tidak dapat mengendalikan jenis maklumat berstruktur ini dan ia lebih menumpukan pada pemprosesan data tidak berstruktur yang diwakili oleh vektor berdimensi tinggi. Dalam aplikasi RAG, menggabungkan data graf berstruktur dan carian vektor teks tidak berstruktur membolehkan kami menikmati kelebihan kedua-duanya pada masa yang sama, iaitu perkara yang akan dibincangkan oleh artikel ini. struktur
