

Pohon kemahiran Transformer semakin berkuasa.
Penyelidik dari Universiti Massachusetts, Google, dan Universiti Illinois di Urbana-Champaign (UIUC) baru-baru ini menerbitkan kertas kerja di mana mereka berjaya mencapai matlamat untuk menjana bukti teorem lengkap secara automatik dengan menggunakan model bahasa yang besar.

Alamat kertas: https://arxiv.org/pdf/2303.04910.pdf
Karya ini dinamakan sempena Baldur (abang Thor dalam mitologi Norse), dan ini adalah kali pertama Transformer boleh menjana bukti penuh, juga menunjukkan bahawa bukti model sebelumnya boleh, ditambah baik apabila menyediakan model dengan konteks tambahan.
Kertas kerja ini diterbitkan di ESEC/FSE (ACM European Joint Conference on Software Engineering and Symposium on Fundamentals of Software Engineering) pada Disember 2023, dan memenangi Anugerah Kertas Cemerlang.
Seperti yang kita semua tahu, pepijat tidak dapat dielakkan dalam perisian, yang mungkin tidak menyebabkan terlalu banyak masalah untuk aplikasi atau tapak web umum. Walau bagaimanapun, untuk perisian di sebalik sistem kritikal, seperti protokol penyulitan, peranti perubatan dan pengangkutan angkasa, kami mesti memastikan tiada pepijat.
- Semakan dan ujian kod am tidak dapat memberikan jaminan ini, yang memerlukan pengesahan rasmi.
Untuk pengesahan rasmi, penjelasan yang diberikan oleh ScienceDirect ialah:
proses menyemak secara matematik bahawa kelakuan sesuatu sistem, yang diterangkan menggunakan model formal, memenuhi sifat tertentu, juga diterangkan menggunakan model formal
merujuk kepada proses menyemak secara matematik sama ada tingkah laku sistem yang diterangkan menggunakan model formal memenuhi sifat yang diberikan.
Secara ringkasnya, ia menggunakan kaedah analisis matematik untuk membina model melalui enjin algoritma untuk menjalankan analisis menyeluruh dan pengesahan ruang keadaan reka bentuk yang akan diuji.
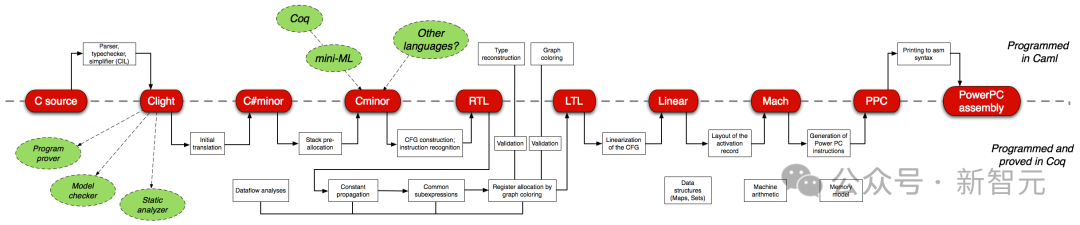
Pengesahan perisian rasmi ialah salah satu tugas yang paling mencabar untuk jurutera perisian. Sebagai contoh, CompCert, pengkompil C yang disahkan dengan pembukti teorem interaktif Coq, adalah satu-satunya pengkompil yang digunakan oleh GCC dan LLVM di mana-mana, antara lain.
Walau bagaimanapun, kos pengesahan rasmi manual (bukti penulisan) agak besar - bukti pengkompil C adalah lebih daripada tiga kali ganda kod pengkompil itu sendiri.
Jadi, pengesahan rasmi itu sendiri adalah tugas "intensif buruh", dan penyelidik juga meneroka kaedah automatik.
Pembantu bukti seperti Coq dan Isabelle melatih model untuk meramal satu langkah bukti pada satu masa dan menggunakan model untuk mencari ruang bukti yang mungkin.
Dan Baldur dalam artikel ini telah memperkenalkan keupayaan model bahasa yang besar dalam bidang ini buat kali pertama, latihan tentang teks dan kod bahasa semula jadi, dan memperhalusi bukti
Baldur boleh menghasilkan bukti yang lengkap daripada teorem sekali gus, Daripada mengambilnya satu langkah pada satu masa.
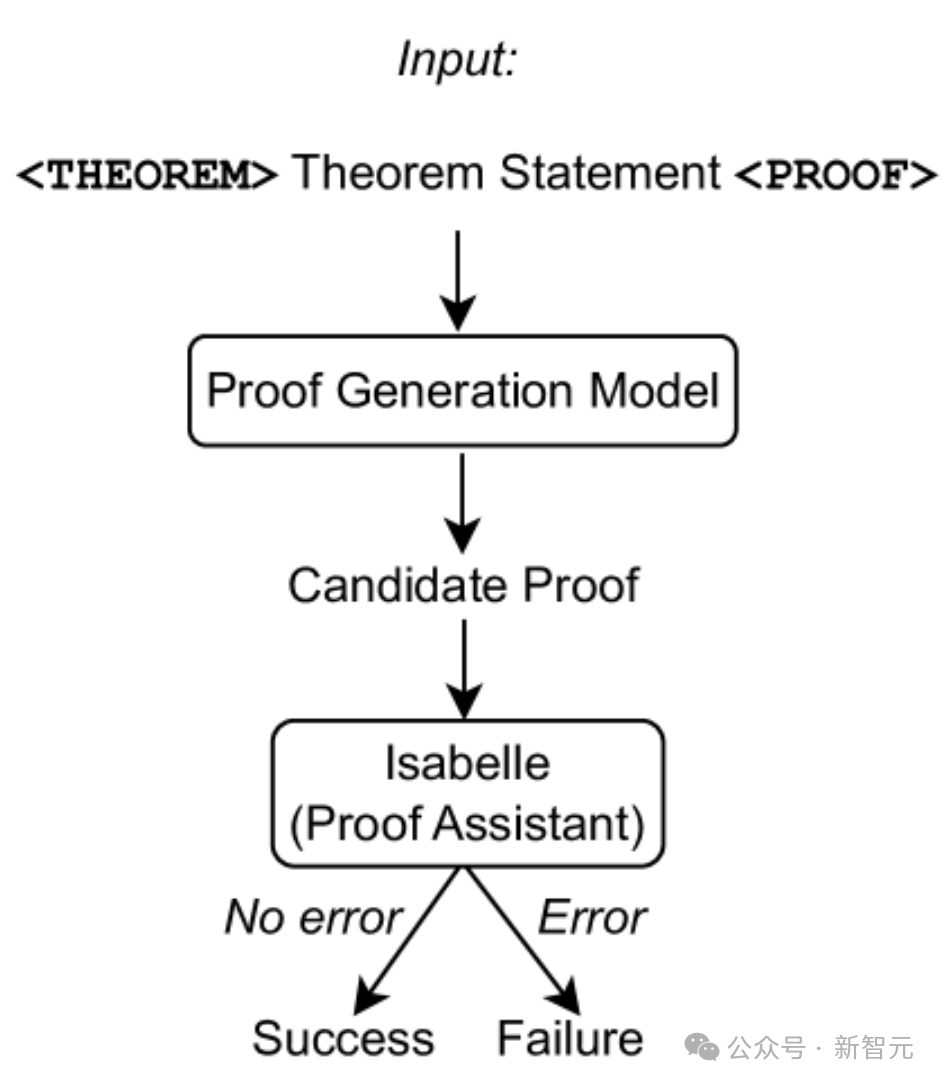
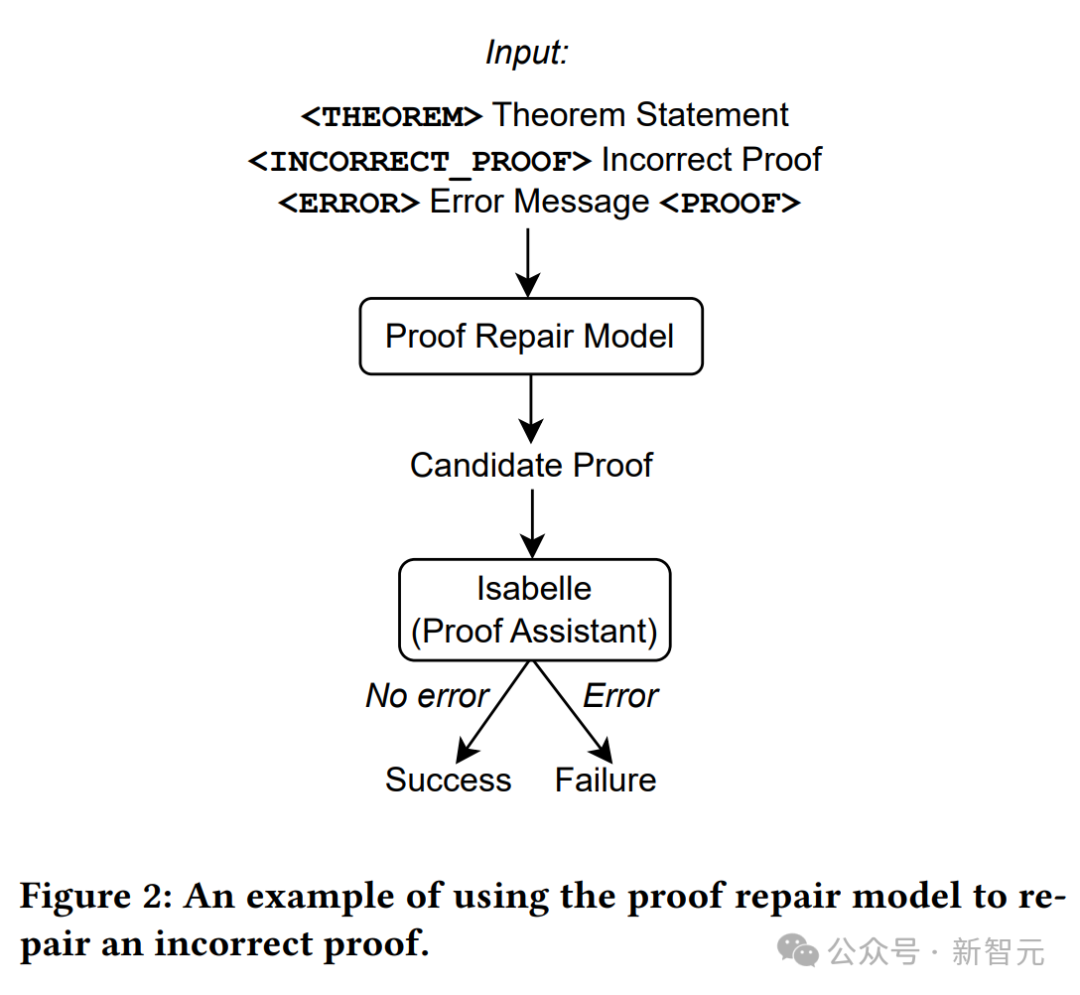
Seperti yang ditunjukkan dalam rajah di atas, hanya pernyataan teorem digunakan sebagai input kepada model penjanaan bukti, kemudian percubaan bukti diekstrak daripada model, dan Isabelle digunakan untuk melakukan semakan bukti.
Jika Isabelle menerima percubaan pembuktian tanpa kesilapan, pembuktian itu berjaya jika tidak, percubaan pembuktian lain diekstrak daripada model penjanaan bukti.
Baldur dinilai berdasarkan penanda aras 6336 teorem Isabelle/HOL dan buktinya, secara empirik menunjukkan keberkesanan penjanaan bukti lengkap, pembaikan dan penambahan konteks.
Selain itu, sebab mengapa alat ini dipanggil Baldur mungkin kerana alat penjanaan bukti automatik terbaik pada masa ini dipanggil Thor.
Thor mempunyai kadar pembuktian yang lebih tinggi (57%) Ia menggunakan model bahasa yang lebih kecil digabungkan dengan kaedah mencari ruang bukti yang mungkin untuk meramalkan langkah pembuktian yang seterusnya, manakala kelebihan Baldur adalah keupayaannya untuk menjana pembuktian yang lengkap.

Tetapi dua beradik Thor dan Baldur juga boleh bekerjasama, yang mungkin meningkatkan kadar bukti hampir 66%.
Baldur dikuasakan oleh Minerva, model bahasa besar Google, yang dilatih pada kertas saintifik dan halaman web yang mengandungi ungkapan matematik dan diperhalusi pada data tentang bukti dan teorem.
Baldur boleh bekerja dengan pembantu pembuktian teorem Isabelle, yang menyemak keputusan pembuktian. Apabila diberi pernyataan teorem, Baldur dapat menghasilkan bukti lengkap hampir 41% pada masa itu.
Untuk meningkatkan lagi prestasi Baldur, penyelidik memberikan maklumat kontekstual tambahan kepada model (seperti definisi lain, atau pernyataan teorem dalam dokumen teori), yang meningkatkan kadar pembuktian kepada 47.5%.
Ini bermakna Baldur dapat mengambil konteks dan menggunakannya untuk meramalkan bukti baharu yang betul - serupa dengan pengaturcara yang lebih cenderung untuk membetulkan pepijat dalam program mereka apabila mereka memahami kaedah dan kod yang berkaitan.
Berikut ialah contoh (teorem fun_sum_commute):

Teorem ini berasal daripada projek yang dipanggil Polinomial dalam Arkib Bukti Formal.
Apabila menulis bukti secara manual, dua kes dibezakan: set adalah terhingga atau tidak terhingga:

Jadi, untuk model, input adalah pernyataan teorem, dan output sasaran adalah Manusia ini -bukti bertulis.
Baldur mengiktiraf keperluan untuk induksi di sini dan menggunakan peraturan aruhan khas yang dipanggil infinite_finite_induct, yang mengikut pendekatan umum yang sama seperti bukti bertulis manusia, tetapi lebih ringkas.
Dan kerana aruhan diperlukan, Sledgehammer yang digunakan oleh Isabelle tidak dapat membuktikan teorem ini secara lalai.
Untuk melatih model penjanaan bukti, para penyelidik membina set data generasi bukti baharu.
Dataset sedia ada mengandungi contoh langkah pembuktian tunggal, dan setiap contoh latihan termasuk keadaan pembuktian (input) dan langkah pembuktian seterusnya untuk digunakan (matlamat).
Memandangkan set data yang mengandungi satu langkah pembuktian, di sini anda perlu mencipta set data baharu untuk melatih model meramalkan keseluruhan bukti sekaligus.
Para penyelidik mengekstrak langkah pembuktian setiap teorem daripada set data dan menggabungkannya untuk membina semula bukti asal. .

Untuk mendapatkan contoh latihan pembaikan bukti daripada rentetan ini, di sini pernyataan teorem, percubaan bukti gagal dan mesej ralat digabungkan sebagai input, dan bukti tulisan manusia yang betul digunakan sebagai sasaran.
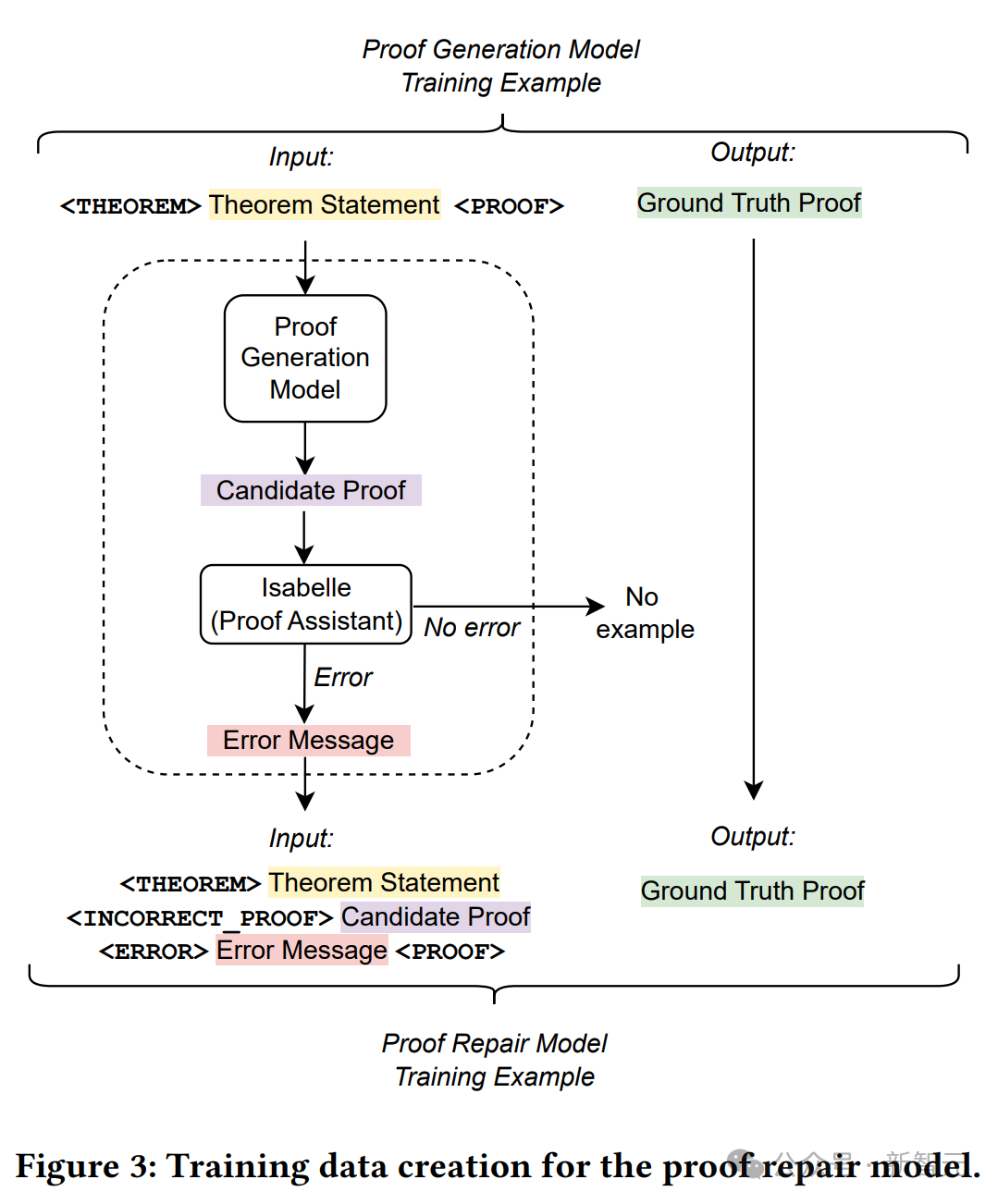
Rajah di atas memperincikan proses penciptaan data latihan.
Gunakan model penjanaan bukti untuk sampel bukti dengan suhu 0 untuk setiap soalan dalam set latihan asal.
Gunakan Pembantu Pembetulan untuk merekodkan semua bukti yang gagal dan mesej ralatnya, kemudian teruskan untuk membina set latihan pembetulan bukti baharu.
Untuk setiap contoh latihan asal, gabungkan pernyataan teorem, bukti calon (salah) yang dijana oleh model penjanaan bukti dan mesej ralat yang sepadan untuk mendapatkan urutan input contoh latihan baharu.
Tambah baris daripada fail teori sebelum pernyataan teorem sebagai konteks tambahan. Sebagai contoh, gambar di bawah kelihatan seperti ini: Model penjanaan bukti dengan konteks dalam Baldur boleh menggunakan maklumat tambahan ini. Rentetan yang muncul dalam pernyataan teorem fun_sum_commute muncul semula dalam konteks ini, jadi maklumat tambahan di sekelilingnya boleh membantu model membuat ramalan yang lebih baik.
 Konteks boleh menjadi pernyataan (teorem, definisi, bukti) atau anotasi bahasa semula jadi.
Konteks boleh menjadi pernyataan (teorem, definisi, bukti) atau anotasi bahasa semula jadi.
Untuk mengeksploitasi panjang input LLM yang tersedia, para penyelidik mula-mula menambah sehingga 50 pernyataan daripada fail teori yang sama.
Semasa latihan, semua penyataan ini mula-mula ditandakan dan kemudian bahagian kiri urutan dipenggal agar sesuai dengan panjang input.
Angka di atas menunjukkan hubungan antara kadar kejayaan bukti dan bilangan percubaan bukti untuk model generatif tanpa konteks dan tanpa konteks. Kita dapat melihat bahawa model generatif bukti dengan konteks secara konsisten mengatasi model generatif biasa.
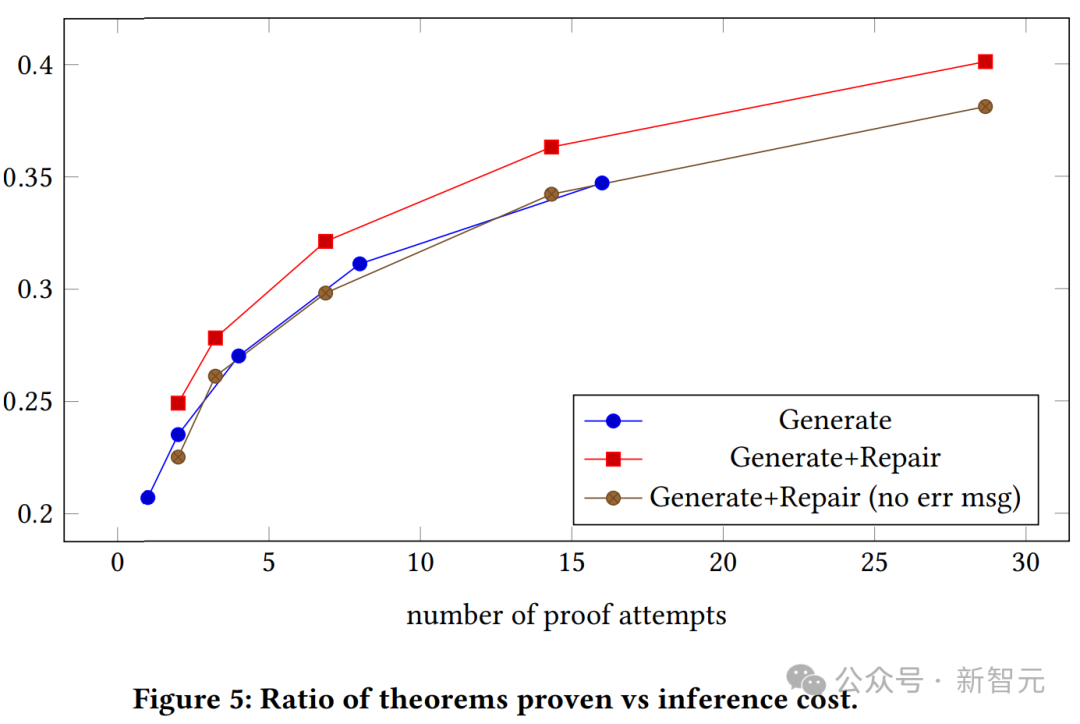
Graf di atas menunjukkan nisbah teorem yang disahkan kepada kos inferens untuk model yang berbeza saiz dan suhu.
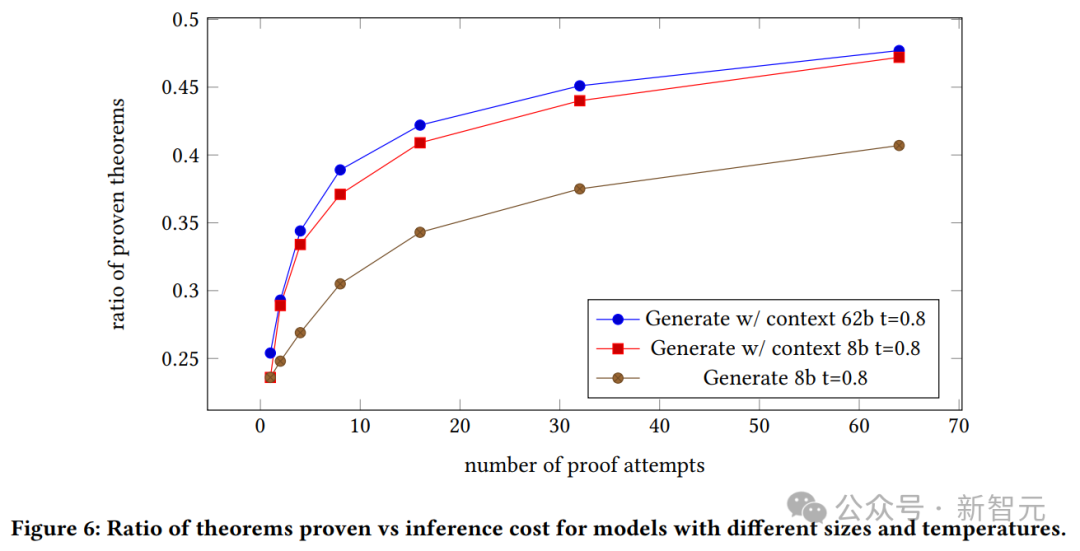 Kita dapat melihat kadar kejayaan bukti model yang dijana, dan hubungan antara konteks model 8B dan model 62B dan bilangan percubaan bukti.
Kita dapat melihat kadar kejayaan bukti model yang dijana, dan hubungan antara konteks model 8B dan model 62B dan bilangan percubaan bukti.
Model 62B dengan konteks membuktikan bahawa model generatif mengatasi model 8B dengan konteks.
Walau bagaimanapun, penulis menekankan di sini bahawa disebabkan kos eksperimen ini yang tinggi dan ketidakupayaan mereka untuk melaraskan hiperparameter, model 62B mungkin berprestasi lebih baik jika ia dioptimumkan.
Atas ialah kandungan terperinci Terence Tao memanggilnya pakar selepas melihatnya! Google dan yang lain menggunakan LLM untuk membuktikan teorem secara automatik dan memenangi kertas persidangan terunggul Semakin lengkap konteksnya, semakin baik buktinya.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



