

Bolehkah terdapat model graf universal——
yang boleh meramalkan ketoksikan berdasarkan struktur molekul dan mengesyorkan rakan di rangkaian sosial?
Atau bolehkah anda bukan sahaja meramalkan petikan kertas pengarang yang berbeza, tetapi juga menemui mekanisme penuaan manusia dalam rangkaian gen?
Jangan beritahu saya, rangka kerja "One for All(OFA)" yang diterima sebagai Spotlight oleh ICLR 2024 telah merealisasikan "intipati" ini.
Penyelidikan ini dicadangkan bersama oleh penyelidik seperti pasukan Profesor Chen Yixin di Universiti Washington di St. Louis, Zhang Muhan dari Universiti Peking, dan Tao Dacheng dari Institut Penyelidikan JD.
Sebagai rangka kerja umum pertama dalam medan graf, OFA membolehkan melatih model GNN tunggal untuk menyelesaikan tugas pengelasan mana-mana set data, sebarang jenis tugas dan mana-mana adegan dalam medan graf.

Cara melaksanakannya secara khusus, berikut adalah sumbangan penulis.
Mereka bentuk model asas universal untuk menyelesaikan pelbagai tugas ialah matlamat jangka panjang dalam bidang kecerdasan buatan. Dalam beberapa tahun kebelakangan ini, model bahasa besar asas (LLM) telah menunjukkan prestasi yang baik dalam memproses tugasan bahasa semula jadi.
Walau bagaimanapun, dalam bidang graf, walaupun rangkaian saraf graf (GNN) mempunyai prestasi yang baik dalam data graf yang berbeza, cara mereka bentuk dan melatih model graf asas yang boleh mengendalikan pelbagai tugas graf pada masa yang sama masih merupakan cara ke hadapan luas.
Berbanding dengan medan bahasa semula jadi, reka bentuk model umum dalam medan graf menghadapi banyak kesukaran unik.
Pertama sekali, berbeza daripada bahasa semula jadi, data graf berbeza mempunyai atribut dan taburan yang berbeza sama sekali.
Sebagai contoh, gambar rajah molekul menerangkan cara berbilang atom membentuk bahan kimia yang berbeza melalui perhubungan daya yang berbeza. Gambar rajah hubungan petikan menerangkan rangkaian petikan bersama antara artikel.
Data graf yang berbeza ini sukar untuk disatukan di bawah rangka kerja latihan.
Kedua, tidak seperti semua tugas dalam LLM, yang boleh ditukar menjadi tugas penjanaan konteks bersatu, tugas graf merangkumi pelbagai subtugas, seperti tugas nod, tugas pautan, tugas graf penuh, dsb.
Subtugas yang berbeza biasanya memerlukan perwakilan tugas yang berbeza dan model graf yang berbeza.
Akhirnya, kejayaan model bahasa yang besar tidak dapat dipisahkan daripada pembelajaran konteks (pembelajaran dalam konteks) dicapai melalui paradigma segera.
Dalam model bahasa yang besar, paradigma segera biasanya merupakan perihalan teks yang boleh dibaca bagi tugas hiliran.
Tetapi bagi data graf yang tidak tersusun dan sukar untuk dihuraikan dengan perkataan, cara mereka bentuk paradigma gesaan graf yang berkesan untuk mencapai pembelajaran dalam konteks masih menjadi misteri yang tidak dapat diselesaikan.
Rajah berikut memberikan rangka kerja keseluruhan OFA:
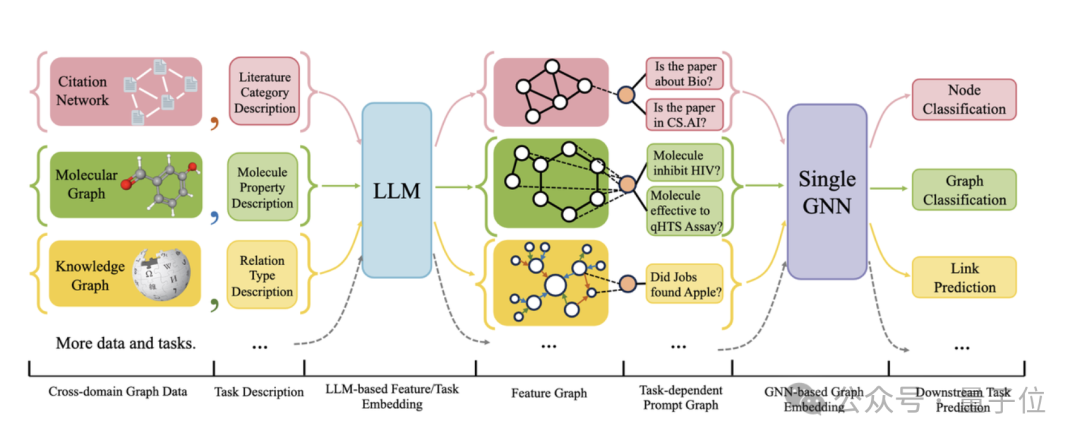
Secara khusus, pasukan OFA menyelesaikan tiga masalah utama yang dinyatakan di atas melalui reka bentuk yang bijak .
Untuk masalah atribut dan taburan data graf yang berbeza, OFA menyatukan semua data graf dengan mencadangkan konsep Graf Beratribut Teks (TAG) . Menggunakan graf teks, OFA menerangkan maklumat nod dan maklumat tepi dalam semua data graf menggunakan rangka kerja bahasa semula jadi bersatu, seperti yang ditunjukkan dalam rajah di bawah:


(NOI) subgraf dan nod gesaan NOI (Nod Prompt NOI) untuk menyatukan jenis subtugas yang berbeza dalam medan graf. Di sini NOI mewakili satu set nod sasaran yang mengambil bahagian dalam tugasan yang sepadan.
Sebagai contoh, dalam tugas ramalan nod, NOI merujuk kepada satu nod yang perlu diramalkan manakala dalam tugas pautan, NOI termasuk dua nod yang perlu meramalkan pautan. Subgraf NOI merujuk kepada subgraf yang mengandungi kejiranan h-hop yang dilanjutkan di sekitar nod NOI ini.
Kemudian, nod gesaan NOI ialah jenis nod yang baru diperkenalkan, disambungkan terus kepada semua NOI.
Yang penting ialah setiap nod gesaan NOI mengandungi maklumat perihalan tugas semasa Maklumat ini wujud dalam bentuk bahasa semula jadi dan diwakili oleh LLM yang sama seperti graf teks.
Memandangkan maklumat yang terkandung dalam nod dalam NOI akan dikumpulkan oleh nod gesaan NOI selepas menghantar mesej GNN, model GNN hanya perlu membuat ramalan melalui nod gesaan NOI.
Dengan cara ini, semua jenis tugas yang berbeza akan mempunyai perwakilan tugas yang bersatu. Contoh khusus ditunjukkan dalam rajah di bawah:
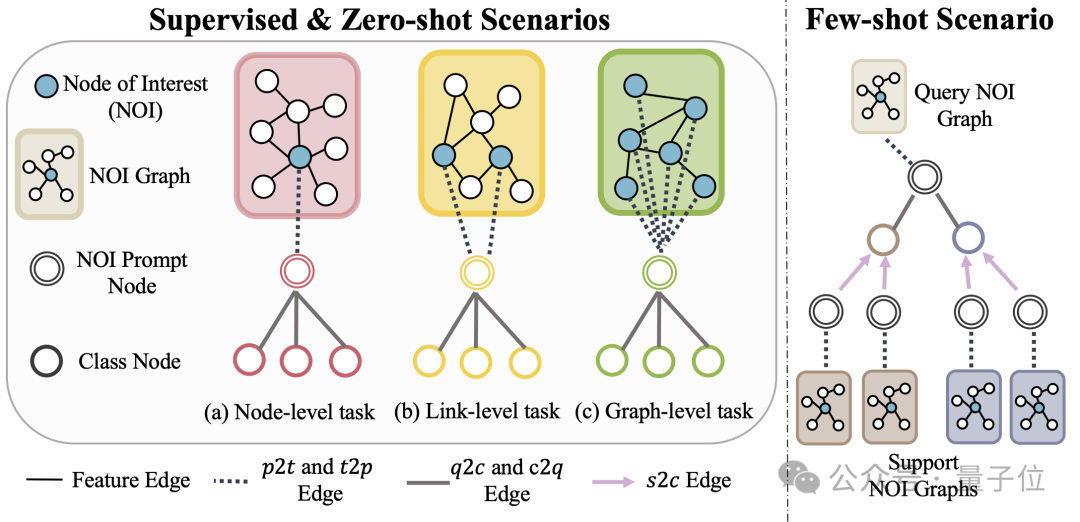
Akhir sekali, untuk merealisasikan pembelajaran dalam konteks dalam medan graf, OFA memperkenalkan subgraf gesaan bersatu.
Dalam senario tugas klasifikasi k-way yang diselia, subgraf gesaan ini mengandungi dua jenis nod: satu ialah nod gesaan NOI yang dinyatakan di atas dan satu lagi ialah nod kategori yang mewakili k kategori berbeza (Nod Kelas).
Teks setiap nod kategori akan menerangkan maklumat berkaitan kategori ini.
Nod gesaan NOI akan disambungkan kepada semua nod kategori dalam satu arah. Graf yang dibina dengan cara ini akan dimasukkan ke dalam model rangkaian saraf graf untuk penghantaran dan pembelajaran mesej.
Akhir sekali, OFA akan melaksanakan tugas pengelasan binari pada setiap nod kategori, dan mengambil nod kategori dengan kebarangkalian tertinggi sebagai hasil ramalan akhir.
Memandangkan maklumat kategori wujud dalam subgraf kiu, walaupun masalah pengelasan yang benar-benar baharu dihadapi, OFA boleh terus meramal tanpa sebarang penalaan halus dengan membina subgraf kiu yang sepadan, sekali gus mencapai pembelajaran sifar pukulan.
Untuk senario pembelajaran beberapa pukulan, tugas klasifikasi akan merangkumi graf input pertanyaan dan graf input sokongan berbilang paradigma graf gesaan OFA akan menyambungkan nod gesaan NOI bagi setiap graf input sokongan kepada nod kategori yang sepadan, dan pada masa yang sama. Nod gesaan NOI bagi graf input pertanyaan disambungkan kepada semua nod kategori.
Langkah ramalan seterusnya adalah konsisten dengan perkara di atas. Dengan cara ini, setiap nod kategori akan menerima maklumat tambahan daripada graf input sokongan, dengan itu mencapai pembelajaran beberapa pukulan di bawah paradigma bersatu.
Sumbangan utama OFA diringkaskan seperti berikut:
Pengagihan data graf bersatu: Dengan mencadangkan graf teks dan menggunakan LLM untuk mengubah maklumat teks, OFA mencapai penjajaran pengedaran dan penyatuan data graf.
Borang tugasan graf seragam: Melalui subgraf NOI dan nod gesaan NOI, OFA mencapai perwakilan bersatu subtugas dalam pelbagai medan graf.
Paradigma pendorong graf bersatu: Dengan mencadangkan paradigma pendorong graf baharu, OFA merealisasikan pembelajaran dalam konteks berbilang senario dalam medan graf.
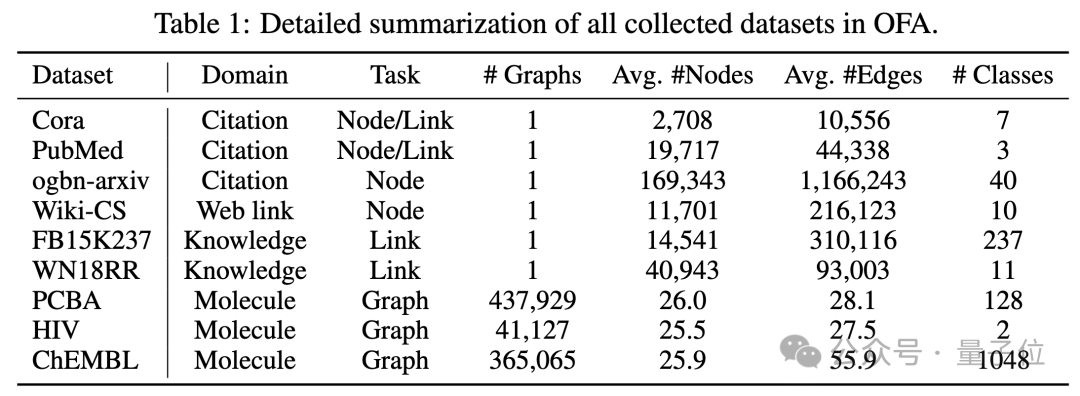
Artikel menguji rangka kerja OFA pada 9 set data yang dikumpul Ujian ini merangkumi sepuluh tugas yang berbeza dalam senario pembelajaran yang diselia, termasuk ramalan nod, ramalan pautan dan klasifikasi Rajah.
Tujuan percubaan adalah untuk mengesahkan keupayaan model OFA tunggal untuk mengendalikan berbilang tugas, di mana pengarang membandingkan penggunaan LLM yang berbeza (OFA-{LLM}) dan latihan model berasingan untuk setiap tugasan (OFA-ind-{LLM}) kesan.
Hasil perbandingan ditunjukkan dalam jadual berikut:
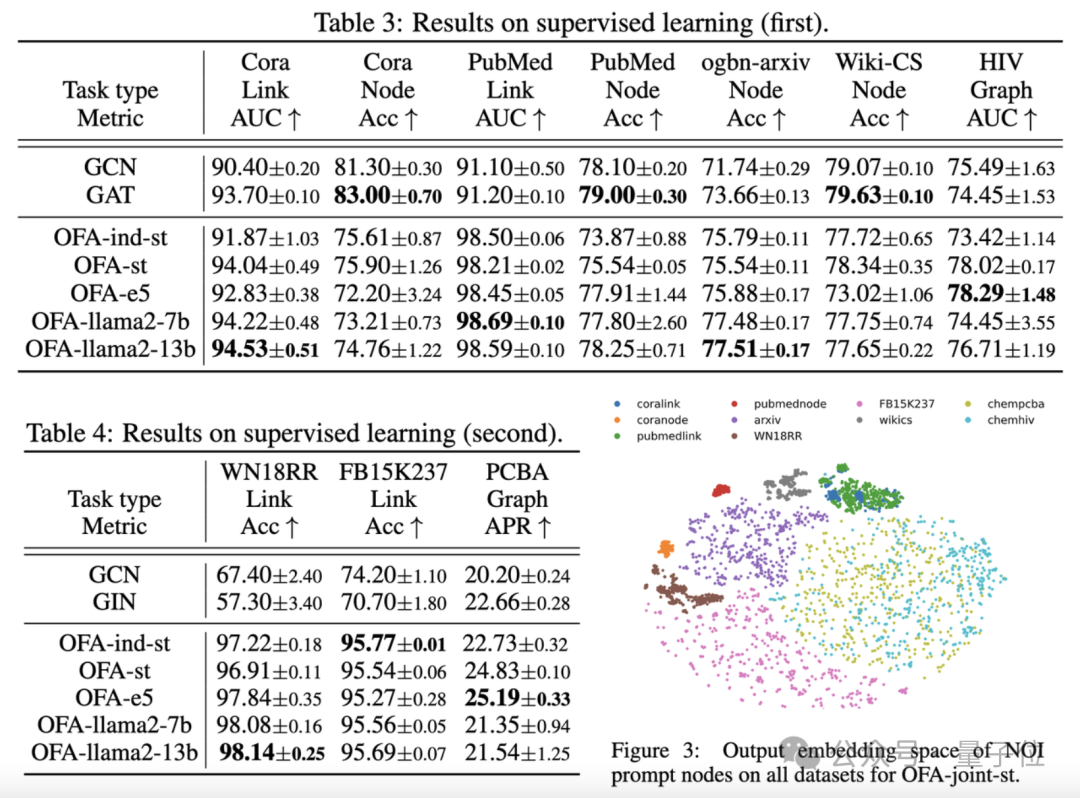
Dapat dilihat bahawa berdasarkan keupayaan generalisasi berkuasa OFA, model graf berasingan (OFA-st, OFA-e5, OFA-llama2-7b, OFA -llama2 -13b)Iaitu, ia boleh mempunyai prestasi yang serupa atau lebih baik daripada model latihan berasingan tradisional(GCN, GAT, OFA-ind-st) pada semua tugas.
Pada masa yang sama, menggunakan LLM yang lebih berkuasa boleh membawa peningkatan prestasi tertentu. Artikel ini selanjutnya memplot perwakilan nod gesaan NOI untuk tugasan yang berbeza oleh model OFA terlatih.
Anda dapat melihat bahawa tugasan yang berbeza dibenamkan ke dalam subruang yang berbeza oleh model, supaya OFA boleh mempelajari tugasan yang berbeza secara berasingan tanpa menjejaskan satu sama lain.
Dalam senario beberapa sampel dan sifar sampel, OFA menggunakan model tunggal pada ogbn-arxiv(graf hubungan petikan), FB15K237(graf pengetahuan) dan Chemble(graf molekul) dan untuk pra-pelatihan Prestasinya pada tugas hiliran dan set data yang berbeza. Keputusan adalah seperti berikut:
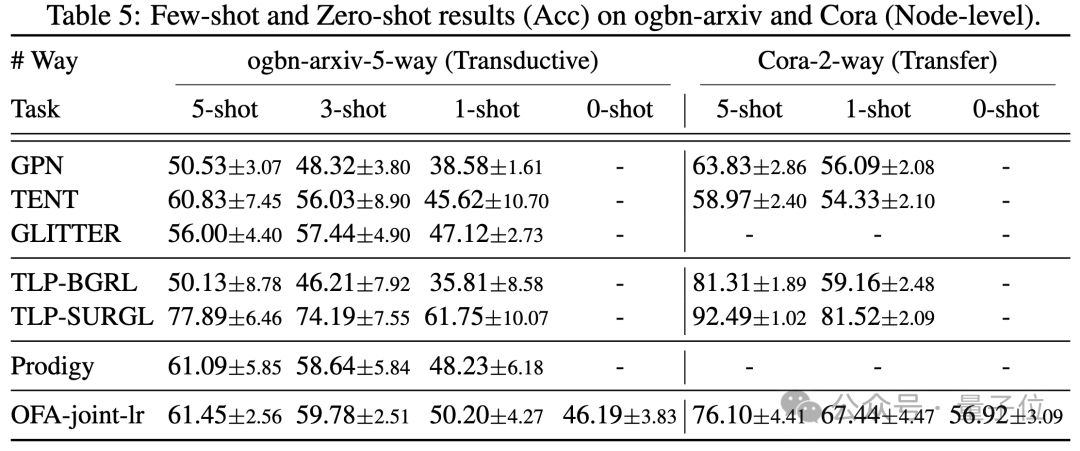
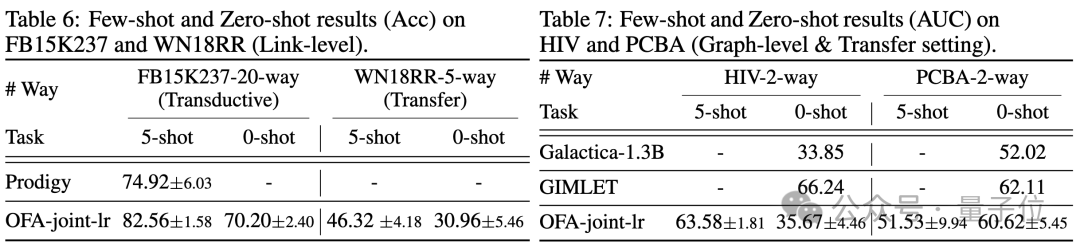
Dapat dilihat bahawa walaupun dalam senario sampel sifar, OFA masih boleh mencapai keputusan yang baik. Diambil bersama, keputusan percubaan mengesahkan prestasi am yang berkuasa OFA dan potensinya sebagai model asas dalam medan graf.
Untuk butiran penyelidikan lanjut, sila rujuk kertas asal.
Alamat: https://www.php.cn/link/dd4729902a3476b2bc9675e3530a852chttps://github.com/LechengKong
Atas ialah kandungan terperinci Rangka kerja universal pertama dalam medan graf ada di sini! Dipilih ke dalam Spotlight ICLR\'24, sebarang set data atau masalah klasifikasi boleh diselesaikan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 pemampatan audio
pemampatan audio
 ps keluar kekunci pintasan skrin penuh
ps keluar kekunci pintasan skrin penuh
 Bagaimana untuk memadam direktori dalam LINUX
Bagaimana untuk memadam direktori dalam LINUX
 Perbezaan antara xls dan xlsx
Perbezaan antara xls dan xlsx
 Bagaimana untuk membuka format json
Bagaimana untuk membuka format json
 Perbezaan antara * dan & dalam bahasa C
Perbezaan antara * dan & dalam bahasa C
 seni bina c/s dan seni bina b/s
seni bina c/s dan seni bina b/s
 Nombor telefon mudah alih maya untuk menerima kod pengesahan
Nombor telefon mudah alih maya untuk menerima kod pengesahan








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



