
 Peranti teknologi
AI
Tanpa membahagikannya kepada token, belajar terus daripada bait dengan cekap juga boleh digunakan dengan cara ini.
Peranti teknologi
AI
Tanpa membahagikannya kepada token, belajar terus daripada bait dengan cekap juga boleh digunakan dengan cara ini.
Tanpa membahagikannya kepada token, belajar terus daripada bait dengan cekap juga boleh digunakan dengan cara ini.

Apabila mentakrifkan model bahasa, kaedah pembahagian kata asas sering digunakan untuk membahagikan ayat kepada perkataan, sub-kata atau aksara. Segmentasi subkata telah lama menjadi pilihan paling popular kerana ia memberikan keseimbangan antara kecekapan latihan dan keupayaan untuk mengendalikan perkataan di luar perbendaharaan kata. Walau bagaimanapun, beberapa kajian telah menunjukkan masalah dengan pembahagian subkata, seperti kekurangan keteguhan pengendalian kesilapan taip, perubahan ejaan dan huruf kecil, dan perubahan morfologi. Oleh itu, isu-isu ini perlu dipertimbangkan dengan teliti dalam reka bentuk model bahasa untuk meningkatkan ketepatan dan keteguhan model.
Oleh itu, sesetengah penyelidik telah memilih pendekatan menggunakan jujukan bait, iaitu melalui pemetaan hujung ke hujung data mentah kepada hasil ramalan tanpa sebarang pembahagian perkataan. Berbanding dengan model sub-kata, model bahasa peringkat byte lebih mudah untuk digeneralisasikan kepada bentuk tulisan dan perubahan morfologi yang berbeza. Walau bagaimanapun, pemodelan teks sebagai bait bermakna urutan yang dijana lebih panjang daripada subkata yang sepadan. Untuk meningkatkan kecekapan, ia perlu dicapai dengan menambah baik seni bina.
Autoregressive Transformer menduduki kedudukan dominan dalam pemodelan bahasa, tetapi masalah kecekapannya amat ketara. Kos pengiraannya meningkat secara kuadratik apabila panjang jujukan meningkat, mengakibatkan kebolehskalaan yang lemah untuk jujukan yang panjang. Untuk menyelesaikan masalah ini, para penyelidik memampatkan perwakilan dalaman Transformer untuk mengendalikan urutan yang panjang. Satu pendekatan sedemikian ialah pembangunan pendekatan pemodelan sedar panjang yang menggabungkan kumpulan token dalam lapisan perantaraan, dengan itu mengurangkan kos pengiraan. Baru-baru ini, Yu et al mencadangkan kaedah yang dipanggil MegaByte Transformer. Ia menggunakan serpihan bait bersaiz tetap untuk mensimulasikan bentuk mampat sebagai subkata, sekali gus mengurangkan kos pengiraan. Walau bagaimanapun, ini mungkin bukan penyelesaian terbaik pada masa ini dan memerlukan penyelidikan dan penambahbaikan lanjut.
Dalam kajian terkini, sarjana dari Universiti Cornell memperkenalkan model bahasa peringkat bait yang cekap dan ringkas yang dipanggil MambaByte. Model ini diperoleh daripada penambahbaikan langsung seni bina Mamba yang diperkenalkan baru-baru ini. Seni bina Mamba dibina berdasarkan kaedah model angkasa lepas (SSM), manakala MambaByte memperkenalkan mekanisme pemilihan yang lebih cekap, menjadikannya berprestasi lebih baik apabila memproses data diskret seperti teks, dan juga menyediakan pelaksanaan GPU yang cekap. Para penyelidik secara ringkas memerhatikan menggunakan Mamba yang tidak diubah suai dan mendapati bahawa ia dapat mengurangkan kesesakan pengiraan utama dalam pemodelan bahasa, dengan itu menghapuskan keperluan untuk tampalan dan menggunakan sepenuhnya sumber pengiraan yang tersedia.

- Tajuk kertas: MambaByte: Model Ruang Negeri Terpilih tanpa token
- Pautan kertas: https://arxiv.org.pdf Dalam percubaan, mereka membandingkan MambaByte dengan seni bina Transformers, SSM dan MegaByte (menampal). Seni bina ini dinilai di bawah parameter tetap dan tetapan pengiraan dan pada beberapa set data teks bentuk panjang. Rajah 1 meringkaskan penemuan utama mereka.
Berbanding dengan Transformers peringkat byte, MambaByte menyediakan penyelesaian yang lebih pantas dan berprestasi tinggi, manakala kecekapan pengkomputeran juga telah dipertingkatkan dengan ketara. Para penyelidik juga membandingkan model bahasa bebas token dengan model subkata terkini dan mendapati bahawa MambaByte berdaya saing dalam hal ini dan boleh mengendalikan urutan yang lebih panjang. Hasil kajian ini menunjukkan bahawa MambaByte boleh menjadi alternatif yang berkuasa kepada tokenizer sedia ada yang bergantung pada mereka, dan dijangka menggalakkan perkembangan selanjutnya pembelajaran hujung ke hujung. 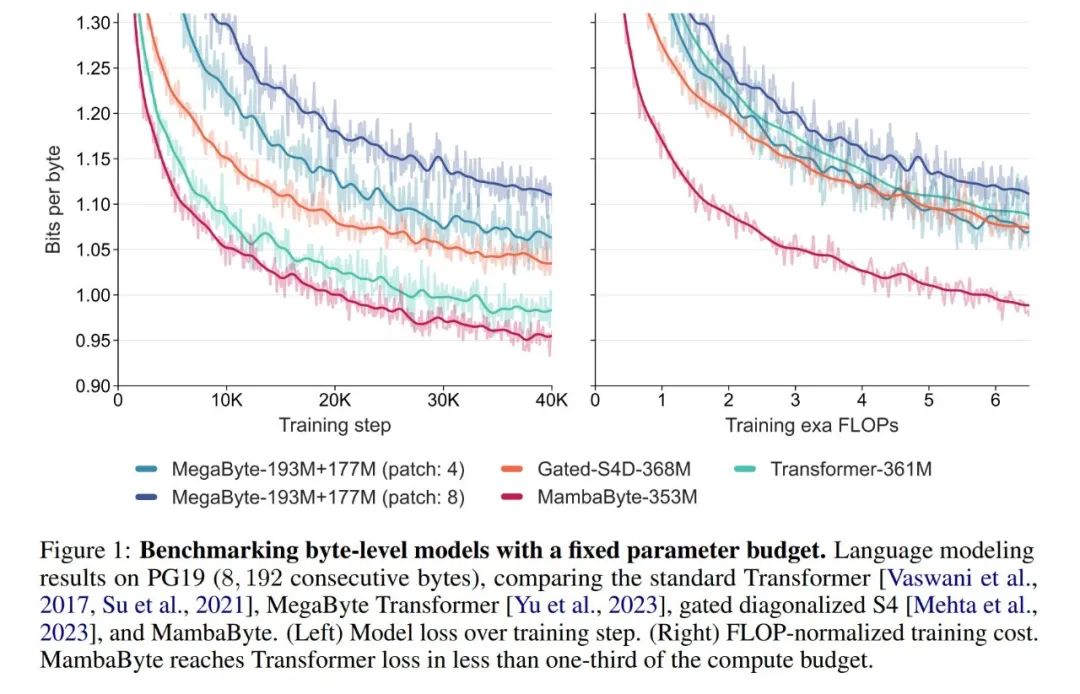
Latar Belakang: Model Jujukan Ruang Keadaan Terpilih
SSM menggunakan persamaan pembezaan tertib pertama untuk memodelkan evolusi masa keadaan tersembunyi. SSM invarian masa linear telah menunjukkan hasil yang baik dalam pelbagai tugas pembelajaran mendalam. Walau bagaimanapun, baru-baru ini penulis Mamba, Gu dan Dao berpendapat bahawa dinamik berterusan kaedah ini kekurangan pemilihan konteks yang bergantung kepada input dalam keadaan tersembunyi, yang mungkin diperlukan untuk tugas seperti pemodelan bahasa. Oleh itu, mereka mencadangkan kaedah Mamba, yang ditakrifkan secara dinamik dengan mengambil input x(t) ∈ R, keadaan tersembunyi h(t) ∈ R^n, dan output y(t) ∈ R sebagai keadaan berterusan yang berubah-ubah masa. pada masa t ialah:
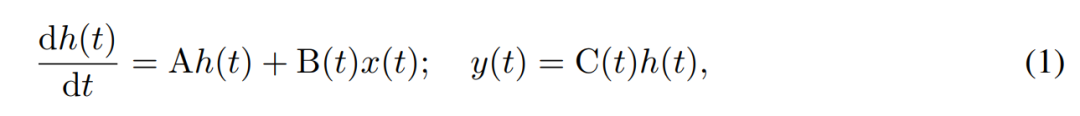 Parameternya ialah matriks sistem invarian masa pepenjuru A∈R^(n×n), dan matriks input dan output yang berubah-ubah B (t)∈R^ (n× 1) dan C (t)∈R^(1×n).
Parameternya ialah matriks sistem invarian masa pepenjuru A∈R^(n×n), dan matriks input dan output yang berubah-ubah B (t)∈R^ (n× 1) dan C (t)∈R^(1×n).
Untuk memodelkan siri masa diskret seperti bait, dinamik masa berterusan dalam (1) mesti dianggarkan melalui pendiskretan. Ini menghasilkan ulangan terpendam masa diskret, dengan matriks A, B dan C baharu pada setiap langkah masa, iaitu
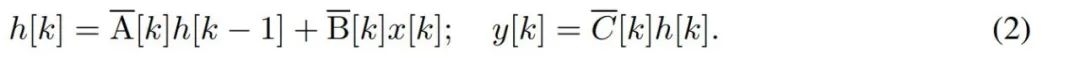
Perhatikan bahawa (2) adalah serupa dengan versi linear rangkaian saraf berulang, yang boleh ditemui dalam bahasa Gelung ini digunakan semasa penjanaan model. Diskretisasi memerlukan setiap kedudukan input mempunyai langkah masa, iaitu Δ[k], sepadan dengan x [k] = x (t_k) daripada 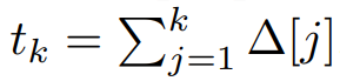 . Matriks masa diskret A, B dan C kemudiannya boleh dikira daripada Δ[k]. Rajah 2 menunjukkan bagaimana Mamba memodelkan jujukan diskret.
. Matriks masa diskret A, B dan C kemudiannya boleh dikira daripada Δ[k]. Rajah 2 menunjukkan bagaimana Mamba memodelkan jujukan diskret.
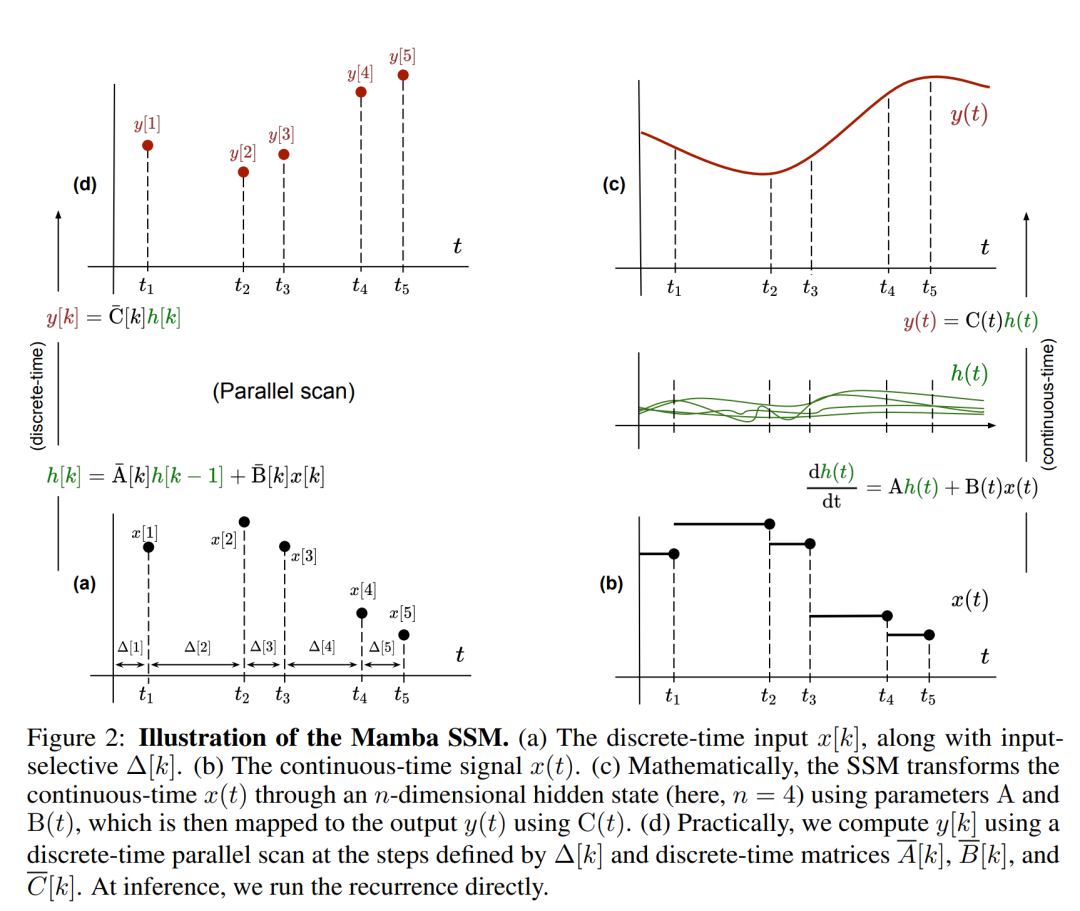
Di Mamba, istilah SSM ialah input terpilih, iaitu, B, C dan Δ ditakrifkan sebagai fungsi input x [k]∈R^d:
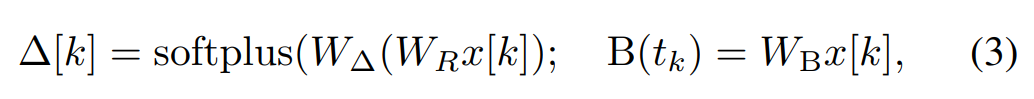
di mana W_B ∈ R^(n×d) (C ditakrifkan sama), W_Δ ∈ R^(d×r) dan W_R ∈ R^(r×d) (untuk sesetengah r ≪d) ialah pemberat yang boleh dipelajari, Dan softplus memastikan positif. Ambil perhatian bahawa untuk setiap dimensi input d, parameter SSM A, B dan C adalah sama, tetapi bilangan langkah masa Δ adalah berbeza ini menghasilkan saiz keadaan tersembunyi n × d untuk setiap langkah masa k.
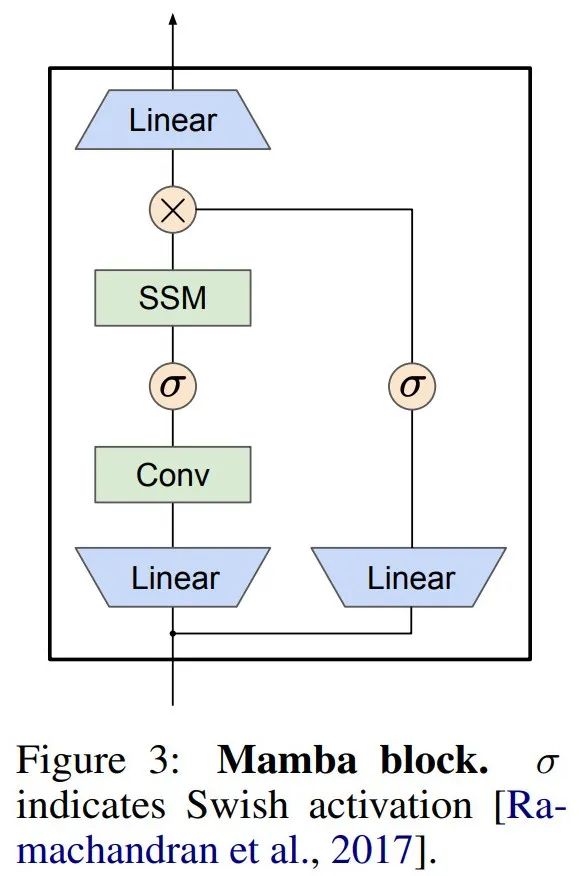 Mamba membenamkan lapisan SSM ini ke dalam model bahasa rangkaian saraf yang lengkap. Khususnya, model ini menggunakan satu siri lapisan gating yang diilhamkan oleh SSM berpagar sebelumnya. Rajah 3 menunjukkan seni bina Mamba menggabungkan lapisan SSM dengan rangkaian saraf berpagar.
Mamba membenamkan lapisan SSM ini ke dalam model bahasa rangkaian saraf yang lengkap. Khususnya, model ini menggunakan satu siri lapisan gating yang diilhamkan oleh SSM berpagar sebelumnya. Rajah 3 menunjukkan seni bina Mamba menggabungkan lapisan SSM dengan rangkaian saraf berpagar.

 Imbasan selari berulang linear. Pada masa latihan, pengarang mempunyai akses kepada keseluruhan jujukan x, membolehkan pengiraan ulangan linear yang lebih cekap. Penyelidikan oleh Smith et al [2023] menunjukkan bahawa pengulangan berurutan dalam SSM linear boleh dikira dengan cekap menggunakan imbasan selari yang cekap. Untuk Mamba, pengarang mula-mula memetakan ulangan kepada jujukan L tuple, di mana e_k =
Imbasan selari berulang linear. Pada masa latihan, pengarang mempunyai akses kepada keseluruhan jujukan x, membolehkan pengiraan ulangan linear yang lebih cekap. Penyelidikan oleh Smith et al [2023] menunjukkan bahawa pengulangan berurutan dalam SSM linear boleh dikira dengan cekap menggunakan imbasan selari yang cekap. Untuk Mamba, pengarang mula-mula memetakan ulangan kepada jujukan L tuple, di mana e_k =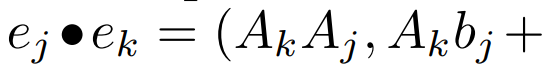
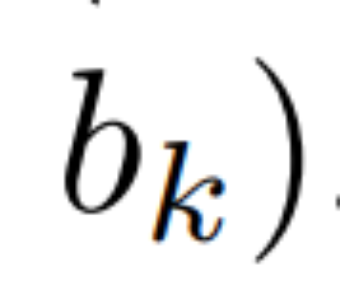 , dan kemudian mentakrifkan pengendali persatuan
, dan kemudian mentakrifkan pengendali persatuan 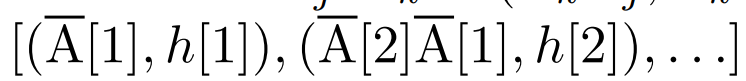 supaya
supaya 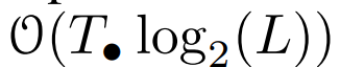 . Akhirnya, mereka menggunakan imbasan selari untuk mengira urutan
. Akhirnya, mereka menggunakan imbasan selari untuk mengira urutan 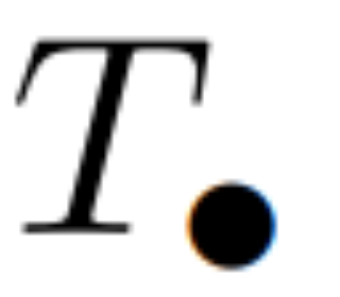 . Secara umum, ini mengambil masa
. Secara umum, ini mengambil masa 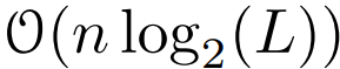 , menggunakan pemproses L/2, di mana
, menggunakan pemproses L/2, di mana
Hasil eksperimen
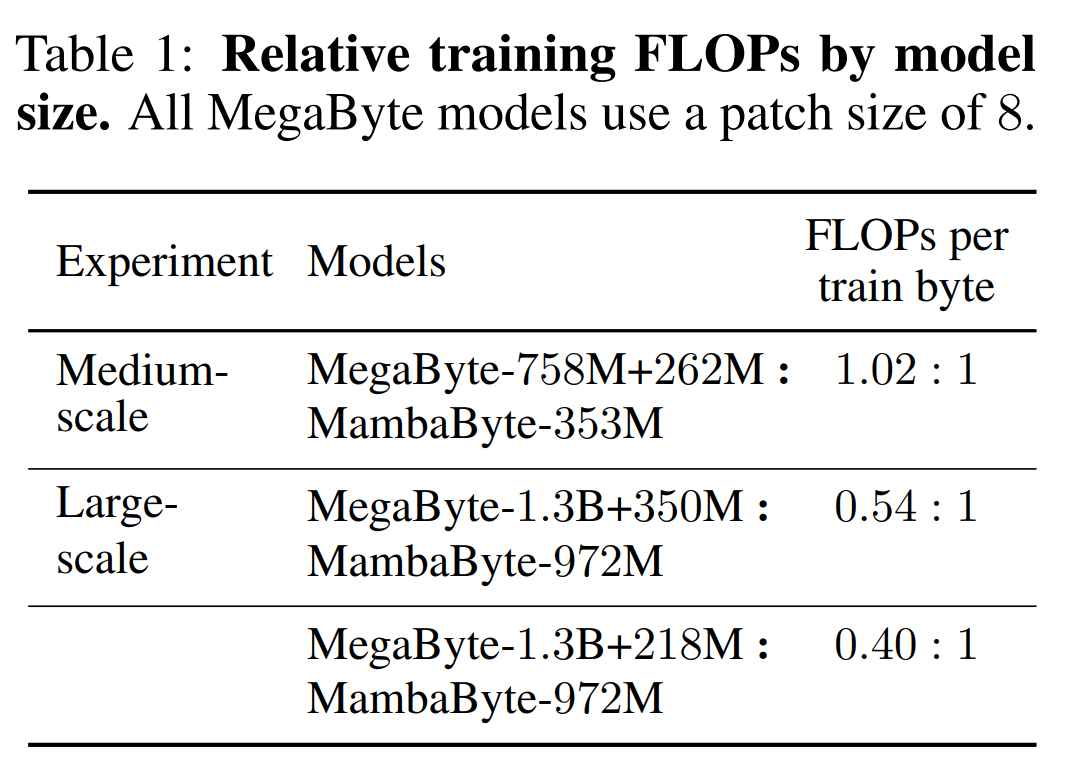
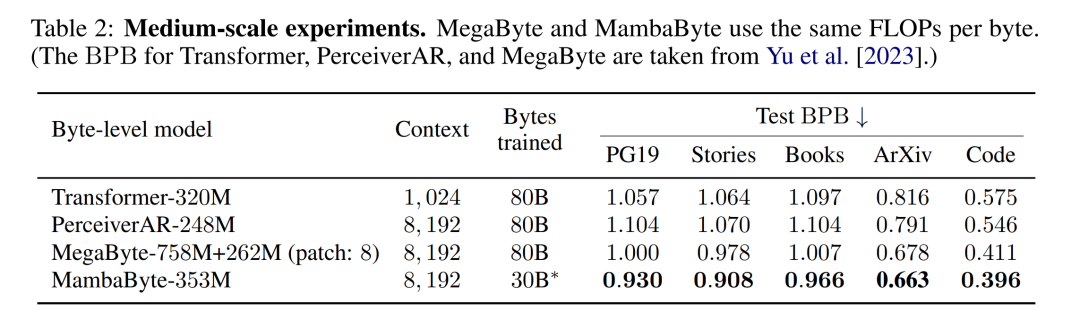
Jadual 2 menunjukkan bit per bait (BPB) untuk setiap set data. Dalam eksperimen ini, model MegaByte758M+262M dan MambaByte menggunakan bilangan FLOP setiap bait yang sama (lihat Jadual 1). Pengarang mendapati bahawa MambaByte secara konsisten mengatasi MegaByte pada semua set data. Selain itu, penulis ambil perhatian bahawa disebabkan kekangan pembiayaan mereka tidak dapat melatih MambaByte pada 80B bait penuh, tetapi MambaByte masih mengatasi MegaByte dengan 63% kurang pengiraan dan 63% kurang data latihan. Selain itu, MambaByte-353M mengatasi prestasi Transformer dan PerceiverAR skala byte.
Mengapa MambaByte berprestasi lebih baik daripada model yang lebih besar dalam beberapa langkah latihan? Rajah 1 meneroka lagi hubungan ini dengan melihat model dengan bilangan parameter yang sama. Angka tersebut menunjukkan bahawa untuk model MegaByte dengan saiz parameter yang sama, model dengan tampalan input yang kurang menunjukkan prestasi yang lebih baik, tetapi selepas mengira penormalan, ia menunjukkan prestasi yang sama. Sebenarnya, Transformer penuh, walaupun lebih perlahan dari segi mutlak, berprestasi serupa dengan MegaByte selepas normalisasi pengiraan. Sebaliknya, beralih kepada seni bina Mamba boleh meningkatkan penggunaan pengiraan dan prestasi model dengan ketara.
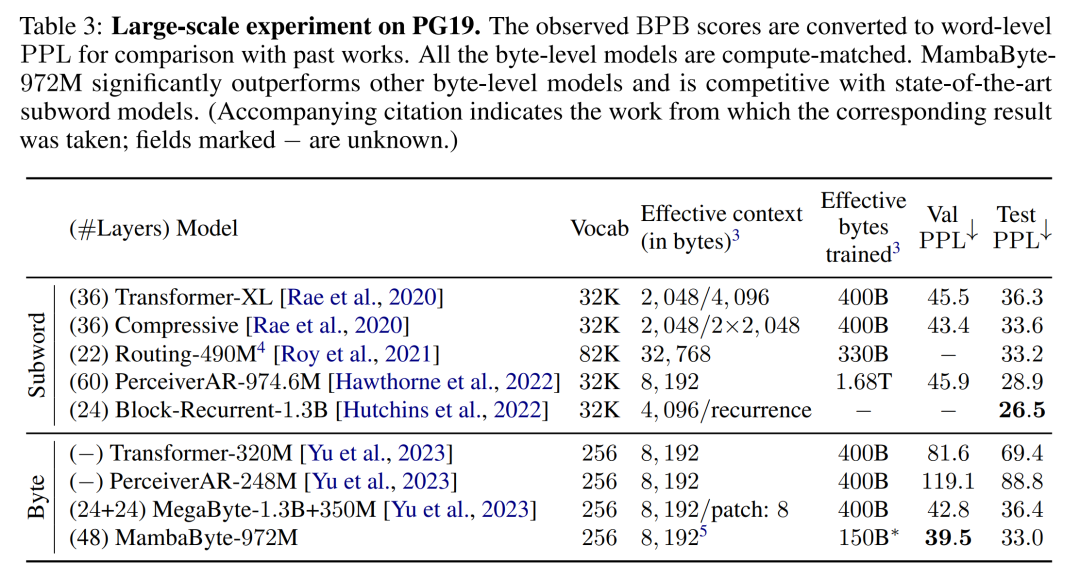
Berdasarkan penemuan ini, Jadual 3 membandingkan versi yang lebih besar bagi model ini pada set data PG19. Dalam eksperimen ini, penulis membandingkan MambaByte-972M dengan MegaByte-1.3B+350M dan model peringkat bait lain serta beberapa model subkata SOTA. Mereka mendapati bahawa MambaByte-972M mengatasi semua model peringkat bait dan berdaya saing dengan model subkata walaupun dilatih pada hanya 150B bait.
Penjanaan teks. Inferens autoregresif dalam model Transformer memerlukan caching keseluruhan konteks, yang memberi kesan ketara kepada kelajuan penjanaan. MambaByte tidak mempunyai kesesakan ini kerana ia mengekalkan hanya satu keadaan tersembunyi yang berubah-ubah masa setiap lapisan, jadi masa setiap langkah generasi adalah malar. Jadual 4 membandingkan kelajuan penjanaan teks MambaByte-972M dan MambaByte-1.6B dengan MegaByte-1.3B+350M pada GPU PCIe A100 80GB. Walaupun MegaByte sangat mengurangkan kos penjanaan melalui tampalan, mereka mendapati bahawa MambaByte adalah 2.6 kali lebih pantas di bawah tetapan parameter yang sama disebabkan penggunaan penjanaan gelung.

Atas ialah kandungan terperinci Tanpa membahagikannya kepada token, belajar terus daripada bait dengan cekap juga boleh digunakan dengan cara ini.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1379
1379
 52
52

 Petua Konfigurasi Firewall Pelayan Mel Debian
Apr 13, 2025 am 11:42 AM
Petua Konfigurasi Firewall Pelayan Mel Debian
Apr 13, 2025 am 11:42 AM
Mengkonfigurasi firewall pelayan Mail Debian adalah langkah penting dalam memastikan keselamatan pelayan. Berikut adalah beberapa kaedah konfigurasi firewall yang biasa digunakan, termasuk penggunaan iptables dan firewalld. Gunakan iptables untuk mengkonfigurasi firewall untuk memasang iptables (jika belum dipasang): sudoapt-getupdateudoapt-getinstalliplesview peraturan iptables semasa: konfigurasi sudoiptable-l
 Bagaimana Debian Readdir Bersepadu Dengan Alat Lain
Apr 13, 2025 am 09:42 AM
Bagaimana Debian Readdir Bersepadu Dengan Alat Lain
Apr 13, 2025 am 09:42 AM
Fungsi Readdir dalam sistem Debian adalah panggilan sistem yang digunakan untuk membaca kandungan direktori dan sering digunakan dalam pengaturcaraan C. Artikel ini akan menerangkan cara mengintegrasikan Readdir dengan alat lain untuk meningkatkan fungsinya. Kaedah 1: Menggabungkan Program Bahasa C dan Pipeline Pertama, tulis program C untuk memanggil fungsi Readdir dan output hasilnya:#termasuk#termasuk#includeintMain (intargc, char*argv []) {dir*dir; structdirent*entry; if (argc! = 2) {
 Cara Melaksanakan Penyortiran Fail oleh Debian Readdir
Apr 13, 2025 am 09:06 AM
Cara Melaksanakan Penyortiran Fail oleh Debian Readdir
Apr 13, 2025 am 09:06 AM
Dalam sistem Debian, fungsi Readdir digunakan untuk membaca kandungan direktori, tetapi urutan yang dikembalikannya tidak ditentukan sebelumnya. Untuk menyusun fail dalam direktori, anda perlu membaca semua fail terlebih dahulu, dan kemudian menyusunnya menggunakan fungsi QSORT. Kod berikut menunjukkan cara menyusun fail direktori menggunakan ReadDir dan QSORT dalam sistem Debian:#termasuk#termasuk#termasuk#termasuk // fungsi perbandingan adat, yang digunakan untuk qSortintCompare (Constvoid*A, Constvoid*b) {Returnstrcmp (*(*(*(*(*(*(*(*(*(*(*(*(*(*(*(*(*(
 Kaedah pemasangan sijil SSL Server Server Debian
Apr 13, 2025 am 11:39 AM
Kaedah pemasangan sijil SSL Server Server Debian
Apr 13, 2025 am 11:39 AM
Langkah -langkah untuk memasang sijil SSL pada pelayan mel Debian adalah seperti berikut: 1. Pasang OpenSSL Toolkit terlebih dahulu, pastikan bahawa OpenSSL Toolkit telah dipasang pada sistem anda. Jika tidak dipasang, anda boleh menggunakan arahan berikut untuk memasang: sudoapt-getupdateudoapt-getinstallopenssl2. Menjana permintaan kunci dan sijil peribadi seterusnya, gunakan OpenSSL untuk menjana kunci peribadi RSA 2048-bit dan permintaan sijil (CSR): Membuka
 Cara Melakukan Pengesahan Tandatangan Digital dengan Debian Openssl
Apr 13, 2025 am 11:09 AM
Cara Melakukan Pengesahan Tandatangan Digital dengan Debian Openssl
Apr 13, 2025 am 11:09 AM
Menggunakan OpenSSL untuk Pengesahan Tandatangan Digital pada Sistem Debian, anda boleh mengikuti langkah -langkah berikut: Penyediaan untuk memasang OpenSSL: Pastikan sistem Debian anda telah dipasang. Jika tidak dipasang, anda boleh menggunakan arahan berikut untuk memasangnya: sudoaptdateudoaptininstallopenssl untuk mendapatkan kunci awam: Pengesahan tandatangan digital memerlukan kunci awam penandatangan. Biasanya, kunci awam akan disediakan dalam bentuk fail, seperti public_key.pe
 Bagaimana Debian OpenSSL Menghalang Serangan Man-dalam-Middle
Apr 13, 2025 am 10:30 AM
Bagaimana Debian OpenSSL Menghalang Serangan Man-dalam-Middle
Apr 13, 2025 am 10:30 AM
Dalam sistem Debian, OpenSSL adalah perpustakaan penting untuk pengurusan penyulitan, penyahsulitan dan sijil. Untuk mengelakkan serangan lelaki-dalam-pertengahan (MITM), langkah-langkah berikut boleh diambil: Gunakan HTTPS: Pastikan semua permintaan rangkaian menggunakan protokol HTTPS dan bukannya HTTP. HTTPS menggunakan TLS (Protokol Keselamatan Lapisan Pengangkutan) untuk menyulitkan data komunikasi untuk memastikan data tidak dicuri atau diganggu semasa penghantaran. Sahkan Sijil Pelayan: Sahkan secara manual Sijil Pelayan pada klien untuk memastikan ia boleh dipercayai. Pelayan boleh disahkan secara manual melalui kaedah perwakilan urlSession
 Cara Melakukan Pengurusan Log Debian Hadoop
Apr 13, 2025 am 10:45 AM
Cara Melakukan Pengurusan Log Debian Hadoop
Apr 13, 2025 am 10:45 AM
Menguruskan Log Hadoop pada Debian, anda boleh mengikuti langkah-langkah berikut dan amalan terbaik: Agregasi log membolehkan pengagregatan log: tetapkan benang.log-agregasi-enable untuk benar dalam fail benang-site.xml untuk membolehkan pengagregatan log. Konfigurasikan dasar pengekalan log: tetapkan yarn.log-aggregasi.Retain-seconds Untuk menentukan masa pengekalan log, seperti 172800 saat (2 hari). Nyatakan Laluan Penyimpanan Log: Melalui Benang
 Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Perintah shutdown CentOS adalah penutupan, dan sintaks adalah tutup [pilihan] [maklumat]. Pilihan termasuk: -h menghentikan sistem dengan segera; -P mematikan kuasa selepas penutupan; -r mulakan semula; -T Waktu Menunggu. Masa boleh ditentukan sebagai segera (sekarang), minit (minit), atau masa tertentu (HH: mm). Maklumat tambahan boleh dipaparkan dalam mesej sistem.
