
 Peranti teknologi
AI
Tinggalkan seni bina pengekod-penyahkod dan gunakan model resapan untuk pengesanan tepi, yang lebih berkesan Universiti Teknologi Pertahanan Nasional mencadangkan DiffusionEdge
Peranti teknologi
AI
Tinggalkan seni bina pengekod-penyahkod dan gunakan model resapan untuk pengesanan tepi, yang lebih berkesan Universiti Teknologi Pertahanan Nasional mencadangkan DiffusionEdge
Tinggalkan seni bina pengekod-penyahkod dan gunakan model resapan untuk pengesanan tepi, yang lebih berkesan Universiti Teknologi Pertahanan Nasional mencadangkan DiffusionEdge

Rangkaian pengesanan tepi dalam semasa biasanya menggunakan seni bina penyahkod pengekod, yang mengandungi modul pensampelan atas dan bawah untuk mengekstrak ciri berbilang peringkat dengan lebih baik. Walau bagaimanapun, struktur ini mengehadkan rangkaian untuk mengeluarkan hasil pengesanan tepi yang tepat dan terperinci.
Sebagai tindak balas kepada masalah ini, kertas kerja di AAI 2024 menyediakan penyelesaian baharu. . Yuxing (Universiti Teknologi Pertahanan Nasional), Yi Renjiao (Universiti Teknologi Pertahanan Kebangsaan), Cai Zhiping (Universiti Teknologi Pertahanan Kebangsaan)
 Pautan kertas: https://arxiv.org/abs/2401.02032
Pautan kertas: https://arxiv.org/abs/2401.02032
- Makmal iGRAPE Universiti Teknologi Pertahanan Nasional mencadangkan kaedah baharu untuk tugas pengesanan tepi dua dimensi. Kaedah ini menggunakan model kebarangkalian resapan untuk menjana peta hasil tepi semasa proses denoising berulang pembelajaran. Untuk mengurangkan penggunaan sumber pengkomputeran, kaedah ini menggunakan ruang terpendam untuk melatih rangkaian dan memperkenalkan modul penyulingan ketidakpastian untuk mengoptimumkan prestasi. Pada masa yang sama, kaedah ini juga menggunakan seni bina yang dipisahkan untuk mempercepatkan proses denoising dan memperkenalkan penapis Fourier adaptif untuk melaraskan ciri. Dengan reka bentuk ini, kaedah ini dapat melatih secara stabil dengan sumber yang terhad dan meramalkan peta tepi yang jelas dan tepat dengan strategi penambahan yang lebih sedikit. Keputusan eksperimen menunjukkan bahawa kaedah ini dengan ketara mengatasi kaedah lain dari segi ketepatan dan ketepatan pada empat set data penanda aras awam. . memerlukan pemprosesan pasca Ini membolehkan anda meramalkan peta tepi yang lebih nipis dan lebih tepat.
- Untuk menyelesaikan kesukaran dalam mengaplikasikan model resapan, kami telah mereka bentuk pelbagai teknik untuk memastikan kaedah tersebut belajar secara stabil dalam ruang terpendam. Pada masa yang sama, kami juga mengekalkan pengetahuan sedia ada ketidakpastian tahap piksel dan menyesuaikan ciri terpendam dalam ruang Fourier.
- 3 Eksperimen perbandingan meluas yang dijalankan pada set data penanda aras awam pengesanan tepi menunjukkan bahawa DiffusionEdge mempunyai kelebihan prestasi yang sangat baik dari segi ketepatan dan kehalusan. Kerja Berkaitan
Kaedah berdasarkan pembelajaran mendalam biasanya menggunakan struktur pengekodan dan penyahkodan termasuk pensampelan atas dan bawah untuk menyepadukan ciri berbilang lapisan [1-2], atau menyepadukan maklumat ketidakpastian daripada berbilang anotasi untuk meningkatkan pengesanan tepi ketepatan[3]. Walau bagaimanapun, secara semula jadi terhad oleh struktur sedemikian, peta hasil tepi yang dihasilkan terlalu tebal untuk tugasan hiliran dan banyak bergantung pada pasca pemprosesan Masalahnya masih perlu diselesaikan. Walaupun banyak karya telah diterokai dalam fungsi kehilangan [4-5] dan strategi pembetulan label [6] untuk membolehkan rangkaian menghasilkan tepi yang lebih halus, kertas ini percaya bahawa medan ini masih memerlukan kaedah yang boleh digunakan tanpa sebarang modul tambahan pengesan yang secara langsung memenuhi ketepatan dan kehalusan tanpa sebarang langkah pasca pemprosesan.
Kaedah Penerangan
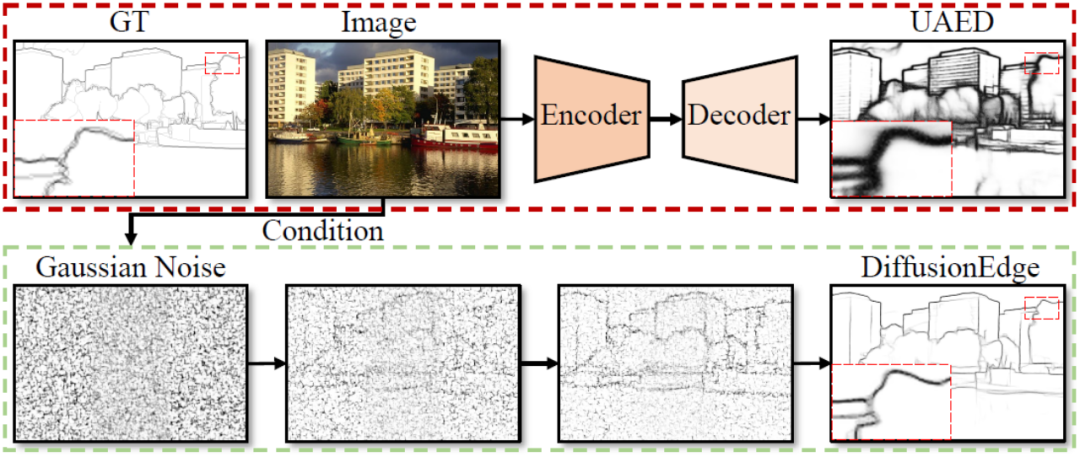
Rangka kerja keseluruhan kaedah DiffusionEdge yang dicadangkan dalam artikel ini ditunjukkan dalam Rajah 2. Diilhamkan oleh kerja sebelumnya, kaedah ini melatih model resapan dengan struktur yang dipisahkan dalam ruang terpendam dan memasukkan imej sebagai isyarat bersyarat tambahan. Kaedah ini memperkenalkan penapis Fourier adaptif untuk analisis kekerapan, dan untuk mengekalkan maklumat ketidakpastian tahap piksel daripada berbilang anotasi dan mengurangkan keperluan pada sumber pengkomputeran, ia juga secara langsung menggunakan pengoptimuman kehilangan entropi secara suling.
Rajah 2 Diagram skematik struktur keseluruhan DiffusionEdge
Memandangkan model penyebaran semasa dibelenggu oleh masalah seperti terlalu banyak langkah pensampelan dan masa inferens yang terlalu lama, kaedah ini diilhamkan oleh DDM [10] dan juga menggunakan decoupled resapan. Seni bina model untuk mempercepatkan proses inferens persampelan. Antaranya, proses resapan hadapan yang dipisahkan dikawal oleh gabungan kebarangkalian peralihan eksplisit dan proses Wiener standard:
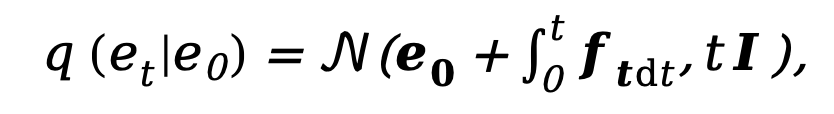
di mana 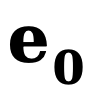 dan
dan 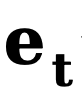 masing-masing mewakili tepi awal dan tepi hingar,
masing-masing mewakili tepi awal dan tepi hingar, 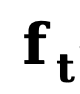 terbalik merujuk kepada tepi terbalik fungsi pemindahan untuk kecerunan. Sama seperti DDM, kaedah ini menggunakan fungsi malar
terbalik merujuk kepada tepi terbalik fungsi pemindahan untuk kecerunan. Sama seperti DDM, kaedah ini menggunakan fungsi malar 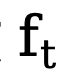 secara lalai, dan proses songsang sepadannya boleh dinyatakan sebagai:
secara lalai, dan proses songsang sepadannya boleh dinyatakan sebagai:
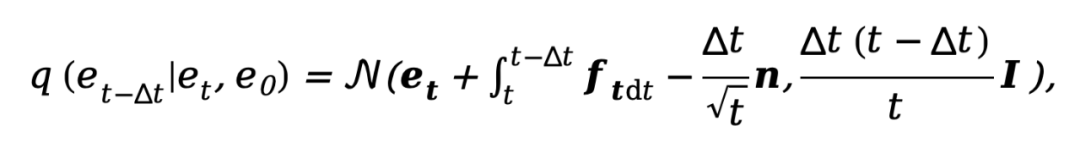
di mana  . Untuk melatih model penyebaran decoupled, kaedah ini memerlukan penyeliaan serentak terhadap data dan komponen hingar, oleh itu, objektif latihan boleh diparameterkan sebagai:
. Untuk melatih model penyebaran decoupled, kaedah ini memerlukan penyeliaan serentak terhadap data dan komponen hingar, oleh itu, objektif latihan boleh diparameterkan sebagai:
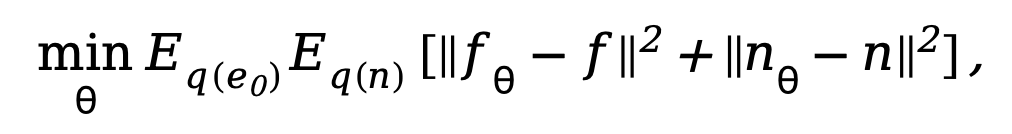
di mana 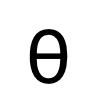 ialah parameter dalam rangkaian denoising. Memandangkan model resapan akan mengambil terlalu banyak kos pengiraan jika ia dilatih dalam ruang imej asal, merujuk kepada idea [11], kaedah yang dicadangkan dalam kertas kerja ini memindahkan proses latihan ke ruang terpendam dengan 4 kali ganda saiz ruang pensampelan rendah.
ialah parameter dalam rangkaian denoising. Memandangkan model resapan akan mengambil terlalu banyak kos pengiraan jika ia dilatih dalam ruang imej asal, merujuk kepada idea [11], kaedah yang dicadangkan dalam kertas kerja ini memindahkan proses latihan ke ruang terpendam dengan 4 kali ganda saiz ruang pensampelan rendah.
Seperti yang ditunjukkan dalam Rajah 2, kaedah ini mula-mula melatih sepasang rangkaian pengekod dan penyahkod Pengekod memampatkan anotasi tepi ke dalam pembolehubah terpendam, dan penyahkod digunakan untuk memulihkan daripada pembolehubah terpendam ini . Dengan cara ini, semasa peringkat latihan rangkaian denoising berdasarkan struktur U-Net, kaedah ini membetulkan berat pasangan rangkaian autoenkoder dan penyahkod, dan melatih proses denoising dalam ruang terpendam, yang boleh mengurangkan pengiraan dengan banyak. kos rangkaian penggunaan sumber sambil mengekalkan prestasi yang baik.
Untuk meningkatkan prestasi akhir rangkaian, kaedah yang dicadangkan dalam artikel ini memperkenalkan modul yang secara adaptif boleh menapis ciri frekuensi berbeza dalam operasi penyahgandingan. Seperti yang ditunjukkan di sudut kiri bawah Rajah 2, kaedah ini menyepadukan penapis transformasi Fourier cepat suai (penapis FFT Penyesuai) ke dalam rangkaian Unet denoising sebelum operasi penyahgandingan untuk menyesuaikan dan memisahkan secara adaptif dalam peta tepi Keluar dan hingar komponen. Khususnya, memandangkan ciri pengekod  , kaedah pertama kali melakukan transformasi Fourier dua dimensi (FFT) di sepanjang dimensi ruang dan mewakili ciri diubah sebagai
, kaedah pertama kali melakukan transformasi Fourier dua dimensi (FFT) di sepanjang dimensi ruang dan mewakili ciri diubah sebagai  . Seterusnya, untuk melatih modul penapisan spektrum penyesuaian ini, peta berat boleh dipelajari
. Seterusnya, untuk melatih modul penapisan spektrum penyesuaian ini, peta berat boleh dipelajari 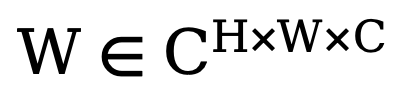 dibina dan Wnya didarab dengan Fc. Penapis spektrum boleh melaraskan frekuensi tertentu secara global, dan pemberat yang dipelajari boleh disesuaikan dengan kes frekuensi yang berbeza bagi pengedaran sasaran dalam set data yang berbeza. Dengan menapis secara adaptif komponen yang tidak diingini, kaedah ini memetakan ciri dari domain frekuensi kembali ke domain spatial melalui operasi transformasi Fourier pantas songsang (IFFT). Akhir sekali, dengan memperkenalkan sambungan baki daripada , kami mengelak daripada menapis sepenuhnya semua maklumat berguna. Proses di atas boleh diterangkan dengan formula berikut:
dibina dan Wnya didarab dengan Fc. Penapis spektrum boleh melaraskan frekuensi tertentu secara global, dan pemberat yang dipelajari boleh disesuaikan dengan kes frekuensi yang berbeza bagi pengedaran sasaran dalam set data yang berbeza. Dengan menapis secara adaptif komponen yang tidak diingini, kaedah ini memetakan ciri dari domain frekuensi kembali ke domain spatial melalui operasi transformasi Fourier pantas songsang (IFFT). Akhir sekali, dengan memperkenalkan sambungan baki daripada , kami mengelak daripada menapis sepenuhnya semua maklumat berguna. Proses di atas boleh diterangkan dengan formula berikut:
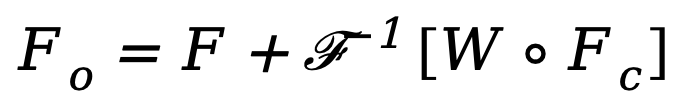
di mana 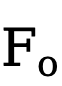 ialah ciri output, dan o mewakili Produk Hadamard.
ialah ciri output, dan o mewakili Produk Hadamard.
Disebabkan ketidakseimbangan yang tinggi dalam bilangan piksel tepi dan bukan tepi (kebanyakan piksel adalah latar belakang bukan tepi), merujuk kepada kerja terdahulu, kami juga memperkenalkan fungsi kehilangan kesedaran ketidakpastian untuk latihan. Khususnya, sebagai kebarangkalian tepi nilai sebenar bagi piksel ke-i, untuk piksel ke-i dalam peta tepi ke-j, nilainya ialah 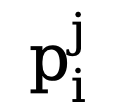 , maka kehilangan WCE yang disedari ketidakpastian dikira seperti berikut:
, maka kehilangan WCE yang disedari ketidakpastian dikira seperti berikut:
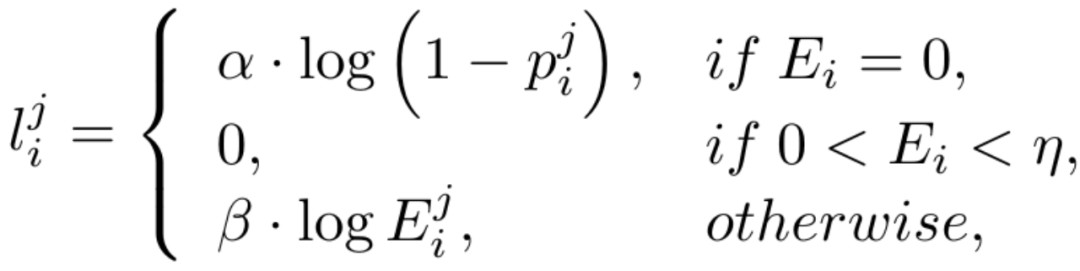
di mana 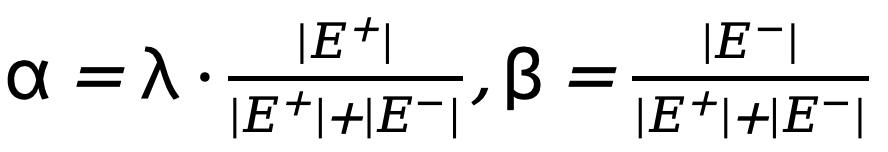 , dengan
, dengan 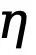 ialah ambang yang menentukan piksel tepi yang tidak pasti dalam anotasi nilai sebenar Jika nilai piksel lebih besar daripada 0 dan kurang daripada ambang ini, sampel piksel kabur dengan keyakinan yang tidak mencukupi akan digunakan dalam pengoptimuman berikutnya. proses diabaikan (fungsi kehilangan ialah 0).
ialah ambang yang menentukan piksel tepi yang tidak pasti dalam anotasi nilai sebenar Jika nilai piksel lebih besar daripada 0 dan kurang daripada ambang ini, sampel piksel kabur dengan keyakinan yang tidak mencukupi akan digunakan dalam pengoptimuman berikutnya. proses diabaikan (fungsi kehilangan ialah 0). 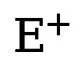 dan
dan 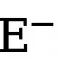 masing-masing mewakili bilangan piksel tepi dan bukan tepi dalam peta tepi beranotasi kebenaran tanah. ialah berat yang digunakan untuk mengimbangi
masing-masing mewakili bilangan piksel tepi dan bukan tepi dalam peta tepi beranotasi kebenaran tanah. ialah berat yang digunakan untuk mengimbangi 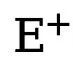 dan
dan 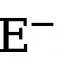 (ditetapkan kepada 1.1). Oleh itu, fungsi kehilangan akhir untuk setiap peta tepi dikira sebagai
(ditetapkan kepada 1.1). Oleh itu, fungsi kehilangan akhir untuk setiap peta tepi dikira sebagai 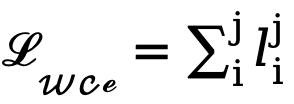 .
.
Mengabaikan piksel keyakinan rendah yang kabur semasa proses pengoptimuman boleh mengelakkan kekeliruan rangkaian, menjadikan proses latihan bertumpu dengan lebih stabil dan meningkatkan prestasi model. Walau bagaimanapun, hampir mustahil untuk menggunakan kehilangan rentas-entropi binari secara langsung dalam ruang terpendam yang tidak sejajar secara numerik dan ruang. Khususnya, kehilangan rentas entropi sedar ketidakpastian menggunakan ambang 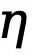 (biasanya dari 0 hingga 1) untuk menentukan sama ada piksel ialah tepi, yang ditakrifkan daripada ruang imej, manakala pembolehubah pendam mengikut taburan normal dan mempunyai sepenuhnya skop dan kepentingan praktikal yang berbeza. Tambahan pula, ketidakpastian tahap piksel adalah sukar untuk diselaraskan dengan saiz ciri terpendam yang dikodkan dan dikurangkan sampel yang berbeza, dan kedua-duanya tidak serasi secara langsung. Oleh itu, secara langsung menggunakan kehilangan entropi silang untuk mengoptimumkan pembolehubah terpendam tidak dapat dielakkan membawa kepada persepsi ketidakpastian yang salah.
(biasanya dari 0 hingga 1) untuk menentukan sama ada piksel ialah tepi, yang ditakrifkan daripada ruang imej, manakala pembolehubah pendam mengikut taburan normal dan mempunyai sepenuhnya skop dan kepentingan praktikal yang berbeza. Tambahan pula, ketidakpastian tahap piksel adalah sukar untuk diselaraskan dengan saiz ciri terpendam yang dikodkan dan dikurangkan sampel yang berbeza, dan kedua-duanya tidak serasi secara langsung. Oleh itu, secara langsung menggunakan kehilangan entropi silang untuk mengoptimumkan pembolehubah terpendam tidak dapat dielakkan membawa kepada persepsi ketidakpastian yang salah.
Sebaliknya, seseorang boleh memilih untuk menyahkod pembolehubah terpendam kembali ke tahap imej, dengan itu menyelia secara langsung peta hasil kelebihan yang diramalkan menggunakan kehilangan rentas entropi yang menyedari ketidakpastian. Malangnya, pelaksanaan ini membenarkan kecerunan parameter rambatan belakang untuk melalui rangkaian pengekod auto berlebihan, menjadikannya sukar untuk memindahkan kecerunan dengan berkesan. Di samping itu, pengiraan kecerunan tambahan dalam rangkaian pengekod auto akan membawa kos penggunaan memori GPU yang besar, yang melanggar niat asal kaedah ini untuk mereka bentuk pengesan tepi praktikal dan sukar untuk digeneralisasikan kepada aplikasi praktikal. Oleh itu, kaedah ini mencadangkan kehilangan penyulingan yang tidak pasti, yang boleh mengoptimumkan secara langsung kecerunan pada ruang terpendam Secara khusus, biarkan pembolehubah pendam yang dibina semula ialah  , penyahkod rangkaian pengekod automatik ialah D, dan hasil tepi yang dinyahkodkan ialah eD mempertimbangkan secara terus mengira kecerunan kerugian rentas entropi binari ketidakpastian
, penyahkod rangkaian pengekod automatik ialah D, dan hasil tepi yang dinyahkodkan ialah eD mempertimbangkan secara terus mengira kecerunan kerugian rentas entropi binari ketidakpastian  berdasarkan peraturan rantaian Kaedah pengiraan khusus ialah:
berdasarkan peraturan rantaian Kaedah pengiraan khusus ialah:
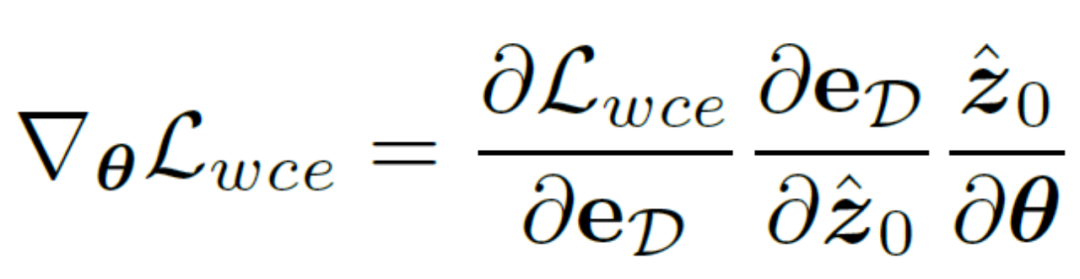
Untuk menghapuskan kesan negatif rangkaian autoenkoder, kaedah ini. autoencoder  terus dilangkau untuk melepasi kecerunan dan kaedah pengiraan kecerunan
terus dilangkau untuk melepasi kecerunan dan kaedah pengiraan kecerunan 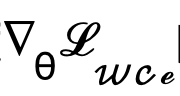 diubah suai dan dilaraskan kepada:
diubah suai dan dilaraskan kepada:
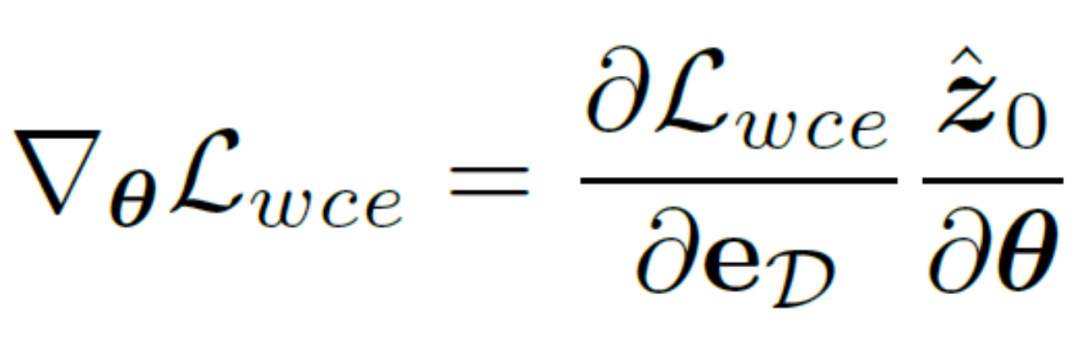
Pelaksanaan sedemikian sangat mengurangkan kos pengiraan dan membolehkan pengoptimuman langsung pada pembolehubah terpendam menggunakan fungsi kehilangan kesedaran ketidakpastian. Dengan cara ini, digabungkan dengan berat kehilangan masa yang berubah-ubah 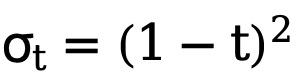 yang berubah secara adaptif dengan bilangan langkah t, objektif pengoptimuman latihan terakhir kaedah ini boleh dinyatakan sebagai:
yang berubah secara adaptif dengan bilangan langkah t, objektif pengoptimuman latihan terakhir kaedah ini boleh dinyatakan sebagai:
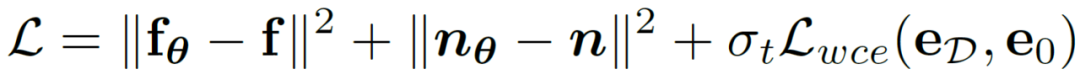
Hasil eksperimen
kaedah mempunyai empat Eksperimen telah dijalankan pada set data standard awam untuk pengesanan tepi yang digunakan secara meluas dalam bidang: BSDS, NYUDv2, Multicue dan BIPED. Memandangkan sukar untuk melabelkan data pengesanan tepi dan jumlah data berlabel adalah agak kecil, kaedah sebelumnya biasanya menggunakan pelbagai strategi untuk meningkatkan set data. Sebagai contoh, imej dalam BSDS dipertingkatkan dengan membalikkan mendatar (2×), penskalaan (3×), dan putaran (16×), menghasilkan set latihan yang 96 kali lebih besar daripada versi asal. Strategi peningkatan biasa yang digunakan oleh kaedah sebelumnya pada set data lain diringkaskan dalam Jadual 1, di mana F bermaksud flip mendatar, S bermaksud penskalaan, R bermaksud putaran, C bermaksud pemangkasan dan G bermaksud pembetulan gamma. Perbezaannya ialah kaedah ini hanya perlu menggunakan tampalan imej 320320 yang dipangkas secara rawak untuk melatih semua data. Dalam set data BSDS, kaedah ini hanya menggunakan flipping dan penskalaan rawak, dan keputusan perbandingan kuantitatifnya ditunjukkan dalam Jadual 2. Dalam set data NYUDv2, Multicue dan BIPED, kaedah itu hanya perlu dilatih dengan flip rawak. Semasa menggunakan strategi peningkatan yang lebih sedikit, kaedah ini berprestasi lebih baik daripada kaedah sebelumnya pada pelbagai set data dan pelbagai penunjuk. Dengan memerhatikan hasil ramalan dalam Rajah 3-5, kita dapat melihat bahawa DiffusionEdge boleh mempelajari dan meramalkan hasil pengesanan tepi yang hampir sama dengan taburan gt Kelebihan hasil ramalan yang tepat dan jelas adalah sangat penting untuk tugasan hiliran yang memerlukan pemurnian . , dan juga menunjukkan potensi besarnya untuk digunakan secara langsung pada tugasan seterusnya. .
 Gamb Perbandingan kualitatif kaedah berbeza pada set data BSDS
Gamb Perbandingan kualitatif kaedah berbeza pada set data BSDS
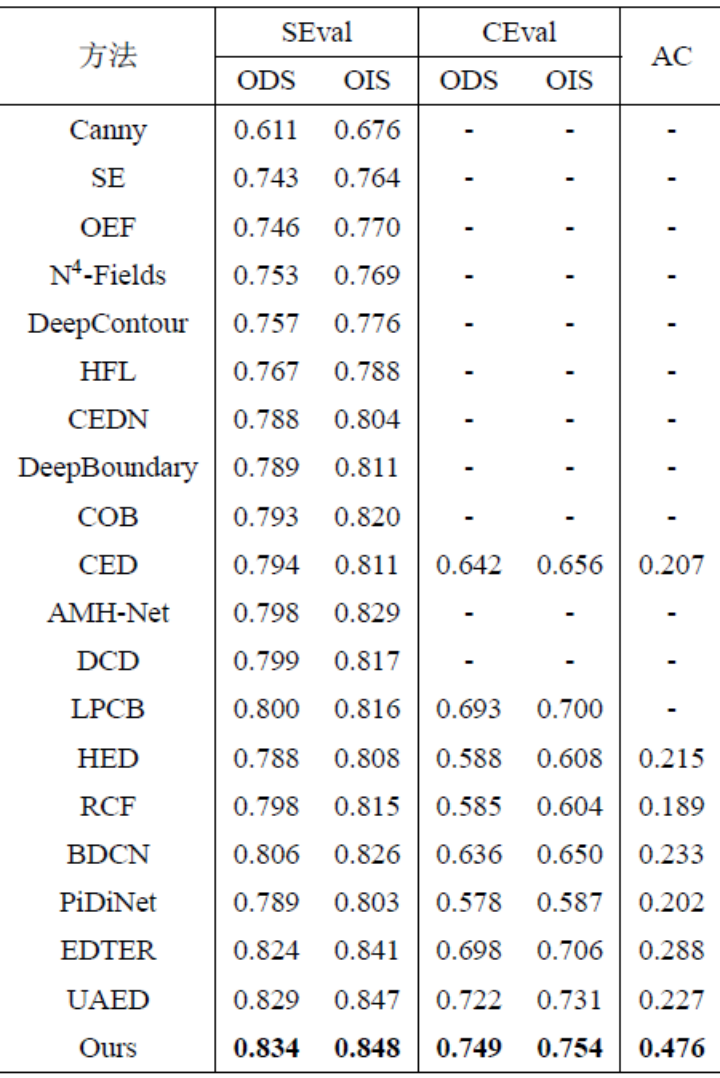 Rajah 4 Perbandingan kualitatif kaedah berbeza pada set data NYUDv2
Rajah 4 Perbandingan kualitatif kaedah berbeza pada set data NYUDv2
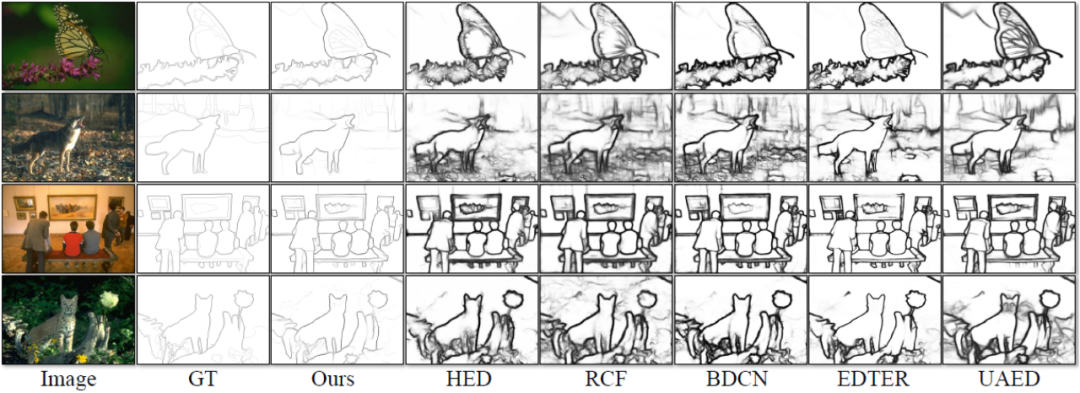 Rajah 5 Perbandingan kualitatif data ED
Rajah 5 Perbandingan kualitatif data ED
Atas ialah kandungan terperinci Tinggalkan seni bina pengekod-penyahkod dan gunakan model resapan untuk pengesanan tepi, yang lebih berkesan Universiti Teknologi Pertahanan Nasional mencadangkan DiffusionEdge. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Cara menyelesaikan MySQL tidak dapat dimulakan
Apr 08, 2025 pm 02:21 PM
Cara menyelesaikan MySQL tidak dapat dimulakan
Apr 08, 2025 pm 02:21 PM
Terdapat banyak sebab mengapa permulaan MySQL gagal, dan ia boleh didiagnosis dengan memeriksa log ralat. Penyebab umum termasuk konflik pelabuhan (periksa penghunian pelabuhan dan ubah suai konfigurasi), isu kebenaran (periksa keizinan pengguna yang menjalankan perkhidmatan), ralat fail konfigurasi (periksa tetapan parameter), rasuah direktori data (memulihkan data atau membina semula ruang meja), isu ruang jadual InnoDB (semak fail ibdata1) Apabila menyelesaikan masalah, anda harus menganalisisnya berdasarkan log ralat, cari punca utama masalah, dan mengembangkan tabiat sandaran data secara teratur untuk mencegah dan menyelesaikan masalah.
 Memahami sifat asid: tiang pangkalan data yang boleh dipercayai
Apr 08, 2025 pm 06:33 PM
Memahami sifat asid: tiang pangkalan data yang boleh dipercayai
Apr 08, 2025 pm 06:33 PM
Penjelasan terperinci mengenai atribut asid asid pangkalan data adalah satu set peraturan untuk memastikan kebolehpercayaan dan konsistensi urus niaga pangkalan data. Mereka menentukan bagaimana sistem pangkalan data mengendalikan urus niaga, dan memastikan integriti dan ketepatan data walaupun dalam hal kemalangan sistem, gangguan kuasa, atau pelbagai pengguna akses serentak. Gambaran keseluruhan atribut asid Atomicity: Transaksi dianggap sebagai unit yang tidak dapat dipisahkan. Mana -mana bahagian gagal, keseluruhan transaksi dilancarkan kembali, dan pangkalan data tidak mengekalkan sebarang perubahan. Sebagai contoh, jika pemindahan bank ditolak dari satu akaun tetapi tidak meningkat kepada yang lain, keseluruhan operasi dibatalkan. Begintransaction; UpdateAcCountSsetBalance = Balance-100Wh
 Bolehkah mysql kembali json
Apr 08, 2025 pm 03:09 PM
Bolehkah mysql kembali json
Apr 08, 2025 pm 03:09 PM
MySQL boleh mengembalikan data JSON. Fungsi JSON_EXTRACT mengekstrak nilai medan. Untuk pertanyaan yang kompleks, pertimbangkan untuk menggunakan klausa WHERE untuk menapis data JSON, tetapi perhatikan kesan prestasinya. Sokongan MySQL untuk JSON sentiasa meningkat, dan disyorkan untuk memberi perhatian kepada versi dan ciri terkini.
 Klausa had SQL Master: Kawal bilangan baris dalam pertanyaan
Apr 08, 2025 pm 07:00 PM
Klausa had SQL Master: Kawal bilangan baris dalam pertanyaan
Apr 08, 2025 pm 07:00 PM
Klausa SQLLIMIT: Kawal bilangan baris dalam hasil pertanyaan. Klausa had dalam SQL digunakan untuk mengehadkan bilangan baris yang dikembalikan oleh pertanyaan. Ini sangat berguna apabila memproses set data yang besar, paparan paginat dan data ujian, dan dapat meningkatkan kecekapan pertanyaan dengan berkesan. Sintaks Asas Sintaks: SelectColumn1, Column2, ... FROMTABLE_NAMELIMITNUMBER_OF_ROWS; Number_of_rows: Tentukan bilangan baris yang dikembalikan. Sintaks dengan Offset: SelectColumn1, Column2, ... Fromtable_namelimitoffset, Number_of_rows; Offset: Langkau
 Bagaimana untuk mengoptimumkan prestasi MySQL untuk aplikasi beban tinggi?
Apr 08, 2025 pm 06:03 PM
Bagaimana untuk mengoptimumkan prestasi MySQL untuk aplikasi beban tinggi?
Apr 08, 2025 pm 06:03 PM
Panduan Pengoptimuman Prestasi Pangkalan Data MySQL Dalam aplikasi yang berintensifkan sumber, pangkalan data MySQL memainkan peranan penting dan bertanggungjawab untuk menguruskan urus niaga besar-besaran. Walau bagaimanapun, apabila skala aplikasi berkembang, kemunculan prestasi pangkalan data sering menjadi kekangan. Artikel ini akan meneroka satu siri strategi pengoptimuman prestasi MySQL yang berkesan untuk memastikan aplikasi anda tetap cekap dan responsif di bawah beban tinggi. Kami akan menggabungkan kes-kes sebenar untuk menerangkan teknologi utama yang mendalam seperti pengindeksan, pengoptimuman pertanyaan, reka bentuk pangkalan data dan caching. 1. Reka bentuk seni bina pangkalan data dan seni bina pangkalan data yang dioptimumkan adalah asas pengoptimuman prestasi MySQL. Berikut adalah beberapa prinsip teras: Memilih jenis data yang betul dan memilih jenis data terkecil yang memenuhi keperluan bukan sahaja dapat menjimatkan ruang penyimpanan, tetapi juga meningkatkan kelajuan pemprosesan data.
 Pantau titisan mysql dan Mariadb dengan pengeksport prometheus mysql
Apr 08, 2025 pm 02:42 PM
Pantau titisan mysql dan Mariadb dengan pengeksport prometheus mysql
Apr 08, 2025 pm 02:42 PM
Pemantauan yang berkesan terhadap pangkalan data MySQL dan MariaDB adalah penting untuk mengekalkan prestasi yang optimum, mengenal pasti kemungkinan kesesakan, dan memastikan kebolehpercayaan sistem keseluruhan. Pengeksport Prometheus MySQL adalah alat yang berkuasa yang memberikan pandangan terperinci ke dalam metrik pangkalan data yang penting untuk pengurusan proaktif dan penyelesaian masalah.
 Kunci utama MySQL boleh menjadi batal
Apr 08, 2025 pm 03:03 PM
Kunci utama MySQL boleh menjadi batal
Apr 08, 2025 pm 03:03 PM
Kunci utama MySQL tidak boleh kosong kerana kunci utama adalah atribut utama yang secara unik mengenal pasti setiap baris dalam pangkalan data. Jika kunci utama boleh kosong, rekod tidak dapat dikenal pasti secara unik, yang akan membawa kepada kekeliruan data. Apabila menggunakan lajur integer sendiri atau UUIDs sebagai kunci utama, anda harus mempertimbangkan faktor-faktor seperti kecekapan dan penghunian ruang dan memilih penyelesaian yang sesuai.
 Kaedah Navicat untuk melihat kata laluan pangkalan data MongoDB
Apr 08, 2025 pm 09:39 PM
Kaedah Navicat untuk melihat kata laluan pangkalan data MongoDB
Apr 08, 2025 pm 09:39 PM
Tidak mustahil untuk melihat kata laluan MongoDB secara langsung melalui Navicat kerana ia disimpan sebagai nilai hash. Cara mendapatkan kata laluan yang hilang: 1. Tetapkan semula kata laluan; 2. Periksa fail konfigurasi (mungkin mengandungi nilai hash); 3. Semak Kod (boleh kata laluan Hardcode).
