

Analisis ringkas tentang penjadualan kumpulan linux

Sistem Linux ialah sistem pengendalian yang menyokong pelaksanaan serentak pelbagai tugas Ia boleh menjalankan berbilang proses pada masa yang sama, dengan itu meningkatkan penggunaan dan kecekapan sistem. Walau bagaimanapun, untuk membolehkan sistem Linux mencapai prestasi optimum, adalah perlu untuk memahami dan menguasai kaedah penjadualan prosesnya. Penjadualan proses merujuk kepada fungsi sistem pengendalian yang memperuntukkan sumber pemproses secara dinamik kepada proses yang berbeza berdasarkan algoritma dan strategi tertentu untuk mencapai pelaksanaan serentak pelbagai tugas. Terdapat banyak kaedah penjadualan proses dalam sistem Linux, salah satunya ialah penjadualan kumpulan. Penjadualan kumpulan ialah kaedah penjadualan proses berasaskan kumpulan yang membenarkan kumpulan proses berbeza berkongsi sumber pemproses dalam perkadaran tertentu, dengan itu mencapai keseimbangan antara keadilan dan kecekapan. Artikel ini akan menganalisis secara ringkas kaedah penjadualan kumpulan Linux, termasuk prinsip, pelaksanaan, konfigurasi, kelebihan dan keburukan penjadualan kumpulan.
cpenjadualan kumpulan dan kumpulan
Inti Linux melaksanakan fungsi kumpulan kawalan (cgroup, sejak linux 2.6.24), yang boleh menyokong proses pengumpulan dan kemudian membahagikan pelbagai sumber mengikut kumpulan. Contohnya: kumpulan-1 mempunyai 30% CPU dan 50% cakera IO, kumpulan-2 mempunyai 10% CPU dan 20% cakera IO, dan seterusnya. Sila rujuk artikel berkaitan cgroup untuk butiran.
cgroup menyokong pembahagian pelbagai jenis sumber, dan sumber CPU adalah salah satu daripadanya, yang membawa kepada penjadualan kumpulan.
Dalam kernel Linux, penjadual tradisional dijadualkan berdasarkan proses. Andaikan bahawa pengguna A dan B berkongsi mesin, yang digunakan terutamanya untuk menyusun atur cara. Kami mungkin berharap A dan B boleh berkongsi sumber CPU secara adil, tetapi jika pengguna A menggunakan make -j8 (8 threads parallel make), dan pengguna B menggunakan make secara langsung (dengan mengandaikan bahawa program make mereka menggunakan keutamaan lalai), program make pengguna A akan menjana 8 kali ganda bilangan proses sebagai pengguna B, dengan itu menduduki (kira-kira) 8 kali ganda CPU pengguna B. Oleh kerana penjadual adalah berasaskan proses, lebih banyak proses yang dimiliki pengguna A, lebih besar kebarangkalian untuk dijadualkan, dan lebih kompetitif ia terhadap CPU.
Bagaimana untuk memastikan pengguna A dan B berkongsi CPU secara adil? Penjadualan kumpulan boleh melakukan ini. Proses kepunyaan pengguna A dan B dibahagikan kepada satu kumpulan setiap satu Penjadual akan memilih satu kumpulan daripada dua kumpulan, dan kemudian memilih proses daripada kumpulan yang dipilih untuk dilaksanakan. Jika kedua-dua kumpulan mempunyai peluang yang sama untuk dipilih, maka pengguna A dan B masing-masing akan menduduki kira-kira 50% daripada CPU.
Struktur data berkaitan
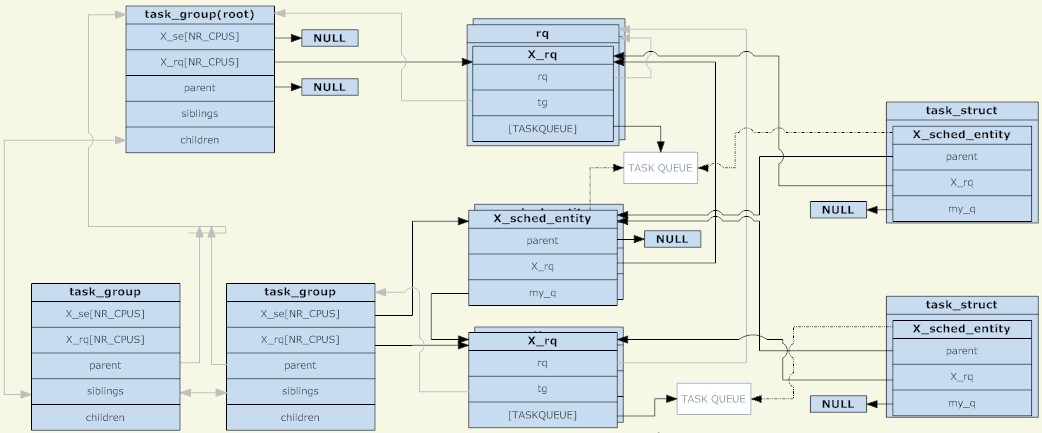
Dalam kernel Linux, struktur kumpulan_tugas digunakan untuk mengurus kumpulan untuk penjadualan kumpulan. Semua kumpulan_tugas yang sedia ada membentuk struktur pokok (sepadan dengan struktur direktori cgroup).
Kumpulan_tugas boleh mengandungi proses dengan mana-mana kategori penjadualan (khususnya, proses masa nyata dan proses biasa), jadi kumpulan_tugas perlu menyediakan satu set struktur penjadualan untuk setiap strategi penjadualan. Set struktur penjadualan yang disebut di sini terutamanya merangkumi dua bahagian, entiti penjadualan dan baris gilir larian (kedua-duanya dikongsi setiap CPU). Entiti penjadualan akan ditambahkan pada baris gilir larian Untuk kumpulan_tugas, entiti penjadualannya akan ditambahkan pada baris gilir larian kumpulan_tugas induknya.
Mengapa wujudnya entiti penjadualan? Oleh kerana terdapat dua jenis objek berjadual: kumpulan_tugas dan tugas, struktur abstrak diperlukan untuk mewakilinya. Jika entiti penjadualan mewakili kumpulan_tugas, medan my_qnya menghala ke baris gilir larian yang sepadan dengan kumpulan penjadualan ini jika tidak, medan my_q ialah NULL dan entiti penjadualan mewakili tugas. Lawan my_q dalam entiti penjadualan ialah Barisan gilir larian nod induk, iaitu baris gilir larian di mana entiti penjadualan ini harus diletakkan.
Jadi, entiti penjadualan dan baris gilir larian membentuk satu lagi struktur pokok setiap nod bukan daunnya sepadan dengan struktur pokok kumpulan_tugas dan nod daun sepadan dengan tugasan tertentu. Sama seperti proses dalam keadaan bukan TASK_RUNNING tidak akan dimasukkan ke dalam baris gilir larian, jika tiada proses dalam keadaan TASK_RUNNING dalam kumpulan, kumpulan ini (entiti penjadualan yang sepadan) tidak akan dimasukkan ke dalam baris gilir larian peringkat atasnya. Untuk menjadi jelas, selagi kumpulan penjadualan dibuat, kumpulan_tugas yang sepadan pasti akan wujud dalam struktur pepohon yang terdiri daripada kumpulan_tugas dan sama ada entiti penjadualannya wujud dalam struktur pepohon yang terdiri daripada baris gilir larian dan entiti penjadualan bergantung pada Sama ada; terdapat proses dalam keadaan TASK_RUNNING dalam kumpulan ini.
Kumpulan_tugas sebagai nod akar tidak mempunyai entiti penjadualan Penjadual sentiasa bermula dari baris gilir lariannya untuk memilih entiti penjadualan seterusnya (nod akar mestilah yang pertama dipilih, dan tiada calon lain, jadi nod akar tidak. Entiti penjadualan diperlukan). Baris gilir larian yang sepadan dengan kumpulan_tugas nod akar dibungkus dalam struktur rq, yang mengandungi bukan sahaja baris gilir larian tertentu, tetapi juga beberapa medan seperti maklumat statistik global.
Apabila penjadualan berlaku, penjadual memilih entiti penjadualan daripada baris gilir larian kumpulan_tugas akar. Jika entiti penjadualan ini mewakili kumpulan_tugas, penjadual perlu terus memilih entiti penjadualan daripada baris gilir larian yang sepadan dengan kumpulan ini. Rekursi ini berterusan sehingga satu proses dipilih. Melainkan baris gilir larian kumpulan_tugas akar kosong, satu proses pasti akan ditemui dengan mengulangi. Kerana jika baris gilir larian yang sepadan dengan kumpulan_tugas kosong, entiti penjadualannya yang sepadan tidak akan ditambahkan pada baris gilir larian yang sepadan dengan nod induknya.
Akhir sekali, untuk kumpulan_tugas, entiti penjadualan dan baris gilir larian dikongsi setiap CPU dan entiti penjadualan (bersamaan dengan kumpulan_tugas) hanya akan ditambahkan pada baris gilir larian yang sepadan dengan CPU yang sama. Untuk tugasan, terdapat hanya satu salinan entiti penjadualan (tidak dibahagikan dengan CPU Fungsi pengimbangan beban penjadual boleh mengalihkan entiti penjadualan (bersamaan dengan tugas) daripada baris gilir larian yang sepadan dengan CPU yang berbeza.
Strategi penjadualan untuk kumpulan
Struktur data utama penjadualan kumpulan telah dijelaskan, tetapi masih terdapat isu yang sangat penting di sini. Kami tahu bahawa tugas mempunyai keutamaan yang sepadan (keutamaan statik atau keutamaan dinamik), dan penjadual memilih proses dalam baris gilir larian berdasarkan keutamaan. Oleh itu, memandangkan kumpulan_tugas dan tugasan diabstraksikan ke dalam entiti penjadualan dan menerima penjadualan yang sama, bagaimanakah keutamaan kumpulan_tugas harus ditakrifkan? Soalan ini perlu dijawab secara khusus oleh kategori penjadualan (kategori penjadualan yang berbeza mempunyai takrifan keutamaan yang berbeza), khususnya rt (penjadualan masa nyata) dan cfs (penjadualan adil sepenuhnya).
Penjadualan kumpulan proses masa nyata
Seperti yang dapat dilihat daripada artikel "Analisis Ringkas Penjadualan Proses Linux", proses masa nyata ialah proses yang mempunyai keperluan masa nyata untuk CPU Keutamaannya berkaitan dengan tugas tertentu dan ditakrifkan sepenuhnya oleh pengguna . Penjadual akan sentiasa memilih proses masa nyata keutamaan tertinggi untuk dijalankan.
Dibangunkan ke dalam penjadualan kumpulan, keutamaan kumpulan ditakrifkan sebagai "keutamaan proses keutamaan tertinggi dalam kumpulan." Sebagai contoh, jika terdapat tiga proses dalam kumpulan dengan keutamaan 10, 20, dan 30, keutamaan kumpulan ialah 10 (semakin kecil nilai, lebih besar keutamaan).
Keutamaan kumpulan ditakrifkan dengan cara ini, yang membawa kepada fenomena yang menarik. Apabila tugasan dimasukkan dalam baris gilir atau dinyah gilir, semua nod nenek moyangnya mesti dinyah gilir terlebih dahulu, dan kemudiannya semula dari bawah ke atas. Oleh kerana keutamaan nod kumpulan bergantung pada nod anaknya, enqueuing dan dequeuing tugas akan mempengaruhi setiap nod nenek moyangnya.
Jadi, apabila penjadual memilih entiti penjadualan daripada kumpulan_tugas nod akar, ia sentiasa boleh mencari keutamaan tertinggi antara semua proses masa nyata dalam keadaan TASK_RUNNING di sepanjang laluan yang betul. Pelaksanaan ini kelihatan semula jadi, tetapi jika anda memikirkannya dengan teliti, apakah gunanya mengumpulkan proses masa nyata dengan cara ini? Tidak kira pengumpulan atau tidak, perkara yang perlu dilakukan oleh penjadual ialah "pilih yang mempunyai keutamaan tertinggi antara semua proses masa nyata dalam keadaan TASK_RUNNING." Nampaknya ada yang kurang di sini...
Sekarang kita perlu memperkenalkan dua fail proc dalam sistem Linux: /proc/sys/kernel/sched_rt_period_us dan /proc/sys/kernel/sched_rt_runtime_us. Kedua-dua fail ini menetapkan bahawa dalam tempoh dengan sched_rt_period_us sebagai tempoh, jumlah masa berjalan semua proses masa nyata tidak boleh melebihi sched_rt_runtime_us. Nilai lalai bagi kedua-dua fail ini ialah 1s dan 0.95s, yang bermaksud setiap saat ialah kitaran Dalam kitaran ini, jumlah masa berjalan semua proses masa nyata tidak melebihi 0.95 saat, dan baki sekurang-kurangnya 0.05. saat akan dikhaskan untuk proses biasa. Dalam erti kata lain, proses masa nyata menduduki tidak lebih daripada 95% daripada CPU. Sebelum kedua-dua fail ini muncul, tiada had untuk masa berjalan proses masa nyata Jika sentiasa ada proses masa nyata dalam keadaan TASK_RUNNING, proses biasa tidak akan dapat dijalankan. Bersamaan dengan sched_rt_runtime_us adalah sama dengan sched_rt_period_us.
Mengapa terdapat dua pembolehubah, sched_rt_runtime_us dan sched_rt_period_us? Bukankah mungkin untuk terus menggunakan pembolehubah yang mewakili peratusan penggunaan CPU? Saya fikir ini adalah kerana banyak proses masa nyata sebenarnya melakukan sesuatu secara berkala, seperti program suara menghantar paket suara setiap 20ms, program video menyegarkan bingkai setiap 40ms, dan sebagainya. Tempoh adalah penting dan hanya menggunakan nisbah penghunian CPU makro tidak dapat menerangkan dengan tepat keperluan proses masa nyata.
Penghimpunan proses masa nyata mengembangkan konsep sched_rt_runtime_us dan sched_rt_period_us Setiap kumpulan_tugasan mempunyai sched_rt_runtime_us dan sched_rt_period_us, yang memastikan bahawa proses dalam kumpulannya sendiri hanya boleh dijalankan dalam tempoh . Nisbah penghunian CPU ialah sched_rt_runtime_us/sched_rt_period_us.
Untuk kumpulan tugasan nod akar, sched_rt_runtime_us dan sched_rt_period_us adalah sama dengan nilai dalam dua fail proc di atas. Untuk nod kumpulan_tugas, dengan mengandaikan bahawa terdapat n subkumpulan penjadualan dan m proses dalam keadaan TASK_RUNNING, nisbah penghunian CPUnya ialah A dan nisbah penghunian CPU bagi n subkumpulan ini ialah B, maka B mestilah kurang daripada atau sama dengan A. , dan baki masa CPU A-B akan diperuntukkan kepada proses m dalam keadaan TASK_RUNNING. (Apa yang dibincangkan di sini ialah nisbah penghunian CPU, kerana setiap kumpulan penjadualan mungkin mempunyai nilai kitaran yang berbeza.)
Untuk melaksanakan logik sched_rt_runtime_us dan sched_rt_period_us, apabila kernel mengemas kini masa berjalan sesuatu proses (seperti kemas kini masa yang dicetuskan oleh gangguan jam berkala), kernel akan menambah masa jalan yang sepadan kepada entiti penjadualan proses semasa dan semua nod nenek moyangnya. Jika entiti penjadualan mencapai masa yang dihadkan oleh sched_rt_runtime_us, ia akan dialih keluar daripada baris gilir larian yang sepadan dan rt_rq yang sepadan akan ditetapkan kepada keadaan pendikit. Dalam keadaan ini, entiti penjadualan yang sepadan dengan rt_rq tidak akan memasuki baris gilir larian lagi. Setiap rt_rq mengekalkan pemasa berkala dengan tempoh masa sched_rt_period_us. Setiap kali pemasa dicetuskan, fungsi panggil balik yang sepadan akan menolak nilai unit sched_rt_period_us daripada masa jalan rt_rq (tetapi mengekalkan masa jalan tidak kurang daripada 0), dan kemudian memulihkan rt_rq daripada keadaan pendikit.
Ada satu lagi soalan Seperti yang dinyatakan sebelum ini, secara lalai, masa berjalan proses masa nyata dalam sistem tidak melebihi 0.95 saat sesaat. Jika permintaan sebenar untuk CPU oleh proses masa nyata adalah kurang daripada 0.95 saat (lebih daripada atau sama dengan 0 saat dan kurang daripada 0.95 saat), masa yang tinggal akan diperuntukkan kepada proses biasa. Dan jika permintaan CPU proses masa nyata lebih besar daripada 0.95 saat, ia hanya boleh berjalan selama 0.95 saat dan baki 0.05 saat akan diperuntukkan kepada proses biasa yang lain. Walau bagaimanapun, bagaimana jika tiada proses biasa perlu menggunakan CPU selama 0.05 saat ini (proses biasa yang tidak mempunyai keadaan TASK_RUNNING)? Dalam kes ini, kerana proses biasa tidak mempunyai permintaan untuk CPU, bolehkah proses masa nyata berjalan selama lebih daripada 0.95 saat? tidak boleh. Dalam baki 0.05 saat, kernel lebih suka mengekalkan CPU melahu daripada membiarkan proses masa nyata menggunakannya. Dapat dilihat bahawa sched_rt_runtime_us dan sched_rt_period_us adalah sangat wajib.
Akhir sekali, terdapat isu berbilang CPU Seperti yang dinyatakan sebelum ini, untuk setiap kumpulan_tugas, entiti penjadualan dan baris gilir dijalankan bagi setiap CPU. sched_rt_runtime_us dan sched_rt_period_us bertindak pada entiti penjadualan, jadi jika terdapat N CPU dalam sistem, had atas CPU sebenar yang diduduki oleh proses masa nyata ialah N*sched_rt_runtime_us/sched_rt_period_us. Iaitu, proses masa nyata hanya boleh berjalan selama 0.95 saat, walaupun had lalai selama satu saat. Tetapi untuk proses masa nyata, jika CPU mempunyai dua teras, ia masih boleh memenuhi permintaannya untuk menduduki 100% CPU (seperti melaksanakan gelung tak terhingga). Maka, adalah wajar bahawa 100% CPU yang diduduki oleh proses masa nyata ini harus terdiri daripada dua bahagian (setiap CPU menduduki sebahagian, tetapi tidak lebih daripada 95%). Tetapi sebenarnya, untuk mengelakkan siri masalah seperti penukaran konteks dan ketidaksahihan cache yang disebabkan oleh pemindahan proses antara CPU, entiti penjadualan pada satu CPU boleh meminjam masa daripada entiti penjadualan yang sepadan pada CPU lain. Hasilnya ialah secara makroskopik, ia bukan sahaja memenuhi had sched_rt_runtime_us, tetapi juga mengelakkan migrasi proses.
Penjadualan kumpulan proses biasa
Pada permulaan artikel, telah disebutkan bahawa dua pengguna A dan B boleh berkongsi keperluan CPU secara sama walaupun bilangan proses berbeza Walau bagaimanapun, strategi penjadualan kumpulan untuk proses masa nyata di atas nampaknya tidak relevan ini. Sebenarnya, ini adalah keperluan untuk proses biasa yang perlu dilakukan oleh penjadual kumpulan.
Berbanding dengan proses masa nyata, penjadualan kumpulan proses biasa tidak begitu khusus. Kumpulan dianggap sebagai entiti yang hampir sama dengan proses Ia mempunyai keutamaan statiknya sendiri, dan penjadual melaraskan keutamaannya secara dinamik. Bagi kumpulan, keutamaan proses dalam kumpulan tidak menjejaskan keutamaan kumpulan Keutamaan proses ini hanya dipertimbangkan apabila kumpulan dipilih oleh penjadual.
Untuk menetapkan keutamaan kumpulan, setiap kumpulan_tugas mempunyai parameter perkongsian (selari dengan dua parameter sched_rt_runtime_us dan sched_rt_period_us yang dinyatakan sebelum ini). Saham bukan keutamaan, tetapi berat entiti penjadualan (beginilah cara penjadual CFS bermain Terdapat surat-menyurat satu dengan satu antara berat dan keutamaan ini. Keutamaan proses biasa juga akan ditukar kepada berat entiti penjadualan yang sepadan, jadi boleh dikatakan bahawa saham mewakili keutamaan.
Nilai lalai saham adalah sama dengan berat yang sepadan dengan keutamaan lalai proses biasa. Jadi secara lalai, kumpulan dan proses berkongsi CPU secara sama rata.
Contoh
(Persekitaran: ubuntu 10.04, kernel 2.6.32, Intel Core2 dwi teras)
Lekapkan cgroup yang hanya membahagikan sumber CPU dan buat dua subkumpulan grp_a dan grp_b:
kouu@kouu-one:~$ sudo mkdir /dev/cgroup/cpu -p
kouu@kouu-one:~$ sudo mount -t cgroup cgroup -o cpu /dev/cgroup/cpu
kouu@kouu-one:/dev/cgroup/cpu$ cd /dev/cgroup/cpu/
kouu@kouu-one:/dev/cgroup/cpu$ mkdir grp_{a,b}
kouu@kouu-one:/dev/cgroup/cpu$ ls *
cgroup.procs cpu.rt_period_us cpu.rt_runtime_us cpu.shares notify_on_release release_agent tasks
grp_a:
cgroup.procs cpu.rt_period_us cpu.rt_runtime_us cpu.shares notify_on_release tasks
grp_b:
cgroup.procs cpu.rt_period_us cpu.rt_runtime_us cpu.shares notify_on_release tasks
Buka tiga cengkerang masing-masing, tambah grp_a pada yang pertama dan grp_b pada dua yang terakhir:
kouu@kouu-one:~/test/rtproc$ cat ttt.sh echo $1 > /dev/cgroup/cpu/$2/tasks
(为什么要用ttt.sh来写cgroup下的tasks文件呢?因为写这个文件需要root权限,当前shell没有root权限,而sudo只能赋予被它执行的程序的root权限。其实sudo sh,然后再在新开的shell里面执行echo操作也是可以的。) kouu@kouu-one:~/test1$ echo $$ 6740 kouu@kouu-one:~/test1$ sudo sh ttt.sh $$ grp_a kouu@kouu-one:~/test2$ echo $$ 9410 kouu@kouu-one:~/test2$ sudo sh ttt.sh $$ grp_b kouu@kouu-one:~/test3$ echo $$ 9425 kouu@kouu-one:~/test3$ sudo sh ttt.sh $$ grp_b
回到cgroup目录下,确认这几个shell都被加进去了:
kouu@kouu-one:/dev/cgroup/cpu$ cat grp_a/tasks 6740 kouu@kouu-one:/dev/cgroup/cpu$ cat grp_b/tasks 9410 9425
现在准备在这三个shell下同时执行一个死循环的程序(a.out),为了避免多CPU带来的影响,将进程绑定到第二个核上:
#define _GNU_SOURCE
\#include
int main()
{
cpu_set_t set;
CPU_ZERO(&set);
CPU_SET(1, &set);
sched_setaffinity(0, sizeof(cpu_set_t), &set);
while(1);
return 0;
}
编译生成a.out,然后在前面的三个shell中分别运行。三个shell分别会fork出一个子进程来执行a.out,这些子进程都会继承其父进程的cgroup分组信息。然后top一下,可以观察到属于grp_a的a.out占了50%的CPU,而属于grp_b的两个a.out各占25%的CPU(加起来也是50%):
kouu@kouu-one:/dev/cgroup/cpu$ top -c ...... PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 19854 kouu 20 0 1616 328 272 R 50 0.0 0:11.69 ./a.out 19857 kouu 20 0 1616 332 272 R 25 0.0 0:05.73 ./a.out 19860 kouu 20 0 1616 332 272 R 25 0.0 0:04.68 ./a.out ......
接下来再试试实时进程,把a.out程序改造如下:
#define _GNU_SOURCE
\#include
int main()
{
int prio = 50;
sched_setscheduler(0, SCHED_FIFO, (struct sched_param*)&prio);
while(1);
return 0;
}
然后设置grp_a的rt_runtime值:
kouu@kouu-one:/dev/cgroup/cpu$ sudo sh \# echo 300000 > grp_a/cpu.rt_runtime_us \# exit kouu@kouu-one:/dev/cgroup/cpu$ cat grp_a/cpu.rt_* 1000000 300000
现在的配置是每秒为一个周期,属于grp_a的实时进程每秒种只能执行300毫秒。运行a.out(设置实时进程需要root权限),然后top看看:
kouu@kouu-one:/dev/cgroup/cpu$ top -c ...... Cpu(s): 31.4%us, 0.7%sy, 0.0%ni, 68.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st ...... PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 28324 root -51 0 1620 332 272 R 60 0.0 0:06.49 ./a.out ......
可以看到,CPU虽然闲着,但是却不分给a.out程序使用。由于双核的原因,a.out实际的CPU占用是60%而不是30%。
其他
前段时间,有一篇“200+行Kernel补丁显著改善Linux桌面性能”的新闻比较火。这个内核补丁能让高负载条件下的桌面程序响应延迟得到大幅度降低。其实现原理是,自动创建基于TTY的task_group,所有进程都会被放置在它所关联的TTY组中。通过这样的自动分组,就将桌面程序(Xwindow会占用一个TTY)和其他终端或伪终端(各自占用一个TTY)划分开了。终端上运行的高负载程序(比如make -j64)对桌面程序的影响将大大减少。(根据前面描述的普通进程的组调度的实现可以知道,如果一个任务给系统带来了很高的负载,只会影响到与它同组的进程。这个任务包含一个或是一万个TASK_RUNNING状态的进程,对于其他组的进程来说是没有影响的。)
本文浅析了linux组调度的方法,包括组调度的原理、实现、配置和优缺点等方面。通过了解和掌握这些知识,我们可以深入理解Linux进程调度的高级知识,从而更好地使用和优化Linux系统。
Atas ialah kandungan terperinci Analisis ringkas tentang penjadualan kumpulan linux. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Apa yang sebenarnya Linux?
Apr 12, 2025 am 12:20 AM
Apa yang sebenarnya Linux?
Apr 12, 2025 am 12:20 AM
Linux sesuai untuk pelayan, persekitaran pembangunan, dan sistem tertanam. 1. Sebagai sistem pengendalian pelayan, Linux stabil dan cekap, dan sering digunakan untuk menggunakan aplikasi konkurasi tinggi. 2. Sebagai persekitaran pembangunan, Linux menyediakan alat arahan dan sistem pengurusan pakej yang cekap untuk meningkatkan kecekapan pembangunan. 3. Dalam sistem tertanam, Linux ringan dan disesuaikan, sesuai untuk persekitaran dengan sumber yang terhad.
 Menggunakan Docker dengan Linux: Panduan Komprehensif
Apr 12, 2025 am 12:07 AM
Menggunakan Docker dengan Linux: Panduan Komprehensif
Apr 12, 2025 am 12:07 AM
Menggunakan Docker di Linux dapat meningkatkan kecekapan pembangunan dan penempatan. 1. Pasang Docker: Gunakan skrip untuk memasang Docker di Ubuntu. 2. Sahkan pemasangan: Jalankan Sudodockerrunhello-World. 3. Penggunaan Asas: Buat kontena Nginx Dockerrun-Namemy-Nginx-P8080: 80-Dnginx. 4. Penggunaan Lanjutan: Buat imej tersuai, bina dan lari menggunakan Dockerfile. 5. Pengoptimuman dan amalan terbaik: Ikuti amalan terbaik untuk menulis dockerfiles menggunakan pelbagai peringkat membina dan dockercompose.
 Cara Memulakan Apache
Apr 13, 2025 pm 01:06 PM
Cara Memulakan Apache
Apr 13, 2025 pm 01:06 PM
Langkah-langkah untuk memulakan Apache adalah seperti berikut: Pasang Apache (perintah: sudo apt-get pemasangan apache2 atau muat turun dari laman web rasmi) Mula Apache (linux: Sudo Systemctl Mula Apache2; Windows: Klik kanan "Apache2.4" Perkhidmatan dan pilih "Mula") Boot secara automatik (Pilihan, Linux: Sudo Systemctl
 Apa yang Harus Dilakukan Sekiranya Pelabuhan Apache80 Diduduki
Apr 13, 2025 pm 01:24 PM
Apa yang Harus Dilakukan Sekiranya Pelabuhan Apache80 Diduduki
Apr 13, 2025 pm 01:24 PM
Apabila port Apache 80 diduduki, penyelesaiannya adalah seperti berikut: Cari proses yang menduduki pelabuhan dan tutupnya. Semak tetapan firewall untuk memastikan Apache tidak disekat. Jika kaedah di atas tidak berfungsi, sila buat semula Apache untuk menggunakan port yang berbeza. Mulakan semula perkhidmatan Apache.
 Cara Memantau Prestasi SSL Nginx di Debian
Apr 12, 2025 pm 10:18 PM
Cara Memantau Prestasi SSL Nginx di Debian
Apr 12, 2025 pm 10:18 PM
Artikel ini menerangkan bagaimana untuk memantau prestasi SSL pelayan Nginx secara berkesan pada sistem Debian. Kami akan menggunakan NginXExporter untuk mengeksport data status nginx ke Prometheus dan kemudian memaparkannya secara visual melalui Grafana. Langkah 1: Mengkonfigurasi Nginx Pertama, kita perlu mengaktifkan modul Stub_status dalam fail konfigurasi Nginx untuk mendapatkan maklumat status nginx. Tambahkan coretan berikut dalam fail konfigurasi nginx anda (biasanya terletak di /etc/nginx/nginx.conf atau termasuk fail): lokasi/nginx_status {stub_status
 Cara memulakan pemantauan oracle
Apr 12, 2025 am 06:00 AM
Cara memulakan pemantauan oracle
Apr 12, 2025 am 06:00 AM
Langkah -langkah untuk memulakan pendengar oracle adalah seperti berikut: Periksa status pendengar (menggunakan arahan status lsnrctl) untuk Windows, mulakan perkhidmatan "TNS pendengar" dalam Pengurus Perkhidmatan Oracle untuk Linux dan Unix, gunakan arahan mula lsnrctl untuk memulakan pendengar untuk menjalankan arahan status lsnrctl untuk mengesahkan bahawa pendengar itu dimulakan
 Cara Menyiapkan Bin Kitar Semula dalam Sistem Debian
Apr 12, 2025 pm 10:51 PM
Cara Menyiapkan Bin Kitar Semula dalam Sistem Debian
Apr 12, 2025 pm 10:51 PM
Artikel ini memperkenalkan dua kaedah mengkonfigurasi tong kitar semula dalam sistem Debian: antara muka grafik dan baris arahan. Kaedah 1: Gunakan antara muka grafik Nautilus untuk membuka Pengurus Fail: Cari dan mulakan Pengurus Fail Nautilus (biasanya dipanggil "Fail") dalam menu desktop atau aplikasi. Cari tong kitar semula: Cari folder bin kitar semula di bar navigasi kiri. Jika tidak dijumpai, cuba klik "Lokasi Lain" atau "Komputer" untuk mencari. Konfigurasikan Properties Bin Recycle: Klik kanan "Bin Kitar Semula" dan pilih "Properties". Dalam tetingkap Properties, anda boleh menyesuaikan tetapan berikut: Saiz maksimum: Hadkan ruang cakera yang terdapat dalam tong kitar semula. Masa pengekalan: Tetapkan pemeliharaan sebelum fail dipadamkan secara automatik di tong kitar semula
 Cara Mengoptimumkan Prestasi Debian Readdir
Apr 13, 2025 am 08:48 AM
Cara Mengoptimumkan Prestasi Debian Readdir
Apr 13, 2025 am 08:48 AM
Dalam sistem Debian, panggilan sistem Readdir digunakan untuk membaca kandungan direktori. Jika prestasinya tidak baik, cuba strategi pengoptimuman berikut: Memudahkan bilangan fail direktori: Split direktori besar ke dalam pelbagai direktori kecil sebanyak mungkin, mengurangkan bilangan item yang diproses setiap panggilan readdir. Dayakan Caching Kandungan Direktori: Bina mekanisme cache, kemas kini cache secara teratur atau apabila kandungan direktori berubah, dan mengurangkan panggilan kerap ke Readdir. Cafh memori (seperti memcached atau redis) atau cache tempatan (seperti fail atau pangkalan data) boleh dipertimbangkan. Mengamalkan struktur data yang cekap: Sekiranya anda melaksanakan traversal direktori sendiri, pilih struktur data yang lebih cekap (seperti jadual hash dan bukannya carian linear) untuk menyimpan dan mengakses maklumat direktori
