

Senarai terpaut ialah struktur data yang biasa digunakan untuk menyusun data tersusun. Ia menghubungkan satu siri nod data ke dalam rantaian data melalui penunjuk, dan merupakan kaedah pelaksanaan penting bagi jadual linear. Berbanding dengan tatasusunan, senarai terpaut adalah lebih dinamik. Apabila membina senarai terpaut, tidak perlu mengetahui jumlah data terlebih dahulu, ruang boleh diperuntukkan secara rawak dan data boleh dimasukkan atau dipadamkan dengan cekap di mana-mana lokasi dalam senarai terpaut dalam masa nyata. Overhed utama senarai terpaut ialah keterurutan akses dan kehilangan ruang untuk mengatur rantai.
Secara amnya, struktur data senarai terpaut harus mengandungi sekurang-kurangnya dua medan: medan data dan medan penunjuk. Medan data digunakan untuk menyimpan data, dan medan penunjuk digunakan untuk mewujudkan hubungan dengan nod seterusnya. Mengikut organisasi medan penunjuk dan bentuk sambungan antara setiap nod, senarai pautan boleh dibahagikan kepada pelbagai jenis seperti senarai pautan tunggal, senarai pautan berganda, senarai pautan bulat dan sebagainya. Berikut ialah gambar rajah skema bagi jenis senarai terpaut biasa ini:
Senarai terpaut tunggal ialah jenis senarai terpaut yang paling mudah Ciri-cirinya ialah hanya terdapat satu medan penunjuk yang menunjuk ke nod berikutnya (seterusnya, senarai pautan tunggal hanya boleh dilalui secara berurutan dari awal hingga akhir (biasanya penunjuk NULL). ).
Dengan mereka bentuk dua medan penunjuk pendahulu dan pengganti, senarai pautan berganda boleh dilalui dari dua arah, yang membezakannya daripada senarai pautan tunggal. Jika hubungan pergantungan antara pendahulu dan pengganti terganggu, "pokok binari" boleh dibentuk jika pendahulu nod pertama menghala ke nod ekor senarai terpaut, dan pengganti nod ekor menghala ke nod pertama; (seperti yang ditunjukkan dalam garis putus-putus dalam Rajah 2), senarai pautan bulat dibentuk ;
Ciri senarai pautan bulat ialah pengganti nod ekor menghala ke nod pertama. Gambar rajah skema senarai berpaut bulat berganda telah diberikan sebelum ini. Cirinya ialah bermula dari mana-mana nod dan dalam mana-mana arah, sebarang data dalam senarai terpaut boleh ditemui. Jika penuding pendahulu dialih keluar, ia adalah satu senarai pautan bulat.
Sebilangan besar struktur senarai terpaut digunakan dalam kernel Linux untuk mengatur data, termasuk senarai peranti dan organisasi data dalam pelbagai modul berfungsi. Kebanyakan senarai terpaut ini menggunakan struktur data senarai terpaut yang cukup menarik yang dilaksanakan dalam [include/linux/list.h]. Bahagian seterusnya artikel ini akan memperkenalkan organisasi dan penggunaan struktur data ini secara terperinci melalui contoh.
Walaupun kernel 2.6 digunakan sebagai asas untuk penjelasan di sini, sebenarnya struktur senarai terpaut dalam kernel 2.4 tidak berbeza dengan pada 2.6. Perbezaannya ialah 2.6 mengembangkan dua struktur data senarai terpaut: baca kemas kini salinan senarai terpaut (rcu) dan senarai terpaut HASH (hlist). Kedua-dua sambungan adalah berdasarkan struktur senarai paling asas Oleh itu, artikel ini terutamanya memperkenalkan struktur senarai terpaut asas, dan kemudian secara ringkas memperkenalkan rcu dan hlist.
Takrifan struktur data senarai terpaut adalah sangat mudah (dipetik daripada [include/linux/list.h], semua kod berikut, melainkan dinyatakan sebaliknya, diambil daripada fail ini):
struct list_head {
struct list_head *next, *prev;
};
Struktur list_head mengandungi dua petunjuk sebelum dan seterusnya menunjuk ke struktur list_head Ia boleh dilihat bahawa senarai terpaut kernel mempunyai fungsi senarai pautan berganda, ia biasanya disusun menjadi senarai terpaut berganda.
Berbeza daripada model struktur senarai pautan dua yang diperkenalkan dalam bahagian pertama, list_head di sini tidak mempunyai medan data. Dalam senarai terpaut kernel Linux, bukannya mengandungi data dalam struktur senarai terpaut, nod senarai terpaut terkandung dalam struktur data.
Dalam buku teks struktur data, takrif klasik senarai terpaut biasanya seperti ini (mengambil senarai pautan tunggal sebagai contoh):
struct list_node {
struct list_node *next;
ElemType data;
};
Oleh kerana ElemType, setiap jenis item data perlu menentukan struktur senarai terpautnya sendiri. Pengaturcara C++ yang berpengalaman harus tahu bahawa perpustakaan templat standard menggunakan Templat C++, yang menggunakan templat untuk mengabstrakkan antara muka operasi senarai terpaut yang bebas daripada jenis item data.
在Linux内核链表中,需要用链表组织起来的数据通常会包含一个struct list_head成员,例如在[include/linux/netfilter.h]中定义了一个nf_sockopt_ops结构来描述Netfilter为某一协议族准备的getsockopt/setsockopt接口,其中就有一个(struct list_head list)成员,各个协议族的nf_sockopt_ops结构都通过这个list成员组织在一个链表中,表头是定义在[net/core/netfilter.c]中的nf_sockopts(struct list_head)。从下图中我们可以看到,这种通用的链表结构避免了为每个数据项类型定义自己的链表的麻烦。Linux的简捷实用、不求完美和标准的风格,在这里体现得相当充分。

实际上Linux只定义了链表节点,并没有专门定义链表头,那么一个链表结构是如何建立起来的呢?让我们来看看LIST_HEAD()这个宏:
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) struct list_head name = LIST_HEAD_INIT(name)
当我们用LIST_HEAD(nf_sockopts)声明一个名为nf_sockopts的链表头时,它的next、prev指针都初始化为指向自己,这样,我们就有了一个空链表,因为Linux用头指针的next是否指向自己来判断链表是否为空:
static inline int list_empty(const struct list_head *head)
{
return head->next == head;
}
除了用LIST_HEAD()宏在声明的时候初始化一个链表以外,Linux还提供了一个INIT_LIST_HEAD宏用于运行时初始化链表:
#define INIT_LIST_HEAD(ptr) do { /
(ptr)->next = (ptr); (ptr)->prev = (ptr); /
} while (0)
我们用INIT_LIST_HEAD(&nf_sockopts)来使用它。
a) 插入
对链表的插入操作有两种:在表头插入和在表尾插入。Linux为此提供了两个接口:
static inline void list_add(struct list_head *new, struct list_head *head); static inline void list_add_tail(struct list_head *new, struct list_head *head);
因为Linux链表是循环表,且表头的next、prev分别指向链表中的第一个和最末一个节点,所以,list_add和list_add_tail的区别并不大,实际上,Linux分别用
__list_add(new, head, head->next);
和
__list_add(new, head->prev, head);
来实现两个接口,可见,在表头插入是插入在head之后,而在表尾插入是插入在head->prev之后。
假设有一个新nf_sockopt_ops结构变量new_sockopt需要添加到nf_sockopts链表头,我们应当这样操作:
list_add(&new_sockopt.list, &nf_sockopts);
从这里我们看出,nf_sockopts链表中记录的并不是new_sockopt的地址,而是其中的list元素的地址。如何通过链表访问到new_sockopt呢?下面会有详细介绍。
b) 删除
static inline void list_del(struct list_head *entry);
当我们需要删除nf_sockopts链表中添加的new_sockopt项时,我们这么操作:
list_del(&new_sockopt.list);
被剔除下来的new_sockopt.list,prev、next指针分别被设为LIST_POSITION2和LIST_POSITION1两个特殊值,这样设置是为了保证不在链表中的节点项不可访问–对LIST_POSITION1和LIST_POSITION2的访问都将引起页故障。与之相对应,list_del_init()函数将节点从链表中解下来之后,调用LIST_INIT_HEAD()将节点置为空链状态。
c) 搬移
Linux提供了将原本属于一个链表的节点移动到另一个链表的操作,并根据插入到新链表的位置分为两类:
static inline void list_move(struct list_head *list, struct list_head *head); static inline void list_move_tail(struct list_head *list, struct list_head *head);
例如list_move(&new_sockopt.list,&nf_sockopts)会把new_sockopt从它所在的链表上删除,并将其再链入nf_sockopts的表头。
d) 合并
除了针对节点的插入、删除操作,Linux链表还提供了整个链表的插入功能:
static inline void list_splice(struct list_head *list, struct list_head *head);
假设当前有两个链表,表头分别是list1和list2(都是struct list_head变量),当调用list_splice(&list1,&list2)时,只要list1非空,list1链表的内容将被挂接在list2链表上,位于list2和list2.next(原list2表的第一个节点)之间。新list2链表将以原list1表的第一个节点为首节点,而尾节点不变。如图(虚箭头为next指针):
图4 链表合并list_splice(&list1,&list2)

当list1被挂接到list2之后,作为原表头指针的list1的next、prev仍然指向原来的节点,为了避免引起混乱,Linux提供了一个list_splice_init()函数:
static inline void list_splice_init(struct list_head *list, struct list_head *head);
该函数在将list合并到head链表的基础上,调用INIT_LIST_HEAD(list)将list设置为空链。
遍历是链表最经常的操作之一,为了方便核心应用遍历链表,Linux链表将遍历操作抽象成几个宏。在介绍遍历宏之前,我们先看看如何从链表中访问到我们真正需要的数据项。
a) 由链表节点到数据项变量
我们知道,Linux链表中仅保存了数据项结构中list_head成员变量的地址,那么我们如何通过这个list_head成员访问到作为它的所有者的节点数据呢?Linux为此提供了一个list_entry(ptr,type,member)宏,其中ptr是指向该数据中list_head成员的指针,也就是存储在链表中的地址值,type是数据项的类型,member则是数据项类型定义中list_head成员的变量名,例如,我们要访问nf_sockopts链表中首个nf_sockopt_ops变量,则如此调用:
list_entry(nf_sockopts->next, struct nf_sockopt_ops, list);
这里”list”正是nf_sockopt_ops结构中定义的用于链表操作的节点成员变量名。
list_entry的使用相当简单,相比之下,它的实现则有一些难懂:
#define list_entry(ptr, type, member) container_of(ptr, type, member)
container_of宏定义在[include/linux/kernel.h]中:
#define container_of(ptr, type, member) ({ /
const typeof( ((type *)0)->member ) *__mptr = (ptr); /
(type *)( (char *)__mptr - offsetof(type,member) );})
offsetof宏定义在[include/linux/stddef.h]中:
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
size_t最终定义为unsigned int(i386)。
这里使用的是一个利用编译器技术的小技巧,即先求得结构成员在与结构中的偏移量,然后根据成员变量的地址反过来得出属主结构变量的地址。
container_of()和offsetof()并不仅用于链表操作,这里最有趣的地方是((type *)0)->member,它将0地址强制”转换”为type结构的指针,再访问到type结构中的member成员。在container_of宏中,它用来给typeof()提供参数(typeof()是gcc的扩展,和sizeof()类似),以获得member成员的数据类型;在offsetof()中,这个member成员的地址实际上就是type数据结构中member成员相对于结构变量的偏移量。
如果这么说还不好理解的话,不妨看看下面这张图:
图5 offsetof()宏的原理

对于给定一个结构,offsetof(type,member)是一个常量,list_entry()正是利用这个不变的偏移量来求得链表数据项的变量地址。
b) 遍历宏
在[net/core/netfilter.c]的nf_register_sockopt()函数中有这么一段话:
……
struct list_head *i;
……
list_for_each(i, &nf_sockopts) {
struct nf_sockopt_ops *ops = (struct nf_sockopt_ops *)i;
……
}
……
函数首先定义一个(struct list_head *)指针变量i,然后调用list_for_each(i,&nf_sockopts)进行遍历。在[include/linux/list.h]中,list_for_each()宏是这么定义的:
#define list_for_each(pos, head) / for (pos = (head)->next, prefetch(pos->next); pos != (head); / pos = pos->next, prefetch(pos->next))
它实际上是一个for循环,利用传入的pos作为循环变量,从表头head开始,逐项向后(next方向)移动pos,直至又回到head(prefetch()可以不考虑,用于预取以提高遍历速度)。
那么在nf_register_sockopt()中实际上就是遍历nf_sockopts链表。为什么能直接将获得的list_head成员变量地址当成struct nf_sockopt_ops数据项变量的地址呢?我们注意到在struct nf_sockopt_ops结构中,list是其中的第一项成员,因此,它的地址也就是结构变量的地址。更规范的获得数据变量地址的用法应该是:
struct nf_sockopt_ops *ops = list_entry(i, struct nf_sockopt_ops, list);
大多数情况下,遍历链表的时候都需要获得链表节点数据项,也就是说list_for_each()和list_entry()总是同时使用。对此Linux给出了一个list_for_each_entry()宏:
#define list_for_each_entry(pos, head, member) ……
与list_for_each()不同,这里的pos是数据项结构指针类型,而不是(struct list_head *)。nf_register_sockopt()函数可以利用这个宏而设计得更简单:
……
struct nf_sockopt_ops *ops;
list_for_each_entry(ops,&nf_sockopts,list){
……
}
……
某些应用需要反向遍历链表,Linux提供了list_for_each_prev()和list_for_each_entry_reverse()来完成这一操作,使用方法和上面介绍的list_for_each()、list_for_each_entry()完全相同。
如果遍历不是从链表头开始,而是从已知的某个节点pos开始,则可以使用list_for_each_entry_continue(pos,head,member)。有时还会出现这种需求,即经过一系列计算后,如果pos有值,则从pos开始遍历,如果没有,则从链表头开始,为此,Linux专门提供了一个list_prepare_entry(pos,head,member)宏,将它的返回值作为list_for_each_entry_continue()的pos参数,就可以满足这一要求。
在并发执行的环境下,链表操作通常都应该考虑同步安全性问题,为了方便,Linux将这一操作留给应用自己处理。Linux链表自己考虑的安全性主要有两个方面:
a) list_empty()判断
Asas list_empty() hanya menentukan sama ada senarai terpaut kosong berdasarkan sama ada penuding kepala seterusnya menghala ke senarai terpaut Linux menyediakan makro list_empty_careful(), yang pada masa yang sama menentukan penuding kepala seterusnya dan sebelumnya. jika kedua-duanya menunjuk kepada dirinya sendiri. Ini adalah terutamanya untuk menghadapi situasi di mana seterusnya dan sebelumnya tidak konsisten disebabkan CPU lain memproses senarai terpaut yang sama. Walau bagaimanapun, komen kod juga mengakui bahawa keupayaan jaminan keselamatan ini terhad: melainkan operasi senarai terpaut CPU lain hanya list_del_init(), keselamatan tidak boleh dijamin, iaitu perlindungan kunci masih diperlukan.
b) Nod dipadamkan semasa traversal
Beberapa makro untuk traversal senarai terpaut telah diperkenalkan sebelum ini. Semuanya mencapai tujuan traversal dengan menggerakkan penuding pos. Tetapi jika operasi traversal termasuk memadamkan nod yang ditunjuk oleh penuding pos, pergerakan penuding pos akan terganggu, kerana list_del(pos) akan menetapkan pos seterusnya dan sebelumnya kepada nilai khas LIST_POSITION2 dan LIST_POSITION1.
Sudah tentu, pemanggil boleh cache sendiri penuding seterusnya untuk menjadikan operasi traversal koheren, tetapi demi ketekalan pengaturcaraan, senarai terpaut Linux masih menyediakan dua antara muka "_safe" yang sepadan dengan operasi traversal asas: list_for_each_safe(pos, n, head ), list_for_each_entry_safe(pos, n, head, member), mereka memerlukan pemanggil untuk memberikan satu lagi penunjuk n jenis yang sama seperti pos, dan menyimpan sementara alamat nod pos seterusnya dalam gelung for untuk mengelakkan ralat yang disebabkan oleh pelepasan nod pos.
Senarai dan hlist Rajah 6
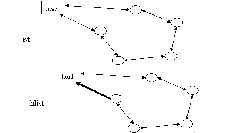
Pereka senarai pautan Linux yang berusaha untuk kecemerlangan (kerana list.h tidak ditandatangani, jadi mungkin Linus Torvalds) percaya bahawa senarai dua pautan berkepala dua (seterusnya, sebelumnya) adalah "terlalu membazir" untuk HASH jadual, jadi dia mereka set berasingan Struktur data hlist yang digunakan dalam jadual HASH ialah senarai terpaut pekeliling berganda pengepala tunggal Seperti yang dapat dilihat daripada rajah di atas, pengepala hlist hanya mempunyai penunjuk ke nod pertama dan tiada penunjuk ke nod ekor Ini mungkin masalah besar Pengepala yang disimpan dalam jadual HASH boleh mengurangkan penggunaan ruang sebanyak separuh.
Oleh kerana struktur data pengepala dan nod adalah berbeza, jika operasi sisipan berlaku antara pengepala dan nod pertama, kaedah sebelumnya tidak akan berfungsi: penunjuk pertama pengepala mesti diubah suai untuk menghala ke nod yang baru dimasukkan , tetapi ia tidak boleh digunakan seperti list_add( ) perihalan bersatu sedemikian. Atas sebab ini, prev nod hlist bukan lagi penunjuk ke nod sebelumnya, tetapi penunjuk ke seterusnya (pertama untuk pengepala) dalam nod sebelumnya (mungkin pengepala) (struct list_head **pprev), oleh itu The operasi memasukkan di kepala jadual boleh mengakses dan mengubah suai penunjuk seterusnya (atau pertama) nod pendahulu melalui "*(node->pprev)" yang konsisten.
Terdapat juga satu siri makro yang berakhir dengan "_rcu" dalam antara muka fungsi senarai terpaut Linux, yang sepadan dengan banyak fungsi yang diperkenalkan di atas. RCU (Read-Copy Update) ialah teknologi baharu yang diperkenalkan dalam kernel 2.5/2.6 yang meningkatkan prestasi penyegerakan dengan melengahkan operasi tulis.
Kami tahu bahawa terdapat lebih banyak operasi membaca data daripada operasi menulis dalam sistem, dan prestasi mekanisme rwlock akan menurun dengan cepat apabila bilangan pemproses meningkat dalam persekitaran SMP (lihat Rujukan 4). Sebagai tindak balas kepada latar belakang aplikasi ini, Paul E. McKenney dari Pusat Teknologi Linux IBM mencadangkan teknologi "kemas kini salinan baca" dan menggunakannya pada kernel Linux. Teras teknologi RCU ialah operasi tulis dibahagikan kepada dua langkah: tulis dan kemas kini, membenarkan operasi baca diakses pada bila-bila masa tanpa menyekat Apabila sistem mempunyai operasi tulis, tindakan kemas kini ditangguhkan sehingga semua operasi baca dihidupkan data selesai. Fungsi RCU dalam senarai terpaut Linux hanyalah sebahagian kecil daripada RCU Linux Analisis pelaksanaan RCU adalah di luar skop artikel ini penggunaan senarai pautan asas Pada asasnya sama.
Untuk kesederhanaan, contoh menggunakan templat program mod pengguna Jika anda perlu menjalankannya, anda boleh menggunakan arahan berikut untuk menyusunnya:
gcc -D__KERNEL__ -I/usr/src/linux-2.6.7/include pfile.c -o pfile
因为内核链表限制在内核态使用,但实际上对于数据结构本身而言并非只能在核态运行,因此,在笔者的编译中使用”-D__KERNEL__”开关”欺骗”编译器。
Atas ialah kandungan terperinci Analisis terperinci senarai terpaut kernel Linux. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



