

Inti Linux mengandungi 4 jenis penjadual IO, iaitu penjadual Noop IO, penjadual IO Anticipatory, penjadual IO Tarikh Akhir dan penjadual IO CFQ.
Biasanya, kelewatan baca dan tulis cakera disebabkan oleh kepala bergerak ke silinder. Untuk menyelesaikan kelewatan ini, kernel terutamanya menggunakan dua strategi: caching dan algoritma penjadualan IO.
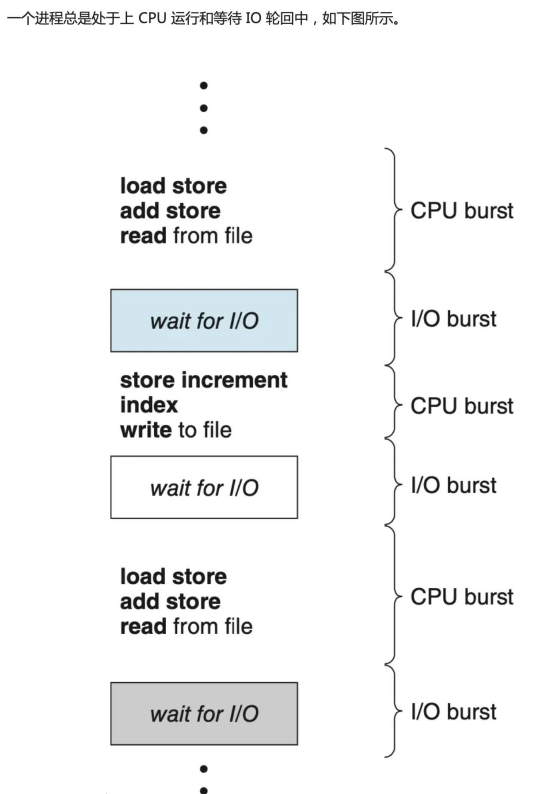
IO Scheduler (IO Scheduler) ialah kaedah yang digunakan oleh sistem pengendalian untuk menentukan susunan operasi IO diserahkan pada peranti blok. Terdapat dua tujuan kewujudan, satu adalah untuk meningkatkan daya pemprosesan IO, dan satu lagi adalah untuk mengurangkan masa tindak balas IO.
Walau bagaimanapun, pemprosesan IO dan masa tindak balas IO selalunya bercanggah Untuk mengimbangi kedua-duanya sebanyak mungkin, penjadual IO menyediakan pelbagai algoritma penjadualan untuk menyesuaikan diri dengan senario permintaan IO yang berbeza. Antaranya, algoritma yang paling berfaedah untuk senario membaca dan menulis rawak seperti pangkalan data ialah DEANLINE.
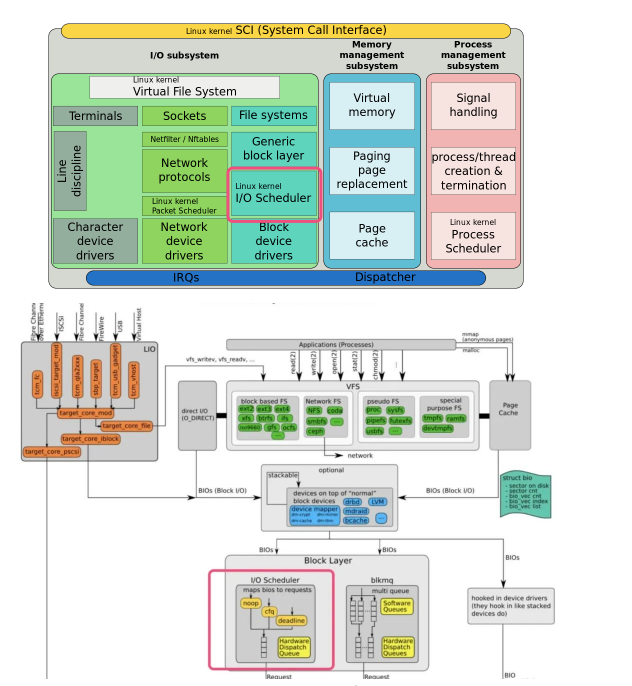
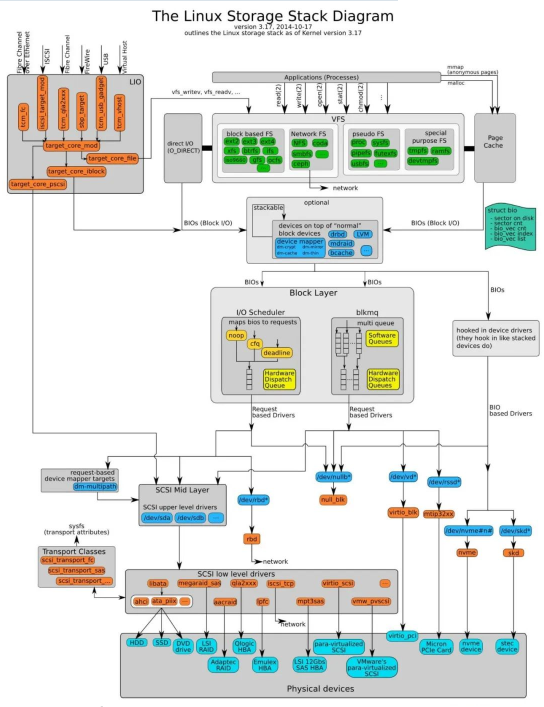
Lokasi penjadual IO dalam timbunan kernel adalah seperti berikut:
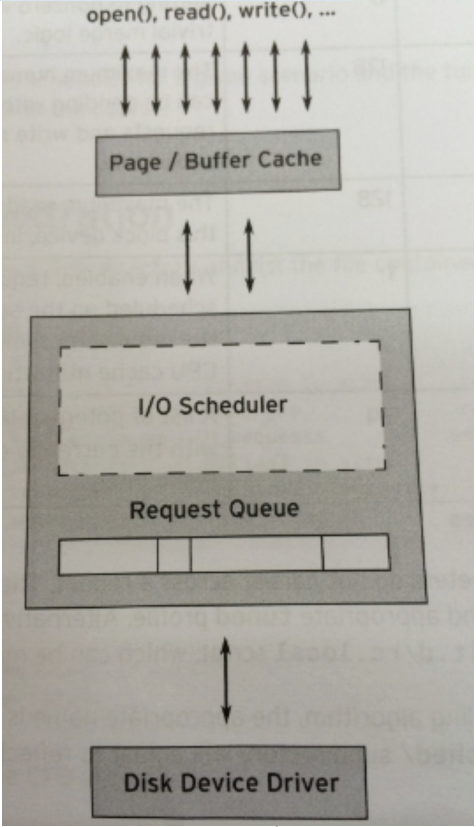
Perkara yang paling tragis tentang peranti blok ialah putaran cakera, yang merupakan proses yang sangat memakan masa. Setiap peranti blok atau partition peranti blok sepadan dengan baris gilir permintaannya sendiri (request_queue), dan setiap baris gilir permintaan boleh memilih penjadual I/O untuk menyelaraskan permintaan yang diserahkan.
Tujuan asas penjadual I/O adalah untuk mengatur permintaan mengikut nombor sektor yang sepadan pada peranti blok untuk mengurangkan pergerakan kepala dan meningkatkan kecekapan. Permintaan dalam baris gilir permintaan setiap peranti akan dibalas mengikut urutan.
Malah, sebagai tambahan kepada baris gilir ini, setiap penjadual sendiri mengekalkan bilangan baris gilir yang berbeza untuk memproses permintaan yang diserahkan, dan permintaan di bahagian atas baris gilir akan dialihkan ke baris gilir permintaan dalam masa terdekat untuk menunggu jawapan.

Fungsi utama penjadual IO adalah untuk mengurangkan keperluan untuk putaran cakera. Terutamanya dicapai melalui 2 cara:
Setiap peranti akan mempunyai baris gilir permintaan sendiri yang sepadan, dan semua permintaan akan berada dalam baris gilir permintaan sebelum diproses. Apabila permintaan baharu datang, jika didapati lokasi permintaan ini bersebelahan dengan permintaan sebelumnya, maka ia boleh digabungkan menjadi satu permintaan.
Jika yang digabungkan tidak ditemui, ia akan diisih mengikut arah putaran cakera. Biasanya peranan penjadual IO adalah untuk menggabungkan dan mengisih tanpa menjejaskan masa pemprosesan permintaan tunggal terlalu banyak.
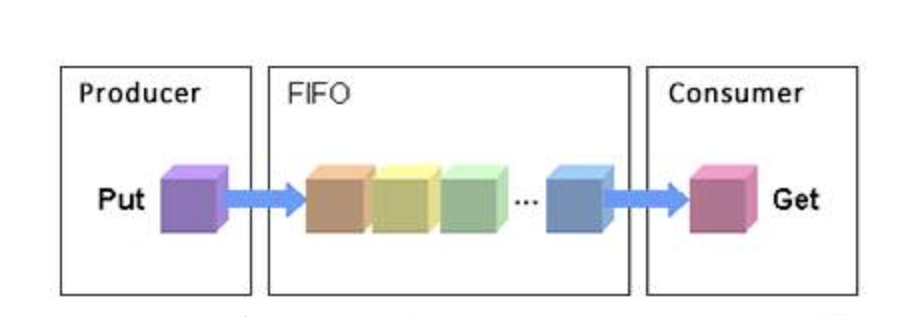
FIFO
Masukkan permintaan input dan output ke dalam baris gilir FIFO, dan kemudian laksanakan permintaan input dan output dalam baris gilir mengikut urutan: Apabila permintaan baharu datang:
Jika boleh dicantumkan, cantumkannya
Jika ia tidak boleh digabungkan, ia akan cuba menyusun. Jika permintaan pada baris gilir sudah sangat lama, permintaan baharu ini tidak boleh melompat ke dalam baris gilir dan hanya boleh diletakkan di penghujung. Jika tidak, masukkan ke dalam kedudukan yang sesuai
Jika ia tidak boleh digabungkan dan tiada kedudukan yang sesuai untuk dimasukkan, ia akan diletakkan di hujung barisan permintaan.
Senario yang boleh digunakan
4.1 Dalam senario di mana anda tidak mahu mengubah suai susunan permintaan input dan output
4.2 Peranti dengan algoritma penjadualan yang lebih pintar di bawah input dan output, seperti peranti storan NAS
4.3 Permintaan input dan output bagi aplikasi lapisan atas telah dioptimumkan dengan teliti
4.4 Peranti cakera kepala tidak berputar, seperti cakera SSD
Algoritma CFQ (Completely Fair Queuing), seperti namanya, adalah algoritma yang benar-benar adil. Ia cuba memperuntukkan baris gilir permintaan dan kepingan masa kepada semua proses yang bersaing untuk mendapatkan hak untuk menggunakan peranti blok Dalam hirisan masa yang diberikan kepada proses oleh penjadual, proses boleh menghantar permintaan baca dan tulisnya ke peranti blok asas. . Apabila potongan masa proses digunakan Setelah selesai, baris gilir permintaan proses akan digantung, menunggu penjadualan.
Sekian masa setiap proses dan panjang baris gilir setiap proses bergantung pada keutamaan IO proses Setiap proses akan mempunyai keutamaan IO, dan penjadual CFQ akan menggunakannya sebagai salah satu faktor untuk dipertimbangkan untuk menentukan proses. Apabila baris gilir permintaan boleh mendapatkan hak untuk menggunakan peranti blok.
Keutamaan IO boleh dibahagikan kepada tiga kategori dari tinggi ke rendah:
RT(masa nyata)
BE(cubaan terbaik)
IDLE(terbiar)
RT dan BE boleh dibahagikan lagi kepada 8 sub-keutamaan. Anda boleh melihat dan mengubah suainya melalui ionice. Lebih tinggi keutamaan, lebih awal ia diproses, lebih banyak kepingan masa digunakan untuk proses ini, dan lebih banyak permintaan boleh diproses pada satu masa.
Malah, kami sudah tahu bahawa kewajaran penjadual CFQ adalah untuk proses, dan hanya permintaan segerak (baca atau syn write) wujud untuk proses itu akan dimasukkan ke dalam baris gilir permintaan proses itu sendiri, dan semua permintaan Asynchronous dengannya keutamaan yang sama, tidak kira dari mana prosesnya, akan dimasukkan ke dalam baris gilir biasa Terdapat sejumlah 8 (RT) + 8 (BE) + 1 (IDLE) = 17 baris gilir permintaan tak segerak.
Bermula dari Linux 2.6.18, CFQ digunakan sebagai algoritma penjadualan IO lalai. Untuk pelayan tujuan umum, CFQ ialah pilihan yang lebih baik. Algoritma penjadualan khusus yang akan digunakan mesti dipilih berdasarkan penanda aras yang mencukupi berdasarkan senario perniagaan tertentu dan tidak boleh diputuskan semata-mata oleh kata-kata orang lain.
TAMAT AKHIR menyelesaikan situasi melampau permintaan IO kebuluran berdasarkan CFQ.
Selain baris gilir pengisihan IO yang dimiliki oleh CFQ sendiri, DEADLINE juga menyediakan baris gilir FIFO untuk membaca IO dan menulis IO.
Masa menunggu maksimum untuk membaca baris gilir FIFO ialah 500ms, dan masa menunggu maksimum untuk menulis baris gilir FIFO ialah 5s (sudah tentu parameter ini boleh ditetapkan secara manual).
Keutamaan permintaan IO dalam baris gilir FIFO adalah lebih tinggi daripada dalam baris gilir CFQ, dan keutamaan baris gilir FIFO yang dibaca adalah lebih tinggi daripada keutamaan baris gilir tulis FIFO. Keutamaan boleh dinyatakan seperti berikut:
“
FIFO(Baca) > FIFO(Tulis) > CFQ
”
Algoritma tarikh akhir menjamin masa tunda minimum untuk permintaan IO yang diberikan Daripada pemahaman ini, ia sepatutnya sangat sesuai untuk aplikasi DSS.
tarikh akhir sebenarnya adalah penambahbaikan pada Lif:
1. Elakkan beberapa permintaan yang tidak dapat diproses terlalu lama.
2. Bezakan antara operasi baca dan operasi tulis.
tarikh akhir IO mengekalkan 3 barisan. Barisan pertama adalah sama seperti Lif, cuba mengisih mengikut lokasi fizikal. Barisan kedua dan barisan ketiga kedua-duanya disusun mengikut masa Perbezaannya ialah satu operasi baca dan satu lagi operasi tulis.
Tarikh akhir IO membezakan antara membaca dan menulis kerana pereka bentuk percaya bahawa jika aplikasi menghantar permintaan baca, ia secara amnya akan menyekat di sana dan menunggu sehingga hasilnya dikembalikan. Permintaan tulis biasanya bukan permintaan aplikasi untuk menulis ke memori, dan kemudian proses latar belakang menulisnya kembali ke cakera. Permohonan biasanya tidak menunggu sehingga penulisan selesai sebelum meneruskan. Jadi permintaan baca harus mempunyai keutamaan yang lebih tinggi daripada permintaan tulis.
Di bawah reka bentuk ini, setiap permintaan baharu akan diletakkan dalam baris gilir pertama Algoritma adalah sama seperti Lif, dan juga akan ditambahkan pada penghujung baris gilir baca atau tulis. Dengan cara ini, kami mula-mula memproses beberapa permintaan daripada baris gilir pertama, dan pada masa yang sama mengesan sama ada beberapa permintaan pertama dalam baris gilir kedua/ketiga telah menunggu terlalu lama Jika mereka telah melebihi ambang, mereka akan diproses. Ambang ini ialah 5ms untuk permintaan baca dan 5s untuk permintaan tulis.
Secara peribadi, saya fikir adalah lebih baik untuk tidak menggunakan partition jenis ini untuk merekod log perubahan pangkalan data, seperti log dalam talian Oracle, binlog MySQL, dsb. Kerana permintaan tulis jenis ini biasanya memanggil fsync. Sekiranya penulisan tidak dapat disiapkan, ia juga akan mempengaruhi prestasi aplikasi.
CFQ dan DEADLINE fokus pada memenuhi permintaan IO yang berselerak. Untuk permintaan IO berterusan, seperti bacaan berurutan, tiada pengoptimuman.
Untuk memenuhi senario campuran IO rawak dan IO berjujukan, Linux turut menyokong algoritma penjadualan ANTICIPATORY. Berdasarkan DEADLINE, ANTICIPATORY menetapkan tetingkap masa menunggu 6ms untuk setiap IO yang dibaca. Jika OS menerima permintaan IO baca dari lokasi bersebelahan dalam 6ms ini, ia boleh dipenuhi dengan serta-merta.
Pilihan algoritma penjadual IO bergantung pada kedua-dua ciri perkakasan dan senario aplikasi.
Pada cakera SAS tradisional, CFQ, DEADLINE dan ANTICIPATORY semuanya adalah pilihan yang baik untuk pelayan pangkalan data khusus, DEADLINE berfungsi dengan baik dalam masa pemprosesan dan tindak balas.
Walau bagaimanapun, pada pemacu keadaan pepejal yang muncul seperti SSD dan Fusion IO, NOOP yang paling mudah mungkin merupakan algoritma terbaik, kerana pengoptimuman tiga algoritma lain adalah berdasarkan memendekkan masa pencarian, dan pemacu keadaan pepejal tidak mempunyai apa- dipanggil mencari masa Dan masa tindak balas IO adalah sangat singkat.
Atas ialah kandungan terperinci Fahami empat algoritma penjadualan IO utama kernel Linux dalam satu artikel. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



