

Artikel ini ialah kajian tentang meningkatkan skala pengoptimuman pesanan sifar Kod tersebut telah menjadi sumber terbuka dan kertas itu telah diterima oleh ICLR 2024.
Hari ini saya ingin memperkenalkan kertas kerja bertajuk "DeepZero: Scaling up Zeroth-Order Optimization for Deep Model Training", yang telah disiapkan dengan kerjasama Michigan State University dan Lawrence Livermore National Laboratory. Kertas kerja ini baru-baru ini diterima oleh persidangan ICLR 2024, dan pasukan penyelidik telah menjadikan kod sumber terbuka. Matlamat utama kertas ini adalah untuk melanjutkan teknik pengoptimuman tertib sifar dalam latihan model pembelajaran mendalam. Pengoptimuman tertib sifar ialah kaedah pengoptimuman yang tidak bergantung pada maklumat kecerunan dan boleh mengendalikan ruang parameter berdimensi tinggi dan struktur model yang kompleks dengan lebih baik. Walau bagaimanapun, kaedah pengoptimuman tertib sifar sedia ada menghadapi cabaran skala dan kecekapan apabila berurusan dengan model pembelajaran mendalam. Untuk menangani cabaran ini, pasukan penyelidik mencadangkan rangka kerja DeepZero. Rangka kerja ini boleh mengendalikan latihan model pembelajaran mendalam berskala besar dengan cekap dengan memperkenalkan strategi pensampelan baharu dan mekanisme pelarasan penyesuaian. DeepZero mengambil kesempatan daripada pengoptimuman pesanan sifar dan menggabungkan teknologi pengkomputeran dan penyejajaran teragih untuk mempercepatkan latihan

Alamat kertas: https://arxiv.org/abs/2210.
alamat: https://arxiv.org/abs/2210Zeroth-Order (ZO) telah menjadi penyelesaian kepada pembelajaran mesin (Pembelajaran Mesin) Teknik yang popular untuk masalah, terutamanya di mana maklumat tertib pertama (FO) sukar atau tidak tersedia:
: Model pembelajaran mesin mungkin digabungkan dengan simulator atau eksperimen yang kompleks Interaksi yang sistem asasnya tidak boleh dibezakan.
: Apabila model pembelajaran mendalam (Pembelajaran Dalam) disepadukan dengan API pihak ketiga, seperti serangan lawan dan pertahanan terhadap model pembelajaran dalam kotak hitam, dan pembelajaran segera kotak hitam perkhidmatan model bahasa.
: Mekanisme perambatan balik prinsip yang digunakan untuk mengira kecerunan tertib pertama mungkin tidak disokong apabila melaksanakan model pembelajaran mendalam pada sistem perkakasan.
2. Anggaran kecerunan pesanan sifar: RGE atau CGE?
Pengoptimum tertib sifar berinteraksi dengan fungsi objektif hanya dengan menyerahkan input dan menerima nilai fungsi yang sepadan. Terdapat dua kaedah penganggaran kecerunan utama: Anggaran Kecerunan Koordinat (CGE) dan Anggaran Kecerunan Rawak (RGE), seperti yang ditunjukkan di bawah:
 di mana
di mana
(contohnya, Anggaran saraf bagi kecerunan tertib pertama daripada parameter model rangkaian). 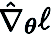
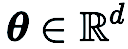 Dalam (RGE),
Dalam (RGE),
ialah saiz gangguan (juga dikenali sebagai parameter pelicinan q ialah bilangan arah rawak yang digunakan untuk mendapatkan terhingga; perbezaan. 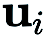
Dalam (CGE), 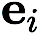 mewakili vektor asas piawai dan
mewakili vektor asas piawai dan 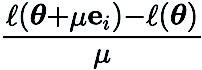 memberikan anggaran perbezaan terhingga bagi terbitan separa
memberikan anggaran perbezaan terhingga bagi terbitan separa 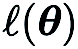 pada koordinat yang sepadan.
pada koordinat yang sepadan.
Berbanding dengan CGE, RGE mempunyai fleksibiliti untuk mengurangkan bilangan penilaian fungsi. Walaupun kecekapan pertanyaannya yang tinggi, masih tidak pasti sama ada RGE boleh memberikan ketepatan yang memuaskan apabila melatih model mendalam dari awal. Untuk tujuan ini, kami menjalankan penyiasatan di mana kami melatih rangkaian neural convolutional kecil (CNN) dengan saiz yang berbeza pada CIFAR-10 menggunakan RGE dan CGE. Seperti yang ditunjukkan dalam rajah di bawah, CGE boleh mencapai ketepatan ujian setanding dengan latihan pengoptimuman pesanan pertama, dan jauh lebih baik daripada RGE. Ia juga lebih cekap masa daripada RGE.
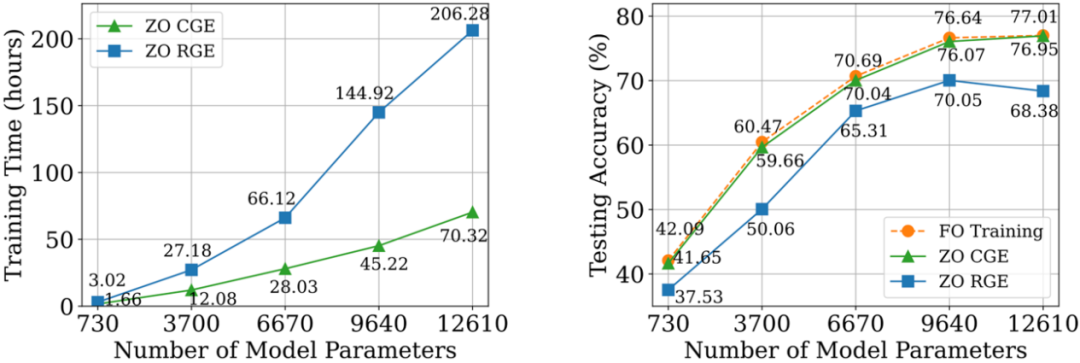
Berdasarkan kelebihan CGE berbanding RGE dari segi ketepatan dan kecekapan pengiraan, Kami memilih CGE sebagai penganggar kecerunan pesanan sifar pilihan. Walau bagaimanapun, kerumitan pertanyaan CGE kekal sebagai hambatan kerana ia berskala dengan saiz model.
3. Rangka kerja pembelajaran mendalam tersusun sifar: DeepZero
Setakat pengetahuan kami, tiada kerja sebelum ini telah menunjukkan keberkesanan pengoptimuman ZO tanpa mengurangkan prestasi dengan ketara semasa melatih rangkaian saraf dalam (DNN). Untuk mengatasi halangan ini, kami membangunkan DeepZero, rangka kerja pembelajaran mendalam pengoptimuman tertib sifar berprinsip yang boleh melanjutkan pengoptimuman tertib sifar kepada latihan rangkaian saraf dari awal.
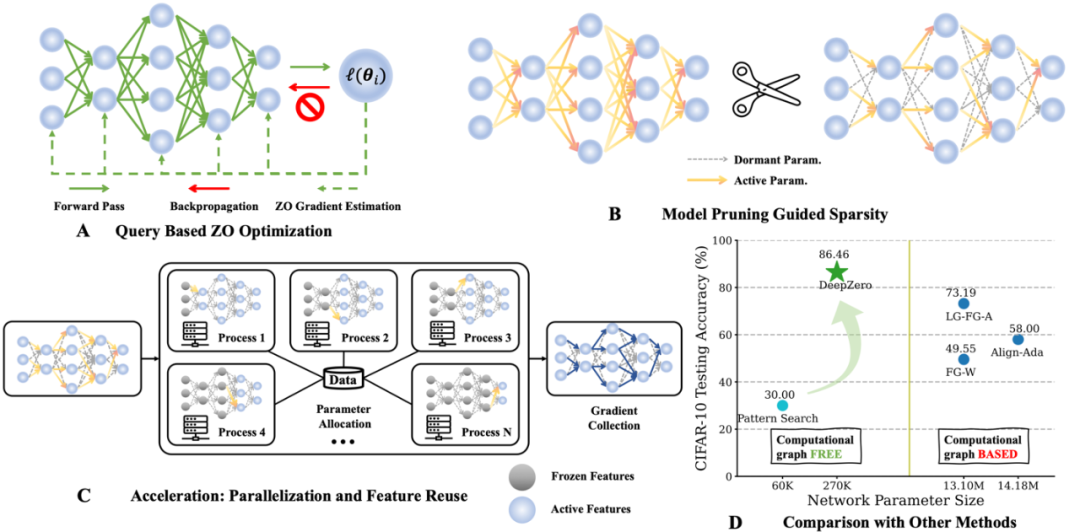
a) Pemangkasan model tertib sifar (ZO-GraSP): Rangkaian saraf padat yang dimulakan secara rawak selalunya mengandungi sub-rangkaian jarang berkualiti tinggi. Walau bagaimanapun, kaedah pemangkasan yang paling berkesan termasuk latihan model sebagai langkah perantaraan. Oleh itu, mereka tidak sesuai untuk mencari sparsity melalui pengoptimuman pesanan sifar. Untuk menangani cabaran di atas, kami diilhamkan oleh kaedah pemangkasan tanpa latihan yang dipanggil pemangkasan permulaan. Antara kaedah tersebut, Gradient Signal Preserving (GraSP) telah dipilih, iaitu kaedah untuk mengenal pasti keterlaluan sebelum rangkaian neural dengan memulakan aliran kecerunan rangkaian secara rawak.
b) Kecerunan Jarang: Untuk mengekalkan manfaat ketepatan model padat latihan, dalam CGE kami menggabungkan keterukan kecerunan dan bukannya keterukan berat. Ini memastikan kami melatih model padat dalam ruang berat, dan bukannya melatih model jarang. Khususnya, kami menggunakan ZO-GraSP untuk menentukan Nisbah Pemangkasan (LPR) dari segi lapisan yang boleh menangkap kebolehmampatan DNN, dan kemudian pengoptimuman tertib sifar boleh melatih model padat dengan mengemas kini secara berterusan berat parameter model separa , di mana nisbah kecerunan jarang adalah ditentukan oleh LPR.
c) Penggunaan semula ciri: Memandangkan CGE mengganggu setiap elemen parameter, ia boleh menggunakan semula ciri sejurus sebelum lapisan gangguan dan melakukan baki operasi perambatan ke hadapan dan bukannya bermula dari lapisan input. Secara empirik, CGE dengan penggunaan semula ciri boleh mencapai lebih daripada 2x pengurangan masa latihan.
d) Pejajaran laluan hadapan: CGE menyokong penyelarasan latihan model. Sifat penyahgandingan ini memungkinkan untuk menskalakan penyebaran ke hadapan merentasi mesin teragih, meningkatkan kelajuan latihan tertib sifar dengan ketara.
4. Analisis eksperimen
a) Klasifikasi imej
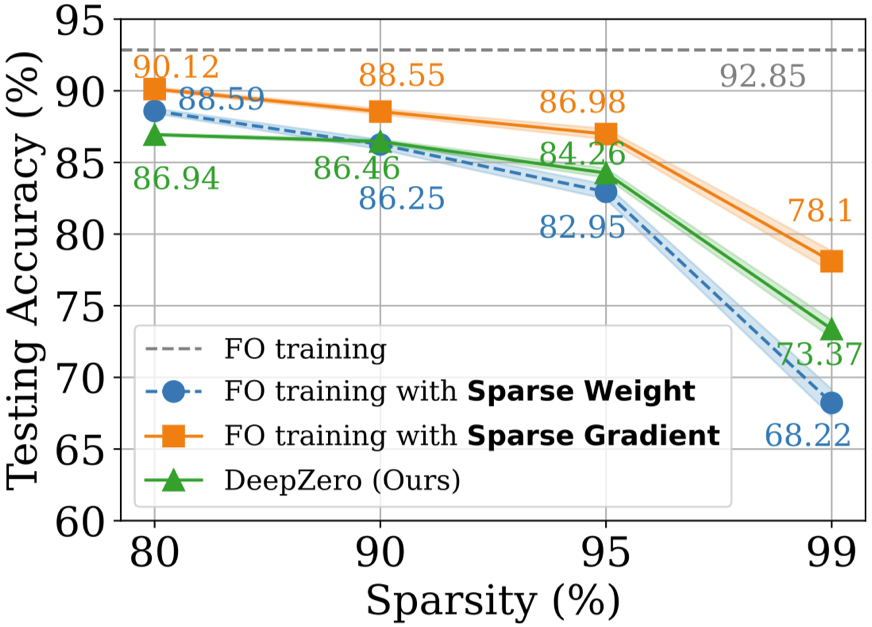
Pada set data CIFAR-10, kami membandingkan ResNet-20 yang dilatih oleh DeepZero dengan dua varian yang dilatih oleh pengoptimuman tertib pertama:
-20 diperolehi melalui latihan pengoptimuman pesanan pertama (2) Sparse ResNet-20 diperolehi melalui FO-GraSP melalui latihan pengoptimuman pesanan pertama seperti yang ditunjukkan di bawah, walaupun pada 80% hingga 99% jarang Dalam selang, berbanding dengan (1) , model yang dilatih menggunakan DeepZero masih mempunyai jurang ketepatan. Ini menyerlahkan cabaran pengoptimuman ZO untuk latihan model mendalam, di mana pelaksanaan sparsity tinggi diingini. Perlu diingat bahawa DeepZero mengatasi prestasi (2) dalam selang jarak 90% hingga 99%,menunjukkan keunggulan keterlaluan kecerunan berbanding ketersedian berat dalam DeepZero
.
 b) Pertahanan kotak hitam
b) Pertahanan kotak hitam
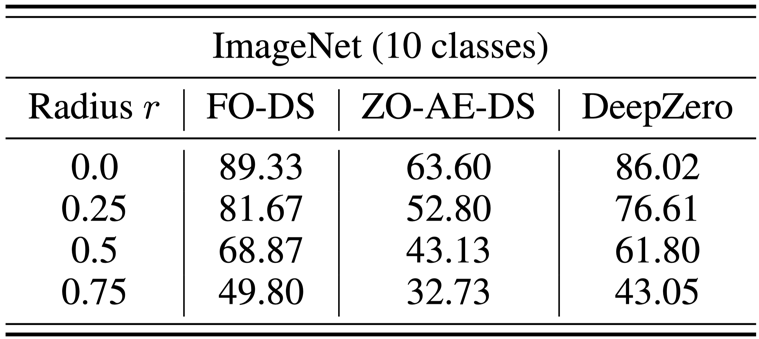
Masalah pertahanan kotak hitam berlaku apabila pemilik model tidak mahu berkongsi butiran model dengan pemain pertahanan. Ini menimbulkan cabaran kepada algoritma peningkatan kekukuhan sedia ada yang secara langsung meningkatkan model kotak putih menggunakan latihan pengoptimuman pesanan pertama. Untuk mengatasi cabaran ini, ZO-AE-DS dicadangkan, yang memperkenalkan AutoEncoder (AE) antara operasi pertahanan menghaluskan (DS) denoising kotak putih dan pengelas imej kotak hitam untuk menyelesaikan cabaran ZO Dimensi latihan. ZO-AE-DS mempunyai kelemahan iaitu sukar untuk menskalakan kepada set data resolusi tinggi (cth., ImageNet), kerana menggunakan AE menjejaskan ketepatan input imej kepada pengelas imej kotak hitam dan mengakibatkan prestasi pertahanan yang lemah. Sebaliknya, DeepZero boleh belajar terus operasi pertahanan disepadukan dengan pengelas kotak hitam, tanpa memerlukan pengekod automatik. Seperti yang ditunjukkan dalam jadual di bawah, DeepZero secara konsisten mengatasi prestasi ZO-AE-DS merentas semua jejari gangguan input dari segi Ketepatan Disahkan (CA).
c) Pembelajaran mendalam ditambah dengan simulasi
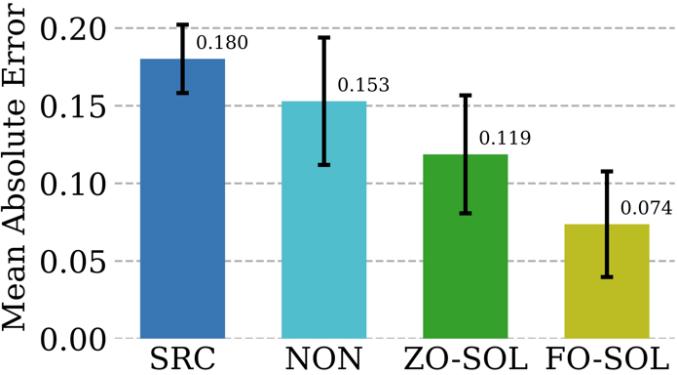
Kaedah berangka amat diperlukan dalam menyediakan simulasi bermaklumat fizikal, tetapi mereka mempunyai cabarannya sendiri: pendiskretan tidak dapat tidak menjana ralat berangka. Kebolehlaksanaan membetulkan rangkaian saraf melalui latihan interaktif kitaran dengan penyelesai Persamaan Pembezaan Separa (PDE) berulang dipanggil Solver-in-the-Loop (SOL). Walaupun kerja sedia ada memfokuskan pada menggunakan atau membangunkan simulator boleh dibezakan untuk latihan model, Kami melanjutkan SOL dengan memanfaatkan DeepZero untuk membolehkan penggunaan dengan simulator tidak boleh dibezakan atau kotak hitam. Jadual berikut membandingkan prestasi pembetulan ralat ujian ZO-SOL (dilaksanakan oleh DeepZero) dengan tiga kaedah berbeza yang boleh dibezakan:
(1) SRC (simulasi ketelitian rendah tanpa pembetulan ralat
(2) NON ( Bukan- latihan interaktif, dilakukan di luar gelung simulasi menggunakan data simulasi rendah dan ketelitian tinggi pra-dihasilkan
(3) FO-SOL (untuk latihan peringkat pertama SOL diberikan simulator boleh dibezakan).
Ralat bagi setiap simulasi ujian dikira sebagai ralat mutlak min (MAE) bagi simulasi yang diperbetulkan berbanding dengan simulasi ketepatan tinggi. Keputusan menunjukkan bahawa ZO-SOL yang dilaksanakan melalui DeepZero masih mengatasi prestasi SRC dan NON dan menutup jurang prestasi dengan FO-SOL walaupun dengan hanya akses simulator berasaskan pertanyaan. Prestasi ZO-SOL berbanding NON menyerlahkan janji ZO-SOL apabila terdapat penyepaduan simulator kotak hitam.
5. Ringkasan dan Perbincangan
Kertas kerja ini memperkenalkan rangka kerja pembelajaran mendalam yang dioptimumkan sifar (DeepZero) untuk latihan rangkaian mendalam. Secara khusus, DeepZero menyepadukan anggaran kecerunan koordinat, kecerunan kecerunan yang dibawa oleh pemangkasan model tertib sifar, penggunaan semula ciri dan selari laluan hadapan ke dalam proses latihan bersatu. Dengan memanfaatkan inovasi ini, DeepZero telah menunjukkan kecekapan dan keberkesanan dalam tugas termasuk klasifikasi imej dan pelbagai senario pembelajaran mendalam kotak hitam praktikal. Selain itu, kebolehgunaan DeepZero pada kawasan lain diterokai, seperti aplikasi yang melibatkan entiti fizikal yang tidak boleh dibezakan, dan latihan pada peranti yang graf pengiraan dan pengiraan perambatan belakang tidak disokong.
Pengenalan kepada pengarang
Zhang Yimeng, calon PhD dalam sains komputer di Makmal OPTML Universiti Michigan minat penyelidikannya termasuk Generatif AI, Multi-Modality, Computer Vision, Safe AI, dan Efficient AI.
Atas ialah kandungan terperinci ICLR 2024 |. Rangka kerja pembelajaran mendalam teroptimum tertib sifar pertama, MSU dan LLNL mencadangkan DeepZero. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



