
 Peranti teknologi
AI
Ajar anda langkah demi langkah cara melaksanakan model bahasa seni bina pakar (MoE) campuran yang jarang dari awal
Peranti teknologi
AI
Ajar anda langkah demi langkah cara melaksanakan model bahasa seni bina pakar (MoE) campuran yang jarang dari awal
Ajar anda langkah demi langkah cara melaksanakan model bahasa seni bina pakar (MoE) campuran yang jarang dari awal

Artikel ini memperkenalkan kaedah melaksanakan model bahasa pakar campuran jarang (MoE), dan menerangkan proses pelaksanaan model secara terperinci, termasuk menggunakan pakar campuran jarang untuk menggantikan rangkaian neural feedforward tradisional, untuk mencapai gating atas-k dan hingar Top-k gating, dan teknologi permulaan Kaiming He. Penulis juga menggambarkan elemen yang kekal tidak berubah daripada seni bina makemore, seperti pemprosesan set data, prapemprosesan tokenisasi dan tugas pemodelan bahasa. Akhir sekali, pautan repositori GitHub disediakan untuk keseluruhan proses pelaksanaan model Ia adalah buku teks praktikal yang jarang berlaku.
Pengenalan
Model pakar campuran (MoE) mula mendapat perhatian meluas selepas dikeluarkan, terutamanya dalam model bahasa pakar campuran yang jarang. Walaupun kebanyakan komponen adalah serupa dengan transformer tradisional, terdapat beberapa isu dengan kestabilan latihan model bahasa pakar campuran yang jarang, walaupun kelihatan agak mudah. Kaedah pelaksanaan KPM berskala kecil yang boleh dikonfigurasikan ini diperkenalkan dalam blog oleh Hugging Face, yang mungkin sangat membantu penyelidik yang ingin mencuba dengan cepat kaedah baharu. Blog ini juga menyediakan kod terperinci berdasarkan PyTorch, yang boleh didapati di pautan ini: https://github.com/AviSoori1x/makeMoE/tree/main. Pelaksanaan berskala kecil sebegini membantu penyelidik menjalankan eksperimen pantas dalam bidang ini. Laman web ini telah menyusun ini untuk manfaat pembaca. Artikel ini membuat beberapa perubahan berdasarkan seni bina makemore:- Gunakan pakar pencampuran yang jarang dan bukannya rangkaian saraf suapan hadapan yang berasingan
; menggunakan kaedah pemula Kaiming He, tetapi fokus artikel ini adalah pada kaedah pemula yang boleh disesuaikan, termasuk pemilihan kaedah pemula seperti Xavier/Glorot.
Pada masa yang sama, modul berikut konsisten dengan makemore: - set data, bahagian prapemprosesan (pembahagian perkataan) dan tugas pemodelan bahasa yang asalnya dipilih oleh Andrej - menjana kandungan teks dalam gaya Shakespeare
- Gelung latihan
- Logik inferens
- Mekanisme pelaksanaan akan diperkenalkan langkah demi langkah
Mekanisme Perhatian Produk Titik Berskala Berskala
#This code is borrowed from Andrej Karpathy's makemore repository linked in the repo.The self attention layers in Sparse mixture of experts models are the same asin regular transformer modelstorch.manual_seed(1337)B,T,C = 4,8,32 # batch, time, channelsx = torch.randn(B,T,C)# let's see a single Head perform self-attentionhead_size = 16key = nn.Linear(C, head_size, bias=False)query = nn.Linear(C, head_size, bias=False)value = nn.Linear(C, head_size, bias=False)k = key(x) # (B, T, 16)q = query(x) # (B, T, 16)wei =q @ k.transpose(-2, -1) # (B, T, 16) @ (B, 16, T) ---> (B, T, T)tril = torch.tril(torch.ones(T, T))#wei = torch.zeros((T,T))wei = wei.masked_fill(tril == 0, float('-inf'))wei = F.softmax(wei, dim=-1) #B,T,Tv = value(x) #B,T,Hout = wei @ v # (B,T,T) @ (B,T,H) -> (B,T,H)out.shape
torch.Size([4, 8, 16])
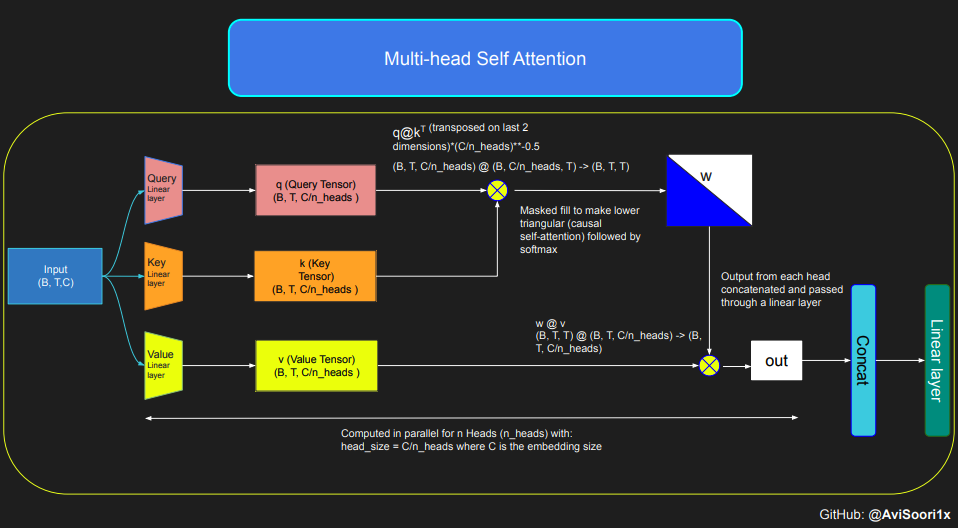 Kemudian, kod perhatian kendiri sebab-akibat dan perhatian kendiri sebab berbilang kepala boleh diatur seperti berikut. Perhatian kendiri berbilang kepala menggunakan berbilang kepala perhatian secara selari, dengan setiap kepala perhatian memfokuskan semata-mata pada sebahagian saluran (dimensi benam). Perhatian diri berbilang kepala pada asasnya meningkatkan proses pembelajaran dan meningkatkan kecekapan latihan model kerana keupayaan selari yang wujud. Kod berikut menggunakan keciciran untuk regularisasi untuk mengelakkan pemasangan berlebihan. . , setiap kawasan pengubah Mekanisme perhatian diri dalam blok kekal tidak berubah. Walau bagaimanapun, struktur setiap blok berubah secara mendadak:
Kemudian, kod perhatian kendiri sebab-akibat dan perhatian kendiri sebab berbilang kepala boleh diatur seperti berikut. Perhatian kendiri berbilang kepala menggunakan berbilang kepala perhatian secara selari, dengan setiap kepala perhatian memfokuskan semata-mata pada sebahagian saluran (dimensi benam). Perhatian diri berbilang kepala pada asasnya meningkatkan proses pembelajaran dan meningkatkan kecekapan latihan model kerana keupayaan selari yang wujud. Kod berikut menggunakan keciciran untuk regularisasi untuk mengelakkan pemasangan berlebihan. . , setiap kawasan pengubah Mekanisme perhatian diri dalam blok kekal tidak berubah. Walau bagaimanapun, struktur setiap blok berubah secara mendadak:
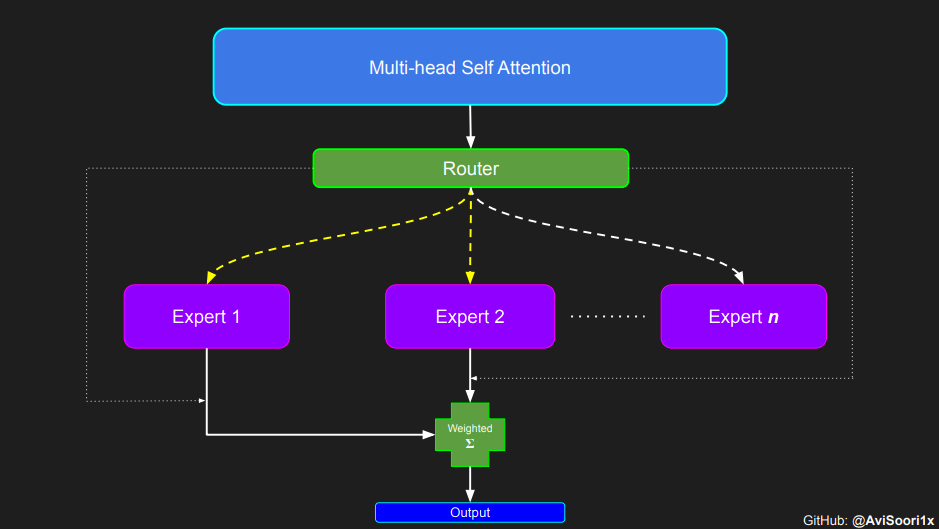
digantikan dengan berbilang rangkaian suapan hadapan yang jarang diaktifkan (iaitu rangkaian pakar). Apa yang dipanggil "pengaktifan jarang" bermakna setiap token dalam jujukan hanya diberikan kepada bilangan pakar yang terhad (biasanya satu atau dua).
这有助于提高训练和推理速度,因为每次前向传递都会激活少数专家。不过,所有专家都必须存在 GPU 内存中,因此当参数总数达到数千亿甚至数万亿时,就会产生部署方面的问题。
#Expert moduleclass Expert(nn.Module):""" An MLP is a simple linear layer followed by a non-linearity i.e. each Expert """def __init__(self, n_embd):super().__init__()self.net = nn.Sequential(nn.Linear(n_embd, 4 * n_embd),nn.ReLU(),nn.Linear(4 * n_embd, n_embd),nn.Dropout(dropout),)def forward(self, x): return self.net(x)
Top-k 门控的一个例子
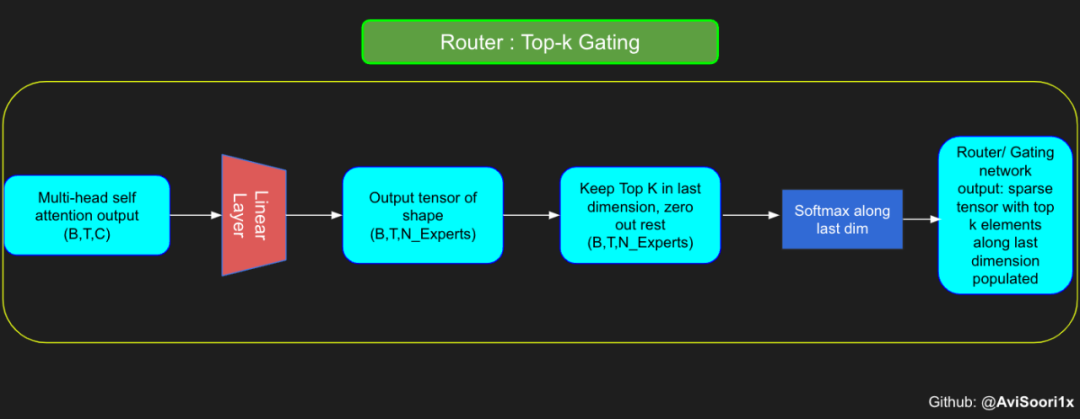
门控网络,也称为路由,确定哪个专家网络接收来自多头注意力的 token 的输出。举个例子解释路由的机制,假设有 4 个专家,token 需要被路由到前 2 个专家中。首先需要通过线性层将 token 输入到门控网络中。该层将对应于(Batch size,Tokens,n_embed)的输入张量从(2,4,32)维度,投影到对应于(Batch size、Tokens,num_expert)的新形状:(2、4,4)。其中 n_embed 是输入的通道维度,num_experts 是专家网络的计数。
接下来,沿最后一个维度,找出最大的前两个值及其相应的索引。
#Understanding how gating worksnum_experts = 4top_k=2n_embed=32#Example multi-head attention output for a simple illustrative example, consider n_embed=32, context_length=4 and batch_size=2mh_output = torch.randn(2, 4, n_embed)topkgate_linear = nn.Linear(n_embed, num_experts) # nn.Linear(32, 4)logits = topkgate_linear(mh_output)top_k_logits, top_k_indices = logits.topk(top_k, dim=-1)# Get top-k expertstop_k_logits, top_k_indices
#output:(tensor([[[ 0.0246, -0.0190],[ 0.1991,0.1513],[ 0.9749,0.7185],[ 0.4406, -0.8357]], [[ 0.6206, -0.0503],[ 0.8635,0.3784],[ 0.6828,0.5972],[ 0.4743,0.3420]]], grad_fn=<TopkBackward0>), tensor([[[2, 3],[2, 1],[3, 1],[2, 1]], [[0, 2], [0, 3], [3, 2], [3, 0]]]))
通过仅保留沿最后一个维度进行比较的前 k 大的值,来获得稀疏门控的输出。用负无穷值填充其余部分,在使用 softmax 激活函数。负无穷会被映射至零,而最大的前两个值会更加突出,且和为 1。要求和为 1 是为了对专家输出的内容进行加权。
zeros = torch.full_like(logits, float('-inf')) #full_like clones a tensor and fills it with a specified value (like infinity) for masking or calculations.sparse_logits = zeros.scatter(-1, top_k_indices, top_k_logits)sparse_logits
#outputtensor([[[ -inf,-inf,0.0246, -0.0190], [ -inf,0.1513,0.1991,-inf], [ -inf,0.7185,-inf,0.9749], [ -inf, -0.8357,0.4406,-inf]],[[ 0.6206,-inf, -0.0503,-inf], [ 0.8635,-inf,-inf,0.3784], [ -inf,-inf,0.5972,0.6828], [ 0.3420,-inf,-inf,0.4743]]], grad_fn=<ScatterBackward0>)
gating_output= F.softmax(sparse_logits, dim=-1)gating_output
#ouputtensor([[[0.0000, 0.0000, 0.5109, 0.4891], [0.0000, 0.4881, 0.5119, 0.0000], [0.0000, 0.4362, 0.0000, 0.5638], [0.0000, 0.2182, 0.7818, 0.0000]],[[0.6617, 0.0000, 0.3383, 0.0000], [0.6190, 0.0000, 0.0000, 0.3810], [0.0000, 0.0000, 0.4786, 0.5214], [0.4670, 0.0000, 0.0000, 0.5330]]], grad_fn=<SoftmaxBackward0>)
使用有噪声的 top-k 门控以实现负载平衡
# First define the top k router moduleclass TopkRouter(nn.Module):def __init__(self, n_embed, num_experts, top_k):super(TopkRouter, self).__init__()self.top_k = top_kself.linear =nn.Linear(n_embed, num_experts) def forward(self, mh_ouput):# mh_ouput is the output tensor from multihead self attention blocklogits = self.linear(mh_output)top_k_logits, indices = logits.topk(self.top_k, dim=-1)zeros = torch.full_like(logits, float('-inf'))sparse_logits = zeros.scatter(-1, indices, top_k_logits)router_output = F.softmax(sparse_logits, dim=-1) return router_output, indices
接下来使用下面这段代码来测试程序:
#Testing this out:num_experts = 4top_k = 2n_embd = 32mh_output = torch.randn(2, 4, n_embd)# Example inputtop_k_gate = TopkRouter(n_embd, num_experts, top_k)gating_output, indices = top_k_gate(mh_output)gating_output.shape, gating_output, indices#And it works!!
#output(torch.Size([2, 4, 4]), tensor([[[0.5284, 0.0000, 0.4716, 0.0000],[0.0000, 0.4592, 0.0000, 0.5408],[0.0000, 0.3529, 0.0000, 0.6471],[0.3948, 0.0000, 0.0000, 0.6052]], [[0.0000, 0.5950, 0.4050, 0.0000], [0.4456, 0.0000, 0.5544, 0.0000], [0.7208, 0.0000, 0.0000, 0.2792], [0.0000, 0.0000, 0.5659, 0.4341]]], grad_fn=<SoftmaxBackward0>), tensor([[[0, 2],[3, 1],[3, 1],[3, 0]], [[1, 2], [2, 0], [0, 3], [2, 3]]]))
尽管最近发布的 mixtral 的论文没有提到这一点,但本文的作者相信有噪声的 Top-k 门控机制是训练 MoE 模型的一个重要工具。从本质上讲,不会希望所有的 token 都发送给同一组「受欢迎」的专家网络。人们需要的是能在开发和探索之间取得良好平衡。为此,为了负载平衡,从门控的线性层向 logits 激活函数添加标准正态噪声是有帮助的,这使训练更有效率。
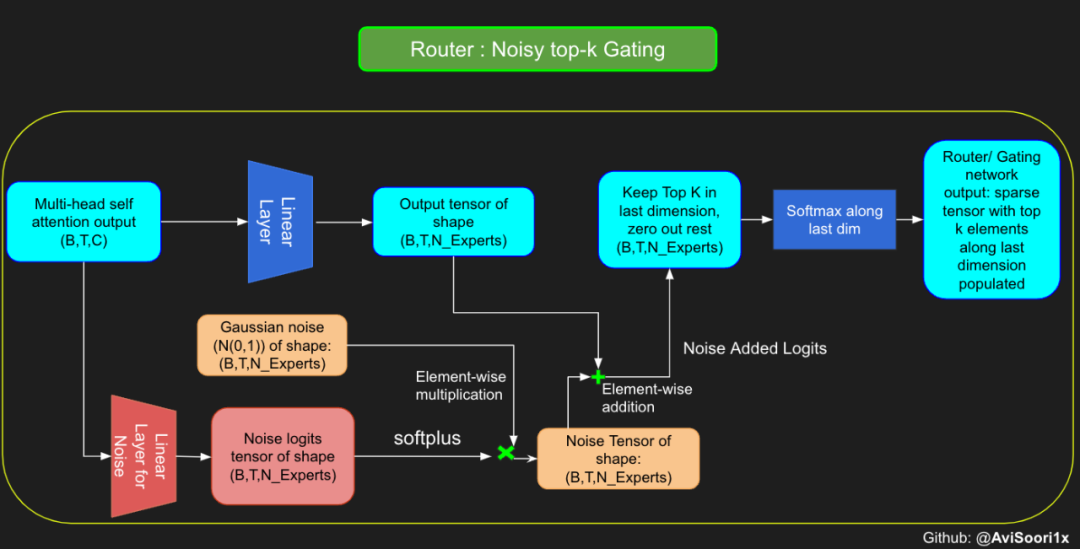
#Changing the above to accomodate noisy top-k gatingclass NoisyTopkRouter(nn.Module):def __init__(self, n_embed, num_experts, top_k):super(NoisyTopkRouter, self).__init__()self.top_k = top_k#layer for router logitsself.topkroute_linear = nn.Linear(n_embed, num_experts)self.noise_linear =nn.Linear(n_embed, num_experts)def forward(self, mh_output):# mh_ouput is the output tensor from multihead self attention blocklogits = self.topkroute_linear(mh_output)#Noise logitsnoise_logits = self.noise_linear(mh_output)#Adding scaled unit gaussian noise to the logitsnoise = torch.randn_like(logits)*F.softplus(noise_logits)noisy_logits = logits + noisetop_k_logits, indices = noisy_logits.topk(self.top_k, dim=-1)zeros = torch.full_like(noisy_logits, float('-inf'))sparse_logits = zeros.scatter(-1, indices, top_k_logits)router_output = F.softmax(sparse_logits, dim=-1) return router_output, indices
再次尝试代码:
#Testing this out, again:num_experts = 8top_k = 2n_embd = 16mh_output = torch.randn(2, 4, n_embd)# Example inputnoisy_top_k_gate = NoisyTopkRouter(n_embd, num_experts, top_k)gating_output, indices = noisy_top_k_gate(mh_output)gating_output.shape, gating_output, indices#It works!!
#output(torch.Size([2, 4, 8]), tensor([[[0.4181, 0.0000, 0.5819, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],[0.4693, 0.5307, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],[0.0000, 0.4985, 0.5015, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],[0.0000, 0.0000, 0.0000, 0.2641, 0.0000, 0.7359, 0.0000, 0.0000]], [[0.0000, 0.0000, 0.0000, 0.6301, 0.0000, 0.3699, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000, 0.4766, 0.0000, 0.0000, 0.0000, 0.5234], [0.0000, 0.0000, 0.0000, 0.6815, 0.0000, 0.0000, 0.3185, 0.0000], [0.4482, 0.5518, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000]]], grad_fn=<SoftmaxBackward0>), tensor([[[2, 0],[1, 0],[2, 1],[5, 3]], [[3, 5], [7, 3], [3, 6], [1, 0]]]))
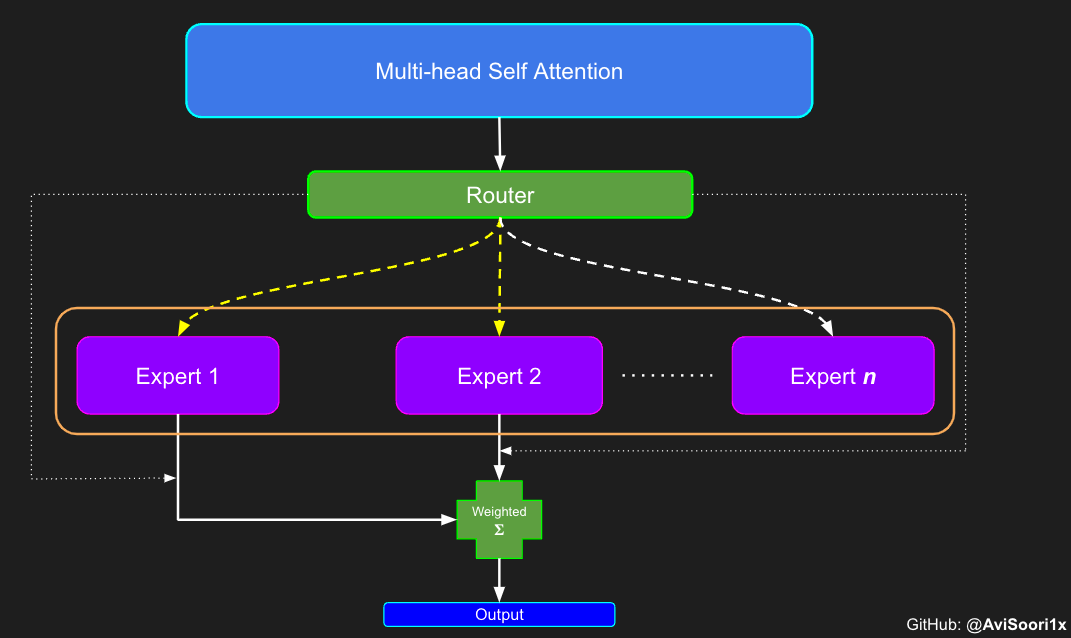
创建稀疏化的混合专家模块
在获得门控网络的输出结果之后,对于给定的 token,将前 k 个值选择性地与来自相应的前 k 个专家的输出相乘。这种选择性乘法的结果是一个加权和,该加权和构成 SparseMoe 模块的输出。这个过程的关键和难点是避免不必要的乘法运算,只为前 k 名专家进行正向转播。为每个专家执行前向传播将破坏使用稀疏 MoE 的目的,因为这个过程将不再是稀疏的。
class SparseMoE(nn.Module):def __init__(self, n_embed, num_experts, top_k):super(SparseMoE, self).__init__()self.router = NoisyTopkRouter(n_embed, num_experts, top_k)self.experts = nn.ModuleList([Expert(n_embed) for _ in range(num_experts)])self.top_k = top_kdef forward(self, x):gating_output, indices = self.router(x)final_output = torch.zeros_like(x)# Reshape inputs for batch processingflat_x = x.view(-1, x.size(-1))flat_gating_output = gating_output.view(-1, gating_output.size(-1))# Process each expert in parallelfor i, expert in enumerate(self.experts):# Create a mask for the inputs where the current expert is in top-kexpert_mask = (indices == i).any(dim=-1)flat_mask = expert_mask.view(-1)if flat_mask.any():expert_input = flat_x[flat_mask]expert_output = expert(expert_input)# Extract and apply gating scoresgating_scores = flat_gating_output[flat_mask, i].unsqueeze(1)weighted_output = expert_output * gating_scores# Update final output additively by indexing and addingfinal_output[expert_mask] += weighted_output.squeeze(1) return final_output
运行以下代码来用样本测试上述实现,可以看到确实如此!
import torchimport torch.nn as nn#Let's test this outnum_experts = 8top_k = 2n_embd = 16dropout=0.1mh_output = torch.randn(4, 8, n_embd)# Example multi-head attention outputsparse_moe = SparseMoE(n_embd, num_experts, top_k)final_output = sparse_moe(mh_output)print("Shape of the final output:", final_output.shape)Shape of the final output: torch.Size([4, 8, 16])
需要强调的是,如上代码所示,从路由 / 门控网络输出的 top_k 本身也很重要。索引确定了被激活的专家是哪些, 对应的值又决定了权重大小。下图进一步解释了加权求和的概念。
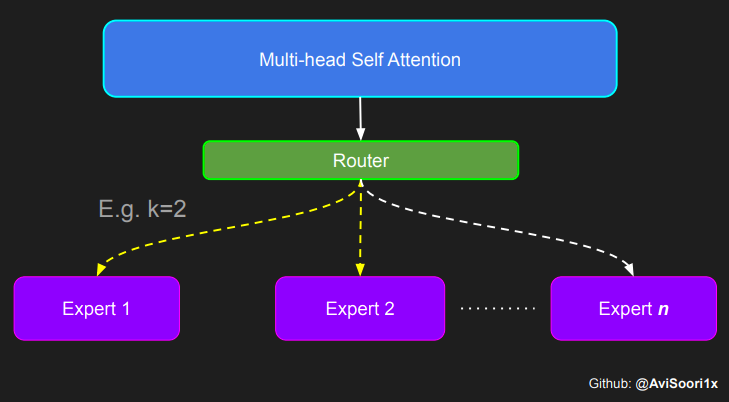
模块整合
将多头自注意力和稀疏混合专家相结合,形成稀疏混合专家 transformer 块。就像在 vanilla transformer 块中一样,也要使用残差以确保训练稳定,并避免梯度消失等问题。此外,要采用层归一化来进一步稳定学习过程。
#Create a self attention + mixture of experts block, that may be repeated several number of timesclass Block(nn.Module):""" Mixture of Experts Transformer block: communication followed by computation (multi-head self attention + SparseMoE) """def __init__(self, n_embed, n_head, num_experts, top_k):# n_embed: embedding dimension, n_head: the number of heads we'd likesuper().__init__()head_size = n_embed // n_headself.sa = MultiHeadAttention(n_head, head_size)self.smoe = SparseMoE(n_embed, num_experts, top_k)self.ln1 = nn.LayerNorm(n_embed)self.ln2 = nn.LayerNorm(n_embed)def forward(self, x):x = x + self.sa(self.ln1(x))x = x + self.smoe(self.ln2(x)) return x
最后,将所有内容整合在一起,形成稀疏混合专家语言模型。
class SparseMoELanguageModel(nn.Module):def __init__(self):super().__init__()# each token directly reads off the logits for the next token from a lookup table self.token_embedding_table = nn.Embedding(vocab_size, n_embed) self.position_embedding_table = nn.Embedding(block_size, n_embed)self.blocks = nn.Sequential(*[Block(n_embed, n_head=n_head, num_experts=num_experts,top_k=top_k) for _ in range(n_layer)])self.ln_f = nn.LayerNorm(n_embed) # final layer normself.lm_head = nn.Linear(n_embed, vocab_size)def forward(self, idx, targets=None):B, T = idx.shape# idx and targets are both (B,T) tensor of integerstok_emb = self.token_embedding_table(idx) # (B,T,C)pos_emb = self.position_embedding_table(torch.arange(T, device=device)) # (T,C)x = tok_emb + pos_emb # (B,T,C)x = self.blocks(x) # (B,T,C)x = self.ln_f(x) # (B,T,C)logits = self.lm_head(x) # (B,T,vocab_size)if targets is None:loss = Noneelse:B, T, C = logits.shapelogits = logits.view(B*T, C)targets = targets.view(B*T)loss = F.cross_entropy(logits, targets)return logits, lossdef generate(self, idx, max_new_tokens):# idx is (B, T) array of indices in the current contextfor _ in range(max_new_tokens):# crop idx to the last block_size tokensidx_cond = idx[:, -block_size:]# get the predictionslogits, loss = self(idx_cond)# focus only on the last time steplogits = logits[:, -1, :] # becomes (B, C)# apply softmax to get probabilitiesprobs = F.softmax(logits, dim=-1) # (B, C)# sample from the distributionidx_next = torch.multinomial(probs, num_samples=1) # (B, 1)# append sampled index to the running sequenceidx = torch.cat((idx, idx_next), dim=1) # (B, T+1) return idx
参数初始化对于深度神经网络的高效训练非常重要。由于专家中存在 ReLU 激活,因此这里使用了 Kaiming He 初始化。也可以尝试在 transformer 中更常用的 Glorot 初始化。杰里米 - 霍华德(Jeremy Howard)的《Fastai》第 2 部分有一个从头开始实现这些功能的精彩讲座:https://course.fast.ai/Lessons/lesson17.html
Glorot 参数初始化通常被用于 transformer 模型,因此这是一个可能提高模型性能的方法。
def kaiming_init_weights(m):if isinstance (m, (nn.Linear)): init.kaiming_normal_(m.weight)model = SparseMoELanguageModel()model.apply(kaiming_init_weights)
本文作者使用 mlflow 跟踪并记录重要指标和训练超参数。
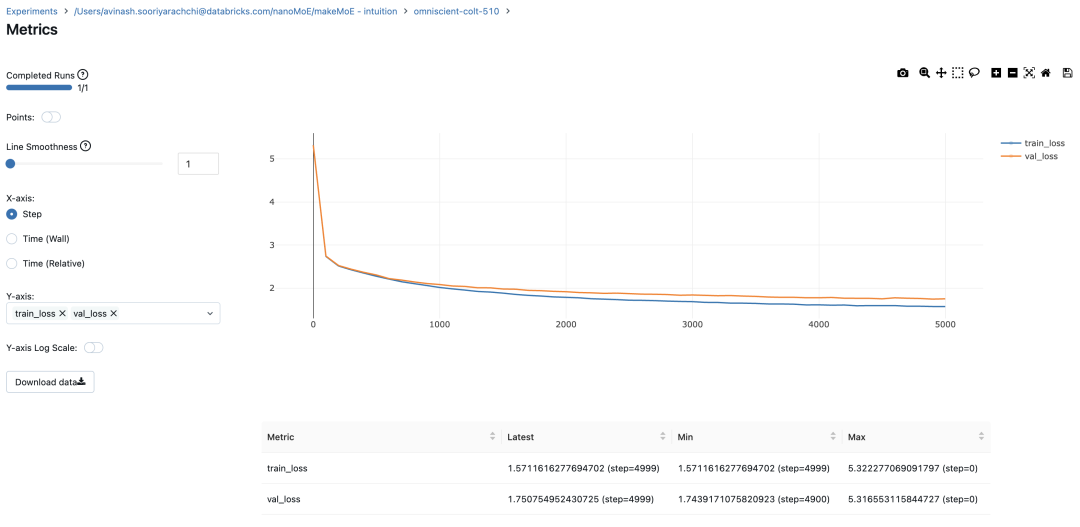
#Using MLFlowm = model.to(device)# print the number of parameters in the modelprint(sum(p.numel() for p in m.parameters())/1e6, 'M parameters')# create a PyTorch optimizeroptimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)#mlflow.set_experiment("makeMoE")with mlflow.start_run():#If you use mlflow.autolog() this will be automatically logged. I chose to explicitly log here for completenessparams = {"batch_size": batch_size , "block_size" : block_size, "max_iters": max_iters, "eval_interval": eval_interval,"learning_rate": learning_rate, "device": device, "eval_iters": eval_iters, "dropout" : dropout, "num_experts": num_experts, "top_k": top_k }mlflow.log_params(params)for iter in range(max_iters):# every once in a while evaluate the loss on train and val setsif iter % eval_interval == 0 or iter == max_iters - 1:losses = estimate_loss()print(f"step {iter}: train loss {losses['train']:.4f}, val loss {losses['val']:.4f}")metrics = {"train_loss": losses['train'], "val_loss": losses['val']}mlflow.log_metrics(metrics, step=iter)# sample a batch of dataxb, yb = get_batch('train')# evaluate the losslogits, loss = model(xb, yb)optimizer.zero_grad(set_to_none=True)loss.backward()optimizer.step()8.996545 M parametersstep 0: train loss 5.3223, val loss 5.3166step 100: train loss 2.7351, val loss 2.7429step 200: train loss 2.5125, val loss 2.5233...step 4999: train loss 1.5712, val loss 1.7508
记录训练和验证损失可以很好地指示训练的进展情况。该图显示,可能应该在 4500 次时停止(当验证损失稍微增加时)
接下来可以使用这个模型逐字符自回归地生成文本。
# generate from the model. Not great. Not too bad eithercontext = torch.zeros((1, 1), dtype=torch.long, device=device)print(decode(m.generate(context, max_new_tokens=2000)[0].tolist()))
DUKE VINCENVENTIO:If it ever fecond he town sue kigh now,That thou wold'st is steen 't.SIMNA:Angent her; no, my a born Yorthort,Romeoos soun and lawf to your sawe with ch a woft ttastly defy,To declay the soul art; and meart smad.CORPIOLLANUS:Which I cannot shall do from by born und ot cold warrike,What king we best anone wrave's going of heard and goodThus playvage; you have wold the grace....
本文参考内容:
在实施过程中,作者大量参考了以下出版物:
混合专家模型:https://arxiv.org/pdf/2401.04088.pdf
超大型神经网络:稀疏门控混合专家层:https://arxiv.org/pdf/1701.06538.pdf
来自 Andrej Karpathy 的原始 makemore 实现:https://github.com/karpathy/makemore
还可以尝试以下几种方法,来提高模型性能:
提高混合专家模块的效率;
尝试不同的神经网络初始化策略;
从字符级到子词级的分词;
对专家数量和 k 的取值(每个 token 激活的专家数量)进行贝叶斯超参数搜索。这可以归类为神经架构搜索。
优化专家能力。
Atas ialah kandungan terperinci Ajar anda langkah demi langkah cara melaksanakan model bahasa seni bina pakar (MoE) campuran yang jarang dari awal. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Tutorial Model Penyebaran Bernilai Masa Anda, dari Universiti Purdue
Apr 07, 2024 am 09:01 AM
Tutorial Model Penyebaran Bernilai Masa Anda, dari Universiti Purdue
Apr 07, 2024 am 09:01 AM
Penyebaran bukan sahaja boleh meniru lebih baik, tetapi juga "mencipta". Model resapan (DiffusionModel) ialah model penjanaan imej. Berbanding dengan algoritma yang terkenal seperti GAN dan VAE dalam bidang AI, model resapan mengambil pendekatan yang berbeza. Idea utamanya ialah proses menambah hingar pada imej dan kemudian secara beransur-ansur menolaknya. Cara mengecilkan dan memulihkan imej asal adalah bahagian teras algoritma. Algoritma akhir mampu menghasilkan imej daripada imej bising rawak. Dalam beberapa tahun kebelakangan ini, pertumbuhan luar biasa AI generatif telah membolehkan banyak aplikasi menarik dalam penjanaan teks ke imej, penjanaan video dan banyak lagi. Prinsip asas di sebalik alat generatif ini ialah konsep resapan, mekanisme pensampelan khas yang mengatasi batasan kaedah sebelumnya.
 Hasilkan PPT dengan satu klik! Kimi: Biarlah 'pekerja migran PPT' menjadi popular dahulu
Aug 01, 2024 pm 03:28 PM
Hasilkan PPT dengan satu klik! Kimi: Biarlah 'pekerja migran PPT' menjadi popular dahulu
Aug 01, 2024 pm 03:28 PM
Kimi: Hanya dalam satu ayat, dalam sepuluh saat sahaja, PPT akan siap. PPT sangat menjengkelkan! Untuk mengadakan mesyuarat, anda perlu mempunyai PPT; untuk menulis laporan mingguan, anda perlu mempunyai PPT untuk membuat pelaburan, anda perlu menunjukkan PPT walaupun anda menuduh seseorang menipu, anda perlu menghantar PPT. Kolej lebih seperti belajar jurusan PPT Anda menonton PPT di dalam kelas dan melakukan PPT selepas kelas. Mungkin, apabila Dennis Austin mencipta PPT 37 tahun lalu, dia tidak menyangka satu hari nanti PPT akan berleluasa. Bercakap tentang pengalaman sukar kami membuat PPT membuatkan kami menitiskan air mata. "Ia mengambil masa tiga bulan untuk membuat PPT lebih daripada 20 muka surat, dan saya menyemaknya berpuluh-puluh kali. Saya rasa ingin muntah apabila saya melihat PPT itu." ialah PPT." Jika anda mengadakan mesyuarat dadakan, anda harus melakukannya
 Semua anugerah CVPR 2024 diumumkan! Hampir 10,000 orang menghadiri persidangan itu di luar talian dan seorang penyelidik Cina dari Google memenangi anugerah kertas terbaik
Jun 20, 2024 pm 05:43 PM
Semua anugerah CVPR 2024 diumumkan! Hampir 10,000 orang menghadiri persidangan itu di luar talian dan seorang penyelidik Cina dari Google memenangi anugerah kertas terbaik
Jun 20, 2024 pm 05:43 PM
Pada awal pagi 20 Jun, waktu Beijing, CVPR2024, persidangan penglihatan komputer antarabangsa teratas yang diadakan di Seattle, secara rasmi mengumumkan kertas kerja terbaik dan anugerah lain. Pada tahun ini, sebanyak 10 kertas memenangi anugerah, termasuk 2 kertas terbaik dan 2 kertas pelajar terbaik Selain itu, terdapat 2 pencalonan kertas terbaik dan 4 pencalonan kertas pelajar terbaik. Persidangan teratas dalam bidang visi komputer (CV) ialah CVPR, yang menarik sejumlah besar institusi penyelidikan dan universiti setiap tahun. Mengikut statistik, sebanyak 11,532 kertas telah diserahkan tahun ini, 2,719 daripadanya diterima, dengan kadar penerimaan 23.6%. Menurut analisis statistik data CVPR2024 Institut Teknologi Georgia, dari perspektif topik penyelidikan, bilangan kertas terbesar ialah sintesis dan penjanaan imej dan video (Imageandvideosyn
 Daripada logam kosong kepada model besar dengan 70 bilion parameter, berikut ialah tutorial dan skrip sedia untuk digunakan
Jul 24, 2024 pm 08:13 PM
Daripada logam kosong kepada model besar dengan 70 bilion parameter, berikut ialah tutorial dan skrip sedia untuk digunakan
Jul 24, 2024 pm 08:13 PM
Kami tahu bahawa LLM dilatih pada kelompok komputer berskala besar menggunakan data besar-besaran Tapak ini telah memperkenalkan banyak kaedah dan teknologi yang digunakan untuk membantu dan menambah baik proses latihan LLM. Hari ini, perkara yang ingin kami kongsikan ialah artikel yang mendalami teknologi asas dan memperkenalkan cara menukar sekumpulan "logam kosong" tanpa sistem pengendalian pun menjadi gugusan komputer untuk latihan LLM. Artikel ini datang daripada Imbue, sebuah permulaan AI yang berusaha untuk mencapai kecerdasan am dengan memahami cara mesin berfikir. Sudah tentu, mengubah sekumpulan "logam kosong" tanpa sistem pengendalian menjadi gugusan komputer untuk latihan LLM bukanlah proses yang mudah, penuh dengan penerokaan dan percubaan dan kesilapan, tetapi Imbue akhirnya berjaya melatih LLM dengan 70 bilion parameter proses terkumpul
 Panduan Pemasangan PyCharm Edisi Komuniti: Kuasai semua langkah dengan cepat
Jan 27, 2024 am 09:10 AM
Panduan Pemasangan PyCharm Edisi Komuniti: Kuasai semua langkah dengan cepat
Jan 27, 2024 am 09:10 AM
Mula Pantas dengan PyCharm Edisi Komuniti: Tutorial Pemasangan Terperinci Analisis Penuh Pengenalan: PyCharm ialah persekitaran pembangunan bersepadu (IDE) Python yang berkuasa yang menyediakan set alat yang komprehensif untuk membantu pembangun menulis kod Python dengan lebih cekap. Artikel ini akan memperkenalkan secara terperinci cara memasang Edisi Komuniti PyCharm dan menyediakan contoh kod khusus untuk membantu pemula bermula dengan cepat. Langkah 1: Muat turun dan pasang Edisi Komuniti PyCharm Untuk menggunakan PyCharm, anda perlu memuat turunnya dari tapak web rasminya terlebih dahulu
 AI sedang digunakan |. AI mencipta vlog kehidupan seorang gadis yang tinggal bersendirian, yang menerima berpuluh ribu suka dalam masa 3 hari
Aug 07, 2024 pm 10:53 PM
AI sedang digunakan |. AI mencipta vlog kehidupan seorang gadis yang tinggal bersendirian, yang menerima berpuluh ribu suka dalam masa 3 hari
Aug 07, 2024 pm 10:53 PM
Editor Laporan Kuasa Mesin: Yang Wen Gelombang kecerdasan buatan yang diwakili oleh model besar dan AIGC telah mengubah cara kita hidup dan bekerja secara senyap-senyap, tetapi kebanyakan orang masih tidak tahu cara menggunakannya. Oleh itu, kami telah melancarkan lajur "AI dalam Penggunaan" untuk memperkenalkan secara terperinci cara menggunakan AI melalui kes penggunaan kecerdasan buatan yang intuitif, menarik dan padat serta merangsang pemikiran semua orang. Kami juga mengalu-alukan pembaca untuk menyerahkan kes penggunaan yang inovatif dan praktikal. Pautan video: https://mp.weixin.qq.com/s/2hX_i7li3RqdE4u016yGhQ Baru-baru ini, vlog kehidupan seorang gadis yang tinggal bersendirian menjadi popular di Xiaohongshu. Animasi gaya ilustrasi, ditambah dengan beberapa perkataan penyembuhan, boleh diambil dengan mudah dalam beberapa hari sahaja.
 Lima perisian pengaturcaraan untuk memulakan pembelajaran bahasa C
Feb 19, 2024 pm 04:51 PM
Lima perisian pengaturcaraan untuk memulakan pembelajaran bahasa C
Feb 19, 2024 pm 04:51 PM
Sebagai bahasa pengaturcaraan yang digunakan secara meluas, bahasa C merupakan salah satu bahasa asas yang mesti dipelajari bagi mereka yang ingin melibatkan diri dalam pengaturcaraan komputer. Walau bagaimanapun, bagi pemula, mempelajari bahasa pengaturcaraan baharu boleh menjadi sukar, terutamanya disebabkan kekurangan alat pembelajaran dan bahan pengajaran yang berkaitan. Dalam artikel ini, saya akan memperkenalkan lima perisian pengaturcaraan untuk membantu pemula memulakan bahasa C dan membantu anda bermula dengan cepat. Perisian pengaturcaraan pertama ialah Code::Blocks. Code::Blocks ialah persekitaran pembangunan bersepadu sumber terbuka (IDE) percuma untuk
 Mesti dibaca untuk pemula teknikal: Analisis tahap kesukaran bahasa C dan Python
Mar 22, 2024 am 10:21 AM
Mesti dibaca untuk pemula teknikal: Analisis tahap kesukaran bahasa C dan Python
Mar 22, 2024 am 10:21 AM
Tajuk: Wajib dibaca untuk pemula teknikal: Analisis kesukaran bahasa C dan Python, memerlukan contoh kod khusus Dalam era digital hari ini, teknologi pengaturcaraan telah menjadi keupayaan yang semakin penting. Sama ada anda ingin bekerja dalam bidang seperti pembangunan perisian, analisis data, kecerdasan buatan, atau hanya belajar pengaturcaraan kerana minat, memilih bahasa pengaturcaraan yang sesuai ialah langkah pertama. Di antara banyak bahasa pengaturcaraan, bahasa C dan Python adalah dua bahasa pengaturcaraan yang digunakan secara meluas, masing-masing mempunyai ciri tersendiri. Artikel ini akan menganalisis tahap kesukaran bahasa C dan Python
