
 Peranti teknologi
AI
'Kemunculan Pintar' Penjanaan Pertuturan: 100,000 Jam Latihan Data, Amazon Menawarkan 1 Bilion Parameter BASE TTS
Peranti teknologi
AI
'Kemunculan Pintar' Penjanaan Pertuturan: 100,000 Jam Latihan Data, Amazon Menawarkan 1 Bilion Parameter BASE TTS
'Kemunculan Pintar' Penjanaan Pertuturan: 100,000 Jam Latihan Data, Amazon Menawarkan 1 Bilion Parameter BASE TTS

Dengan perkembangan pesat model pembelajaran mendalam generatif, pemprosesan bahasa semula jadi (NLP) dan penglihatan komputer (CV) telah mengalami perubahan ketara. Daripada model yang diselia sebelum ini yang memerlukan latihan khusus, kepada model umum yang hanya memerlukan arahan yang mudah dan jelas untuk menyelesaikan pelbagai tugas. Transformasi ini memberikan kami penyelesaian yang lebih cekap dan fleksibel.
Dalam bidang pemprosesan pertuturan dan text-to-speech (TTS), satu transformasi sedang berlaku. Dengan memanfaatkan beribu-ribu jam data, model ini membawa sintesis lebih dekat dan lebih dekat kepada pertuturan manusia sebenar.
Dalam kajian baru-baru ini, Amazon melancarkan BASE TTS secara rasmi, meningkatkan skala parameter model TTS kepada tahap yang belum pernah berlaku sebelum ini iaitu 1 bilion.

Tajuk kertas: TTS ASAS: Pengajaran daripada membina model Teks-ke-Pertuturan berbilion parameter pada 100K jam data
Pautan kertas: https://arxiv.org/pdf. pdf
BASE TTS ialah sistem TTS (LTTS) berbilang bahasa berskala besar, berbilang pembesar suara. Ia menggunakan kira-kira 100,000 jam data pertuturan domain awam untuk latihan, iaitu dua kali ganda berbanding VALL-E, yang mempunyai jumlah data latihan tertinggi sebelum ini. Diilhamkan oleh pengalaman kejayaan LLM, BASE TTS menganggap TTS sebagai masalah ramalan token seterusnya dan menggabungkannya dengan sejumlah besar data latihan untuk mencapai keupayaan berbilang bahasa dan berbilang pembesar suara yang berkuasa.
Sumbangan utama kertas kerja ini diringkaskan seperti berikut:
BASE TTS yang dicadangkan kini merupakan model TTS terbesar dengan 1 bilion parameter dan dilatih berdasarkan set data yang terdiri daripada 100,000 jam data pertuturan domain awam. Melalui penilaian subjektif, BASE TTS mengatasi prestasi model garis dasar LTTS awam.
Artikel ini menunjukkan cara untuk meningkatkan keupayaan BASE TTS untuk menghasilkan prosodi yang sesuai untuk teks kompleks dengan memanjangkannya kepada set data dan saiz model yang lebih besar. Untuk menilai pemahaman teks dan keupayaan pemaparan model TTS berskala besar, penyelidik membangunkan set ujian "keupayaan timbul" dan melaporkan prestasi varian BASE TTS yang berbeza pada penanda aras ini. Keputusan menunjukkan bahawa apabila saiz set data dan bilangan parameter meningkat, kualiti BASE TTS semakin bertambah baik.
3 Perwakilan pertuturan diskret baharu berdasarkan model SSL WavLM dicadangkan, bertujuan untuk menangkap maklumat fonologi dan prosodik isyarat pertuturan sahaja. Perwakilan ini mengatasi kaedah pengkuantitian garis dasar, membolehkannya dinyahkodkan kepada bentuk gelombang berkualiti tinggi dengan penyahkod mudah, pantas dan penstriman walaupun tahap mampatan tinggi (hanya 400 bit/s).
Seterusnya, mari lihat butiran kertas.
BASE TTS model
Sama seperti kerja pemodelan pertuturan baru-baru ini, penyelidik menggunakan pendekatan berasaskan LLM untuk mengendalikan tugasan TTS. Teks dimasukkan ke dalam model autoregresif berasaskan Transformer yang meramalkan perwakilan audio diskret (dipanggil kod pertuturan), yang kemudiannya dinyahkodkan kepada bentuk gelombang oleh penyahkod terlatih berasingan yang terdiri daripada lapisan linear dan konvolusi.
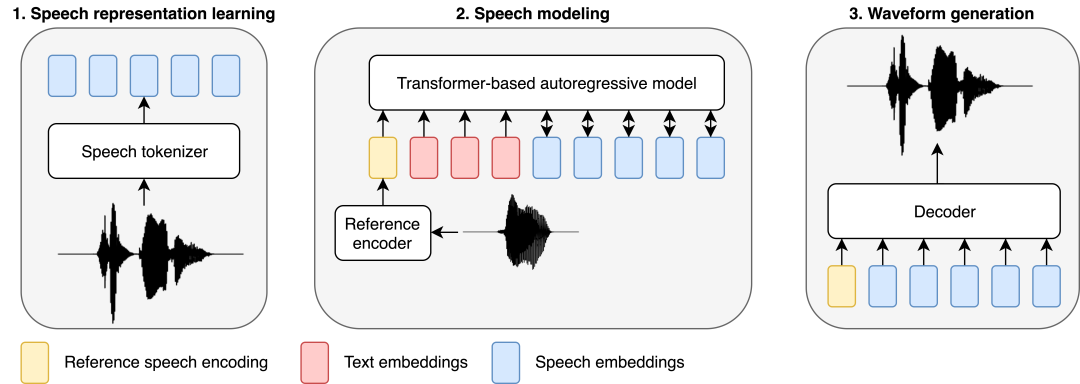
BASE TTS direka bentuk untuk mensimulasikan pengedaran bersama token teks dan kemudian perwakilan pertuturan diskret, yang penyelidik panggil pengekodan pertuturan. Diskretisasi pertuturan oleh codec audio adalah penting kepada reka bentuk, kerana ini membolehkan penggunaan terus kaedah yang dibangunkan untuk LLM, yang merupakan asas untuk hasil penyelidikan terkini dalam LTTS. Khususnya, kami memodelkan pengekodan pertuturan menggunakan Transformer autoregresif penyahkodan dengan objektif latihan rentas entropi. Walaupun mudah, matlamat ini boleh menangkap taburan kebarangkalian kompleks pertuturan ekspresif, dengan itu mengurangkan masalah terlalu licin yang dilihat dalam sistem TTS saraf awal. Sebagai model bahasa tersirat, sebaik sahaja varian yang cukup besar dilatih pada data yang mencukupi, BASE TTS juga akan membuat lonjakan kualitatif dalam pemaparan prosodi.
Perwakilan Bahasa Diskret
Perwakilan diskrit ialah asas kejayaan LLM, tetapi mengenal pasti perwakilan yang padat dan bermaklumat dalam pertuturan tidak begitu jelas seperti dalam teks, dan kurang diterokai sebelum ini. Untuk BASE TTS, penyelidik mula-mula cuba menggunakan garis dasar VQ-VAE (Bahagian 2.2.1), yang berdasarkan seni bina pengekod auto untuk membina semula spektrogram mel melalui kesesakan diskret. VQ-VAE telah menjadi paradigma yang berjaya untuk pertuturan dan perwakilan imej, terutamanya sebagai unit pemodelan untuk TTS.
Para penyelidik juga memperkenalkan kaedah baharu untuk mempelajari perwakilan pertuturan melalui pengekodan pertuturan berasaskan WavLM (Bahagian 2.2.2). Dalam pendekatan ini, penyelidik mendiskrisikan ciri yang diekstrak daripada model SSL WavLM untuk membina semula spektrogram mel. Para penyelidik menggunakan fungsi kehilangan tambahan untuk memudahkan pemisahan pembesar suara dan memampatkan kod pertuturan yang dijana menggunakan Pengekodan Pasangan Byte (BPE) untuk mengurangkan panjang jujukan, membolehkan penggunaan Transformer untuk Pemodelan audio yang lebih panjang.
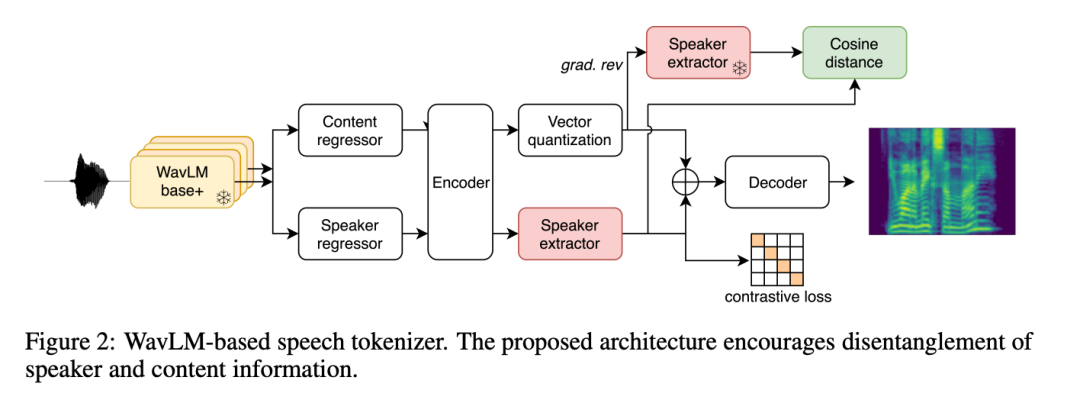
Kedua-dua perwakilan dimampatkan (masing-masing 325 bit/s dan 400 bit/s) untuk membolehkan pemodelan autoregresif yang lebih cekap berbanding codec audio popular. Berdasarkan tahap pemampatan ini, matlamat seterusnya adalah untuk mengalih keluar maklumat daripada kod pertuturan yang boleh dibina semula semasa penyahkodan (pembesar suara, bunyi audio, dll.) untuk memastikan kapasiti kod pertuturan digunakan terutamanya untuk mengekod fonetik dan prosodik. maklumat.
Pemodelan Pertuturan Autoregresif (SpeechGPT)
Para penyelidik melatih model autoregresif "SpeechGPT" dengan seni bina GPT-2, yang digunakan untuk meramalkan pengekodan pertuturan yang dikondisikan pada teks dan pertuturan rujukan. Keadaan pertuturan rujukan terdiri daripada ujaran yang dipilih secara rawak daripada penutur yang sama, yang dikodkan sebagai benam bersaiz tetap. Pembenaman pertuturan rujukan, pengekodan teks dan pertuturan disatukan ke dalam urutan yang dimodelkan oleh model autoregresif berasaskan Transformer. Kami menggunakan benam kedudukan yang berasingan dan kepala ramalan yang berasingan untuk teks dan pertuturan. Mereka melatih model autoregresif dari awal tanpa pra-latihan pada teks. Untuk mengekalkan maklumat teks untuk membimbing onomatopoeia, SpeechGPT juga dilatih dengan tujuan untuk meramalkan token seterusnya bagi bahagian teks urutan input, jadi bahagian SpeechGPT ialah LM teks sahaja. Berat yang lebih rendah digunakan di sini untuk kehilangan teks berbanding kehilangan pertuturan.
Penjanaan bentuk gelombang
Selain itu, penyelidik menetapkan penyahkod pertuturan-ke-gelombang yang berasingan (dipanggil "codec pertuturan") yang bertanggungjawab untuk membina semula identiti pembesar suara dan keadaan rakaman. Untuk menjadikan model lebih berskala, mereka menggantikan lapisan LSTM dengan lapisan konvolusi untuk menyahkod perwakilan perantaraan. Penyelidikan menunjukkan bahawa codec pertuturan berasaskan konvolusi ini adalah cekap dari segi pengiraan, mengurangkan masa sintesis sistem keseluruhan lebih daripada 70% berbanding dengan penyahkod garis dasar berasaskan resapan.
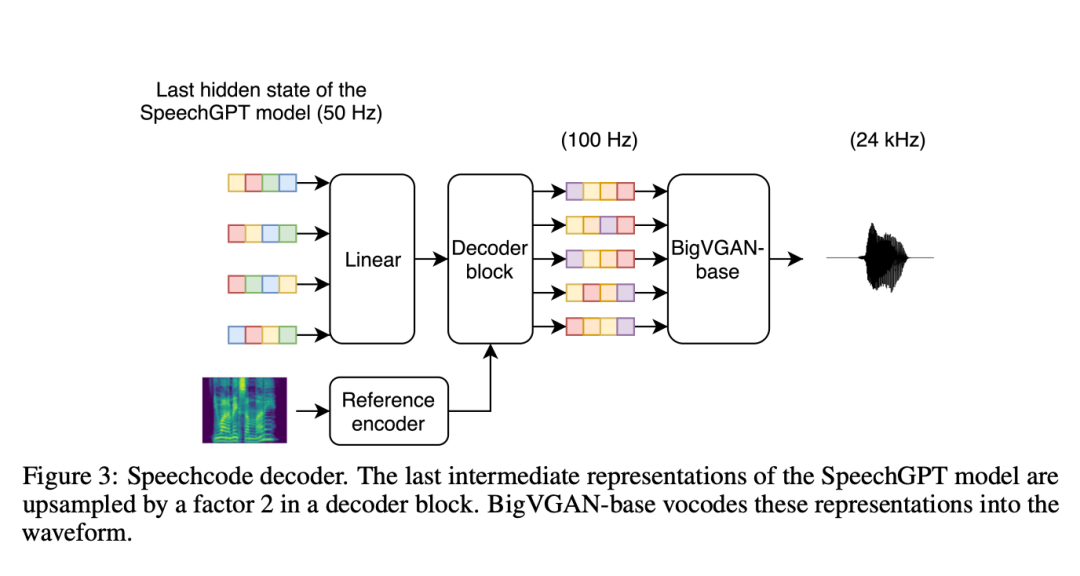
Para penyelidik juga menegaskan bahawa sebenarnya input codec pertuturan bukanlah pengekodan pertuturan, tetapi keadaan tersembunyi terakhir Transformer autoregresif. Ini dilakukan kerana perwakilan laten padat dalam kaedah TortoiseTTS sebelumnya memberikan maklumat yang lebih kaya daripada satu kod fonetik. Semasa proses latihan, penyelidik memasukkan teks dan kod sasaran ke dalam SpeechGPT terlatih (pembekuan parameter), dan kemudian melaraskan penyahkod berdasarkan keadaan tersembunyi terakhir. Memasukkan keadaan tersembunyi terakhir SpeechGPT membantu meningkatkan pembahagian dan kualiti akustik pertuturan, tetapi juga mengikat penyahkod kepada versi SpeechGPT tertentu. Ini merumitkan eksperimen kerana ia memaksa kedua-dua komponen sentiasa dibina secara berurutan. Batasan ini perlu ditangani dalam kerja akan datang.
Penilaian Eksperimen
Para penyelidik meneroka cara penskalaan mempengaruhi keupayaan model untuk menghasilkan prosodi dan ungkapan yang sesuai untuk input teks yang mencabar, sama seperti cara LLM "muncul" keupayaan baharu melalui penskalaan data dan parameter. Untuk menguji sama ada hipotesis ini juga terpakai kepada LTTS, penyelidik mencadangkan skema penilaian untuk menilai potensi kebolehan muncul dalam TTS, mengenal pasti tujuh kategori yang mencabar: kata nama majmuk, emosi, perkataan asing, parabahasa dan tanda baca , isu dan kerumitan sintaksis.
Berbilang percubaan mengesahkan struktur BASE TTS dan kualiti, kefungsian dan prestasi pengiraannya:
Pertama, penyelidik membandingkan kualiti model yang dicapai oleh pengekodan pertuturan berasaskan autopengekod dan berasaskan WavLM.
Para penyelidik kemudian menilai dua pendekatan untuk penyahkodan akustik kod pertuturan: penyahkod berasaskan resapan dan codec pertuturan.
Selepas melengkapkan ablasi struktur ini, kami menilai keupayaan muncul BASE TTS merentas 3 variasi saiz set data dan parameter model, serta oleh pakar bahasa.
Selain itu, penyelidik menjalankan ujian MUSHRA subjektif untuk mengukur keaslian, serta kebolehfahaman automatik dan ukuran persamaan pembesar suara, dan melaporkan perbandingan kualiti pertuturan dengan model teks ke pertuturan sumber terbuka yang lain.
Pengekodan pertuturan VQ-VAE lwn. pengekodan pertuturan WavLM
Untuk menguji secara menyeluruh kualiti dan kepelbagaian kedua-dua kaedah tokenisasi pertuturan, para penyelidik menjalankan MUSHRA pada 6 orang Inggeris Amerika dan 4 penutur Sepanyol Evaluate. Dari segi skor min MUSHRA untuk bahasa Inggeris, sistem berasaskan VQ-VAE dan WavLM adalah setanding (VQ-VAE: 74.8 vs WavLM: 74.7). Walau bagaimanapun, untuk bahasa Sepanyol, model berasaskan WavLM secara statistik lebih baik daripada model VQ-VAE (VQ-VAE: 73.3 vs WavLM: 74.7). Ambil perhatian bahawa data Bahasa Inggeris membentuk kira-kira 90% daripada set data, manakala data Sepanyol hanya membentuk 2%.
Jadual 3 menunjukkan keputusan yang dikelaskan mengikut pembesar suara:
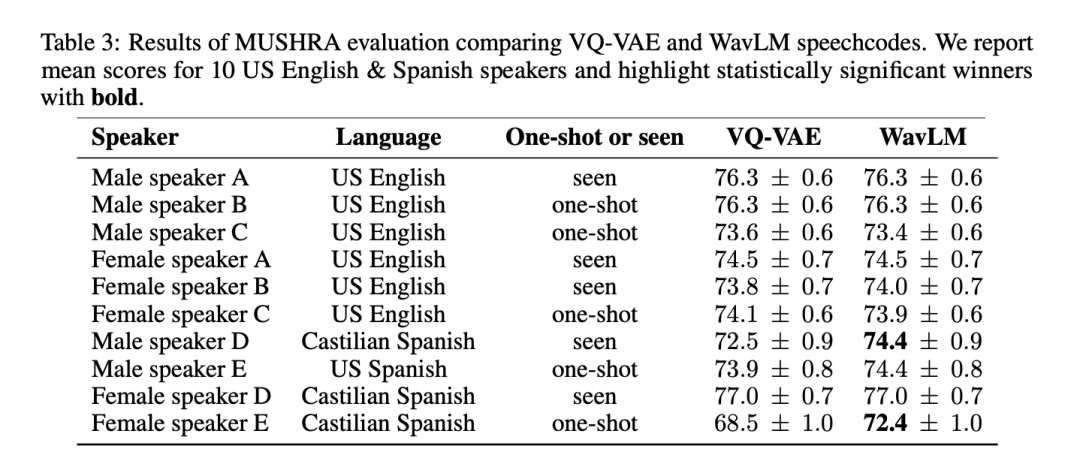
Memandangkan sistem berasaskan WavLM berprestasi sekurang-kurangnya atau lebih baik daripada garis dasar VQ-VAE, kami menggunakannya untuk mewakili BASE TTS dalam percubaan selanjutnya.
Penyahkod berasaskan resapan vs. penyahkod kod pertuturan
Seperti yang dinyatakan di atas, BASE TTS memudahkan penyahkod garis dasar berasaskan resapan dengan mencadangkan codec pertuturan hujung ke hujung. Kaedah ini fasih dan meningkatkan kelajuan inferens sebanyak 3 kali ganda. Untuk memastikan pendekatan ini tidak merendahkan kualiti, codec pertuturan yang dicadangkan telah dinilai berdasarkan garis dasar. Jadual 4 menyenaraikan keputusan penilaian MUSHRA ke atas 4 orang Amerika berbahasa Inggeris dan 2 orang berbahasa Sepanyol:
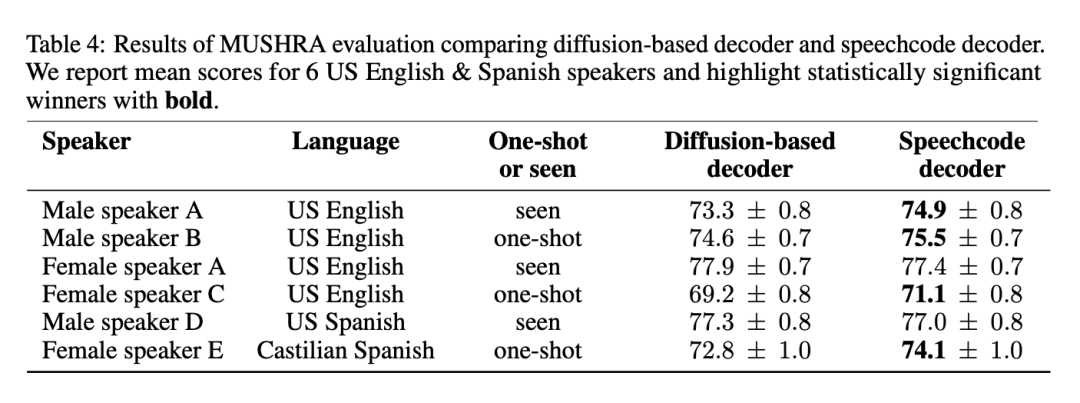
Keputusan menunjukkan bahawa codec pertuturan adalah kaedah pilihan kerana ia tidak mengurangkan kualiti, Dan untuk kebanyakan pertuturan, ia meningkatkan kualiti sambil memberikan inferens yang lebih cepat. Para penyelidik juga menyatakan bahawa menggabungkan dua model generatif yang berkuasa untuk pemodelan pertuturan adalah berlebihan dan boleh dipermudahkan dengan meninggalkan penyahkod resapan.
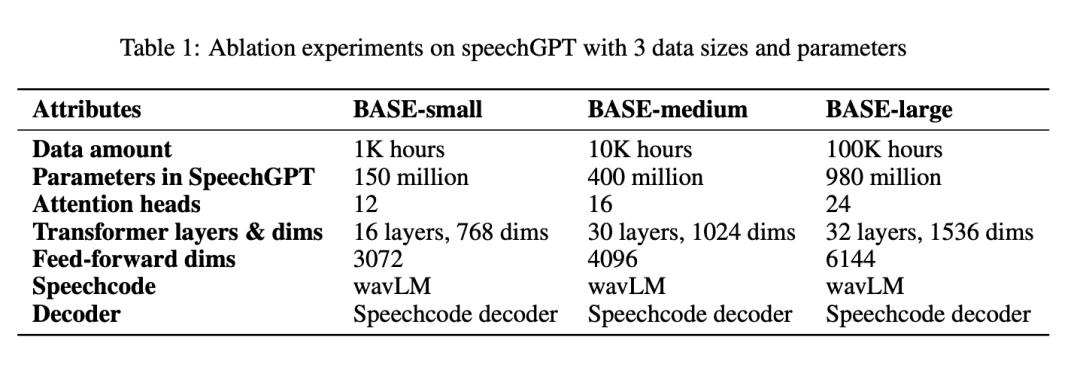
Kuasa kemunculan: ablasi data dan saiz model
Jadual 1 melaporkan semua parameter mengikut sistem BASE-kecil, BASE-sederhana dan BASE-besar:
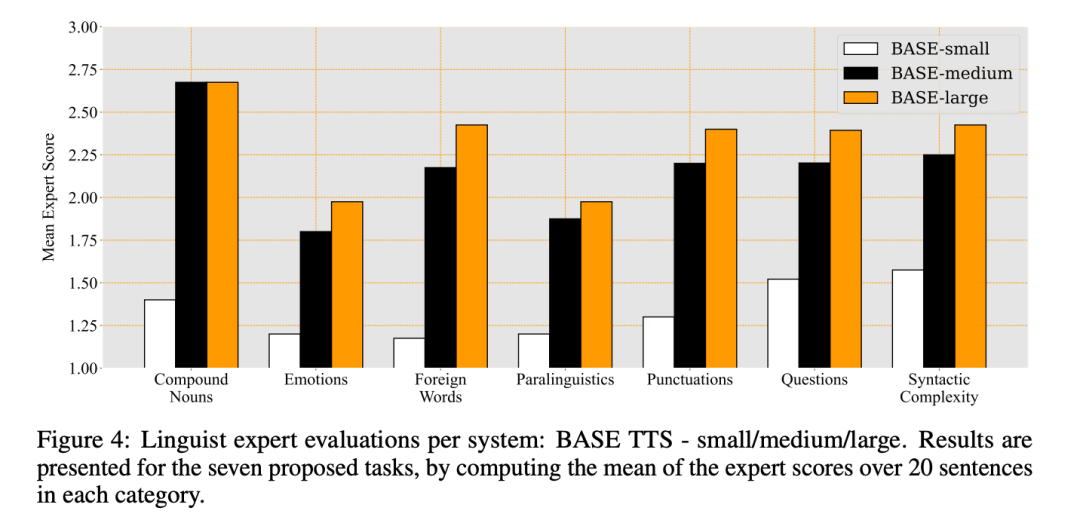
Hasil keputusan pakar dan penilaian pakar bahasa untuk ketiga-tiga sistem bahasa skor purata bagi setiap kategori ditunjukkan dalam Rajah 4:
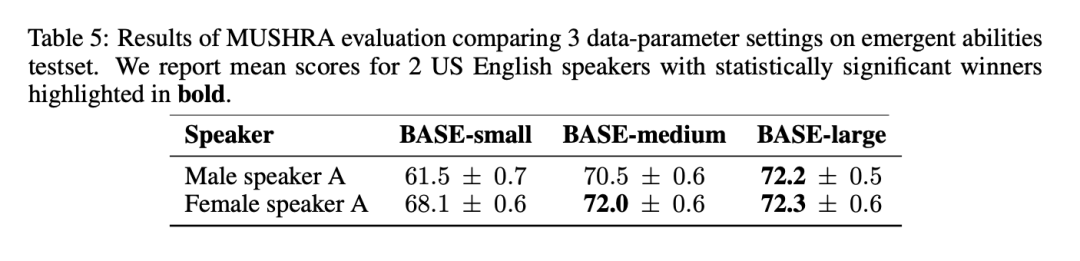
Dalam keputusan MUSHRA dalam Jadual 5, dapat diperhatikan bahawa keaslian pertuturan meningkat dengan ketara daripada BASE-kecil kepada BASE-sederhana, tetapi daripada BASE-sederhana kepada BASE- Penambahbaikan besar adalah lebih kecil:
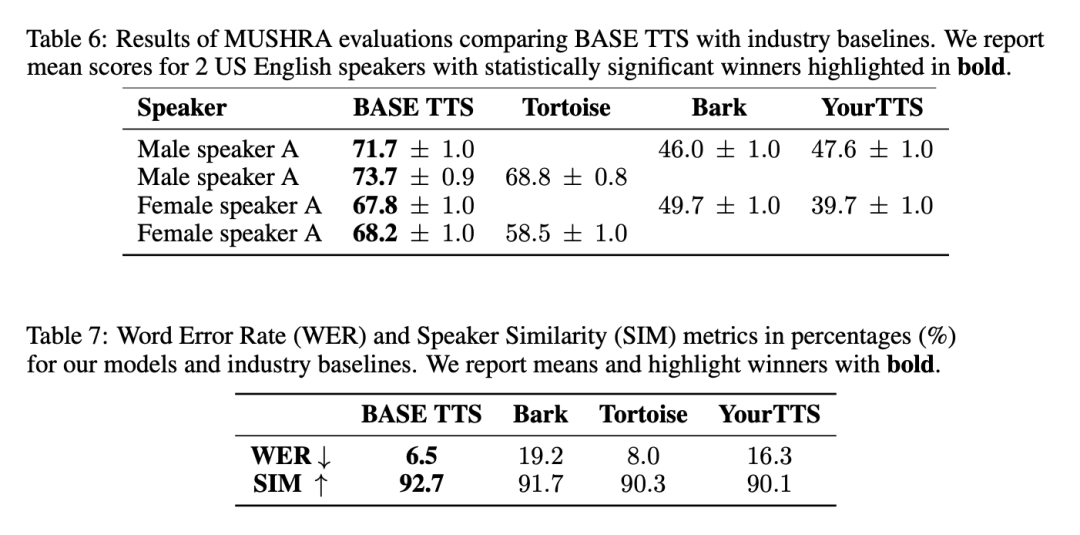
BASE TTS vs. baseline industri
Secara amnya, BASE TTS menjana pertuturan yang paling semula jadi, mempunyai paling sedikit salah jajaran dengan teks input dan paling serupa dengan ucapan penceramah rujukan. Keputusan yang berkaitan ditunjukkan dalam Jadual 6 dan Jadual 7:
Peningkatan kecekapan sintesis yang dibawa oleh codec pertuturan
Codec pertuturan mampu memproses penstriman, iaitu menjana pertuturan secara inkremental cara. Menggabungkan keupayaan ini dengan SpeechGPT autoregresif, sistem boleh mencapai kependaman bait pertama serendah 100 milisaat — cukup untuk menghasilkan pertuturan yang boleh difahami dengan hanya beberapa kod pertuturan yang dinyahkod.
Latensi minimum ini berbeza dengan penyahkod berasaskan resapan, yang memerlukan keseluruhan urutan pertuturan (satu atau lebih ayat) dijana sekali gus, dengan kependaman bait pertama bersamaan dengan jumlah masa penjanaan.
Selain itu, penyelidik mendapati bahawa codec pertuturan menjadikan keseluruhan sistem pengiraan lebih cekap dari segi pengiraan dengan faktor 3 berbanding garis dasar resapan. Mereka menjalankan penanda aras yang menghasilkan 1000 penyata dengan tempoh kira-kira 20 saat dengan saiz kelompok 1 pada GPU NVIDIA® V100. Secara purata, SpeechGPT berbilion parameter menggunakan penyahkod resapan mengambil masa 69.1 saat untuk melengkapkan sintesis, manakala SpeechGPT yang sama menggunakan codec pertuturan hanya mengambil masa 17.8 saat.
Untuk butiran penyelidikan lanjut, sila rujuk kertas asal.
Atas ialah kandungan terperinci 'Kemunculan Pintar' Penjanaan Pertuturan: 100,000 Jam Latihan Data, Amazon Menawarkan 1 Bilion Parameter BASE TTS. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1371
1371
 52
52

 Robot DeepMind bermain pingpong, dan pukulan depan dan pukulan kilasnya tergelincir ke udara, mengalahkan manusia pemula sepenuhnya
Aug 09, 2024 pm 04:01 PM
Robot DeepMind bermain pingpong, dan pukulan depan dan pukulan kilasnya tergelincir ke udara, mengalahkan manusia pemula sepenuhnya
Aug 09, 2024 pm 04:01 PM
Tetapi mungkin dia tidak dapat mengalahkan lelaki tua di taman itu? Sukan Olimpik Paris sedang rancak berlangsung, dan pingpong telah menarik perhatian ramai. Pada masa yang sama, robot juga telah membuat penemuan baru dalam bermain pingpong. Sebentar tadi, DeepMind mencadangkan ejen robot pembelajaran pertama yang boleh mencapai tahap pemain amatur manusia dalam pingpong yang kompetitif. Alamat kertas: https://arxiv.org/pdf/2408.03906 Sejauh manakah robot DeepMind bermain pingpong? Mungkin setanding dengan pemain amatur manusia: kedua-dua pukulan depan dan pukulan kilas: pihak lawan menggunakan pelbagai gaya permainan, dan robot juga boleh bertahan: servis menerima dengan putaran yang berbeza: Walau bagaimanapun, keamatan permainan nampaknya tidak begitu sengit seperti lelaki tua di taman itu. Untuk robot, pingpong
 Cakar mekanikal pertama! Yuanluobao muncul di Persidangan Robot Dunia 2024 dan mengeluarkan robot catur pertama yang boleh memasuki rumah
Aug 21, 2024 pm 07:33 PM
Cakar mekanikal pertama! Yuanluobao muncul di Persidangan Robot Dunia 2024 dan mengeluarkan robot catur pertama yang boleh memasuki rumah
Aug 21, 2024 pm 07:33 PM
Pada 21 Ogos, Persidangan Robot Dunia 2024 telah diadakan dengan megah di Beijing. Jenama robot rumah SenseTime "Yuanluobot SenseRobot" telah memperkenalkan seluruh keluarga produknya, dan baru-baru ini mengeluarkan robot permainan catur AI Yuanluobot - Edisi Profesional Catur (selepas ini dirujuk sebagai "Yuanluobot SenseRobot"), menjadi robot catur A pertama di dunia untuk rumah. Sebagai produk robot permainan catur ketiga Yuanluobo, robot Guoxiang baharu telah melalui sejumlah besar peningkatan teknikal khas dan inovasi dalam AI dan jentera kejuruteraan Buat pertama kalinya, ia telah menyedari keupayaan untuk mengambil buah catur tiga dimensi melalui cakar mekanikal pada robot rumah, dan melaksanakan Fungsi mesin manusia seperti bermain catur, semua orang bermain catur, semakan notasi, dsb.
 Claude pun dah jadi malas! Netizen: Belajar untuk memberi percutian kepada diri sendiri
Sep 02, 2024 pm 01:56 PM
Claude pun dah jadi malas! Netizen: Belajar untuk memberi percutian kepada diri sendiri
Sep 02, 2024 pm 01:56 PM
Permulaan sekolah akan bermula, dan bukan hanya pelajar yang akan memulakan semester baharu yang harus menjaga diri mereka sendiri, tetapi juga model AI yang besar. Beberapa ketika dahulu, Reddit dipenuhi oleh netizen yang mengadu Claude semakin malas. "Tahapnya telah banyak menurun, ia sering berhenti seketika, malah output menjadi sangat singkat. Pada minggu pertama keluaran, ia boleh menterjemah dokumen penuh 4 halaman sekaligus, tetapi kini ia tidak dapat mengeluarkan separuh halaman pun. !" https:// www.reddit.com/r/ClaudeAI/comments/1by8rw8/something_just_feels_wrong_with_claude_in_the/ dalam siaran bertajuk "Totally disappointed with Claude", penuh dengan
 Pada Persidangan Robot Sedunia, robot domestik yang membawa 'harapan penjagaan warga tua masa depan' ini telah dikepung
Aug 22, 2024 pm 10:35 PM
Pada Persidangan Robot Sedunia, robot domestik yang membawa 'harapan penjagaan warga tua masa depan' ini telah dikepung
Aug 22, 2024 pm 10:35 PM
Pada Persidangan Robot Dunia yang diadakan di Beijing, paparan robot humanoid telah menjadi tumpuan mutlak di gerai Stardust Intelligent, pembantu robot AI S1 mempersembahkan tiga persembahan utama dulcimer, seni mempertahankan diri dan kaligrafi dalam. satu kawasan pameran, berkebolehan kedua-dua sastera dan seni mempertahankan diri, menarik sejumlah besar khalayak profesional dan media. Permainan elegan pada rentetan elastik membolehkan S1 menunjukkan operasi halus dan kawalan mutlak dengan kelajuan, kekuatan dan ketepatan. CCTV News menjalankan laporan khas mengenai pembelajaran tiruan dan kawalan pintar di sebalik "Kaligrafi Pengasas Syarikat Lai Jie menjelaskan bahawa di sebalik pergerakan sutera, bahagian perkakasan mengejar kawalan daya terbaik dan penunjuk badan yang paling menyerupai manusia (kelajuan, beban). dll.), tetapi di sisi AI, data pergerakan sebenar orang dikumpulkan, membolehkan robot menjadi lebih kuat apabila ia menghadapi situasi yang kuat dan belajar untuk berkembang dengan cepat. Dan tangkas
 Pasukan Li Feifei mencadangkan ReKep untuk memberi robot kecerdasan spatial dan mengintegrasikan GPT-4o
Sep 03, 2024 pm 05:18 PM
Pasukan Li Feifei mencadangkan ReKep untuk memberi robot kecerdasan spatial dan mengintegrasikan GPT-4o
Sep 03, 2024 pm 05:18 PM
Penyepaduan mendalam penglihatan dan pembelajaran robot. Apabila dua tangan robot bekerja bersama-sama dengan lancar untuk melipat pakaian, menuang teh dan mengemas kasut, ditambah pula dengan 1X robot humanoid NEO yang telah menjadi tajuk berita baru-baru ini, anda mungkin mempunyai perasaan: kita seolah-olah memasuki zaman robot. Malah, pergerakan sutera ini adalah hasil teknologi robotik canggih + reka bentuk bingkai yang indah + model besar berbilang modal. Kami tahu bahawa robot yang berguna sering memerlukan interaksi yang kompleks dan indah dengan alam sekitar, dan persekitaran boleh diwakili sebagai kekangan dalam domain spatial dan temporal. Sebagai contoh, jika anda ingin robot menuang teh, robot terlebih dahulu perlu menggenggam pemegang teko dan memastikannya tegak tanpa menumpahkan teh, kemudian gerakkannya dengan lancar sehingga mulut periuk sejajar dengan mulut cawan. , dan kemudian condongkan teko pada sudut tertentu. ini
 Anugerah ACL 2024 Diumumkan: Salah satu Kertas Terbaik mengenai Pentafsiran Oracle oleh HuaTech, Anugerah Ujian Masa GloVe
Aug 15, 2024 pm 04:37 PM
Anugerah ACL 2024 Diumumkan: Salah satu Kertas Terbaik mengenai Pentafsiran Oracle oleh HuaTech, Anugerah Ujian Masa GloVe
Aug 15, 2024 pm 04:37 PM
Pada persidangan ACL ini, para penyumbang telah mendapat banyak keuntungan. ACL2024 selama enam hari diadakan di Bangkok, Thailand. ACL ialah persidangan antarabangsa teratas dalam bidang linguistik pengiraan dan pemprosesan bahasa semula jadi Ia dianjurkan oleh Persatuan Antarabangsa untuk Linguistik Pengiraan dan diadakan setiap tahun. ACL sentiasa menduduki tempat pertama dalam pengaruh akademik dalam bidang NLP, dan ia juga merupakan persidangan yang disyorkan CCF-A. Persidangan ACL tahun ini adalah yang ke-62 dan telah menerima lebih daripada 400 karya termaju dalam bidang NLP. Petang semalam, persidangan itu mengumumkan kertas kerja terbaik dan anugerah lain. Kali ini, terdapat 7 Anugerah Kertas Terbaik (dua tidak diterbitkan), 1 Anugerah Kertas Tema Terbaik, dan 35 Anugerah Kertas Cemerlang. Persidangan itu turut menganugerahkan 3 Anugerah Kertas Sumber (ResourceAward) dan Anugerah Impak Sosial (
 Hongmeng Smart Travel S9 dan persidangan pelancaran produk baharu senario penuh, beberapa produk baharu blockbuster dikeluarkan bersama-sama
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 dan persidangan pelancaran produk baharu senario penuh, beberapa produk baharu blockbuster dikeluarkan bersama-sama
Aug 08, 2024 am 07:02 AM
Petang ini, Hongmeng Zhixing secara rasmi mengalu-alukan jenama baharu dan kereta baharu. Pada 6 Ogos, Huawei mengadakan persidangan pelancaran produk baharu Hongmeng Smart Xingxing S9 dan senario penuh Huawei, membawakan sedan perdana pintar panoramik Xiangjie S9, M7Pro dan Huawei novaFlip baharu, MatePad Pro 12.2 inci, MatePad Air baharu, Huawei Bisheng With banyak produk pintar semua senario baharu termasuk pencetak laser siri X1, FreeBuds6i, WATCHFIT3 dan skrin pintar S5Pro, daripada perjalanan pintar, pejabat pintar kepada pakaian pintar, Huawei terus membina ekosistem pintar senario penuh untuk membawa pengguna pengalaman pintar Internet Segala-galanya. Hongmeng Zhixing: Pemerkasaan mendalam untuk menggalakkan peningkatan industri kereta pintar Huawei berganding bahu dengan rakan industri automotif China untuk menyediakan
 AI sedang digunakan |. Permainan Amway AI yang gila oleh CEO Microsoft telah menyeksa saya beribu kali
Aug 14, 2024 am 12:00 AM
AI sedang digunakan |. Permainan Amway AI yang gila oleh CEO Microsoft telah menyeksa saya beribu kali
Aug 14, 2024 am 12:00 AM
Editor Laporan Kuasa Mesin: Yang Wen Gelombang kecerdasan buatan yang diwakili oleh model besar dan AIGC telah mengubah cara kita hidup dan bekerja secara senyap-senyap, tetapi kebanyakan orang masih tidak tahu cara menggunakannya. Oleh itu, kami telah melancarkan lajur "AI dalam Penggunaan" untuk memperkenalkan secara terperinci cara menggunakan AI melalui kes penggunaan kecerdasan buatan yang intuitif, menarik dan padat serta merangsang pemikiran semua orang. Kami juga mengalu-alukan pembaca untuk menyerahkan kes penggunaan yang inovatif dan praktikal. Ya Tuhan, AI benar-benar menjadi seorang yang genius. Baru-baru ini, ia menjadi topik hangat bahawa sukar untuk membezakan ketulenan gambar yang dihasilkan oleh AI. (Untuk butiran, sila pergi ke: AI sedang digunakan | Menjadi kecantikan AI dalam tiga langkah, dan dipukul kembali kepada bentuk asal anda oleh AI dalam sesaat) Selain wanita AI Google yang popular di Internet, pelbagai penjana FLUX telah muncul di platform sosial
