
 Peranti teknologi
AI
Anda boleh mula menggunakan Windows dan Office secara langsung. Sangat mudah untuk mengendalikan komputer dengan ejen model yang besar.
Peranti teknologi
AI
Anda boleh mula menggunakan Windows dan Office secara langsung. Sangat mudah untuk mengendalikan komputer dengan ejen model yang besar.
Anda boleh mula menggunakan Windows dan Office secara langsung. Sangat mudah untuk mengendalikan komputer dengan ejen model yang besar.

Apabila bercakap tentang masa depan pembantu AI, orang ramai boleh dengan mudah memikirkan Jarvis pembantu AI dalam siri "Iron Man". Jarvis menunjukkan fungsi yang mempesonakan dalam filem Dia bukan sahaja orang kanan Tony Stark, tetapi juga jambatannya untuk berkomunikasi dengan teknologi canggih. Dengan kemunculan model berskala besar, cara manusia menggunakan alat sedang mengalami perubahan revolusioner, dan mungkin kita selangkah lebih dekat dengan senario fiksyen sains. Bayangkan agen berbilang modal yang boleh mengawal komputer di sekeliling kita secara langsung melalui papan kekunci dan tetikus seperti manusia. Betapa menariknya kejayaan ini.
AI pembantu Jarvis
Penyelidikan terkini "ScreenAgent: A Vision Language Model-driven Computer Control Agent" dari Sekolah Kecerdasan Buatan Universiti Jilin menunjukkan imaginasi menggunakan model bahasa visual yang besar mengawal secara langsung GUI komputer. Kajian ini mencadangkan model ScreenAgent, yang buat pertama kalinya meneroka kawalan langsung tetikus dan papan kekunci komputer melalui Agen VLM tanpa memerlukan bantuan tag tambahan, mencapai matlamat operasi komputer langsung model berskala besar. Selain itu, ScreenAgent menggunakan proses "plan-execute-reflect" automatik untuk mencapai kawalan berterusan antara muka GUI buat kali pertama. Kerja ini meneroka dan memperbaharui kaedah interaksi manusia-komputer, dan juga sumber sumber terbuka termasuk set data, pengawal dan kod latihan dengan maklumat kedudukan yang tepat. .

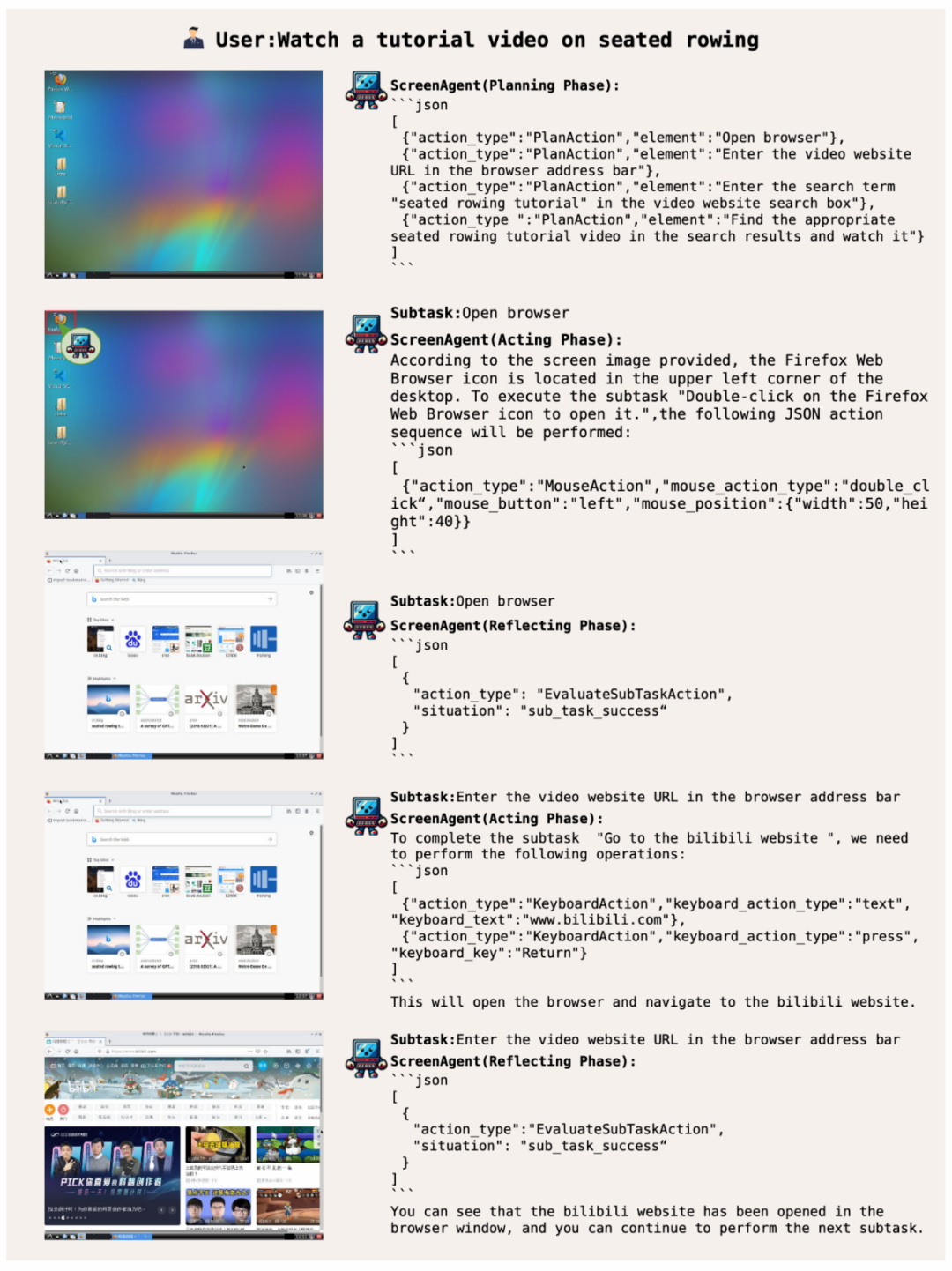
- membawa anda melayari Internet dan mencapai kebebasan hiburan
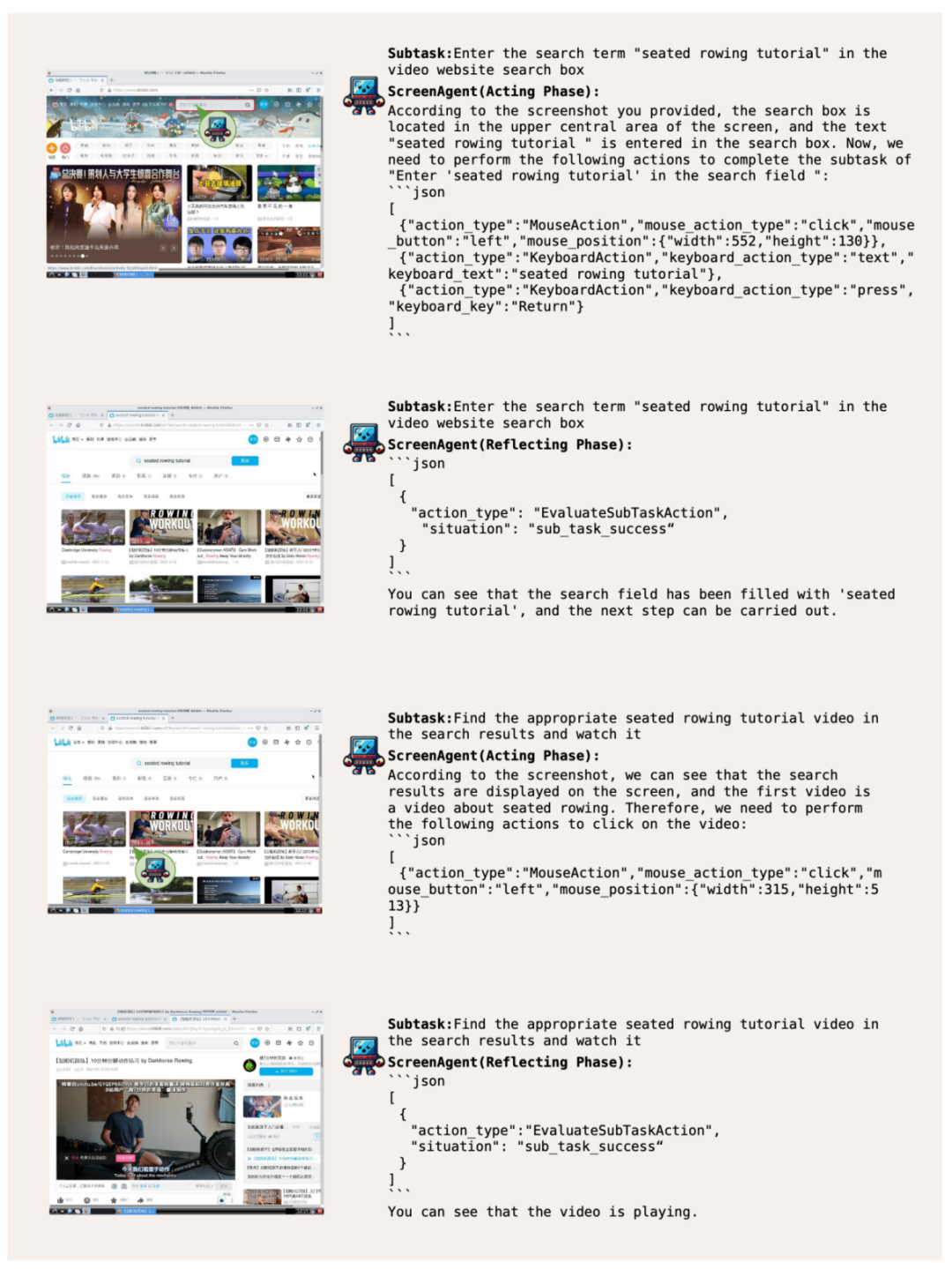
- ScreenAgent mencari dan memainkan video tertentu dalam talian berdasarkan penerangan teks pengguna:
memberi Kemahiran peringkat tinggi pengguna
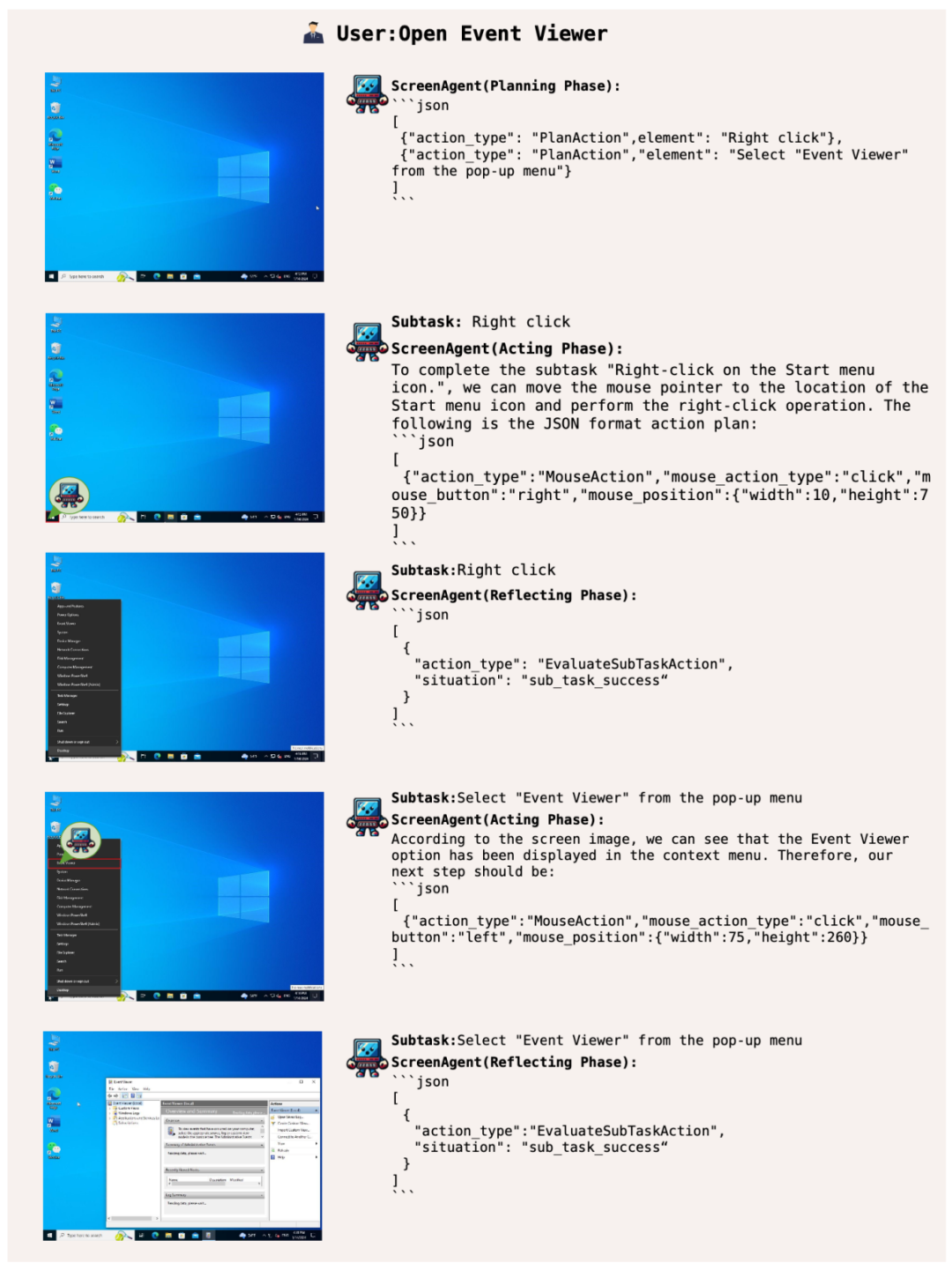
Biarkan ScreenAgent membuka pemapar acara Windows:
Kuasai kemahiran pejabat dan bermain dengan mudah dengan pejabat
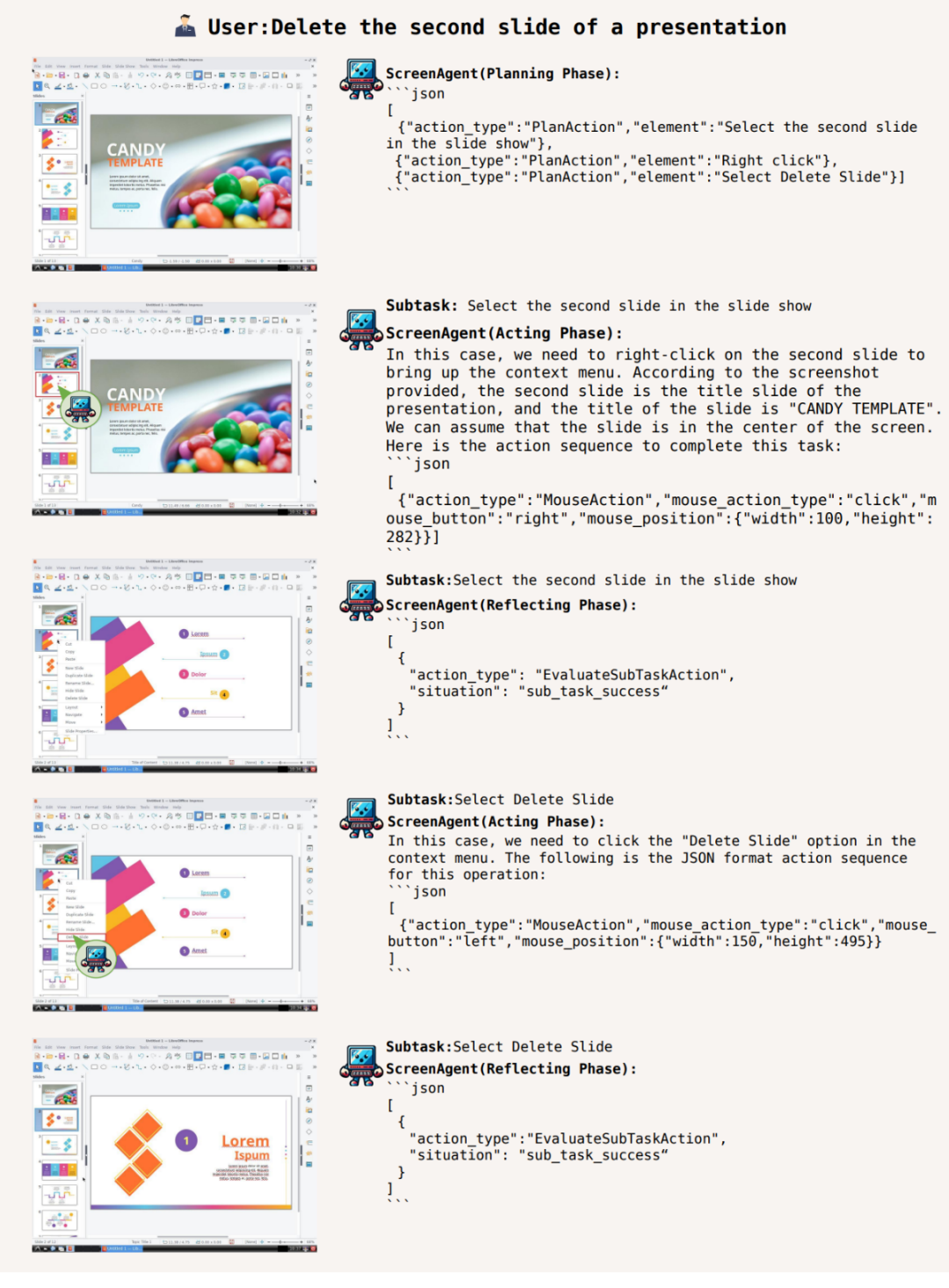
perisian pejabat, Skrin Di samping itu Sebagai contoh, mengikut penerangan teks pengguna, padamkan PPT pada halaman kedua yang dibuka:
Rancang sebelum mengambil tindakan, tahu di mana untuk berhenti dan dapatkan
Untuk menyelesaikan tugas tertentu , ia mesti dilakukan sebelum tugas dilaksanakan dengan baik dalam merancang aktiviti. ScreenAgent boleh membuat perancangan berdasarkan imej yang diperhatikan dan keperluan pengguna sebelum memulakan tugas, contohnya:
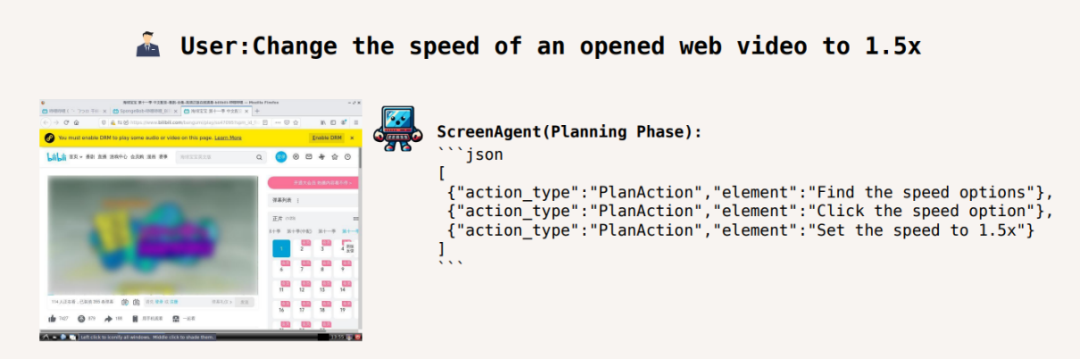
 Laraskan kelajuan main balik video kepada 1.5 kali:
Laraskan kelajuan main balik video kepada 1.5 kali:
Cari kereta bandar Magotan terpakai pada 58 Magotan. tapak web Harga:
Pasang xeyes dalam baris arahan:
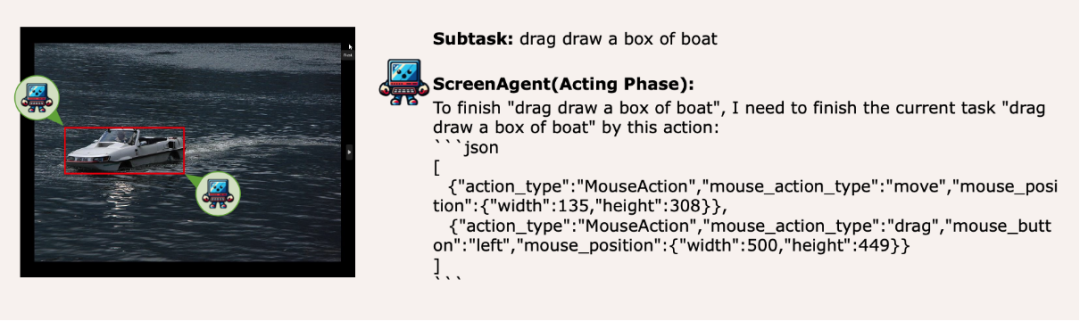
Penghijrahan keupayaan kedudukan visual, pemilihan tetikus adalah bebas tekanan

ScreenAgent juga mengekalkan keupayaan untuk mengesan objek semula jadi secara visual, dan boleh melukis bingkai pemilihan objek dengan menyeret tetikus:

kaedah yang diperlukan
mengajar cara berinteraksi dengan Interaksi langsung dengan antara muka grafik pengguna bukanlah perkara yang mudah. Ia memerlukan ejen untuk mempunyai pelbagai keupayaan komprehensif seperti perancangan tugas, pemahaman imej, kedudukan visual dan penggunaan alat. Terdapat kompromi tertentu dalam model sedia ada atau penyelesaian interaksi Contohnya, model seperti LLaVA-1.5 tidak mempunyai keupayaan kedudukan visual yang tepat pada imej bersaiz besar GPT-4V mempunyai perancangan misi yang sangat kuat, pemahaman imej dan keupayaan OCR, tetapi enggan memberi Dapatkan koordinat yang tepat. Penyelesaian sedia ada memerlukan anotasi manual bagi label digital tambahan pada imej, dan membenarkan model memilih elemen UI yang perlu diklik, seperti Mobile-Agent, UFO dan projek lain selain itu, model seperti CogAgent dan Fuyu-8B boleh menyokong imej resolusi tinggi Ia mempunyai input dan keupayaan kedudukan visual yang tepat, tetapi CogAgent tidak mempunyai keupayaan panggilan fungsi yang lengkap, dan Fuyu-8B tidak mempunyai keupayaan bahasa.
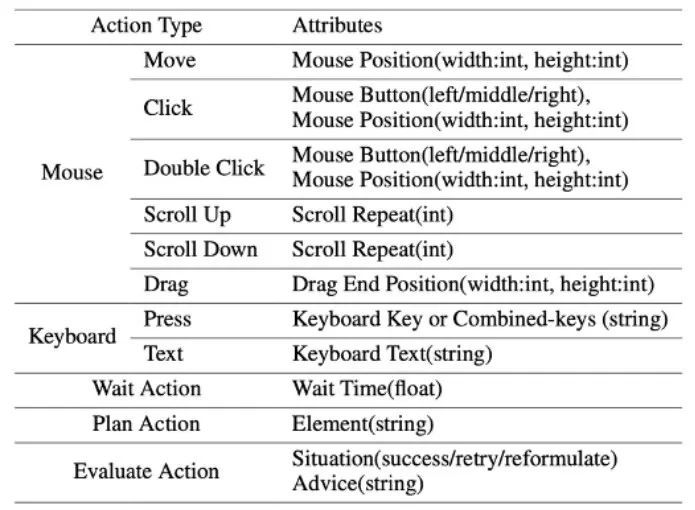
Untuk menyelesaikan masalah di atas, artikel itu mencadangkan untuk membina persekitaran baharu untuk ejen model bahasa visual (Ejen VLM) untuk berinteraksi dengan skrin komputer sebenar. Dalam persekitaran ini, ejen boleh memerhati tangkapan skrin dan memanipulasi antara muka pengguna grafik dengan mengeluarkan tindakan tetikus dan papan kekunci. Untuk membimbing Ejen VLM berinteraksi secara berterusan dengan skrin komputer, artikel itu membina proses pengendalian yang merangkumi "perancangan-pelaksanaan-pantulan". Semasa fasa perancangan, ejen diminta untuk memecahkan tugas pengguna kepada subtugas. Semasa fasa pelaksanaan, Ejen akan memerhati tangkapan skrin dan memberikan tindakan tetikus dan papan kekunci tertentu untuk melaksanakan subtugasan. Pengawal akan melaksanakan tindakan ini dan memberi maklum balas keputusan pelaksanaan kepada Ejen. Semasa fasa refleksi, Ejen memerhati keputusan pelaksanaan, menentukan status semasa dan memilih untuk meneruskan pelaksanaan, mencuba semula atau melaraskan pelan. Proses ini berterusan sehingga tugasan selesai. Perlu dinyatakan bahawa ScreenAgent tidak perlu menggunakan sebarang modul pengecaman teks atau pengecaman ikon, dan menggunakan pendekatan hujung ke hujung untuk melatih semua keupayaan model.
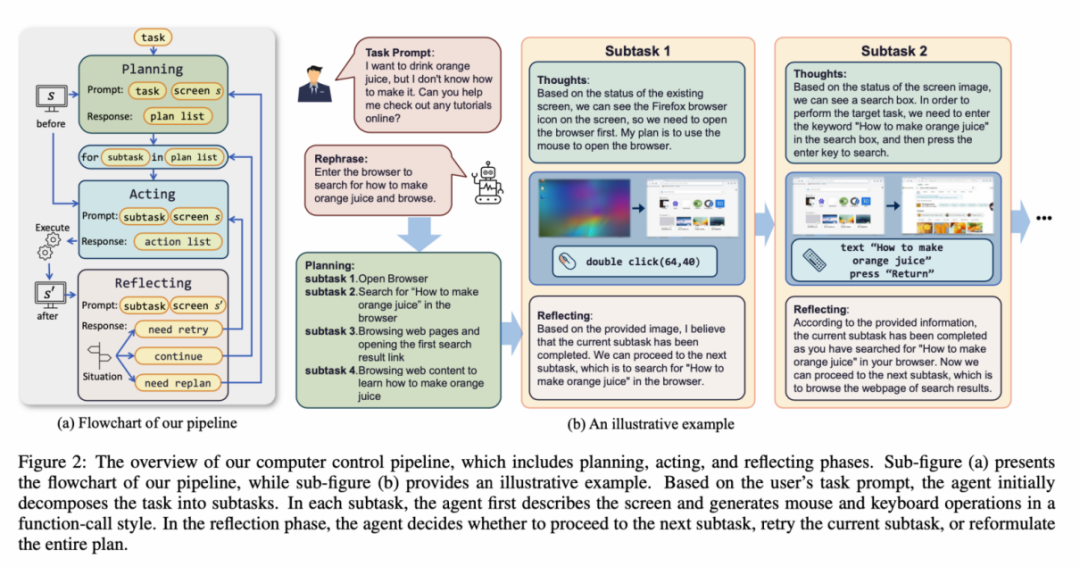
Persekitaran ScreenAgent merujuk kepada protokol sambungan desktop jauh VNC untuk mereka bentuk ruang tindakan Ejen, termasuk operasi klik tetikus dan papan kekunci yang paling asas memerlukan Ejen memberikan koordinat skrin yang tepat. Berbanding dengan memanggil API khusus untuk menyelesaikan tugas, kaedah ini lebih umum dan boleh digunakan pada pelbagai sistem pengendalian desktop dan aplikasi seperti Windows dan Linux Desktop.
ScreenAgent Dataset
Untuk melatih model ScreenAgent, artikel tersebut secara manual menganotasi set data ScreenAgent dengan maklumat kedudukan visual yang tepat. Set data ini merangkumi pelbagai tugas komputer harian, termasuk operasi fail, penyemakan imbas web, hiburan permainan dan senario lain dalam persekitaran Desktop Windows dan Linux.
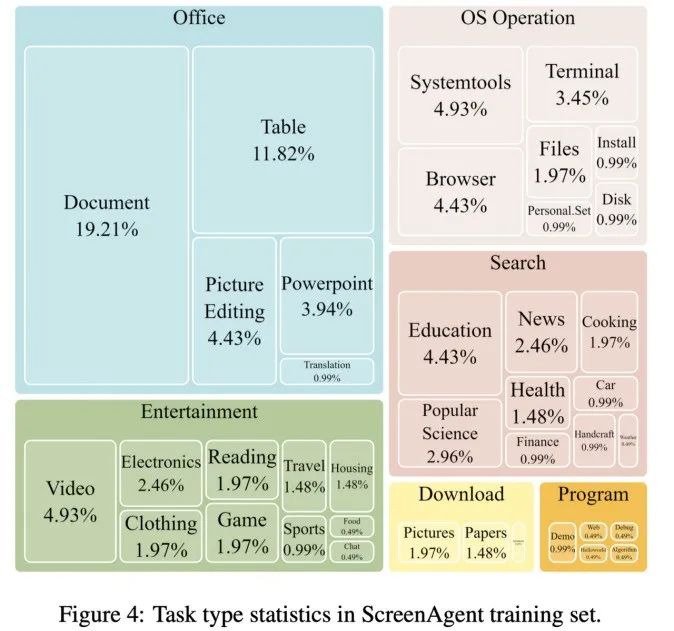
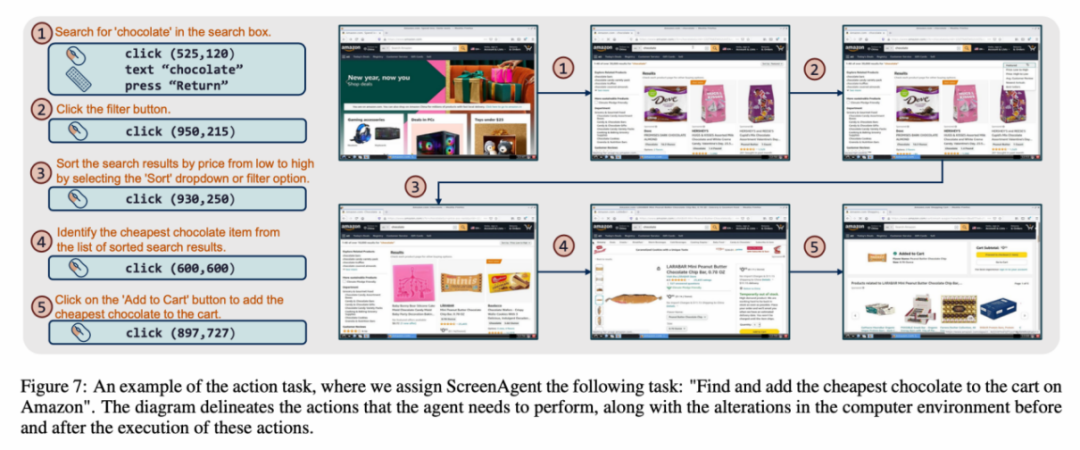
Setiap sampel dalam set data ialah proses lengkap untuk menyelesaikan tugasan, termasuk perihalan tindakan, tangkapan skrin dan tindakan tertentu yang dilaksanakan. Contohnya, dalam kes "menambah coklat paling murah pada troli beli-belah" di tapak web Amazon, anda perlu mencari kata kunci dalam kotak carian dahulu, kemudian gunakan penapis untuk mengisih harga dan akhirnya menambah item paling murah pada beli-belah troli. Keseluruhan set data mengandungi 273 rekod tugasan yang lengkap.
Hasil eksperimen
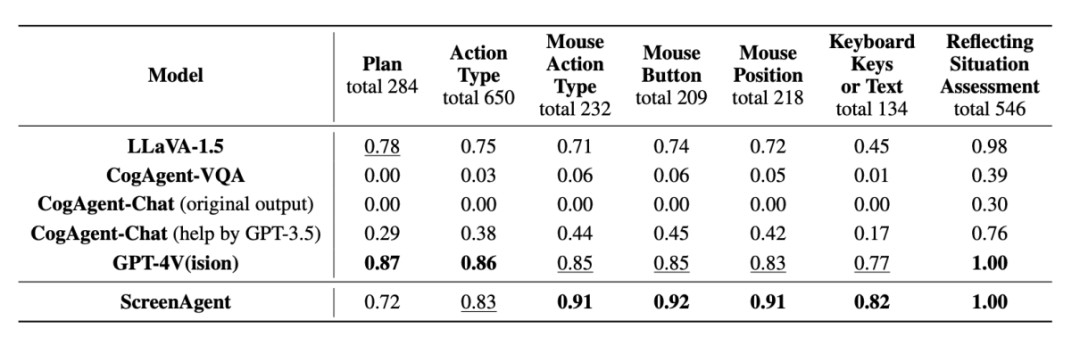
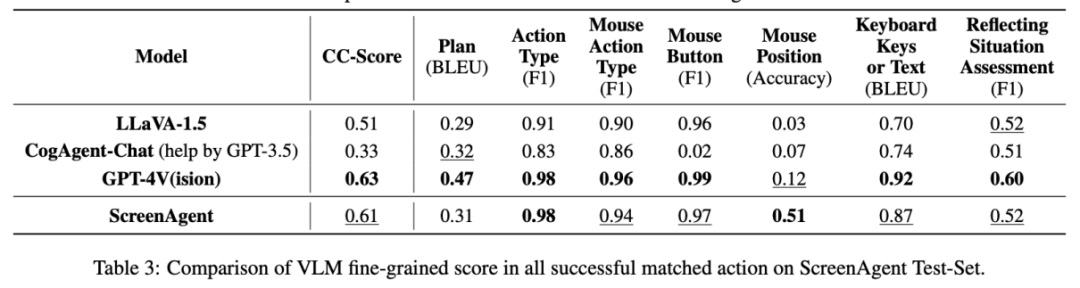
Dalam bahagian analisis eksperimen, penulis membandingkan ScreenAgent dengan berbilang model VLM sedia ada dari pelbagai sudut, terutamanya termasuk dua peringkat, keupayaan mengikut arahan dan ketepatan ramalan tindakan yang terperinci. Keupayaan berikut arahan terutamanya menguji sama ada model boleh mengeluarkan urutan tindakan dan jenis tindakan dengan betul dalam format JSON. Ketepatan ramalan atribut tindakan membandingkan sama ada nilai atribut setiap tindakan diramalkan dengan betul, seperti kedudukan klik tetikus, kekunci papan kekunci, dsb.
Perintah untuk mengikuti
🎜🎜Dari segi perintah berikut, tugas pertama Ejen adalah untuk mengeluarkan panggilan fungsi alat yang betul mengikut kata gesaan, iaitu, untuk mengeluarkan format JSON yang betul Dalam hal ini, kedua-dua ScreenAgent dan GPT-4V boleh mengikuti arahan dengan sangat baik, dan CogAgent asal Oleh kerana kekurangan sokongan data dalam bentuk panggilan API semasa latihan penalaan halus visual, keupayaan untuk mengeluarkan JSON hilang.
Kadar ketepatan ramalan atribut tindakan
Dari perspektif kadar ketepatan atribut tindakan, ScreenAgent juga telah mencapai tahap yang setanding dengan GPT-4V. Terutama, ScreenAgent jauh melebihi model sedia ada dalam ketepatan klik tetikus. Ini menunjukkan bahawa penalaan halus visual secara berkesan meningkatkan keupayaan kedudukan tepat model. Tambahan pula, kami juga melihat jurang yang jelas antara ScreenAgent dan GPT-4V dalam perancangan misi, yang menyerlahkan pengetahuan akal sehat GPT-4V dan keupayaan perancangan misi. . digunakan secara meluas dalam pelbagai aplikasi perisian dan sistem pengendalian. ScreenAgent boleh menyelesaikan tugasan yang diberikan oleh pengguna secara autonomi di bawah kawalan proses "pantulan-pelaksanaan-pelan". Dengan cara ini, pengguna boleh melihat setiap langkah penyiapan tugas dan lebih memahami pemikiran tingkah laku Ejen.
 Artikel sumber terbuka perisian kawalan, kod latihan model dan set data. Atas dasar ini, anda boleh meneroka kerja yang lebih canggih ke arah kecerdasan buatan am, seperti pembelajaran pengukuhan di bawah maklum balas alam sekitar, penerokaan aktif Ejen terhadap dunia terbuka, membina model dunia, perpustakaan kemahiran Ejen, dsb.
Artikel sumber terbuka perisian kawalan, kod latihan model dan set data. Atas dasar ini, anda boleh meneroka kerja yang lebih canggih ke arah kecerdasan buatan am, seperti pembelajaran pengukuhan di bawah maklum balas alam sekitar, penerokaan aktif Ejen terhadap dunia terbuka, membina model dunia, perpustakaan kemahiran Ejen, dsb.
Atas ialah kandungan terperinci Anda boleh mula menggunakan Windows dan Office secara langsung. Sangat mudah untuk mengendalikan komputer dengan ejen model yang besar.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Bagaimana untuk melihat dokumen perkataan dalam vscode Bagaimana untuk melihat dokumen perkataan dalam vscode
May 09, 2024 am 09:37 AM
Bagaimana untuk melihat dokumen perkataan dalam vscode Bagaimana untuk melihat dokumen perkataan dalam vscode
May 09, 2024 am 09:37 AM
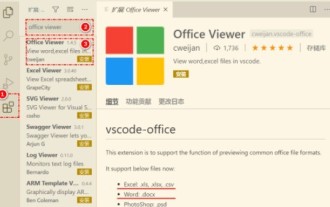
Mula-mula, buka perisian vscode pada komputer, klik ikon [Sambungan] di sebelah kiri, seperti yang ditunjukkan dalam ① dalam rajah Kemudian, masukkan [pemeriksa pejabat] dalam kotak carian antara muka sambungan, seperti yang ditunjukkan dalam ② dalam rajah . Kemudian, daripada carian Pilih [officeviewer] untuk memasang dalam hasil, seperti yang ditunjukkan dalam ③ dalam rajah Akhir sekali, buka fail, seperti docx, pdf, dsb., seperti yang ditunjukkan di bawah
 WPS dan Office tidak mempunyai fon Cina, dan nama fon Cina dipaparkan dalam bahasa Inggeris.
Jun 19, 2024 am 06:56 AM
WPS dan Office tidak mempunyai fon Cina, dan nama fon Cina dipaparkan dalam bahasa Inggeris.
Jun 19, 2024 am 06:56 AM
Komputer kawan saya, semua fon Cina seperti Lagu tiruan, gaya Kai, Xing Kai, Microsoft Yahei, dan lain-lain tidak boleh didapati di WPS dan OFFICE Editor di bawah akan memberitahu anda bagaimana untuk menyelesaikan masalah ini. Fon dalam sistem adalah biasa, tetapi semua fon dalam pilihan fon WPS tidak tersedia, hanya fon awan. OFFICE hanya mempunyai fon Inggeris, bukan sebarang fon Cina. Selepas memasang versi WPS yang berbeza, fon Inggeris tersedia, tetapi juga tiada fon Cina. Penyelesaian: Panel Kawalan → Kategori → Jam, Bahasa dan Wilayah → Tukar Bahasa Paparan → (Wilayah dan Bahasa) Pengurusan → (Bahasa untuk program bukan Unikod) Tukar Tetapan Serantau Sistem → Bahasa Cina (Ringkas, China) → Mulakan semula. Panel Kawalan, tukar mod paparan di penjuru kanan sebelah atas kepada "Kategori", Jam, Bahasa dan Wilayah, tukar
 Xiaomi Mi Pad 6 siri melancarkan Pejabat WPS peringkat PC dalam kuantiti penuh
Apr 25, 2024 pm 09:10 PM
Xiaomi Mi Pad 6 siri melancarkan Pejabat WPS peringkat PC dalam kuantiti penuh
Apr 25, 2024 pm 09:10 PM
Menurut berita dari laman web ini pada 25 April, Xiaomi secara rasmi mengumumkan hari ini bahawa Xiaomi Mi Pad 6, Mi Pad 6 Pro, Mi Pad 6 Max 14, dan Mi Pad 6 S Pro kini menyokong sepenuhnya WPSOffice peringkat PC. Antaranya, Xiaomi Mi Pad 6 Pro dan Xiaomi Mi Pad 6 perlu menaik taraf versi sistem kepada V816.0.4.0 dan ke atas sebelum mereka boleh memuat turun WPSOfficePC daripada Xiaomi App Store. WPSOfficePC mengguna pakai operasi dan susun atur yang sama seperti komputer, dan dipasangkan dengan aksesori papan kekunci tablet, ia boleh meningkatkan kecekapan pejabat. Mengikut pengalaman penilaian tapak ini sebelum ini, WPSOfficePC jauh lebih cekap apabila mengedit dokumen, borang, pembentangan dan fail lain. Selain itu, pelbagai fungsi yang menyusahkan untuk digunakan pada terminal mudah alih, seperti susun atur teks, sisipan gambar,
 rendering 3d, konfigurasi komputer? Apakah jenis komputer yang diperlukan untuk mereka bentuk pemaparan 3D?
May 06, 2024 pm 06:25 PM
rendering 3d, konfigurasi komputer? Apakah jenis komputer yang diperlukan untuk mereka bentuk pemaparan 3D?
May 06, 2024 pm 06:25 PM
rendering 3d, konfigurasi komputer? 1 Konfigurasi komputer adalah sangat penting untuk pemaparan 3D, dan prestasi perkakasan yang mencukupi diperlukan untuk memastikan kesan dan kelajuan pemaparan. Perenderan 23D memerlukan banyak pengiraan dan pemprosesan imej, jadi ia memerlukan CPU, kad grafik dan memori berprestasi tinggi. 3 Adalah disyorkan untuk mengkonfigurasi sekurang-kurangnya satu komputer dengan sekurang-kurangnya 6 teras dan 12 utas CPU, lebih daripada 16GB memori dan kad grafik berprestasi tinggi untuk memenuhi keperluan pemaparan 3D yang lebih tinggi. Pada masa yang sama, anda juga perlu memberi perhatian kepada pelesapan haba komputer dan konfigurasi bekalan kuasa untuk memastikan operasi komputer yang stabil. Apakah jenis komputer yang diperlukan untuk mereka bentuk pemaparan 3D? Saya juga seorang pereka, jadi saya akan memberikan anda satu set konfigurasi (saya akan menggunakannya semula) CPU: amd960t dengan 6 teras (atau 1090t overclocked secara langsung) Memori: 1333
 Kelajuan Internet Data Selular Perlahan pada iPhone: Pembetulan
May 03, 2024 pm 09:01 PM
Kelajuan Internet Data Selular Perlahan pada iPhone: Pembetulan
May 03, 2024 pm 09:01 PM
Menghadapi ketinggalan, sambungan data mudah alih perlahan pada iPhone? Biasanya, kekuatan internet selular pada telefon anda bergantung pada beberapa faktor seperti rantau, jenis rangkaian selular, jenis perayauan, dsb. Terdapat beberapa perkara yang boleh anda lakukan untuk mendapatkan sambungan Internet selular yang lebih pantas dan boleh dipercayai. Betulkan 1 – Paksa Mulakan Semula iPhone Kadangkala, paksa memulakan semula peranti anda hanya menetapkan semula banyak perkara, termasuk sambungan selular. Langkah 1 – Hanya tekan kekunci naikkan kelantangan sekali dan lepaskan. Seterusnya, tekan kekunci Turun Kelantangan dan lepaskannya semula. Langkah 2 - Bahagian seterusnya proses adalah untuk menahan butang di sebelah kanan. Biarkan iPhone selesai dimulakan semula. Dayakan data selular dan semak kelajuan rangkaian. Semak semula Betulkan 2 – Tukar mod data Walaupun 5G menawarkan kelajuan rangkaian yang lebih baik, ia berfungsi lebih baik apabila isyarat lemah
 Versi Kuaishou Sora 'Ke Ling' dibuka untuk ujian: menghasilkan video lebih 120-an, memahami fizik dengan lebih baik dan boleh memodelkan pergerakan kompleks dengan tepat
Jun 11, 2024 am 09:51 AM
Versi Kuaishou Sora 'Ke Ling' dibuka untuk ujian: menghasilkan video lebih 120-an, memahami fizik dengan lebih baik dan boleh memodelkan pergerakan kompleks dengan tepat
Jun 11, 2024 am 09:51 AM
Apa? Adakah Zootopia dibawa menjadi realiti oleh AI domestik? Didedahkan bersama-sama dengan video itu ialah model penjanaan video domestik berskala besar baharu yang dipanggil "Keling". Sora menggunakan laluan teknikal yang serupa dan menggabungkan beberapa inovasi teknologi yang dibangunkan sendiri untuk menghasilkan video yang bukan sahaja mempunyai pergerakan yang besar dan munasabah, tetapi juga mensimulasikan ciri-ciri dunia fizikal dan mempunyai keupayaan gabungan konsep dan imaginasi yang kuat. Mengikut data, Keling menyokong penjanaan video ultra panjang sehingga 2 minit pada 30fps, dengan resolusi sehingga 1080p dan menyokong berbilang nisbah aspek. Satu lagi perkara penting ialah Keling bukanlah demo atau demonstrasi hasil video yang dikeluarkan oleh makmal, tetapi aplikasi peringkat produk yang dilancarkan oleh Kuaishou, pemain terkemuka dalam bidang video pendek. Selain itu, tumpuan utama adalah untuk menjadi pragmatik, bukan untuk menulis cek kosong, dan pergi ke dalam talian sebaik sahaja ia dikeluarkan Model besar Ke Ling telah pun dikeluarkan di Kuaiying.
 Daya hidup kecerdasan super membangkitkan! Tetapi dengan kedatangan AI yang mengemas kini sendiri, ibu tidak perlu lagi bimbang tentang kesesakan data
Apr 29, 2024 pm 06:55 PM
Daya hidup kecerdasan super membangkitkan! Tetapi dengan kedatangan AI yang mengemas kini sendiri, ibu tidak perlu lagi bimbang tentang kesesakan data
Apr 29, 2024 pm 06:55 PM
Saya menangis hingga mati. Dunia sedang membina model besar. Data di Internet tidak mencukupi. Model latihan kelihatan seperti "The Hunger Games", dan penyelidik AI di seluruh dunia bimbang tentang cara memberi makan data ini kepada pemakan yang rakus. Masalah ini amat ketara dalam tugas berbilang modal. Pada masa mereka mengalami kerugian, pasukan pemula dari Jabatan Universiti Renmin China menggunakan model baharu mereka sendiri untuk menjadi yang pertama di China untuk menjadikan "suapan data yang dijana model itu sendiri" menjadi kenyataan. Selain itu, ia merupakan pendekatan serampang dua mata dari segi pemahaman dan sisi penjanaan Kedua-dua pihak boleh menjana data baharu berbilang modal yang berkualiti tinggi dan memberikan maklum balas data kepada model itu sendiri. Apakah model? Awaker 1.0, model berbilang modal besar yang baru sahaja muncul di Forum Zhongguancun. Siapa pasukan itu? Enjin Sophon. Diasaskan oleh Gao Yizhao, pelajar kedoktoran di Sekolah Kecerdasan Buatan Hillhouse Universiti Renmin.
 Tentera Udara A.S. mempamerkan jet pejuang AI pertamanya dengan profil tinggi! Menteri secara peribadi menjalankan pandu uji tanpa campur tangan semasa keseluruhan proses, dan 100,000 baris kod telah diuji selama 21 kali.
May 07, 2024 pm 05:00 PM
Tentera Udara A.S. mempamerkan jet pejuang AI pertamanya dengan profil tinggi! Menteri secara peribadi menjalankan pandu uji tanpa campur tangan semasa keseluruhan proses, dan 100,000 baris kod telah diuji selama 21 kali.
May 07, 2024 pm 05:00 PM
Baru-baru ini, bulatan tentera telah terharu dengan berita: jet pejuang tentera AS kini boleh melengkapkan pertempuran udara automatik sepenuhnya menggunakan AI. Ya, baru-baru ini, jet pejuang AI tentera AS telah didedahkan buat pertama kali, mendedahkan misterinya. Nama penuh pesawat pejuang ini ialah Variable Stability Simulator Test Aircraft (VISTA). Ia diterbangkan sendiri oleh Setiausaha Tentera Udara AS untuk mensimulasikan pertempuran udara satu lawan satu. Pada 2 Mei, Setiausaha Tentera Udara A.S. Frank Kendall berlepas menggunakan X-62AVISTA di Pangkalan Tentera Udara Edwards Ambil perhatian bahawa semasa penerbangan selama satu jam, semua tindakan penerbangan telah diselesaikan secara autonomi oleh AI! Kendall berkata - "Sejak beberapa dekad yang lalu, kami telah memikirkan tentang potensi tanpa had pertempuran udara-ke-udara autonomi, tetapi ia sentiasa kelihatan di luar jangkauan." Namun kini,
