
import torch import torch.nn.functional as F def temperature_sampling(logits, temperature=1.0): logits = logits / temperature probabilities = F.softmax(logits, dim=-1) sampled_token = torch.multinomial(probabilities, 1) return sampled_token.item()
 Peranti teknologi
AI
Pengenalan kepada lima kaedah pensampelan dalam tugas penjanaan bahasa semula jadi dan pelaksanaan kod Pytorch
Peranti teknologi
AI
Pengenalan kepada lima kaedah pensampelan dalam tugas penjanaan bahasa semula jadi dan pelaksanaan kod Pytorch
Pengenalan kepada lima kaedah pensampelan dalam tugas penjanaan bahasa semula jadi dan pelaksanaan kod Pytorch

Dalam tugas penjanaan bahasa semula jadi, kaedah pensampelan ialah teknik untuk mendapatkan output teks daripada model generatif. Artikel ini akan membincangkan 5 kaedah biasa dan melaksanakannya menggunakan PyTorch.
1. Penyahkodan Tamak
Dalam penyahkodan tamak, model generatif meramalkan perkataan jujukan output berdasarkan urutan masa langkah demi masa. Pada setiap langkah masa, model mengira taburan kebarangkalian bersyarat bagi setiap perkataan, dan kemudian memilih perkataan dengan kebarangkalian bersyarat tertinggi sebagai output langkah masa semasa. Perkataan ini menjadi input kepada langkah masa seterusnya, dan proses penjanaan diteruskan sehingga beberapa syarat penamatan dipenuhi, seperti urutan panjang tertentu atau penanda akhir khas. Ciri Penyahkodan Greedy ialah setiap kali perkataan dengan kebarangkalian bersyarat semasa tertinggi dipilih sebagai output, tanpa mengambil kira penyelesaian optimum global. Kaedah ini mudah dan cekap, tetapi mungkin menghasilkan urutan terhasil yang kurang tepat atau pelbagai. Penyahkodan Tamak sesuai untuk beberapa tugas penjanaan jujukan yang mudah, tetapi untuk tugas yang kompleks, strategi penyahkodan yang lebih kompleks mungkin diperlukan untuk meningkatkan kualiti penjanaan.
Walaupun kaedah ini lebih pantas dalam pengiraan, memandangkan penyahkodan tamak hanya menumpukan pada penyelesaian optimum tempatan, ia mungkin menyebabkan teks yang dijana kekurangan kepelbagaian atau tidak tepat, dan penyelesaian optimum global tidak dapat diperoleh.
Walaupun penyahkodan tamak mempunyai hadnya, ia masih digunakan secara meluas dalam banyak tugas penjanaan jujukan, terutamanya apabila pelaksanaan pantas diperlukan atau tugas itu agak mudah.
def greedy_decoding(input_ids, max_tokens=300): with torch.inference_mode(): for _ in range(max_tokens): outputs = model(input_ids) next_token_logits = outputs.logits[:, -1, :] next_token = torch.argmax(next_token_logits, dim=-1) if next_token == tokenizer.eos_token_id: break input_ids = torch.cat([input_ids, rearrange(next_token, 'c -> 1 c')], dim=-1) generated_text = tokenizer.decode(input_ids[0]) return generated_text
2. Beam Search
Beam Search ialah lanjutan daripada penyahkodan tamak, yang mengatasi masalah optimum tempatan penyahkodan tamak dengan mengekalkan berbilang jujukan calon pada setiap langkah masa.
Carian rasuk ialah kaedah menjana teks yang mengekalkan perkataan calon dengan kebarangkalian tertinggi pada setiap langkah masa, dan kemudian terus berkembang berdasarkan perkataan calon ini pada langkah masa seterusnya sehingga penghujung generasi. Kaedah ini boleh meningkatkan kepelbagaian teks yang dijana dengan mempertimbangkan berbilang laluan perkataan calon.
Dalam carian rasuk, model menjana berbilang jujukan calon secara serentak dan bukannya memilih hanya satu jujukan terbaik. Ia meramalkan perkataan yang mungkin pada langkah masa seterusnya berdasarkan urutan separa yang dijana pada masa ini dan keadaan tersembunyi, dan mengira taburan kebarangkalian bersyarat bagi setiap perkataan. Kaedah menjana berbilang jujukan calon secara selari ini membantu meningkatkan kecekapan carian, membolehkan model mencari jujukan dengan kebarangkalian keseluruhan yang paling tinggi dengan lebih cepat.
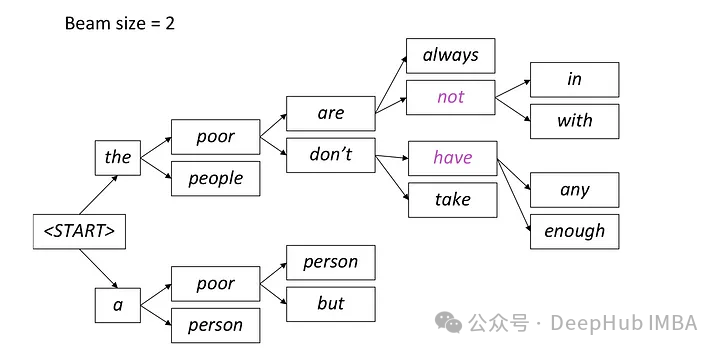
Pada setiap langkah, hanya dua laluan yang paling mungkin disimpan, dan laluan yang selebihnya dibuang mengikut tetapan rasuk = 2. Proses ini berterusan sehingga syarat berhenti dipenuhi, yang boleh menghasilkan token akhir urutan atau mencapai panjang jujukan maksimum yang ditetapkan oleh model. Output akhir akan menjadi urutan dengan kebarangkalian keseluruhan tertinggi antara set laluan terakhir.
from einops import rearrange import torch.nn.functional as F def beam_search(input_ids, max_tokens=100, beam_size=2): beam_scores = torch.zeros(beam_size).to(device) beam_sequences = input_ids.clone() active_beams = torch.ones(beam_size, dtype=torch.bool) for step in range(max_tokens): outputs = model(beam_sequences) logits = outputs.logits[:, -1, :] probs = F.softmax(logits, dim=-1) top_scores, top_indices = torch.topk(probs.flatten(), k=beam_size, sorted=False) beam_indices = top_indices // probs.shape[-1] token_indices = top_indices % probs.shape[-1] beam_sequences = torch.cat([ beam_sequences[beam_indices], token_indices.unsqueeze(-1)], dim=-1) beam_scores = top_scores active_beams = ~(token_indices == tokenizer.eos_token_id) if not active_beams.any(): print("no active beams") break best_beam = beam_scores.argmax() best_sequence = beam_sequences[best_beam] generated_text = tokenizer.decode(best_sequence) return generated_text3. Pensampelan Suhu
Pensampelan parameter suhu (Pensampelan Suhu) sering digunakan dalam model generatif berasaskan kebarangkalian, seperti model bahasa. Ia mengawal kepelbagaian teks yang dijana dengan memperkenalkan parameter yang dipanggil "Suhu" untuk melaraskan taburan kebarangkalian output model.
Dalam pensampelan parameter suhu, apabila model menjana perkataan pada setiap langkah masa, ia akan mengira taburan kebarangkalian bersyarat bagi perkataan tersebut. Model kemudian membahagikan nilai kebarangkalian bagi setiap perkataan dalam taburan kebarangkalian bersyarat ini dengan parameter suhu, menormalkan hasilnya, dan memperoleh taburan kebarangkalian ternormal baharu. Nilai suhu yang lebih tinggi menjadikan pengedaran kebarangkalian lebih lancar, sekali gus meningkatkan kepelbagaian teks yang dihasilkan. Perkataan berkebarangkalian rendah juga mempunyai kebarangkalian yang lebih tinggi untuk dipilih manakala nilai suhu yang lebih rendah akan menjadikan taburan kebarangkalian lebih tertumpu dan lebih berkemungkinan untuk memilih perkataan berkemungkinan tinggi, jadi teks yang dihasilkan lebih deterministik. Akhir sekali, model mengambil sampel secara rawak mengikut taburan kebarangkalian ternormal baharu ini dan memilih perkataan yang dijana. Pensampelan Top-K juga boleh meningkatkan kepelbagaian teks, dan kepelbagaian teks yang dihasilkan boleh dikawal dengan mengehadkan bilangan perkataan calon
import torch import torch.nn.functional as F def temperature_sampling(logits, temperature=1.0): logits = logits / temperature probabilities = F.softmax(logits, dim=-1) sampled_token = torch.multinomial(probabilities, 1) return sampled_token.item()
Salin selepas log masuk
.import torch import torch.nn.functional as F def temperature_sampling(logits, temperature=1.0): logits = logits / temperature probabilities = F.softmax(logits, dim=-1) sampled_token = torch.multinomial(probabilities, 1) return sampled_token.item()
5、Top-P (Nucleus) Sampling:
Nucleus Sampling(核采样),也被称为Top-p Sampling旨在在保持生成文本质量的同时增加多样性。这种方法可以视作是Top-K Sampling的一种变体,它在每个时间步根据模型输出的概率分布选择概率累积超过给定阈值p的词语集合,然后在这个词语集合中进行随机采样。这种方法会动态调整候选词语的数量,以保持一定的文本多样性。

在Nucleus Sampling中,模型在每个时间步生成词语时,首先按照概率从高到低对词汇表中的所有词语进行排序,然后模型计算累积概率,并找到累积概率超过给定阈值p的最小词语子集,这个子集就是所谓的“核”(nucleus)。模型在这个核中进行随机采样,根据词语的概率分布来选择最终输出的词语。这样做可以保证所选词语的总概率超过了阈值p,同时也保持了一定的多样性。
参数p是Nucleus Sampling中的重要参数,它决定了所选词语的概率总和。p的值会被设置在(0,1]之间,表示词语总概率的一个下界。
Nucleus Sampling 能够保持一定的生成质量,因为它在一定程度上考虑了概率分布。通过选择概率总和超过给定阈值p的词语子集进行随机采样,Nucleus Sampling 能够增加生成文本的多样性。
def top_p_sampling(input_ids, max_tokens=100, top_p=0.95): with torch.inference_mode(): for _ in range(max_tokens): outputs = model(input_ids) next_token_logits = outputs.logits[:, -1, :] sorted_logits, sorted_indices = torch.sort(next_token_logits, descending=True) sorted_probabilities = F.softmax(sorted_logits, dim=-1) cumulative_probs = torch.cumsum(sorted_probabilities, dim=-1) sorted_indices_to_remove = cumulative_probs > top_p sorted_indices_to_remove[..., 0] = False indices_to_remove = sorted_indices[sorted_indices_to_remove] next_token_logits.scatter_(-1, indices_to_remove[None, :], float('-inf')) probs = F.softmax(next_token_logits, dim=-1) next_token = torch.multinomial(probs, num_samples=1) input_ids = torch.cat([input_ids, next_token], dim=-1) generated_text = tokenizer.decode(input_ids[0]) return generated_text总结
自然语言生成任务中,采样方法是非常重要的。选择合适的采样方法可以在一定程度上影响生成文本的质量、多样性和效率。上面介绍的几种采样方法各有特点,适用于不同的应用场景和需求。
贪婪解码是一种简单直接的方法,适用于速度要求较高的情况,但可能导致生成文本缺乏多样性。束搜索通过保留多个候选序列来克服贪婪解码的局部最优问题,生成的文本质量更高,但计算开销较大。Top-K 采样和核采样可以控制生成文本的多样性,适用于需要平衡质量和多样性的场景。温度参数采样则可以根据温度参数灵活调节生成文本的多样性,适用于需要平衡多样性和质量的任务。
Atas ialah kandungan terperinci Pengenalan kepada lima kaedah pensampelan dalam tugas penjanaan bahasa semula jadi dan pelaksanaan kod Pytorch. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Bytedance Cutting melancarkan keahlian super SVIP: 499 yuan untuk langganan tahunan berterusan, menyediakan pelbagai fungsi AI
Jun 28, 2024 am 03:51 AM
Bytedance Cutting melancarkan keahlian super SVIP: 499 yuan untuk langganan tahunan berterusan, menyediakan pelbagai fungsi AI
Jun 28, 2024 am 03:51 AM
Laman web ini melaporkan pada 27 Jun bahawa Jianying ialah perisian penyuntingan video yang dibangunkan oleh FaceMeng Technology, anak syarikat ByteDance Ia bergantung pada platform Douyin dan pada asasnya menghasilkan kandungan video pendek untuk pengguna platform tersebut Windows , MacOS dan sistem pengendalian lain. Jianying secara rasmi mengumumkan peningkatan sistem keahliannya dan melancarkan SVIP baharu, yang merangkumi pelbagai teknologi hitam AI, seperti terjemahan pintar, penonjolan pintar, pembungkusan pintar, sintesis manusia digital, dsb. Dari segi harga, yuran bulanan untuk keratan SVIP ialah 79 yuan, yuran tahunan ialah 599 yuan (nota di laman web ini: bersamaan dengan 49.9 yuan sebulan), langganan bulanan berterusan ialah 59 yuan sebulan, dan langganan tahunan berterusan ialah 499 yuan setahun (bersamaan dengan 41.6 yuan sebulan) . Di samping itu, pegawai yang dipotong juga menyatakan bahawa untuk meningkatkan pengalaman pengguna, mereka yang telah melanggan VIP asal
 Pembantu pengekodan AI yang ditambah konteks menggunakan Rag dan Sem-Rag
Jun 10, 2024 am 11:08 AM
Pembantu pengekodan AI yang ditambah konteks menggunakan Rag dan Sem-Rag
Jun 10, 2024 am 11:08 AM
Tingkatkan produktiviti, kecekapan dan ketepatan pembangun dengan menggabungkan penjanaan dipertingkatkan semula dan memori semantik ke dalam pembantu pengekodan AI. Diterjemah daripada EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, pengarang JanakiramMSV. Walaupun pembantu pengaturcaraan AI asas secara semulajadi membantu, mereka sering gagal memberikan cadangan kod yang paling relevan dan betul kerana mereka bergantung pada pemahaman umum bahasa perisian dan corak penulisan perisian yang paling biasa. Kod yang dijana oleh pembantu pengekodan ini sesuai untuk menyelesaikan masalah yang mereka bertanggungjawab untuk menyelesaikannya, tetapi selalunya tidak mematuhi piawaian pengekodan, konvensyen dan gaya pasukan individu. Ini selalunya menghasilkan cadangan yang perlu diubah suai atau diperhalusi agar kod itu diterima ke dalam aplikasi
 Tujuh Soalan Temuduga Teknikal GenAI & LLM yang Cool
Jun 07, 2024 am 10:06 AM
Tujuh Soalan Temuduga Teknikal GenAI & LLM yang Cool
Jun 07, 2024 am 10:06 AM
Untuk mengetahui lebih lanjut tentang AIGC, sila layari: 51CTOAI.x Komuniti https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou berbeza daripada bank soalan tradisional yang boleh dilihat di mana-mana sahaja di Internet memerlukan pemikiran di luar kotak. Model Bahasa Besar (LLM) semakin penting dalam bidang sains data, kecerdasan buatan generatif (GenAI) dan kecerdasan buatan. Algoritma kompleks ini meningkatkan kemahiran manusia dan memacu kecekapan dan inovasi dalam banyak industri, menjadi kunci kepada syarikat untuk kekal berdaya saing. LLM mempunyai pelbagai aplikasi Ia boleh digunakan dalam bidang seperti pemprosesan bahasa semula jadi, penjanaan teks, pengecaman pertuturan dan sistem pengesyoran. Dengan belajar daripada sejumlah besar data, LLM dapat menjana teks
 Bolehkah penalaan halus benar-benar membolehkan LLM mempelajari perkara baharu: memperkenalkan pengetahuan baharu boleh menjadikan model menghasilkan lebih banyak halusinasi
Jun 11, 2024 pm 03:57 PM
Bolehkah penalaan halus benar-benar membolehkan LLM mempelajari perkara baharu: memperkenalkan pengetahuan baharu boleh menjadikan model menghasilkan lebih banyak halusinasi
Jun 11, 2024 pm 03:57 PM
Model Bahasa Besar (LLM) dilatih pada pangkalan data teks yang besar, di mana mereka memperoleh sejumlah besar pengetahuan dunia sebenar. Pengetahuan ini dibenamkan ke dalam parameter mereka dan kemudiannya boleh digunakan apabila diperlukan. Pengetahuan tentang model ini "diperbaharui" pada akhir latihan. Pada akhir pra-latihan, model sebenarnya berhenti belajar. Selaraskan atau perhalusi model untuk mempelajari cara memanfaatkan pengetahuan ini dan bertindak balas dengan lebih semula jadi kepada soalan pengguna. Tetapi kadangkala pengetahuan model tidak mencukupi, dan walaupun model boleh mengakses kandungan luaran melalui RAG, ia dianggap berfaedah untuk menyesuaikan model kepada domain baharu melalui penalaan halus. Penalaan halus ini dilakukan menggunakan input daripada anotasi manusia atau ciptaan LLM lain, di mana model menemui pengetahuan dunia sebenar tambahan dan menyepadukannya
 Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) set data memainkan peranan penting dalam mempromosikan penyelidikan pemprosesan bahasa semula jadi (NLP). Set data QA berkualiti tinggi bukan sahaja boleh digunakan untuk memperhalusi model, tetapi juga menilai dengan berkesan keupayaan model bahasa besar (LLM), terutamanya keupayaan untuk memahami dan menaakul tentang pengetahuan saintifik. Walaupun pada masa ini terdapat banyak set data QA saintifik yang meliputi bidang perubatan, kimia, biologi dan bidang lain, set data ini masih mempunyai beberapa kekurangan. Pertama, borang data adalah agak mudah, kebanyakannya adalah soalan aneka pilihan. Ia mudah dinilai, tetapi mengehadkan julat pemilihan jawapan model dan tidak dapat menguji sepenuhnya keupayaan model untuk menjawab soalan saintifik. Sebaliknya, Soal Jawab terbuka
 Lima sekolah pembelajaran mesin yang anda tidak tahu
Jun 05, 2024 pm 08:51 PM
Lima sekolah pembelajaran mesin yang anda tidak tahu
Jun 05, 2024 pm 08:51 PM
Pembelajaran mesin ialah cabang penting kecerdasan buatan yang memberikan komputer keupayaan untuk belajar daripada data dan meningkatkan keupayaan mereka tanpa diprogramkan secara eksplisit. Pembelajaran mesin mempunyai pelbagai aplikasi dalam pelbagai bidang, daripada pengecaman imej dan pemprosesan bahasa semula jadi kepada sistem pengesyoran dan pengesanan penipuan, dan ia mengubah cara hidup kita. Terdapat banyak kaedah dan teori yang berbeza dalam bidang pembelajaran mesin, antaranya lima kaedah yang paling berpengaruh dipanggil "Lima Sekolah Pembelajaran Mesin". Lima sekolah utama ialah sekolah simbolik, sekolah sambungan, sekolah evolusi, sekolah Bayesian dan sekolah analogi. 1. Simbolisme, juga dikenali sebagai simbolisme, menekankan penggunaan simbol untuk penaakulan logik dan ekspresi pengetahuan. Aliran pemikiran ini percaya bahawa pembelajaran adalah proses penolakan terbalik, melalui sedia ada
 Prestasi SOTA, kaedah AI ramalan pertalian protein-ligan pelbagai mod Xiamen, menggabungkan maklumat permukaan molekul buat kali pertama
Jul 17, 2024 pm 06:37 PM
Prestasi SOTA, kaedah AI ramalan pertalian protein-ligan pelbagai mod Xiamen, menggabungkan maklumat permukaan molekul buat kali pertama
Jul 17, 2024 pm 06:37 PM
Editor |. KX Dalam bidang penyelidikan dan pembangunan ubat, meramalkan pertalian pengikatan protein dan ligan dengan tepat dan berkesan adalah penting untuk pemeriksaan dan pengoptimuman ubat. Walau bagaimanapun, kajian semasa tidak mengambil kira peranan penting maklumat permukaan molekul dalam interaksi protein-ligan. Berdasarkan ini, penyelidik dari Universiti Xiamen mencadangkan rangka kerja pengekstrakan ciri berbilang mod (MFE) novel, yang buat pertama kalinya menggabungkan maklumat mengenai permukaan protein, struktur dan jujukan 3D, dan menggunakan mekanisme perhatian silang untuk membandingkan ciri modaliti yang berbeza penjajaran. Keputusan eksperimen menunjukkan bahawa kaedah ini mencapai prestasi terkini dalam meramalkan pertalian mengikat protein-ligan. Tambahan pula, kajian ablasi menunjukkan keberkesanan dan keperluan maklumat permukaan protein dan penjajaran ciri multimodal dalam rangka kerja ini. Penyelidikan berkaitan bermula dengan "S
 Meletakkan pasaran seperti AI, GlobalFoundries memperoleh teknologi gallium nitrida Tagore Technology dan pasukan berkaitan
Jul 15, 2024 pm 12:21 PM
Meletakkan pasaran seperti AI, GlobalFoundries memperoleh teknologi gallium nitrida Tagore Technology dan pasukan berkaitan
Jul 15, 2024 pm 12:21 PM
Menurut berita dari laman web ini pada 5 Julai, GlobalFoundries mengeluarkan kenyataan akhbar pada 1 Julai tahun ini, mengumumkan pemerolehan teknologi power gallium nitride (GaN) Tagore Technology dan portfolio harta intelek, dengan harapan dapat mengembangkan bahagian pasarannya dalam kereta dan Internet of Things dan kawasan aplikasi pusat data kecerdasan buatan untuk meneroka kecekapan yang lebih tinggi dan prestasi yang lebih baik. Memandangkan teknologi seperti AI generatif terus berkembang dalam dunia digital, galium nitrida (GaN) telah menjadi penyelesaian utama untuk pengurusan kuasa yang mampan dan cekap, terutamanya dalam pusat data. Laman web ini memetik pengumuman rasmi bahawa semasa pengambilalihan ini, pasukan kejuruteraan Tagore Technology akan menyertai GLOBALFOUNDRIES untuk membangunkan lagi teknologi gallium nitride. G
