

Sumber pengkomputeran yang digunakan hanyalah 2/25 model Resapan Video Stabil(SVD) tradisional!
AnimateLCM-SVD-xt dikeluarkan, yang menukar model resapan video untuk denoising berulang, yang memakan masa dan memerlukan banyak pengiraan.
Mari kita lihat dahulu kesan animasi yang dihasilkan.
Gaya cyberpunk mudah dikawal Budak itu memakai fon kepala dan berdiri di jalan bandar neon:
 Gambar
Gambar
Gaya realistik juga boleh digunakan, pasangan pengantin sedang berpelukan, memegang sejambak yang halus. dalam Menyaksikan cinta di bawah tembok batu purba:
 gambar
gambar
Gaya fiksyen sains, dan juga mempunyai rasa pencerobohan makhluk asing ke bumi:
 gambar
gambar
The MSVnimateLCtM, The MSVnimate Universiti China Hong Kong, Dicadangkan bersama oleh penyelidik dari Avolution AI, Makmal Kepintaran Buatan Shanghai dan Institut Penyelidikan SenseTime. . SVD Lebih pantas dan lebih cekap:
 Gambar
Gambar
Pada masa ini, kod AnimateLCM akan menjadi sumber terbuka dan akan ada demo dalam talian yang tersedia untuk permainan percubaan. Mulakan dan cuba demoSeperti yang anda lihat daripada antara muka demo, AnimateLCM pada masa ini mempunyai tiga versi AnimateLCM-SVD-xt adalah untuk penjanaan imej kepada video secara umum; -i2v adalah untuk penjanaan Imej kepada video yang diperibadikan.
 Pictures
Pictures
Di bawah ialah kawasan konfigurasi di mana anda boleh memilih model Dreambooth asas atau model LoRA, dan melaraskan nilai alfa LoRA melalui peluncur. . Gambar
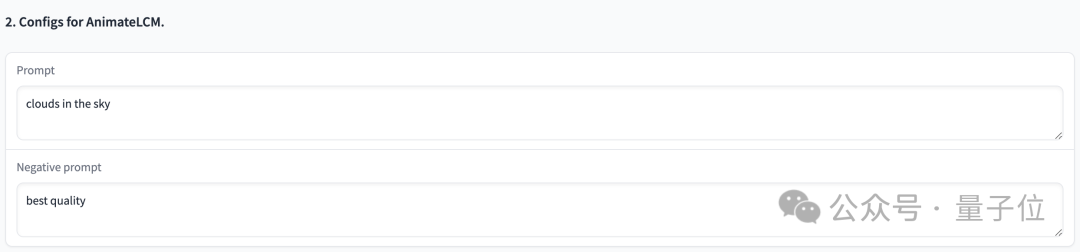
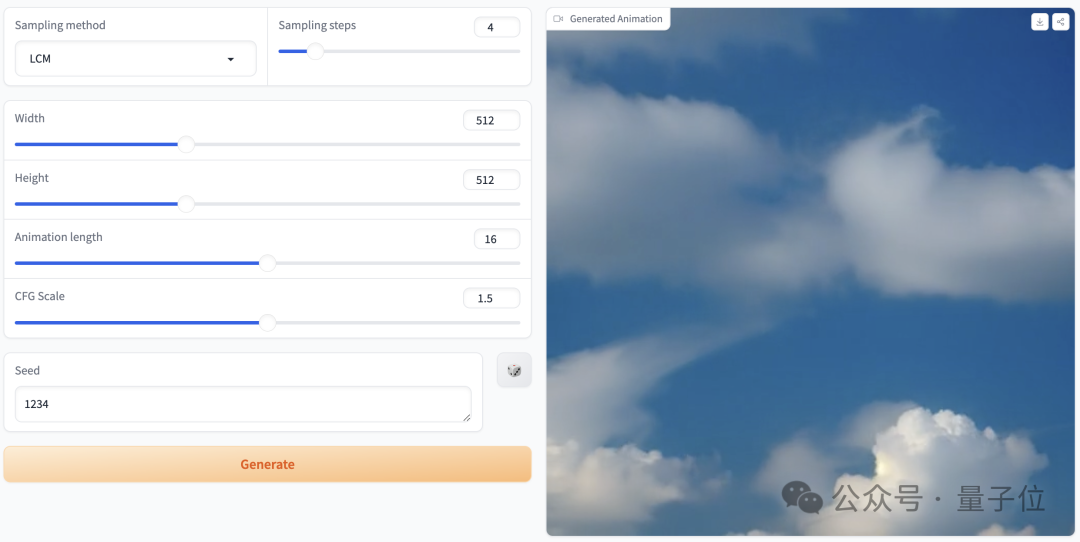
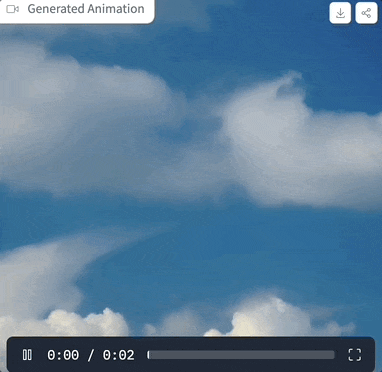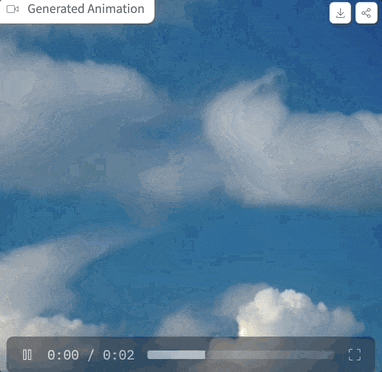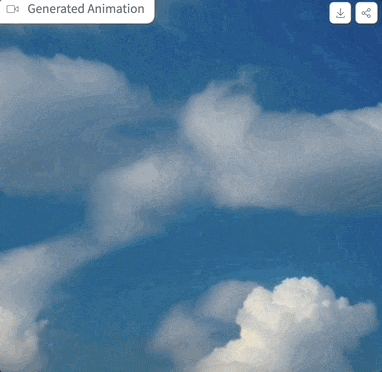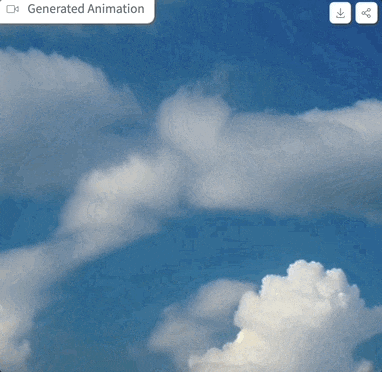
Mari kita mulakan Selepas mencubanya, perkataan gesaan ialah "awan di langit", tetapan parameter adalah seperti yang ditunjukkan di atas, dan langkah pensampelan hanya 4 langkah, kesan yang dihasilkan adalah seperti ini: gambar
gambar
 Gambar
Gambar
 gambar
gambar
 .
.
 gambar
gambar
 Gambar
Gambar
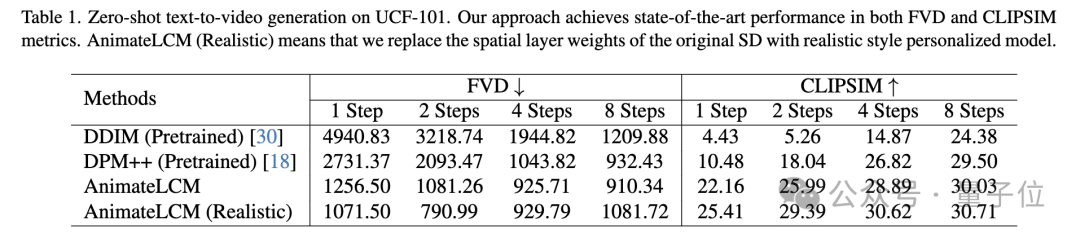
Berhati-hati bahawa walaupun model resapan video telah mendapat perhatian yang semakin meningkat kerana keupayaannya untuk menghasilkan video yang koheren dan berkeyakinan tinggi, salah satu kesukaran ialah proses denoising berulang bukan sahaja memakan masa tetapi juga intensif secara pengiraan, yang mengehadkannya. skop permohonan.
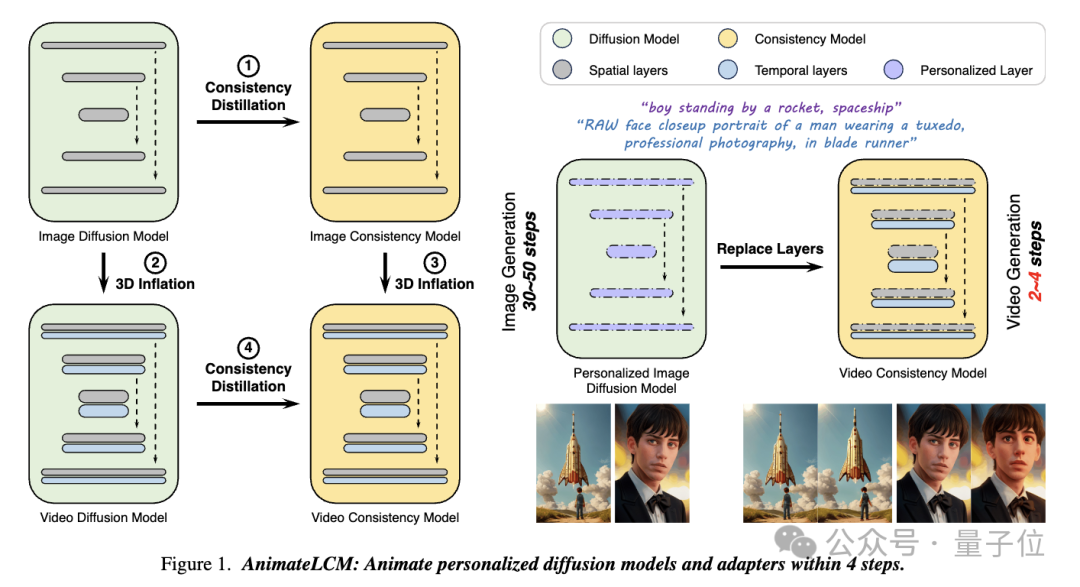
Dalam karya ini AnimateLCM, para penyelidik telah diilhamkan oleh Model Konsistensi (CM), yang memudahkan model penyebaran imej yang telah terlatih untuk mengurangkan langkah-langkah yang diperlukan untuk pensampelan dan berjaya menskalakan penjanaan imej bersyarat Model Ketekalan Terpendam (LCM ) .
 Gambar
Gambar
Secara khusus, penyelidik mencadangkan strategi Pembelajaran Konsistensi Terpisah(Pembelajaran Konsistensi Terpisah).
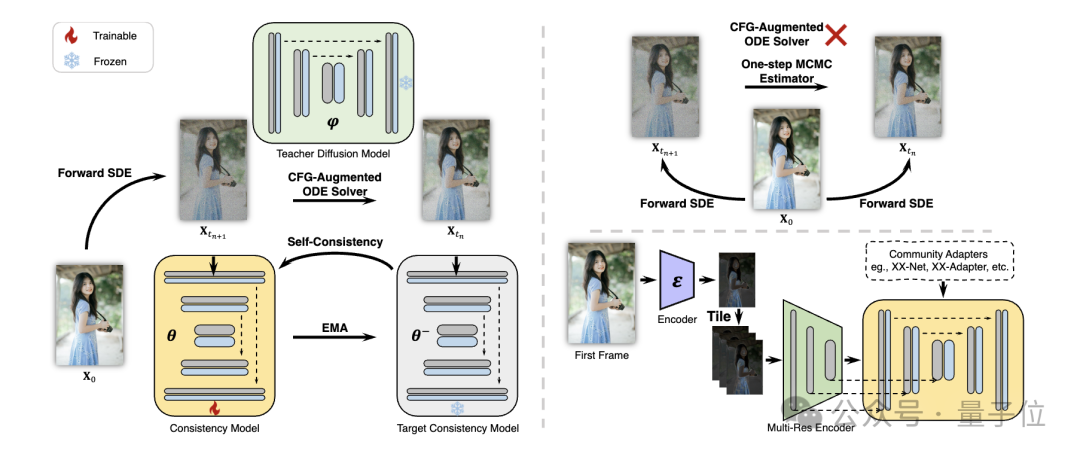
Mula-mula menyaring model resapan stabil ke dalam model ketekalan imej pada set data teks imej berkualiti tinggi, dan kemudian lakukan penyulingan konsisten pada data video untuk mendapatkan model ketekalan video. Strategi ini meningkatkan kecekapan latihan dengan latihan secara berasingan di peringkat spatial dan temporal.
 Gambar
Gambar
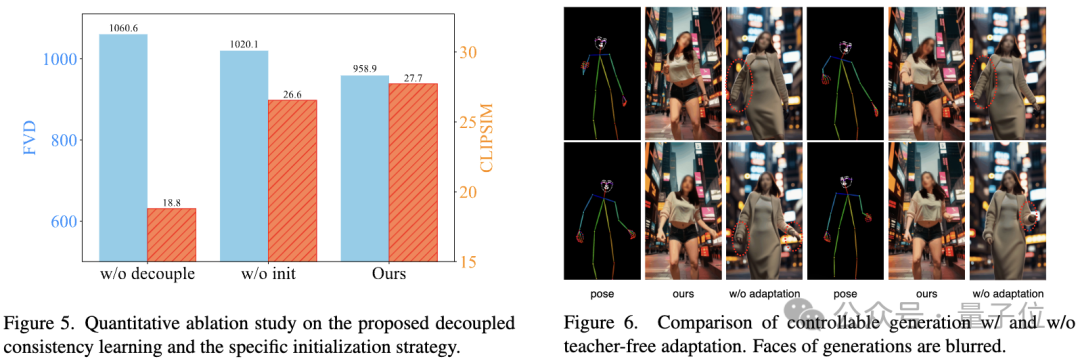
Selain itu, untuk melaksanakan pelbagai fungsi penyesuai plug-and-play (contohnya, menggunakan ControlNet untuk mencapai penjanaan yang boleh dikawal) dalam komuniti Stable Diffusion, para penyelidik juga mencadangkan Teacher - Percuma Sesuaikan strategi (Penyesuaian Tanpa Guru) untuk menjadikan penyesuai kawalan sedia ada lebih konsisten dengan model ketekalan dan mencapai penjanaan video terkawal yang lebih baik.
 Gambar
Gambar
 Picture
Picture
 Picture
Picture
1]https:// animatelcm. github.io/
Atas ialah kandungan terperinci Hasilkan 25 bingkai animasi berkualiti tinggi dalam dua langkah, dikira sebagai 8% daripada SVD |. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Kekunci yang manakah harus saya tekan untuk memulihkan apabila saya tidak boleh menaip pada papan kekunci komputer saya?
Kekunci yang manakah harus saya tekan untuk memulihkan apabila saya tidak boleh menaip pada papan kekunci komputer saya?
 pencetus_ralat
pencetus_ralat
 Bagaimana untuk menyegarkan bios
Bagaimana untuk menyegarkan bios
 Kaedah penyulitan data
Kaedah penyulitan data
 Bagaimana untuk menutup port 135
Bagaimana untuk menutup port 135
 Analisis statistik
Analisis statistik
 Bagaimana untuk memulihkan video yang telah dialih keluar secara rasmi daripada Douyin
Bagaimana untuk memulihkan video yang telah dialih keluar secara rasmi daripada Douyin
 Bagaimana untuk menyemak nilai MD5
Bagaimana untuk menyemak nilai MD5








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



