
 Java
javaTutorial
Nilaikan kesan prestasi cache peringkat pertama MyBatis dalam persekitaran serentak
Java
javaTutorial
Nilaikan kesan prestasi cache peringkat pertama MyBatis dalam persekitaran serentak
Nilaikan kesan prestasi cache peringkat pertama MyBatis dalam persekitaran serentak


Tajuk: Analisis kesan aplikasi cache peringkat pertama mybatis dalam persekitaran serentak
Pengenalan:
Apabila menggunakan mybatis untuk akses pangkalan data, cache peringkat pertama didayakan secara lalai kesan ke atas pangkalan data bilangan lawatan dan meningkatkan prestasi sistem. Walau bagaimanapun, dalam persekitaran serentak, cache peringkat pertama mungkin mempunyai beberapa masalah Artikel ini akan menganalisis kesan aplikasi cache peringkat pertama mybatis dalam persekitaran serentak dan memberikan contoh kod tertentu.
1. Gambaran keseluruhan cache peringkat pertama
Cache peringkat pertama mybatis ialah cache peringkat sesi Ia didayakan secara lalai dan selamat untuk benang. Idea teras cache peringkat pertama adalah untuk cache hasil setiap pertanyaan dalam sesi Jika parameter pertanyaan seterusnya adalah sama, keputusan akan diperoleh terus dari cache tanpa menanyakan pangkalan data lagi, yang mana. boleh mengurangkan bilangan capaian pangkalan data.
2. Kesan aplikasi cache peringkat pertama
- Kurangkan bilangan akses pangkalan data: Dengan menggunakan cache peringkat pertama, anda boleh mengurangkan bilangan akses pangkalan data dan meningkatkan prestasi sistem. Dalam persekitaran serentak, berbilang benang berkongsi sesi yang sama dan boleh berkongsi data dalam cache, mengelakkan operasi pertanyaan pangkalan data berulang.
- Tingkatkan kelajuan tindak balas sistem: Memandangkan cache peringkat pertama boleh memperoleh hasil terus daripada cache tanpa menanyakan pangkalan data, ia boleh mengurangkan masa tindak balas sistem dan meningkatkan pengalaman pengguna dengan banyak. . yang diperolehi oleh benang daripada cache adalah data lama, yang akan membawa kepada ketidakkonsistenan data. Penyelesaian kepada masalah ini ialah menggunakan cache peringkat kedua atau memuat semula cache secara manual.
- Contoh kod:
- Andaikan terdapat antara muka UserDao dan fail UserMapper.xml, UserDao mentakrifkan kaedah getUserById untuk menanyakan maklumat pengguna berdasarkan ID pengguna. Contoh kod adalah seperti berikut:
public interface UserDao {
User getUserById(int id);
}- Fail konfigurasi UserMapper.xml
<mapper namespace="com.example.UserDao"> <select id="getUserById" resultType="com.example.User"> SELECT * FROM user WHERE id = #{id} </select> </mapper>Salin selepas log masukKod menggunakan cache peringkat pertama - 🜎 kod cache di atas keputusan Kepada cache peringkat pertama, pertanyaan kedua mendapat keputusan terus daripada cache tanpa menanya pangkalan data sekali lagi. Ini boleh mengurangkan bilangan capaian pangkalan data dan meningkatkan prestasi sistem. Kesimpulan: Cache peringkat pertama mybatis boleh mengurangkan bilangan capaian pangkalan data dan meningkatkan prestasi sistem secara berkesan dalam persekitaran serentak. Walau bagaimanapun, apabila berbilang rangkaian berkongsi sesi yang sama, mungkin terdapat isu ketidakkonsistenan data. Oleh itu, dalam aplikasi sebenar, adalah perlu untuk mempertimbangkan sama ada untuk menggunakan cache peringkat pertama mengikut keperluan perniagaan tertentu, dan menggunakan strategi yang sepadan untuk menyelesaikan masalah yang berpotensi. Pada masa yang sama, menggunakan strategi caching yang sesuai dan cara teknikal, seperti menggunakan cache peringkat kedua atau menyegarkan semula cache secara manual, boleh mengoptimumkan lagi prestasi sistem.
public class Main { public static void main(String[] args) { SqlSessionFactory sqlSessionFactory = MyBatisUtil.getSqlSessionFactory(); // 获取SqlSessionFactory SqlSession sqlSession = sqlSessionFactory.openSession(); // 打开一个会话 UserDao userDao = sqlSession.getMapper(UserDao.class); // 获取UserDao的实例 User user1 = userDao.getUserById(1); // 第一次查询,会将结果缓存到一级缓存中 User user2 = userDao.getUserById(1); // 第二次查询,直接从缓存中获取结果 System.out.println(user1); System.out.println(user2); sqlSession.close(); // 关闭会话 } }Salin selepas log masuk Atas ialah kandungan terperinci Nilaikan kesan prestasi cache peringkat pertama MyBatis dalam persekitaran serentak. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1374
1374
 52
52

 Langkah terperinci untuk membersihkan memori di Xiaohongshu
Apr 26, 2024 am 10:43 AM
Langkah terperinci untuk membersihkan memori di Xiaohongshu
Apr 26, 2024 am 10:43 AM
1. Buka Xiaohongshu, klik Saya di sudut kanan bawah 2. Klik ikon tetapan, klik Umum 3. Klik Kosongkan Cache
 Apa yang perlu dilakukan jika telefon Huawei anda mempunyai memori yang tidak mencukupi (Kaedah praktikal untuk menyelesaikan masalah memori yang tidak mencukupi)
Apr 29, 2024 pm 06:34 PM
Apa yang perlu dilakukan jika telefon Huawei anda mempunyai memori yang tidak mencukupi (Kaedah praktikal untuk menyelesaikan masalah memori yang tidak mencukupi)
Apr 29, 2024 pm 06:34 PM
Memori yang tidak mencukupi pada telefon mudah alih Huawei telah menjadi masalah biasa yang dihadapi oleh ramai pengguna, dengan peningkatan dalam aplikasi mudah alih dan fail media. Untuk membantu pengguna menggunakan sepenuhnya ruang storan telefon bimbit mereka, artikel ini akan memperkenalkan beberapa kaedah praktikal untuk menyelesaikan masalah memori yang tidak mencukupi pada telefon mudah alih Huawei. 1. Bersihkan cache: rekod sejarah dan data tidak sah untuk mengosongkan ruang memori dan mengosongkan fail sementara yang dijana oleh aplikasi. Cari "Storan" dalam tetapan telefon Huawei anda, klik "Kosongkan Cache" dan pilih butang "Kosongkan Cache" untuk memadam fail cache aplikasi. 2. Nyahpasang aplikasi yang jarang digunakan: Untuk mengosongkan ruang memori, padamkan beberapa aplikasi yang jarang digunakan. Seret ia ke bahagian atas skrin telefon, tekan lama ikon "Nyahpasang" aplikasi yang ingin anda padamkan, kemudian klik butang pengesahan untuk menyelesaikan penyahpasangan. 3.Aplikasi mudah alih untuk
 Cara menyempurnakan deepseek di dalam negara
Feb 19, 2025 pm 05:21 PM
Cara menyempurnakan deepseek di dalam negara
Feb 19, 2025 pm 05:21 PM
Penalaan setempat model kelas DeepSeek menghadapi cabaran sumber dan kepakaran pengkomputeran yang tidak mencukupi. Untuk menangani cabaran-cabaran ini, strategi berikut boleh diterima pakai: Kuantisasi model: Menukar parameter model ke dalam bilangan bulat ketepatan rendah, mengurangkan jejak memori. Gunakan model yang lebih kecil: Pilih model pretrained dengan parameter yang lebih kecil untuk penalaan halus tempatan yang lebih mudah. Pemilihan data dan pra-proses: Pilih data berkualiti tinggi dan lakukan pra-proses yang sesuai untuk mengelakkan kualiti data yang lemah yang mempengaruhi keberkesanan model. Latihan Batch: Untuk set data yang besar, beban data dalam kelompok untuk latihan untuk mengelakkan limpahan memori. Percepatan dengan GPU: Gunakan kad grafik bebas untuk mempercepatkan proses latihan dan memendekkan masa latihan.
 SOTA terbaharu nuScenes |. SparseAD: Pertanyaan jarang membantu pemanduan autonomi hujung ke hujung yang cekap!
Apr 17, 2024 pm 06:22 PM
SOTA terbaharu nuScenes |. SparseAD: Pertanyaan jarang membantu pemanduan autonomi hujung ke hujung yang cekap!
Apr 17, 2024 pm 06:22 PM
Ditulis di hadapan & titik permulaan Paradigma hujung ke hujung menggunakan rangka kerja bersatu untuk mencapai pelbagai tugas dalam sistem pemanduan autonomi. Walaupun kesederhanaan dan kejelasan paradigma ini, prestasi kaedah pemanduan autonomi hujung ke hujung pada subtugas masih jauh ketinggalan berbanding kaedah tugasan tunggal. Pada masa yang sama, ciri pandangan mata burung (BEV) padat yang digunakan secara meluas dalam kaedah hujung ke hujung sebelum ini menyukarkan untuk membuat skala kepada lebih banyak modaliti atau tugasan. Paradigma pemanduan autonomi hujung ke hujung (SparseAD) tertumpu carian jarang dicadangkan di sini, di mana carian jarang mewakili sepenuhnya keseluruhan senario pemanduan, termasuk ruang, masa dan tugas, tanpa sebarang perwakilan BEV yang padat. Khususnya, seni bina jarang bersatu direka bentuk untuk kesedaran tugas termasuk pengesanan, penjejakan dan pemetaan dalam talian. Di samping itu, berat
 Apa yang perlu dilakukan jika pelayar Edge menggunakan terlalu banyak memori Apa yang perlu dilakukan jika pelayar Edge menggunakan terlalu banyak memori
May 09, 2024 am 11:10 AM
Apa yang perlu dilakukan jika pelayar Edge menggunakan terlalu banyak memori Apa yang perlu dilakukan jika pelayar Edge menggunakan terlalu banyak memori
May 09, 2024 am 11:10 AM
1. Mula-mula, masukkan pelayar Edge dan klik tiga titik di penjuru kanan sebelah atas. 2. Kemudian, pilih [Sambungan] dalam bar tugas. 3. Seterusnya, tutup atau nyahpasang pemalam yang anda tidak perlukan.
 Dengan hanya $250, pengarah teknikal Hugging Face mengajar anda cara memperhalusi Llama 3
May 06, 2024 pm 03:52 PM
Dengan hanya $250, pengarah teknikal Hugging Face mengajar anda cara memperhalusi Llama 3
May 06, 2024 pm 03:52 PM
Model bahasa besar sumber terbuka yang biasa seperti Llama3 yang dilancarkan oleh model Meta, Mistral dan Mixtral yang dilancarkan oleh MistralAI, dan Jamba yang dilancarkan oleh AI21 Lab telah menjadi pesaing OpenAI. Dalam kebanyakan kes, pengguna perlu memperhalusi model sumber terbuka ini berdasarkan data mereka sendiri untuk melancarkan potensi model sepenuhnya. Tidak sukar untuk memperhalusi model bahasa besar (seperti Mistral) berbanding model kecil menggunakan Q-Learning pada GPU tunggal, tetapi penalaan halus yang cekap bagi model besar seperti Llama370b atau Mixtral kekal sebagai cabaran sehingga kini . Oleh itu, Philipp Sch, pengarah teknikal HuggingFace
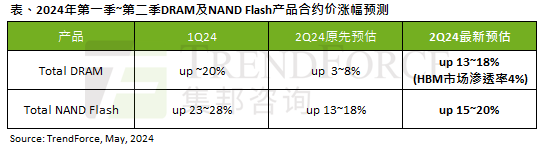 Kesan gelombang AI adalah jelas TrendForce telah menyemak semula ramalannya untuk memori DRAM dan harga kontrak memori kilat NAND meningkat pada suku ini.
May 07, 2024 pm 09:58 PM
Kesan gelombang AI adalah jelas TrendForce telah menyemak semula ramalannya untuk memori DRAM dan harga kontrak memori kilat NAND meningkat pada suku ini.
May 07, 2024 pm 09:58 PM
Menurut laporan tinjauan TrendForce, gelombang AI mempunyai impak yang besar pada memori DRAM dan pasaran memori flash NAND. Dalam berita laman web ini pada 7 Mei, TrendForce berkata dalam laporan penyelidikan terbarunya hari ini bahawa agensi itu telah meningkatkan kenaikan harga kontrak untuk dua jenis produk storan pada suku ini. Secara khusus, TrendForce pada asalnya menganggarkan bahawa harga kontrak memori DRAM pada suku kedua 2024 akan meningkat sebanyak 3~8%, dan kini menganggarkannya pada 13~18% dari segi memori kilat NAND, anggaran asal akan meningkat sebanyak 13~ 18%, dan anggaran baharu ialah 15%. ~20%, hanya eMMC/UFS mempunyai peningkatan yang lebih rendah sebanyak 10%. ▲Sumber imej TrendForce TrendForce menyatakan bahawa agensi itu pada asalnya menjangkakan untuk meneruskan
 Adakah win11 mengambil kurang memori daripada win10?
Apr 18, 2024 am 12:57 AM
Adakah win11 mengambil kurang memori daripada win10?
Apr 18, 2024 am 12:57 AM
Ya, secara keseluruhan, Win11 menggunakan kurang memori daripada Win10. Pengoptimuman termasuk kernel sistem yang lebih ringan, pengurusan memori yang lebih baik, pilihan hibernasi baharu dan proses latar belakang yang lebih sedikit. Ujian menunjukkan bahawa jejak memori Win11 biasanya 5-10% lebih rendah daripada Win10 dalam konfigurasi yang serupa. Tetapi penggunaan memori juga dipengaruhi oleh konfigurasi perkakasan, aplikasi dan tetapan sistem.
