
 Peranti teknologi
AI
Pecah ke lapisan bawah AI! Pasukan NUS Youyang menggunakan model resapan untuk membina parameter rangkaian saraf, LeCun menyukainya
Peranti teknologi
AI
Pecah ke lapisan bawah AI! Pasukan NUS Youyang menggunakan model resapan untuk membina parameter rangkaian saraf, LeCun menyukainya
Pecah ke lapisan bawah AI! Pasukan NUS Youyang menggunakan model resapan untuk membina parameter rangkaian saraf, LeCun menyukainya

Model resapan telah membawa masuk aplikasi baharu utama -
Sama seperti Sora menjana video, ia menjana parameter untuk rangkaian saraf dan terus menembusi ke lapisan bawah AI!
Ini adalah hasil penyelidikan sumber terbuka terkini pasukan Profesor You Yang di Universiti Nasional Singapura, bersama-sama dengan UCB, Makmal Meta AI dan institusi lain.

Secara khusus, pasukan penyelidik mencadangkan model resapan p(arameter)-diff untuk menjana parameter rangkaian saraf.
Gunakannya untuk menjana parameter rangkaian, kelajuan sehingga 44 kali lebih pantas daripada latihan langsung, dan prestasinya tidak kalah.
Selepas model dikeluarkan, ia dengan cepat membangkitkan perbincangan hangat dalam komuniti AI.
Sesetengah orang malah secara langsung menyatakan bahawa ini pada asasnya bersamaan dengan AI mencipta AI baharu.

Malah gergasi AI LeCun memuji pencapaian ini selepas melihatnya, mengatakan bahawa ia benar-benar idea yang comel.
Malah, p-diff memang mempunyai kepentingan yang sama seperti Sora Dr. Fuzhao Xue (Xue Fuzhao) dari makmal yang sama menerangkan secara terperinci:
Sora menjana data berdimensi tinggi, iaitu video, Ini. menjadikan Sora simulator dunia (menghampirkan AGI dari satu dimensi).
Dan kerja ini, penyebaran rangkaian saraf, boleh menjana parameter dalam model, berpotensi untuk menjadi pelajar/pengoptimum bertaraf dunia meta, bergerak ke arah AGI dari satu lagi dimensi penting yang baharu.

Berbalik kepada topik, bagaimanakah p-diff menjana parameter rangkaian saraf?
Menggabungkan pengekod auto dengan model resapan
Untuk memahami masalah ini, kita mesti terlebih dahulu memahami ciri kerja model resapan dan rangkaian saraf.
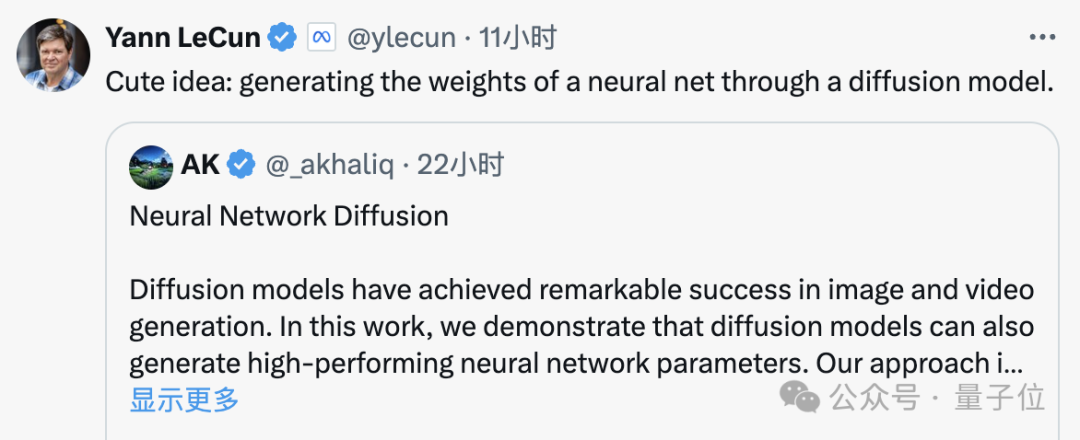
Proses penjanaan resapan ialah transformasi daripada pengedaran rawak kepada pengedaran yang sangat spesifik Melalui penambahan bunyi kompaun, maklumat visual dikurangkan kepada pengedaran hingar yang mudah.
Latihan rangkaian saraf juga mengikuti proses transformasi ini dan juga boleh direndahkan dengan menambah bunyi Diilhamkan oleh ciri ini, penyelidik mencadangkan kaedah p-diff.
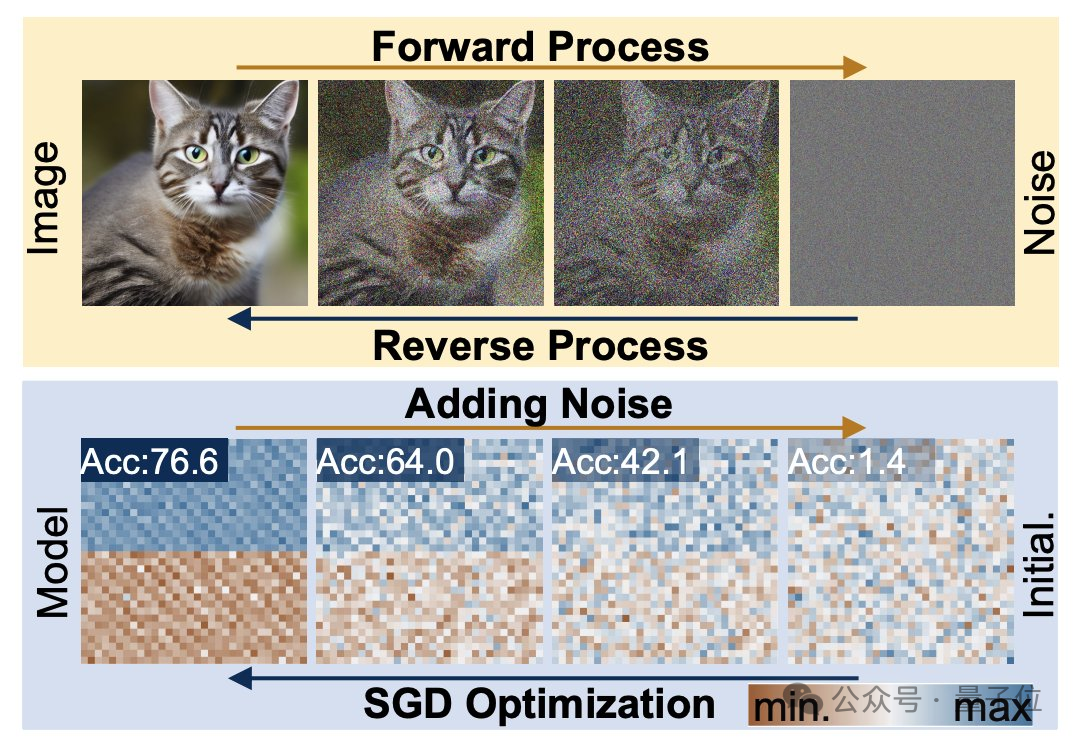
Dari sudut pandangan struktur, p-diff direka oleh pasukan penyelidik berdasarkan model resapan terpendam standard dan digabungkan dengan pengekod auto.
Penyelidik terlebih dahulu memilih sebahagian daripada parameter rangkaian yang telah dilatih dan berprestasi baik, dan mengembangkannya ke dalam bentuk vektor satu dimensi.
Kemudian gunakan pengekod automatik untuk mengekstrak perwakilan terpendam daripada vektor satu dimensi sebagai data latihan untuk model resapan Ini boleh menangkap ciri utama parameter asal.
Semasa proses latihan, penyelidik membenarkan p-diff mempelajari pengedaran parameter melalui proses ke hadapan dan ke belakang Selepas selesai, model resapan mensintesis perwakilan berpotensi ini daripada hingar rawak seperti proses penjanaan maklumat visual.
Akhir sekali, perwakilan terpendam yang baru dijana dipulihkan kepada parameter rangkaian oleh penyahkod yang sepadan dengan pengekod dan digunakan untuk membina model baharu.
Rajah di bawah ialah taburan parameter model ResNet-18 yang dilatih dari awal menggunakan 3 benih rawak melalui p-diff, menunjukkan corak taburan antara lapisan berbeza dan antara parameter berbeza dalam lapisan yang sama.

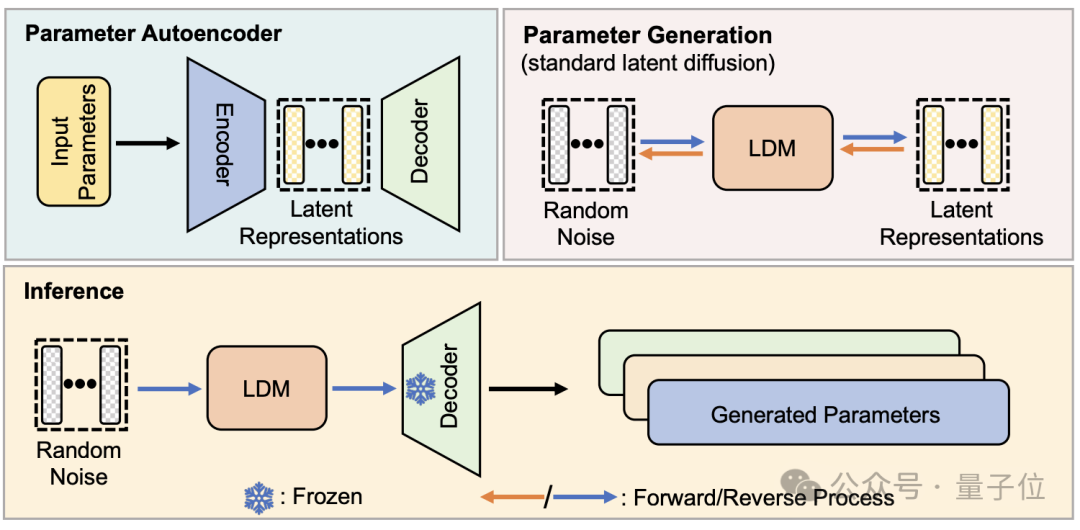
Untuk menilai kualiti parameter yang dijana oleh p-diff, para penyelidik mengujinya pada 8 set data menggunakan 3 jenis rangkaian saraf dua saiz setiap satu.
Dalam jadual di bawah, tiga nombor dalam setiap kumpulan mewakili keputusan penilaian model asal, model bersepadu dan model yang dijana dengan p-diff.
Seperti yang anda boleh lihat daripada keputusan, prestasi model yang dijana dengan p-diff pada dasarnya hampir atau lebih baik daripada model asal yang dilatih secara manual.
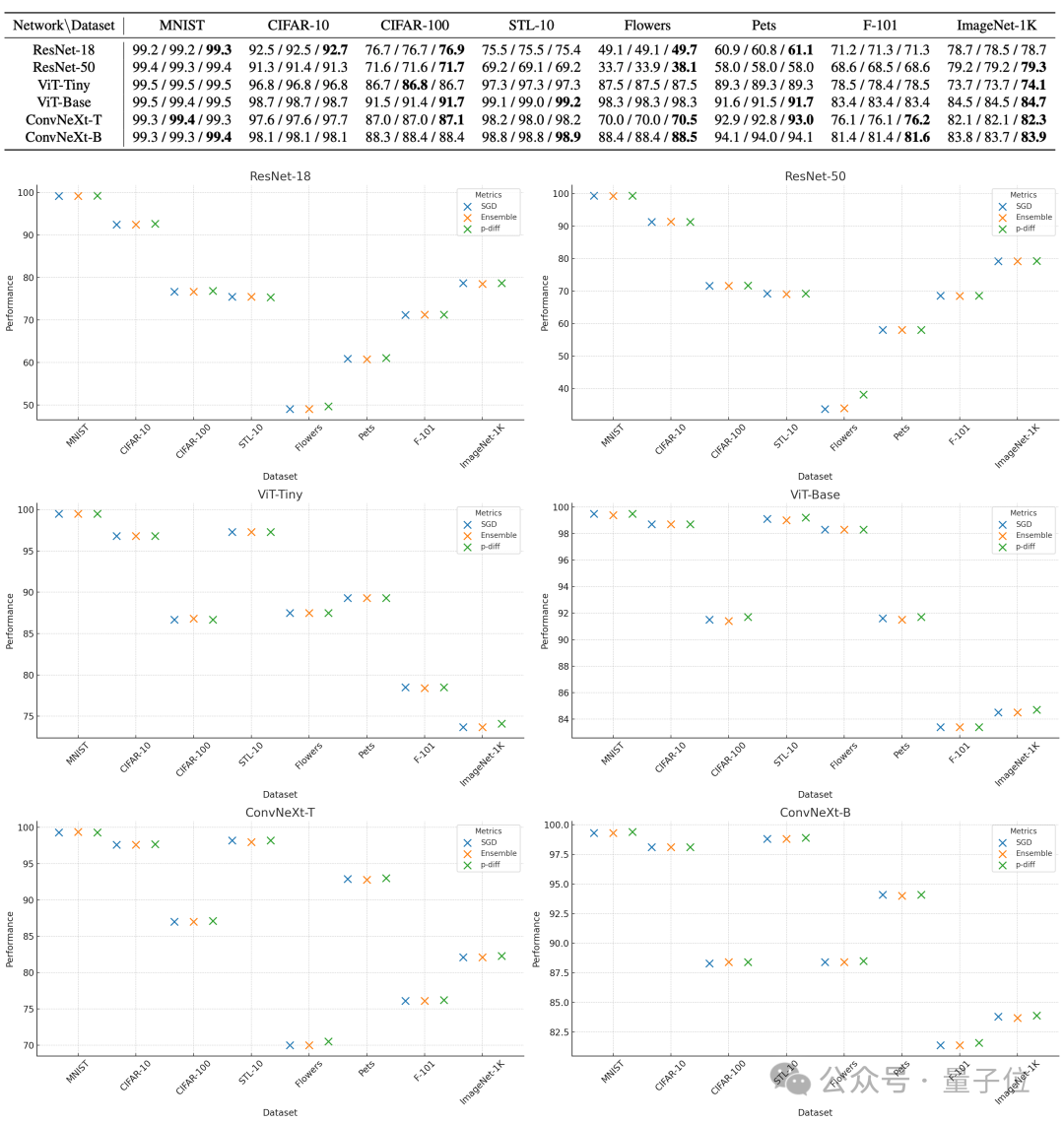
Dari segi kecekapan, tanpa kehilangan ketepatan, p-diff menjana rangkaian ResNet-18 15 kali lebih pantas daripada latihan tradisional, dan menjana Vit-Base 44 kali lebih pantas.
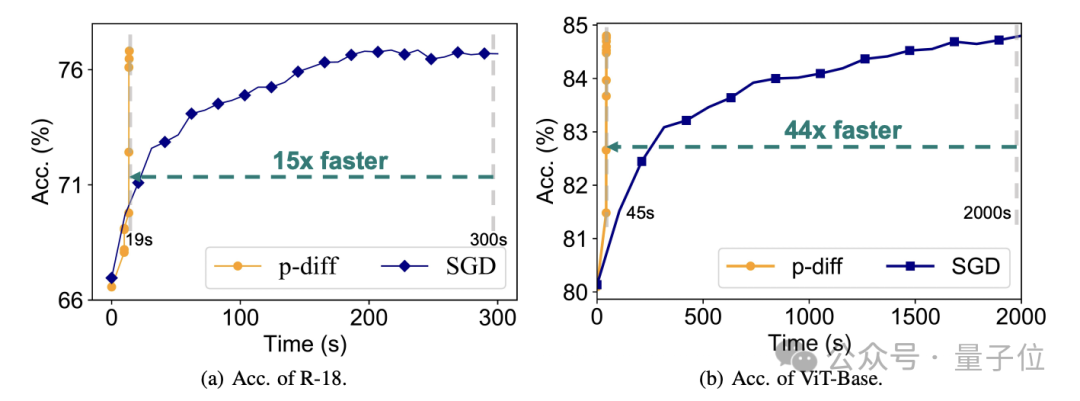
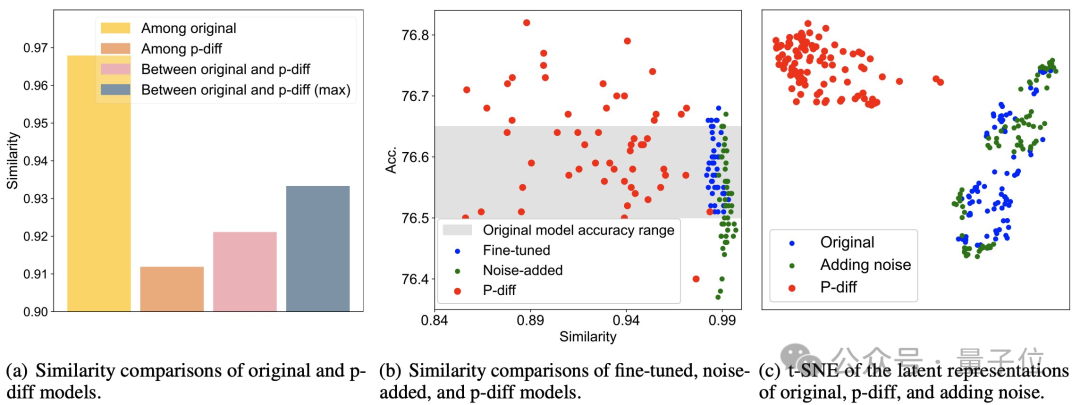
Keputusan ujian tambahan membuktikan bahawa model yang dihasilkan oleh p-diff adalah jauh berbeza daripada data latihan.
Seperti yang anda lihat dari rajah (a) di bawah, persamaan antara model yang dihasilkan oleh p-diff adalah lebih rendah daripada persamaan antara model asal, serta persamaan antara p-diff dan model asal.
Seperti yang dapat dilihat dari (b) dan (c), berbanding dengan kaedah penalaan halus dan penambahan hingar, persamaan p-diff juga lebih rendah.
Keputusan ini menunjukkan bahawa p-diff sebenarnya menjana model baharu dan bukannya hanya menghafal sampel latihan Ia juga menunjukkan bahawa ia mempunyai keupayaan generalisasi yang baik dan boleh menjana model baharu yang berbeza daripada data latihan.
Pada masa ini, kod p-diff adalah sumber terbuka Jika anda berminat, anda boleh menyemaknya di GitHub.
Alamat kertas: https://arxiv.org/abs/2402.13144
GitHub: https://github.com/NUS-HPC-AI-Lab/Neurally
Atas ialah kandungan terperinci Pecah ke lapisan bawah AI! Pasukan NUS Youyang menggunakan model resapan untuk membina parameter rangkaian saraf, LeCun menyukainya. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Bagaimana untuk mencapai kesan elemen input yang tinggi tetapi teks yang tinggi di bahagian bawah?
Apr 04, 2025 pm 10:27 PM
Bagaimana untuk mencapai kesan elemen input yang tinggi tetapi teks yang tinggi di bahagian bawah?
Apr 04, 2025 pm 10:27 PM
Bagaimana untuk mencapai ketinggian elemen input adalah sangat tinggi tetapi teks terletak di bahagian bawah. Dalam pembangunan front-end, anda sering menghadapi beberapa keperluan pelarasan gaya, seperti menetapkan ketinggian ...
 Bagaimana cara memaparkan 'badan bulat jingnan mai' yang dipasang dengan betul di laman web?
Apr 05, 2025 pm 10:33 PM
Bagaimana cara memaparkan 'badan bulat jingnan mai' yang dipasang dengan betul di laman web?
Apr 05, 2025 pm 10:33 PM
Menggunakan fail font yang dipasang di laman web baru -baru ini, saya memuat turun fon percuma dari internet dan berjaya memasangnya ke dalam sistem saya. Sekarang ...
 Bagaimana untuk memilih elemen kanak -kanak dengan item nama kelas pertama melalui CSS?
Apr 05, 2025 pm 11:24 PM
Bagaimana untuk memilih elemen kanak -kanak dengan item nama kelas pertama melalui CSS?
Apr 05, 2025 pm 11:24 PM
Apabila bilangan elemen tidak ditetapkan, bagaimana untuk memilih elemen anak pertama nama kelas yang ditentukan melalui CSS. Semasa memproses struktur HTML, anda sering menghadapi unsur yang berbeza ...
 Di mana untuk mendapatkan bahan untuk pengeluaran halaman H5
Apr 05, 2025 pm 11:33 PM
Di mana untuk mendapatkan bahan untuk pengeluaran halaman H5
Apr 05, 2025 pm 11:33 PM
Sumber utama bahan halaman H5 adalah: 1. Laman web bahan profesional (berbayar, berkualiti tinggi, hak cipta yang jelas); 2. Bahan buatan sendiri (keunikan yang tinggi, tetapi memakan masa); 3. Perpustakaan Bahan Sumber Terbuka (percuma, perlu ditapis dengan teliti); 4. Laman web gambar/video (disahkan hak cipta diperlukan). Di samping itu, gaya bahan bersatu, penyesuaian saiz, pemprosesan mampatan, dan perlindungan hak cipta adalah perkara utama yang perlu diberi perhatian.
 Bagaimana menggunakan CSS dan Flexbox untuk melaksanakan susun atur imej dan teks yang responsif pada saiz skrin yang berbeza?
Apr 05, 2025 pm 06:06 PM
Bagaimana menggunakan CSS dan Flexbox untuk melaksanakan susun atur imej dan teks yang responsif pada saiz skrin yang berbeza?
Apr 05, 2025 pm 06:06 PM
Melaksanakan susun atur responsif menggunakan CSS apabila kami ingin melaksanakan perubahan susun atur di bawah saiz skrin yang berbeza dalam reka bentuk web, CSS ...
 Adakah pengeluaran halaman H5 memerlukan penyelenggaraan berterusan?
Apr 05, 2025 pm 11:27 PM
Adakah pengeluaran halaman H5 memerlukan penyelenggaraan berterusan?
Apr 05, 2025 pm 11:27 PM
Halaman H5 perlu dikekalkan secara berterusan, kerana faktor -faktor seperti kelemahan kod, keserasian pelayar, pengoptimuman prestasi, kemas kini keselamatan dan peningkatan pengalaman pengguna. Kaedah penyelenggaraan yang berkesan termasuk mewujudkan sistem ujian lengkap, menggunakan alat kawalan versi, kerap memantau prestasi halaman, mengumpul maklum balas pengguna dan merumuskan pelan penyelenggaraan.
 Menetapkan Flex: 1 1 0 Apakah perbezaan antara menetapkan flex-basis dan tidak menetapkan flex-basis?
Apr 05, 2025 am 09:39 AM
Menetapkan Flex: 1 1 0 Apakah perbezaan antara menetapkan flex-basis dan tidak menetapkan flex-basis?
Apr 05, 2025 am 09:39 AM
Perbezaan antara flex: 110 dalam susun atur flex dan flex-basis tidak ditetapkan dalam susun atur flex, bagaimana untuk menetapkan flex ...
 Bagaimana untuk menghapuskan ekspresi bersyarat tertentu dalam tag skrip dalam rentetan HTML?
Apr 05, 2025 pm 12:45 PM
Bagaimana untuk menghapuskan ekspresi bersyarat tertentu dalam tag skrip dalam rentetan HTML?
Apr 05, 2025 pm 12:45 PM
Mengubahsuai kandungan rentetan HTML dengan cekap Artikel ini akan meneroka cara mengubah suai rentetan HTML, dengan matlamat mengeluarkan ...
