

Kertas 6 halaman Microsoft meletup: ternary LLM, sangat lazat!

Ini adalah kesimpulan yang dikemukakan oleh Microsoft dan Akademi Sains Universiti China dalam kajian terkini -
Semua LLM akan menjadi 1.58 bit.

Secara khusus, kaedah yang dicadangkan dalam kajian ini dipanggil BitNet b1.58, yang boleh dikatakan bermula daripada parameter "root" model bahasa besar.
Storan tradisional dalam bentuk nombor titik terapung 16-bit (seperti FP16 atau BF16) telah ditukar kepada ternary , iaitu {-1, 0, 1}.
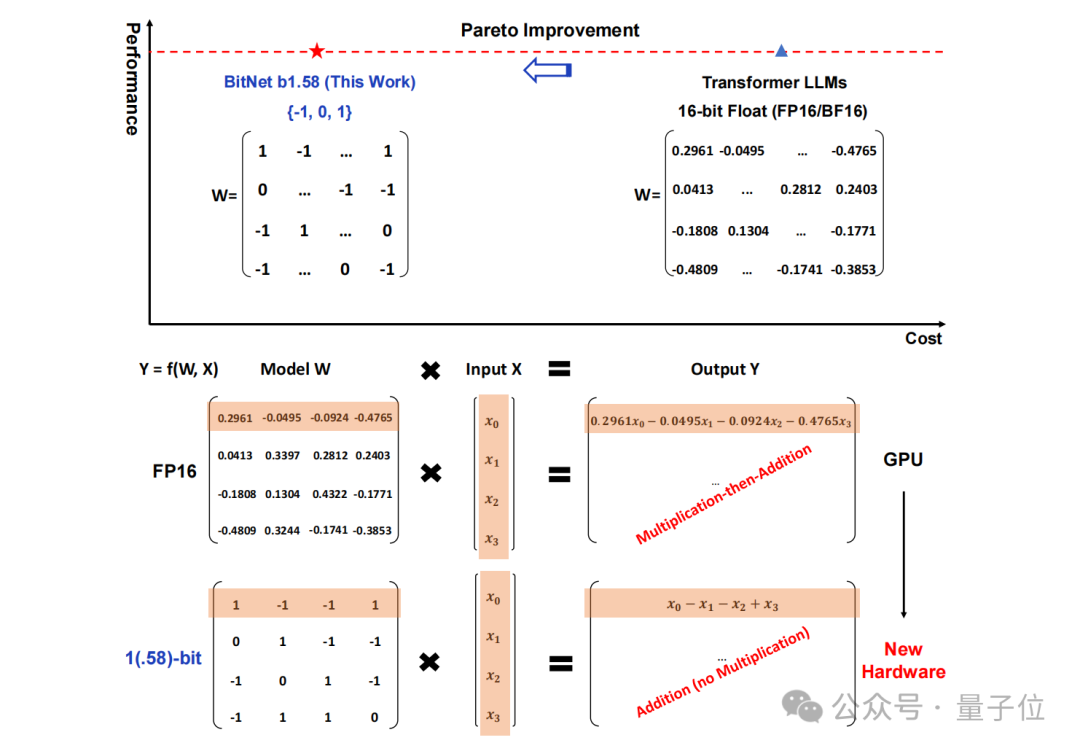
Perlu diingat bahawa "1.58 bit" tidak bermakna setiap parameter menduduki 1.58 bait ruang storan, tetapi setiap parameter boleh dikodkan dengan 1.58 bit maklumat.
Selepas penukaran sedemikian, pengiraan dalam matriks hanya akan melibatkan penambahan integer, sekali gus membolehkan model besar mengurangkan ruang storan dan sumber pengkomputeran yang diperlukan dengan ketara sambil mengekalkan ketepatan tertentu.
Sebagai contoh, BitNet b1.58 dibandingkan dengan Llama apabila saiz model ialah 3B Walaupun kelajuan meningkat sebanyak 2.71 kali, penggunaan memori GPU hampir hanya satu perempat daripada asal. Dan apabila saiz model lebih besar(contohnya, 70B) , peningkatan kelajuan dan penjimatan memori akan menjadi lebih ketara!
Idea subversif ini benar-benar menarik perhatian netizen, dan kertas itu juga mendapat perhatian tinggi tentang Jenaka lama kertas itu:1 bit sahaja yang ANDA perlukan.
Tukar semua parameter kepada ternaryJadi bagaimanakah BitNet b1.58 dilaksanakan? Jom teruskan membaca.
 Penyelidikan ini sebenarnya adalah pengoptimuman yang dilakukan oleh pasukan asal berdasarkan kertas yang diterbitkan sebelum ini, iaitu, nilai tambahan 0 ditambahkan pada BitNet asal.
Penyelidikan ini sebenarnya adalah pengoptimuman yang dilakukan oleh pasukan asal berdasarkan kertas yang diterbitkan sebelum ini, iaitu, nilai tambahan 0 ditambahkan pada BitNet asal.
(Transformer)
, menggantikan nn.Linear dengan BitLinear. Bagi pengoptimuman terperinci, perkara pertama ialah "menambah 0" yang baru kami sebutkan, iaitu,
Bagi pengoptimuman terperinci, perkara pertama ialah "menambah 0" yang baru kami sebutkan, iaitu,
(pengkuantiti berat).
Berat model BitNet b1.58 dikuantasikan ke dalam nilai terner {-1, 0, 1}, yang bersamaan dengan menggunakan 1.58 bit untuk mewakili setiap berat dalam sistem binari. Kaedah kuantifikasi ini mengurangkan jejak ingatan model dan memudahkan proses pengiraan.
Kedua, dari segireka bentuk fungsi kuantisasi
, untuk mengehadkan berat kepada -1, 0 atau +1, penyelidik menggunakan fungsi kuantisasi yang dipanggil absmean.
Fungsi ini mula-mula menskalakan mengikut purata nilai mutlak matriks berat, dan kemudian membundarkan setiap nilai kepada integer terdekat (-1, 0, +1).
Langkah seterusnya ialahkuantisasi pengaktifan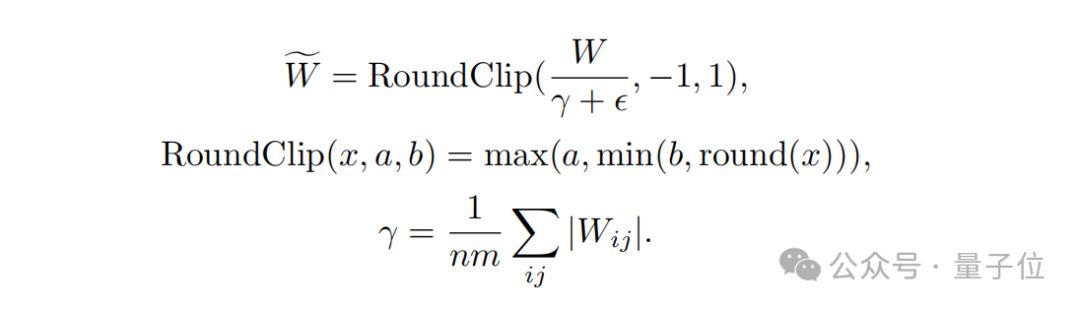
.
Kuantisasi nilai pengaktifan adalah sama seperti pelaksanaan dalam BitNet, tetapi nilai pengaktifan tidak diskalakan kepada julat [0, Qb] sebelum fungsi tak linear. Sebaliknya, pengaktifan diskalakan kepada julat [−Qb, Qb] untuk menghapuskan pengkuantitian titik sifar. Perlu dinyatakan bahawa untuk menjadikan BitNet b1.58 serasi dengan komuniti sumber terbuka, pasukan penyelidik menggunakan komponen model LLaMA, seperti RMSNorm, SwiGLU, dll., supaya ia boleh disepadukan dengan mudah ke dalam arus perdana terbuka. perisian sumber. Akhir sekali, dari segi perbandingan prestasi percubaan, pasukan membandingkan BitNet b1.58 dan FP16 LLaMA LLM pada model yang berbeza saiz. Hasilnya menunjukkan bahawa BitNet b1.58 mula memadankan LLaMA berketepatan penuh LLM dalam kebingungan pada saiz model 3B, sambil mencapai peningkatan ketara dalam kependaman, penggunaan memori dan daya pemprosesan. Dan apabila saiz model menjadi lebih besar, peningkatan prestasi ini akan menjadi lebih ketara. Seperti yang dinyatakan di atas, kaedah unik kajian ini telah menyebabkan banyak perbincangan hangat di Internet. Pengarang DeepLearning.scala Yang Bo berkata: Berbanding dengan BitNet asal, ciri terbesar BitNet b1.58 ialah ia membenarkan 0 parameter. Saya berpendapat bahawa dengan mengubah sedikit fungsi pengkuantitian, kita mungkin dapat mengawal perkadaran parameter 0. Apabila perkadaran 0 parameter adalah besar, pemberat boleh disimpan dalam format yang jarang, supaya purata memori video yang diduduki oleh setiap parameter adalah kurang daripada 1 bit. Ini bersamaan dengan MoE peringkat berat. Saya rasa ia lebih elegan daripada KPM biasa. Pada masa yang sama, dia juga membangkitkan kekurangan BitNet: Kelemahan terbesar BitNet ialah walaupun ia boleh mengurangkan overhed memori semasa inferens, keadaan pengoptimum dan kecerunan masih menggunakan nombor titik terapung, dan latihan masih sangat memakan ingatan. Saya fikir jika BitNet boleh digabungkan dengan teknologi yang menjimatkan memori video semasa latihan, maka berbanding dengan rangkaian separuh ketepatan tradisional, ia boleh menyokong lebih banyak parameter dengan kuasa pengkomputeran dan memori video yang sama, yang akan mempunyai kelebihan yang besar. Cara semasa untuk menyimpan overhed memori grafik bagi keadaan pengoptimum sedang memunggah. Satu cara untuk menyimpan penggunaan memori kecerunan mungkin ReLoRA. Walau bagaimanapun, percubaan kertas ReLoRA hanya menggunakan model dengan satu bilion parameter, dan tidak ada bukti bahawa ia boleh digeneralisasikan kepada model dengan puluhan atau ratusan bilion parameter. . 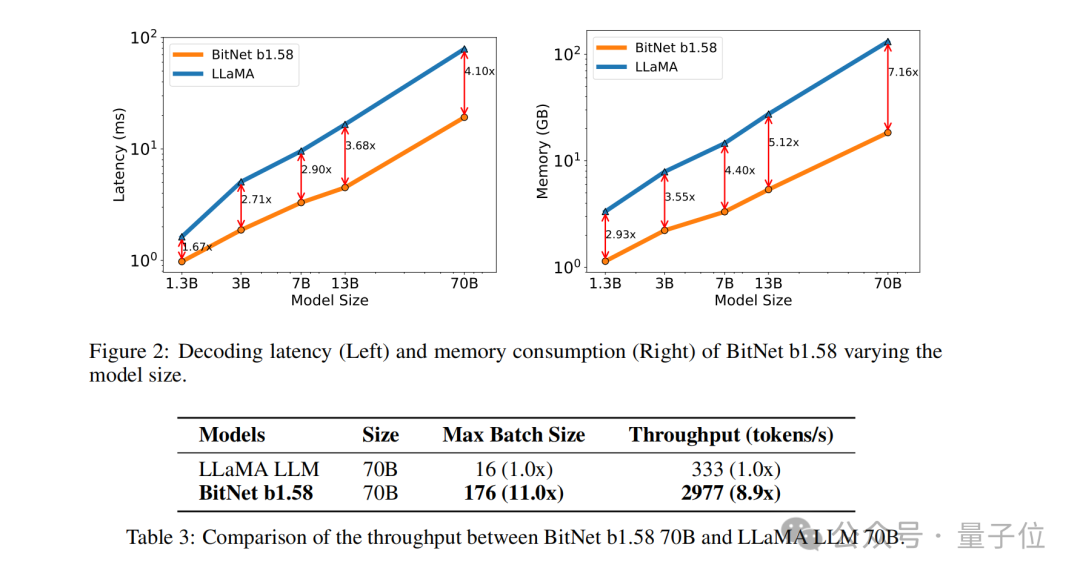
Netizen: Ada kemungkinan untuk menjalankan model besar 120B pada GPU gred pengguna
Jadi apa pendapat anda tentang kaedah baharu ini? 
Atas ialah kandungan terperinci Kertas 6 halaman Microsoft meletup: ternary LLM, sangat lazat!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1374
1374
 52
52

 Cara menyelesaikan MySQL tidak dapat dimulakan
Apr 08, 2025 pm 02:21 PM
Cara menyelesaikan MySQL tidak dapat dimulakan
Apr 08, 2025 pm 02:21 PM
Terdapat banyak sebab mengapa permulaan MySQL gagal, dan ia boleh didiagnosis dengan memeriksa log ralat. Penyebab umum termasuk konflik pelabuhan (periksa penghunian pelabuhan dan ubah suai konfigurasi), isu kebenaran (periksa keizinan pengguna yang menjalankan perkhidmatan), ralat fail konfigurasi (periksa tetapan parameter), rasuah direktori data (memulihkan data atau membina semula ruang meja), isu ruang jadual InnoDB (semak fail ibdata1) Apabila menyelesaikan masalah, anda harus menganalisisnya berdasarkan log ralat, cari punca utama masalah, dan mengembangkan tabiat sandaran data secara teratur untuk mencegah dan menyelesaikan masalah.
 Cara Menggunakan MySQL Selepas Pemasangan
Apr 08, 2025 am 11:48 AM
Cara Menggunakan MySQL Selepas Pemasangan
Apr 08, 2025 am 11:48 AM
Artikel ini memperkenalkan operasi pangkalan data MySQL. Pertama, anda perlu memasang klien MySQL, seperti MySqlworkbench atau Command Line Client. 1. Gunakan perintah MySQL-Uroot-P untuk menyambung ke pelayan dan log masuk dengan kata laluan akaun root; 2. Gunakan CreateTatabase untuk membuat pangkalan data, dan gunakan Pilih pangkalan data; 3. Gunakan createtable untuk membuat jadual, menentukan medan dan jenis data; 4. Gunakan InsertInto untuk memasukkan data, data pertanyaan, kemas kini data dengan kemas kini, dan padam data dengan padam. Hanya dengan menguasai langkah -langkah ini, belajar menangani masalah biasa dan mengoptimumkan prestasi pangkalan data anda boleh menggunakan MySQL dengan cekap.
 Geospatial Laravel: Pengoptimuman peta interaktif dan sejumlah besar data
Apr 08, 2025 pm 12:24 PM
Geospatial Laravel: Pengoptimuman peta interaktif dan sejumlah besar data
Apr 08, 2025 pm 12:24 PM
Cecair memproses 7 juta rekod dan membuat peta interaktif dengan teknologi geospatial. Artikel ini meneroka cara memproses lebih dari 7 juta rekod menggunakan Laravel dan MySQL dan mengubahnya menjadi visualisasi peta interaktif. Keperluan Projek Cabaran Awal: Ekstrak Wawasan berharga menggunakan 7 juta rekod dalam pangkalan data MySQL. Ramai orang mula -mula mempertimbangkan bahasa pengaturcaraan, tetapi mengabaikan pangkalan data itu sendiri: Bolehkah ia memenuhi keperluan? Adakah penghijrahan data atau pelarasan struktur diperlukan? Bolehkah MySQL menahan beban data yang besar? Analisis awal: Penapis utama dan sifat perlu dikenalpasti. Selepas analisis, didapati bahawa hanya beberapa atribut yang berkaitan dengan penyelesaiannya. Kami mengesahkan kemungkinan penapis dan menetapkan beberapa sekatan untuk mengoptimumkan carian. Carian Peta Berdasarkan Bandar
 Cara menetapkan masa tamat vue axios
Apr 07, 2025 pm 10:03 PM
Cara menetapkan masa tamat vue axios
Apr 07, 2025 pm 10:03 PM
Untuk menetapkan masa untuk Vue Axios, kita boleh membuat contoh Axios dan menentukan pilihan masa tamat: dalam tetapan global: vue.prototype. $ Axios = axios.create ({timeout: 5000}); Dalam satu permintaan: ini. $ axios.get ('/api/pengguna', {timeout: 10000}).
 Jurutera Backend Senior Remote (Platform) memerlukan kalangan
Apr 08, 2025 pm 12:27 PM
Jurutera Backend Senior Remote (Platform) memerlukan kalangan
Apr 08, 2025 pm 12:27 PM
Jurutera Backend Senior Remote Company Kekosongan Syarikat: Lokasi Lokasi: Jauh Pejabat Jauh Jenis: Gaji sepenuh masa: $ 130,000- $ 140,000 Penerangan Pekerjaan Mengambil bahagian dalam penyelidikan dan pembangunan aplikasi mudah alih Circle dan ciri-ciri berkaitan API awam yang meliputi keseluruhan kitaran hayat pembangunan perisian. Tanggungjawab utama kerja pembangunan secara bebas berdasarkan rubyonrails dan bekerjasama dengan pasukan react/redux/relay front-end. Membina fungsi teras dan penambahbaikan untuk aplikasi web dan bekerjasama rapat dengan pereka dan kepimpinan sepanjang proses reka bentuk berfungsi. Menggalakkan proses pembangunan positif dan mengutamakan kelajuan lelaran. Memerlukan lebih daripada 6 tahun backend aplikasi web kompleks
 Cara mengoptimumkan prestasi pangkalan data selepas pemasangan MySQL
Apr 08, 2025 am 11:36 AM
Cara mengoptimumkan prestasi pangkalan data selepas pemasangan MySQL
Apr 08, 2025 am 11:36 AM
Pengoptimuman prestasi MySQL perlu bermula dari tiga aspek: konfigurasi pemasangan, pengindeksan dan pengoptimuman pertanyaan, pemantauan dan penalaan. 1. Selepas pemasangan, anda perlu menyesuaikan fail my.cnf mengikut konfigurasi pelayan, seperti parameter innodb_buffer_pool_size, dan tutup query_cache_size; 2. Buat indeks yang sesuai untuk mengelakkan indeks yang berlebihan, dan mengoptimumkan pernyataan pertanyaan, seperti menggunakan perintah menjelaskan untuk menganalisis pelan pelaksanaan; 3. Gunakan alat pemantauan MySQL sendiri (ShowProcessList, ShowStatus) untuk memantau kesihatan pangkalan data, dan kerap membuat semula dan mengatur pangkalan data. Hanya dengan terus mengoptimumkan langkah -langkah ini, prestasi pangkalan data MySQL diperbaiki.
 Penyelesaian kepada perkhidmatan yang tidak dapat dimulakan selepas pemasangan MySQL
Apr 08, 2025 am 11:18 AM
Penyelesaian kepada perkhidmatan yang tidak dapat dimulakan selepas pemasangan MySQL
Apr 08, 2025 am 11:18 AM
MySQL enggan memulakan? Jangan panik, mari kita periksa! Ramai kawan mendapati bahawa perkhidmatan itu tidak dapat dimulakan selepas memasang MySQL, dan mereka sangat cemas! Jangan risau, artikel ini akan membawa anda untuk menangani dengan tenang dan mengetahui dalang di belakangnya! Selepas membacanya, anda bukan sahaja dapat menyelesaikan masalah ini, tetapi juga meningkatkan pemahaman anda tentang perkhidmatan MySQL dan idea anda untuk masalah penyelesaian masalah, dan menjadi pentadbir pangkalan data yang lebih kuat! Perkhidmatan MySQL gagal bermula, dan terdapat banyak sebab, mulai dari kesilapan konfigurasi mudah kepada masalah sistem yang kompleks. Mari kita mulakan dengan aspek yang paling biasa. Pengetahuan asas: Penerangan ringkas mengenai proses permulaan perkhidmatan MySQL Startup. Ringkasnya, sistem operasi memuatkan fail yang berkaitan dengan MySQL dan kemudian memulakan daemon MySQL. Ini melibatkan konfigurasi
 Bagaimana untuk mengoptimumkan prestasi MySQL untuk aplikasi beban tinggi?
Apr 08, 2025 pm 06:03 PM
Bagaimana untuk mengoptimumkan prestasi MySQL untuk aplikasi beban tinggi?
Apr 08, 2025 pm 06:03 PM
Panduan Pengoptimuman Prestasi Pangkalan Data MySQL Dalam aplikasi yang berintensifkan sumber, pangkalan data MySQL memainkan peranan penting dan bertanggungjawab untuk menguruskan urus niaga besar-besaran. Walau bagaimanapun, apabila skala aplikasi berkembang, kemunculan prestasi pangkalan data sering menjadi kekangan. Artikel ini akan meneroka satu siri strategi pengoptimuman prestasi MySQL yang berkesan untuk memastikan aplikasi anda tetap cekap dan responsif di bawah beban tinggi. Kami akan menggabungkan kes-kes sebenar untuk menerangkan teknologi utama yang mendalam seperti pengindeksan, pengoptimuman pertanyaan, reka bentuk pangkalan data dan caching. 1. Reka bentuk seni bina pangkalan data dan seni bina pangkalan data yang dioptimumkan adalah asas pengoptimuman prestasi MySQL. Berikut adalah beberapa prinsip teras: Memilih jenis data yang betul dan memilih jenis data terkecil yang memenuhi keperluan bukan sahaja dapat menjimatkan ruang penyimpanan, tetapi juga meningkatkan kelajuan pemprosesan data.
