
 Peranti teknologi
AI
Kerja baharu oleh pasukan Chen Danqi: Konteks Llama-2 dikembangkan kepada 128k, 10 kali pemprosesan hanya memerlukan 1/6 daripada memori
Peranti teknologi
AI
Kerja baharu oleh pasukan Chen Danqi: Konteks Llama-2 dikembangkan kepada 128k, 10 kali pemprosesan hanya memerlukan 1/6 daripada memori
Kerja baharu oleh pasukan Chen Danqi: Konteks Llama-2 dikembangkan kepada 128k, 10 kali pemprosesan hanya memerlukan 1/6 daripada memori

Pasukan Chen Danqi baru sahaja mengeluarkan kaedah pengembangan tetingkap konteks LLM baharu:
Ia boleh memanjangkan tetingkap Llama-2 kepada 128k menggunakan hanya 8k dokumen token untuk latihan. Perkara yang paling penting ialah dalam proses ini, model hanya memerlukan1/6 daripada memori asal, dan model mencapai 10 kali pemprosesan.
mengurangkan kos latihan:
Menggunakan kaedah ini untuk mengubah alpaca 7B 2 hanya memerlukansekeping A100.
Pasukan berkata:Kami berharap kaedah ini berguna dan mudah digunakan, serta menyediakan keupayaan konteks yangPada masa ini, model dan kod diterbitkan di HuggingFace dan GitHub.murah dan berkesan untuk LLM akan datang.
CEPE, nama penuhnya ialah "Pengembangan Konteks dengan Pengekodan Selari(Pengembangan Konteks dengan Pengekodan Selari)". Sebagai rangka kerja yang ringan, ia boleh digunakan untuk memanjangkan tetingkap konteks mana-mana model
dilatih dan arahan yang diperhalusi. Untuk mana-mana model bahasa penyahkod sahaja yang telah dilatih, CEPE memanjangkannya dengan menambahkan dua komponen kecil:
Satu ialah pengekod keciluntuk pengekodan blok konteks panjang
Satu adalah modul Daya perhatian silangke dalam setiap lapisan penyahkod, digunakan untuk memfokuskan pada perwakilan pengekod. Seni bina lengkap adalah seperti berikut:
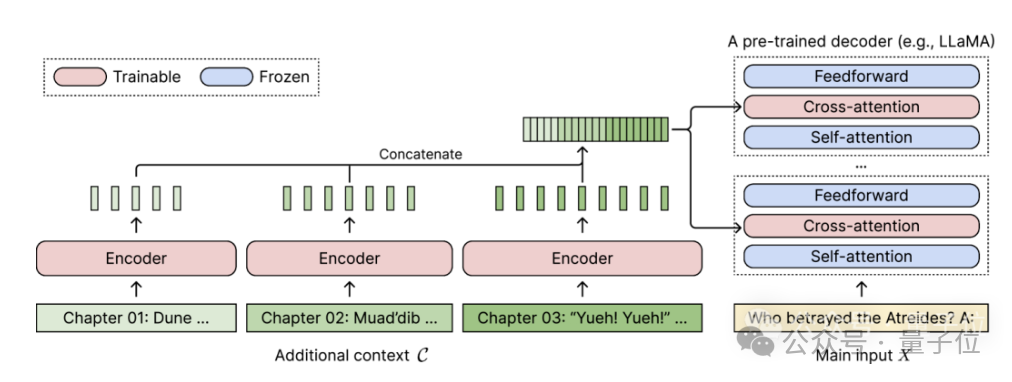 Dalam rajah ini, model pengekod mengekod 3 blok tambahan konteks secara selari dan digabungkan dengan perwakilan tersembunyi terakhir, yang kemudiannya digunakan sebagai input kepada perhatian silang penyahkod lapisan.
Dalam rajah ini, model pengekod mengekod 3 blok tambahan konteks secara selari dan digabungkan dengan perwakilan tersembunyi terakhir, yang kemudiannya digunakan sebagai input kepada perhatian silang penyahkod lapisan.
Di sini, lapisan perhatian silang tertumpu terutamanya pada perwakilan pengekod antara lapisan perhatian diri dan lapisan suapan ke hadapan dalam model penyahkod.
Dengan berhati-hati memilih data latihan yang tidak memerlukan pelabelan, CEPE membantu model mempunyai keupayaan konteks yang panjang dan juga mahir dalam pengambilan dokumen.
Pengarang memperkenalkan bahawa CEPE tersebut terutamanya mengandungi tiga kelebihan utama:
(1) Panjangnya boleh digeneralisasikankerana ia tidak dikekang oleh pengekodan kedudukan Sebaliknya, konteksnya dibahagikan dan dikodkan, dan setiap satu segmen adalah Mempunyai pengekodan lokasi sendiri.
(2) Kecekapan tinggiMenggunakan pengekod kecil dan pengekodan selari untuk memproses konteks boleh mengurangkan kos pengiraan.
Pada masa yang sama, memandangkan perhatian silang hanya menumpukan pada perwakilan lapisan terakhir pengekod, dan model bahasa yang hanya menggunakan penyahkod perlu cache pasangan nilai kunci setiap token dalam setiap lapisan, jadi dalam perbandingan, CEPE memerlukan banyak pengurangan memori.
(3) Kurangkan kos latihan
Tidak seperti kaedah penalaan halus penuh, CEPE hanya melaraskan pengekod dan perhatian silang sambil mengekalkan model penyahkod besar beku.
Pengarang memperkenalkan bahawa dengan mengembangkan dekoder 7B menjadi model
dengan pengekod 400M dan lapisan perhatian silang (jumlah 1.4 bilion parameter), ia boleh dilengkapkan dengan GPU A100 80GB. Kerisauan terus berkurang
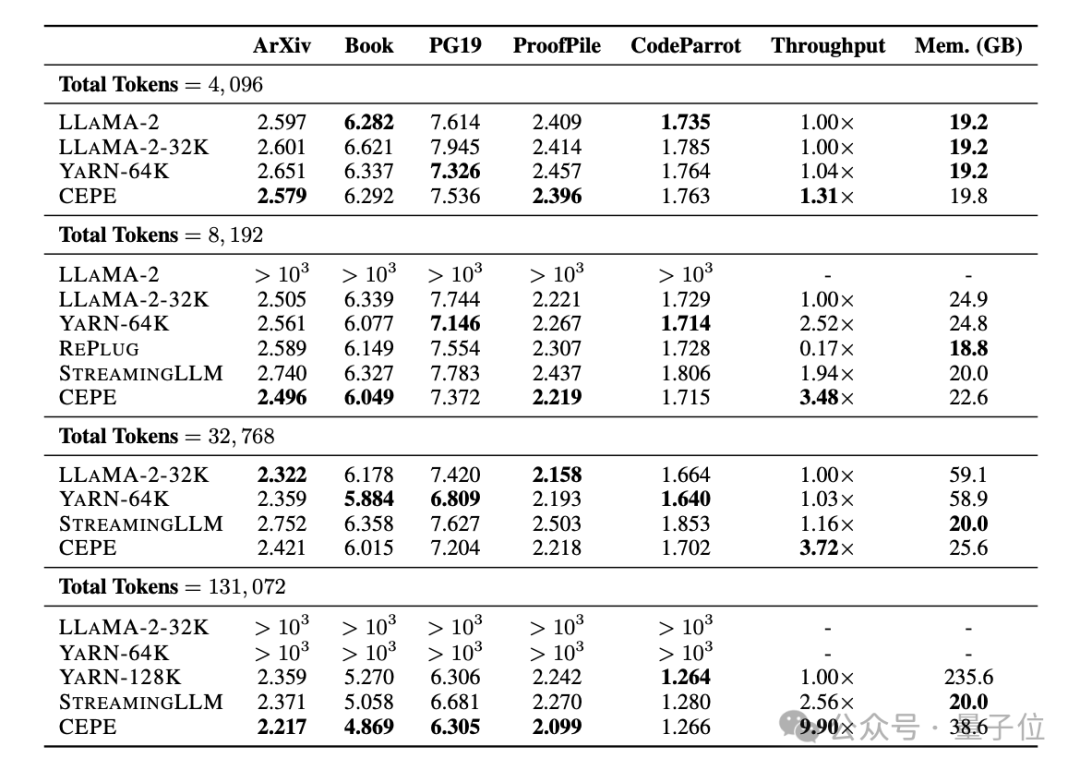
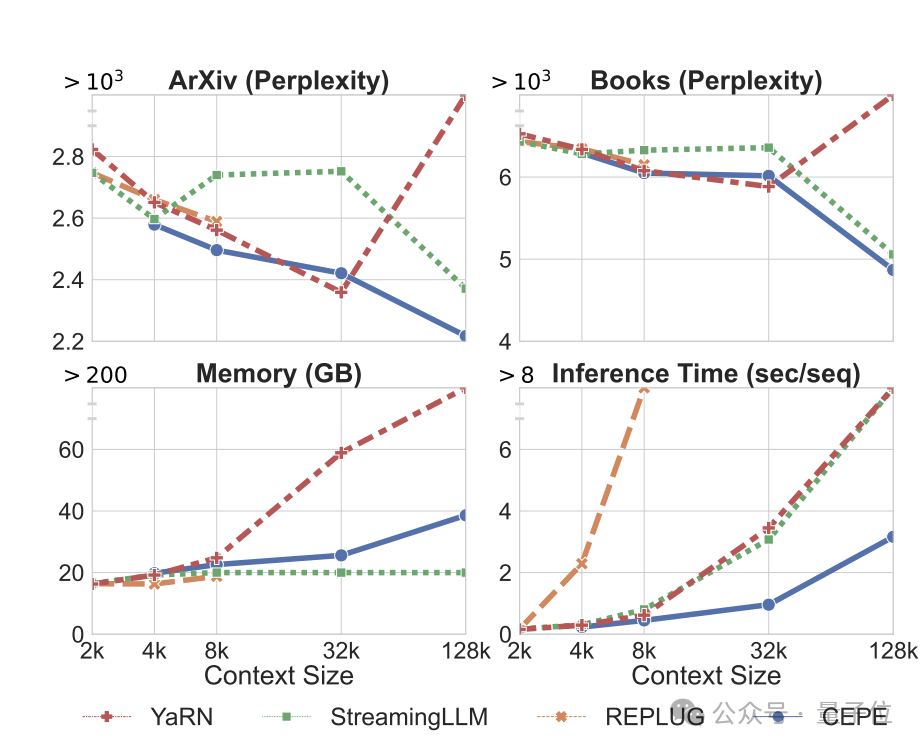
Pasukan menggunakan CEPE pada Llama-2 dan dilatih pada versi 20 bilion token yang ditapis RedPajama
(hanya 1% daripada bajet pra-latihan Llama-2). Pertama, berbanding dengan dua model yang diperhalusi sepenuhnya, LLAMA2-32K dan YARN-64K, CEPE mencapai
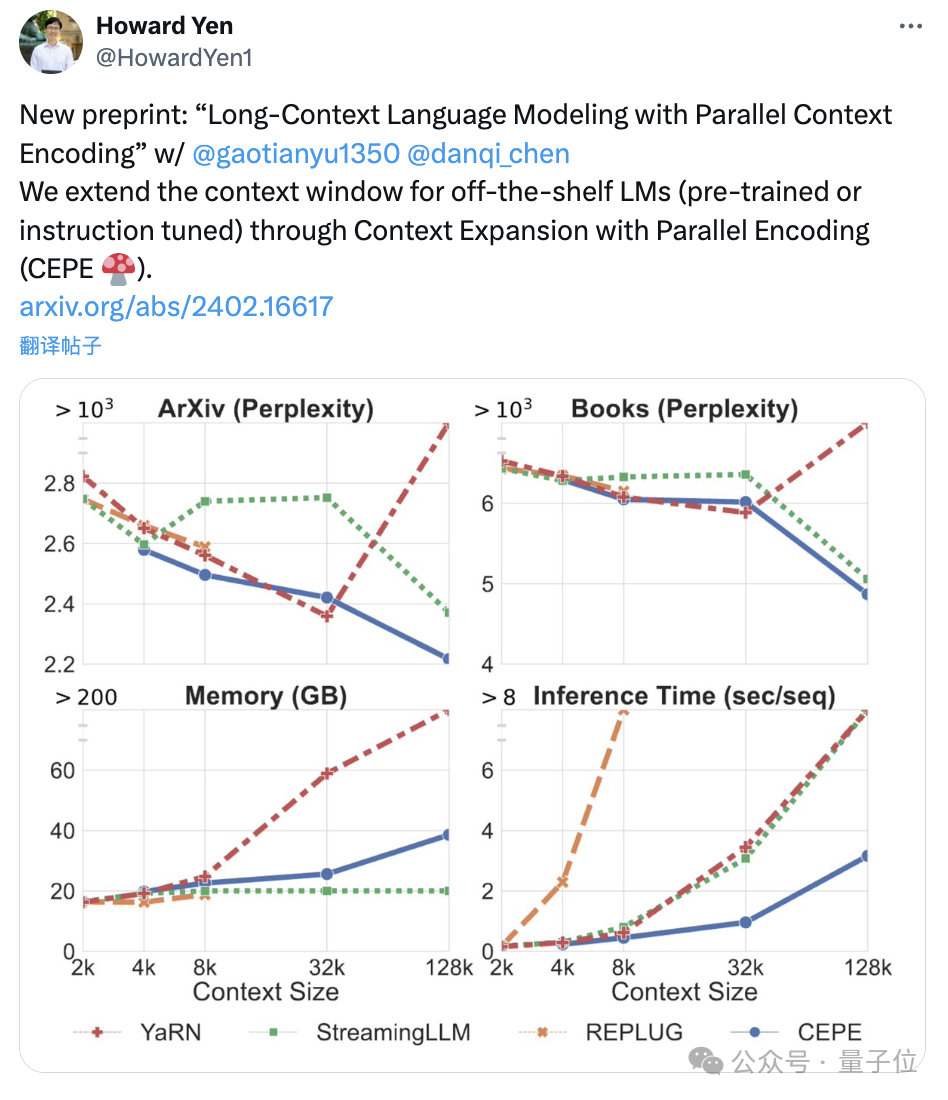
perplexity yang lebih rendah atau setanding pada semua set data sambil mempunyai kadar penggunaan memori yang lebih rendah dan daya pemprosesan yang lebih tinggi.
 Apabila konteks ditingkatkan kepada 128k
Apabila konteks ditingkatkan kepada 128k
, kebingungan CEPE terus berkurangan sambil mengekalkan keadaan ingatan yang rendah. Sebaliknya, Llama-2-32K dan YARN-64K bukan sahaja gagal membuat generalisasi melebihi tempoh latihan mereka, tetapi juga disertai dengan peningkatan ketara dalam kos ingatan.
 Kedua,
Kedua,
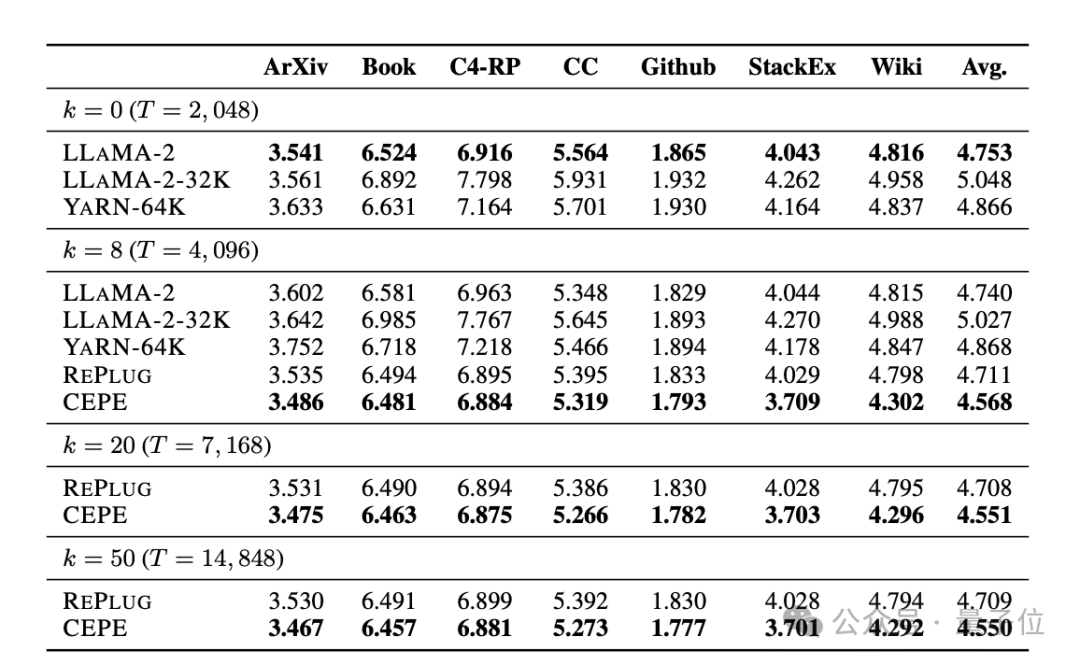
keupayaan mendapatkan semula dipertingkatkan. Seperti yang ditunjukkan dalam jadual berikut:
Dengan menggunakan konteks yang diperoleh semula, CEPE boleh meningkatkan kebingungan model dengan berkesan dan berprestasi lebih baik daripada RePlug.
Perlu diingat bahawa walaupun perenggan k=50 (latihan ialah 60), CEPE akan terus memperbaiki kebingungan.
Ini menunjukkan bahawa CEPE dipindahkan dengan baik ke tetapan peningkatan perolehan, manakala model penyahkod konteks penuh merosot dalam keupayaan ini.
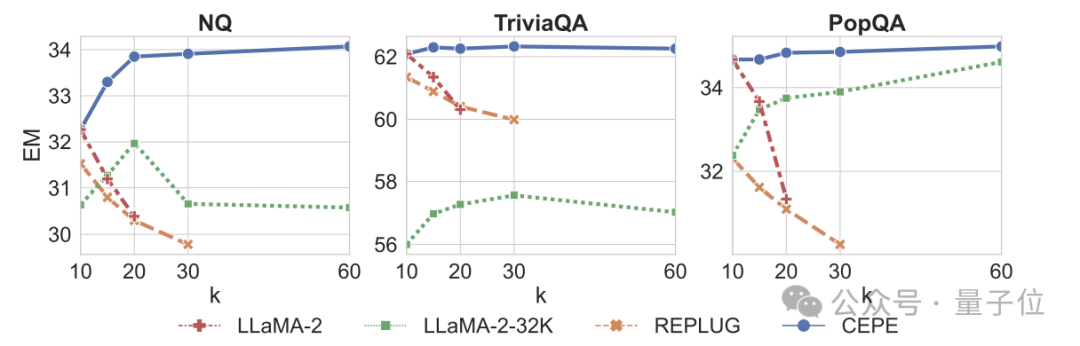
Ketiga, keupayaan soalan dan jawapan domain terbukamelebihi dengan ketara.
Seperti yang ditunjukkan dalam rajah di bawah, CEPE jauh lebih baik daripada model lain dalam semua set data dan parameter perenggan k, dan tidak seperti model lain, prestasi menurun dengan ketara apabila nilai k menjadi lebih besar dan lebih besar.
Ini juga menunjukkan CEPE tidak sensitif kepada sejumlah besar perenggan yang berlebihan atau tidak berkaitan.
Jadi untuk diringkaskan, CEPE mengatasi semua tugasan di atas dengan ingatan dan kos pengiraan yang jauh lebih rendah berbanding kebanyakan penyelesaian lain.
Akhir sekali, berdasarkan asas ini, penulis mencadangkan CEPE-Distilled (CEPED) khusus untuk model penalaan arahan.
Ia hanya menggunakan data yang tidak berlabel untuk mengembangkan tetingkap konteks model, menyaring gelagat model yang ditala arahan asal ke dalam seni bina baharu melalui kehilangan perbezaan KL yang dibantu, dengan itu menghapuskan keperluan untuk mengurus data penjejakan arahan konteks panjang yang mahal.
Akhirnya, CEPED boleh mengembangkan tetingkap konteks Llama-2 dan meningkatkan prestasi teks panjang model sambil mengekalkan keupayaan untuk memahami arahan.
Pengenalan pasukan
CEPE mempunyai 3 orang pengarang.
Satu ialah Yan Heguang(Howard Yen), pelajar sarjana dalam sains komputer di Princeton University.
Orang kedua ialah Gao Tianyu, pelajar kedoktoran di sekolah yang sama dan lulusan ijazah sarjana muda dari Universiti Tsinghua.
Mereka semua pelajar pengarang yang sepadan Chen Danqi.

Kertas asal: https://arxiv.org/abs/2402.16617
Pautan rujukan: https://twitter.com/HowardYen1/status/17624745161
Atas ialah kandungan terperinci Kerja baharu oleh pasukan Chen Danqi: Konteks Llama-2 dikembangkan kepada 128k, 10 kali pemprosesan hanya memerlukan 1/6 daripada memori. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1663
1663
 14
1419
52
1313
25
1264
29
1237
24
14
1419
52
1313
25
1264
29
1237
24

 Platform perdagangan mata wang teratas yang manakah di dunia adalah antara sepuluh platform perdagangan mata wang teratas pada tahun 2025
Apr 28, 2025 pm 08:12 PM
Platform perdagangan mata wang teratas yang manakah di dunia adalah antara sepuluh platform perdagangan mata wang teratas pada tahun 2025
Apr 28, 2025 pm 08:12 PM
Sepuluh pertukaran cryptocurrency teratas di dunia pada tahun 2025 termasuk Binance, OKX, Gate.io, Coinbase, Kraken, Huobi, Bitfinex, Kucoin, Bittrex dan Poloniex, yang semuanya dikenali dengan jumlah dan keselamatan perdagangan mereka yang tinggi.
 Berapa bernilai bitcoin
Apr 28, 2025 pm 07:42 PM
Berapa bernilai bitcoin
Apr 28, 2025 pm 07:42 PM
Harga Bitcoin berkisar antara $ 20,000 hingga $ 30,000. 1. Harga Bitcoin telah berubah secara dramatik sejak tahun 2009, mencapai hampir $ 20,000 pada tahun 2017 dan hampir $ 60,000 pada tahun 2021. Harga dipengaruhi oleh faktor -faktor seperti permintaan pasaran, bekalan, dan persekitaran makroekonomi. 3. Dapatkan harga masa nyata melalui pertukaran, aplikasi mudah alih dan laman web. 4. Harga Bitcoin sangat tidak menentu, didorong oleh sentimen pasaran dan faktor luaran. 5. Ia mempunyai hubungan tertentu dengan pasaran kewangan tradisional dan dipengaruhi oleh pasaran saham global, kekuatan dolar AS, dan sebagainya. 6. Trend jangka panjang adalah yakin, tetapi risiko perlu dinilai dengan berhati-hati.
 Platform perdagangan mata wang teratas yang manakah di dunia adalah versi terbaru dari Platform Perdagangan Top Top Top
Apr 28, 2025 pm 08:09 PM
Platform perdagangan mata wang teratas yang manakah di dunia adalah versi terbaru dari Platform Perdagangan Top Top Top
Apr 28, 2025 pm 08:09 PM
Sepuluh platform perdagangan cryptocurrency teratas di dunia termasuk Binance, OKX, Gate.io, Coinbase, Kraken, Huobi Global, Bitfinex, Bittrex, Kucoin dan Poloniex, yang semuanya menyediakan pelbagai kaedah perdagangan dan langkah -langkah keselamatan yang kuat.
 Decryption Gate.IO Strategy Upgrade: Bagaimana untuk mentakrifkan semula Pengurusan Aset Crypto di Memebox 2.0?
Apr 28, 2025 pm 03:33 PM
Decryption Gate.IO Strategy Upgrade: Bagaimana untuk mentakrifkan semula Pengurusan Aset Crypto di Memebox 2.0?
Apr 28, 2025 pm 03:33 PM
Memebox 2.0 mentakrifkan semula pengurusan aset crypto melalui seni bina yang inovatif dan kejayaan prestasi. 1) Ia menyelesaikan tiga titik kesakitan utama: silo aset, kerosakan pendapatan dan paradoks keselamatan dan kemudahan. 2) Melalui hab aset pintar, pengurusan risiko dinamik dan enjin peningkatan pulangan, kelajuan pemindahan rantaian, kadar hasil purata dan kelajuan tindak balas insiden keselamatan diperbaiki. 3) Menyediakan pengguna dengan visualisasi aset, automasi dasar dan integrasi tadbir urus, merealisasikan pembinaan semula nilai pengguna. 4) Melalui kerjasama ekologi dan inovasi pematuhan, keberkesanan keseluruhan platform telah dipertingkatkan. 5) Pada masa akan datang, kolam insurans kontrak pintar, ramalan integrasi pasaran dan peruntukan aset yang didorong AI akan dilancarkan untuk terus memimpin pembangunan industri.
 Apakah platform perdagangan mata wang teratas? 10 pertukaran mata wang maya terkini
Apr 28, 2025 pm 08:06 PM
Apakah platform perdagangan mata wang teratas? 10 pertukaran mata wang maya terkini
Apr 28, 2025 pm 08:06 PM
Saat ini disenaraikan di antara sepuluh mata wang mata wang maya yang teratas: 1. Binance, 2 Okx, 3. Gate.io, 4. Perpustakaan duit syiling, 5. Siren, 6. Huobi Global Station, 7. Bybit, 8. Kucoin, 9.
 Apakah sepuluh aplikasi perdagangan mata wang maya teratas? Kedudukan pertukaran mata wang digital terkini
Apr 28, 2025 pm 08:03 PM
Apakah sepuluh aplikasi perdagangan mata wang maya teratas? Kedudukan pertukaran mata wang digital terkini
Apr 28, 2025 pm 08:03 PM
Sepuluh pertukaran mata wang digital teratas seperti Binance, OKX, Gate.io telah meningkatkan sistem mereka, urus niaga yang pelbagai dan langkah -langkah keselamatan yang ketat.
 Bagaimana cara menggunakan Perpustakaan Chrono di C?
Apr 28, 2025 pm 10:18 PM
Bagaimana cara menggunakan Perpustakaan Chrono di C?
Apr 28, 2025 pm 10:18 PM
Menggunakan perpustakaan Chrono di C membolehkan anda mengawal selang masa dan masa dengan lebih tepat. Mari kita meneroka pesona perpustakaan ini. Perpustakaan Chrono C adalah sebahagian daripada Perpustakaan Standard, yang menyediakan cara moden untuk menangani selang waktu dan masa. Bagi pengaturcara yang telah menderita dari masa. H dan CTime, Chrono tidak diragukan lagi. Ia bukan sahaja meningkatkan kebolehbacaan dan mengekalkan kod, tetapi juga memberikan ketepatan dan fleksibiliti yang lebih tinggi. Mari kita mulakan dengan asas -asas. Perpustakaan Chrono terutamanya termasuk komponen utama berikut: STD :: Chrono :: System_Clock: Mewakili jam sistem, yang digunakan untuk mendapatkan masa semasa. Std :: Chron
 Bagaimana untuk mengendalikan paparan DPI yang tinggi di C?
Apr 28, 2025 pm 09:57 PM
Bagaimana untuk mengendalikan paparan DPI yang tinggi di C?
Apr 28, 2025 pm 09:57 PM
Mengendalikan paparan DPI yang tinggi di C boleh dicapai melalui langkah -langkah berikut: 1) Memahami DPI dan skala, gunakan API Sistem Operasi untuk mendapatkan maklumat DPI dan menyesuaikan output grafik; 2) Mengendalikan keserasian silang platform, gunakan perpustakaan grafik silang platform seperti SDL atau QT; 3) Melaksanakan pengoptimuman prestasi, meningkatkan prestasi melalui cache, pecutan perkakasan, dan pelarasan dinamik tahap butiran; 4) Selesaikan masalah biasa, seperti teks kabur dan elemen antara muka terlalu kecil, dan selesaikan dengan betul menggunakan skala DPI.
