Mona Lisa menguap, seekor ayam belajar mengangkat seterika... Model besar Google VideoPoet menunjukkan prestasi yang sangat baik.
Pada penghujung tahun 2023, syarikat teknologi memberi kesan kepada tahap terakhir AI generatif - penjanaan video. Pada hari Selasa, model penjanaan video besar yang dicadangkan oleh Google telah dilancarkan dan serta-merta menarik perhatian orang ramai. Model bahasa besar yang dipanggil VideoPoet ini dianggap sebagai alat penjanaan video tangkapan sifar revolusioner. VideoPenyair bukan sahaja boleh menjana video daripada teks dan imej, tetapi juga memindahkan gaya dan menukar video kepada pertuturan. Sebenarnya, ia boleh membina pergerakan yang pelbagai dan lancar. 
Sebaik sahaja berita itu keluar, ramai yang menyambutnya: Lihatlah beberapa produk siap semasa dengan hasil yang baik, dan perkembangan teknologi model besar terlalu pantas.
Seseorang meluahkan rasa terkejut dengan kepanjangan video yang dijana oleh model besar ini:
Sumber: https://twitter.com/cybersphere_ai39612us/1967 Juga Sesetengah orang mengatakan bahawa ini adalah model bahasa besar yang revolusioner.
Sesetengah orang juga memanggil Google untuk membuka sumber VideoPoet dengan cepat Trend umum tidak menunggu sesiapa pun.
Dengan pembangunan AI generatif, terdapat gelombang model penjanaan video baharu baru-baru ini yang menunjukkan kualiti gambar yang menakjubkan. Salah satu kesesakan semasa dalam penjanaan video ialah menjana pergerakan besar yang koheren. Tetapi dalam kebanyakan kes, walaupun model terkemuka hanya boleh menghasilkan gerakan yang lebih kecil, atau mempamerkan artifak yang ketara apabila menghasilkan gerakan yang lebih besar.
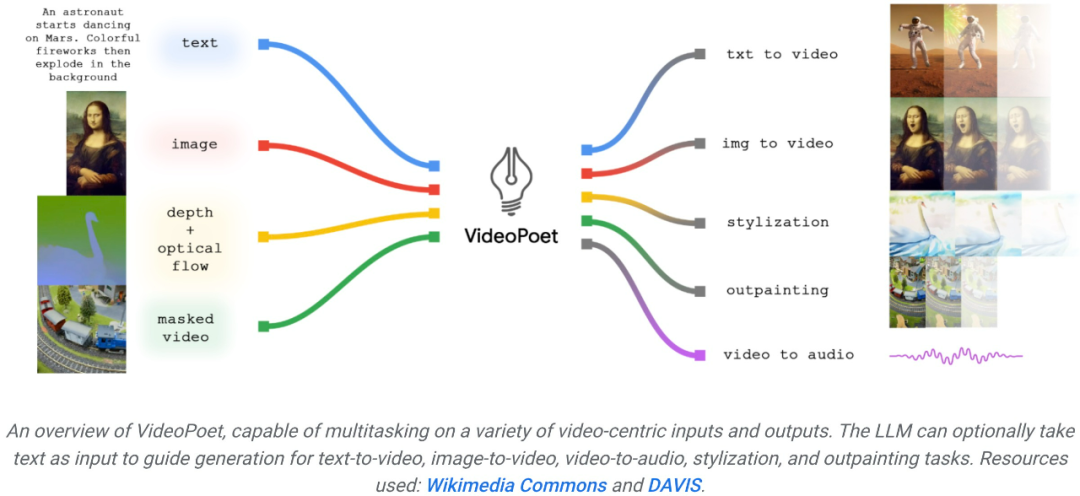
Untuk meneroka aplikasi model bahasa dalam penjanaan video, penyelidik dari Google memperkenalkan model bahasa besar (LLM) VideoPoet, yang boleh melaksanakan pelbagai tugas penjanaan video, termasuk teks ke video, imej ke video, Penggayaan video , pembaikan dan pengembangan video, dan penukaran video kepada audio.
Paparan kesan VideoPenyairPetua: Anjing sedang mendengar muzik
Petua (kiri ke kanan): Jerung menembak pancaran laser dari mulutnya;
Tips (kiri ke kanan): Seekor singa mengaum yang diperbuat daripada kelopak dandelion kuning letupan besar di permukaan Bumi; selfie.
Untuk imej ke video, VideoPoet boleh mengambil imej input dan menghidupkannya dengan gesaan.
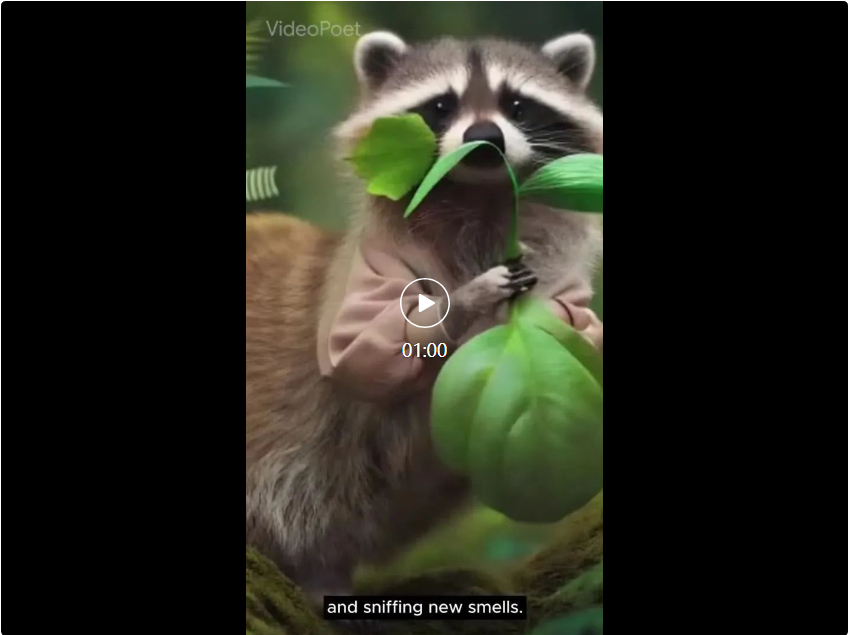
Untuk memulakan Mona Lisa menguap, cuma masukkan gambar dan gesaan: Seorang wanita menguap. Anda akan mendapat kesan berikut.
Petua (dari kiri ke kanan): Sebuah kapal berlayar di laut bergelora dengan ribut petir dan petir, gaya lukisan minyak terbang di atas nebula dengan banyak bintang berkelip-kelip berdiri di atas tebing dengan tongkat pada hari yang berangin, menghadap ke laut lautan awan terapung di bawah.
VideoPoet juga dapat menggayakan video input berdasarkan gesaan teks. Petua (kiri ke kanan): Teddy bear meluncur di tasik ais yang bersih;
VideoPoet juga boleh menjana audio. Mula-mula minta model menjana klip 2 saat dan kemudian cuba meramalkan audio adegan tanpa sebarang panduan teks. Dengan cara ini, VideoPoet mampu menjana video dan audio daripada satu model. VideoPoet juga boleh menjana video yang panjang, lalainya ialah 2 saat. Proses ini boleh diulang tanpa terhingga untuk menjana video dalam sebarang panjang dengan melaraskan 1 saat terakhir video dan meramalkan 1 saat seterusnya. Di bawah ialah contoh demonstrasi VideoPoet menjana video panjang daripada input teks. Petua: Rakaman FPV menunjukkan bandar Elfstone yang sangat tajam di dalam hutan, dengan sungai biru terang, air terjun dan muka tebing menegak yang besar dan curam.
Pengguna boleh menukar gesaan, dengan itu memanjangkan video. Video asal dua rakun menunggang motosikal di jalan gunung yang dikelilingi oleh pokok pain, 8k. Video yang diperluaskan menunjukkan dua rakun menunggang motosikal Sebuah meteor jatuh di belakang rakun, dan meteor itu mengenai bumi dan meletup.
Suntingan Video InteraktifUntuk input video yang disediakan (paling kiri), pengguna boleh menukar pergerakan objek untuk melakukan tindakan yang berbeza. Seperti yang ditunjukkan di bawah, tiga bahagian tengah tidak mempunyai gesaan teks, dan gesaan teks terakhir ialah: Mulakan dengan latar belakang asap.
VideoPoet boleh menambah butiran pada bahagian video yang tidak jelas, atau anda boleh memilih untuk membaikinya melalui panduan teks.
Untuk menunjukkan keupayaan VideoPoet, Google turut menghasilkan sebuah filem pendek yang terdiri daripada berbilang video pendek yang dihasilkan oleh VideoPoet. Skrip, yang ditulis oleh Bard, ialah cerita pendek tentang seekor rakun yang mengembara, lengkap dengan pecahan adegan demi adegan dan senarai segera yang disertakan. Google kemudian menjana klip video untuk setiap gesaan dan mencantumkan semua klip yang dijana bersama-sama untuk menghasilkan video akhir di bawah. Seperti yang ditunjukkan dalam rajah di bawah, VideoPoet boleh menghidupkan imej input untuk menghasilkan video, dan boleh mengedit video atau memanjangkan video.
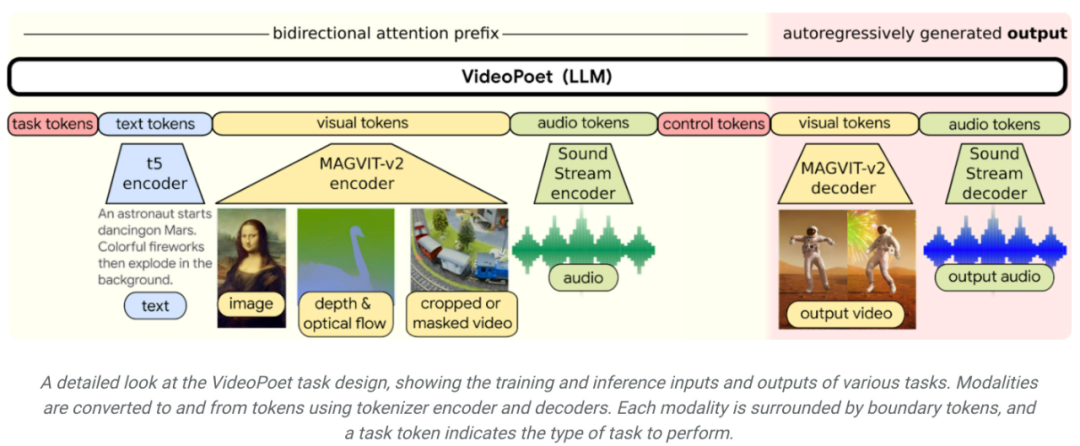
Dari segi penggayaan, model ini menerima video yang mencirikan kedalaman dan aliran optik untuk melukis kandungan dalam gaya berpandukan teks. Kelebihan utama menggunakan LLM untuk latihan ialah banyak peningkatan kecekapan berskala yang diperkenalkan dalam infrastruktur latihan LLM sedia ada boleh digunakan semula. Walau bagaimanapun, LLM beroperasi pada token diskret, yang menjadikan penjanaan video mencabar. Tokenizer video dan audio boleh digunakan untuk mengekod klip video dan audio ke dalam urutan token diskret, dan juga boleh ditukar kembali kepada perwakilan asal. Dengan menggunakan berbilang tokenizer (MAGVIT V2 untuk video dan imej dan SoundStream untuk audio), VideoPoet melatih model bahasa autoregresif untuk mempelajari pelbagai modaliti merentas video, imej, audio dan teks. Setelah model menjana token yang dikondisikan pada beberapa konteks, ia boleh menggunakan penyahkod tokenizer untuk menukarnya kembali kepada perwakilan visual.
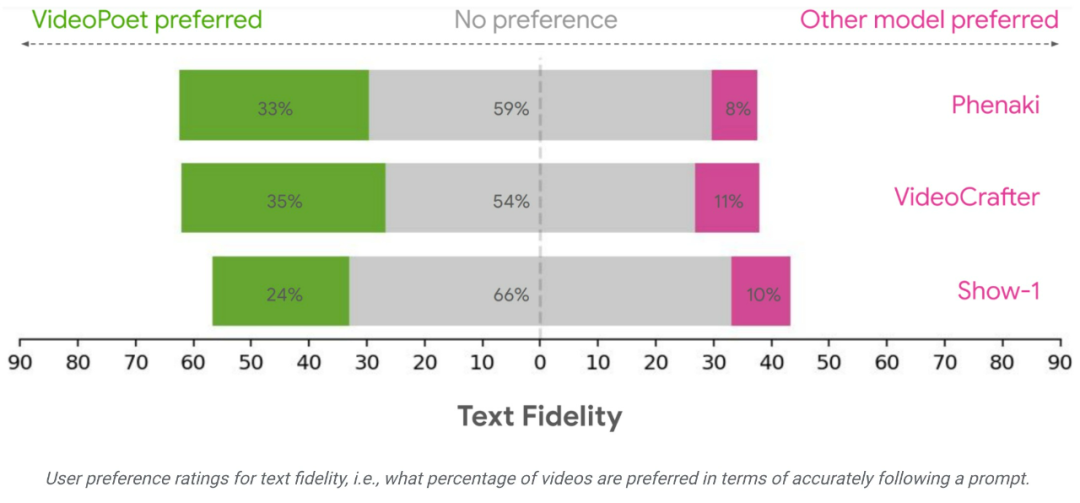
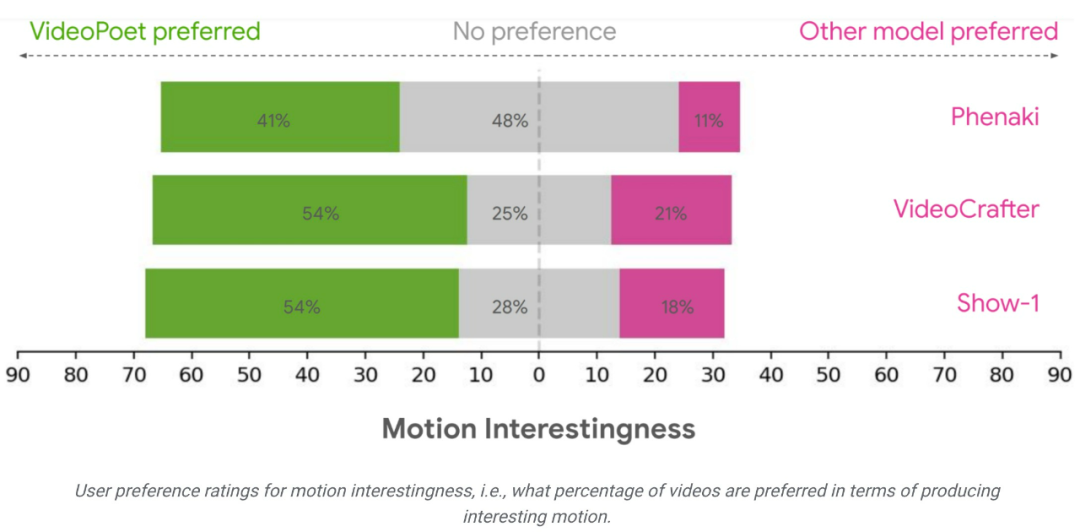
Pasukan penyelidik menilai prestasi VideoPoet dalam penjanaan teks-ke-video menggunakan pelbagai penanda aras untuk membandingkan keputusan dengan kaedah lain. Untuk memastikan penilaian neutral, kajian itu menjalankan semua model di bawah pelbagai gesaan, tanpa contoh pemetik ceri, dan meminta penilai manusia untuk memberikan penilaian keutamaan.
Secara purata, 24-35% contoh dalam VideoPoet dinilai lebih baik daripada model bersaing dalam gesaan berikut, berbanding dengan 8-11% model bersaing. Penilai juga memilih 41-54% daripada contoh dalam VideoPoet kerana tindakan yang menghasilkan video adalah lebih menarik, berbanding 11-21% daripada model lain. https://blog.research.google/2023/12/videopoet-large-language-model-for-zero.html ://sites.research.google/videopoet/stylization/🎜
Atas ialah kandungan terperinci Bolehkah penjanaan video tidak terhingga panjang? Model besar Google VideoPoet sedang dalam talian, netizen: teknologi revolusioner. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!


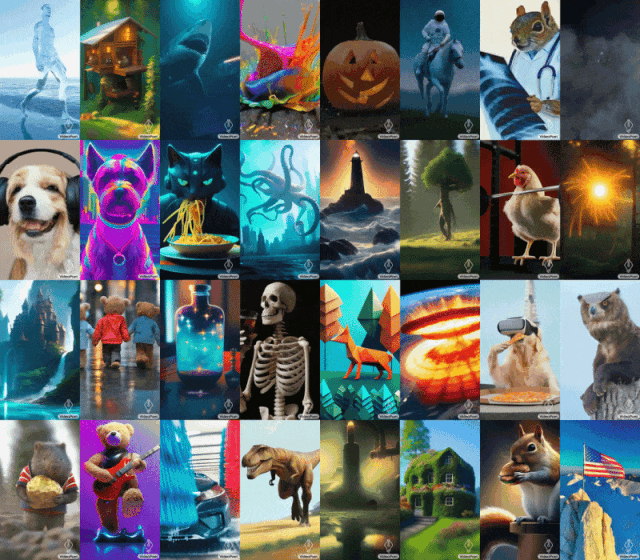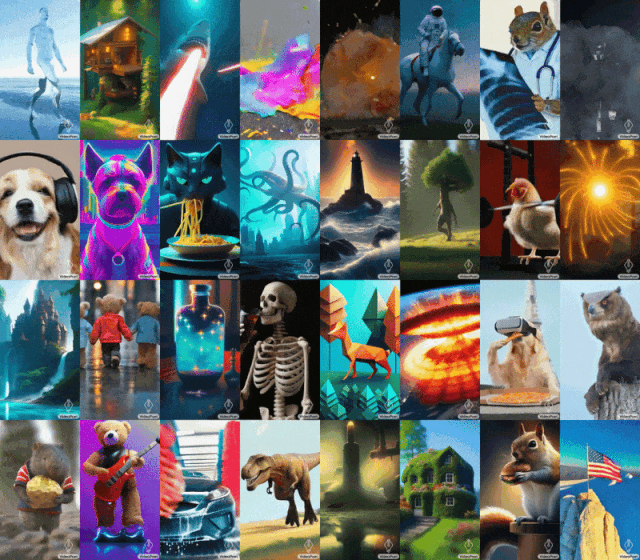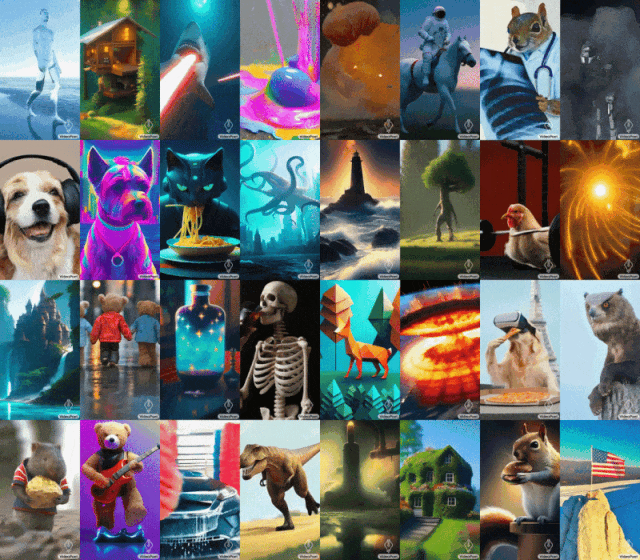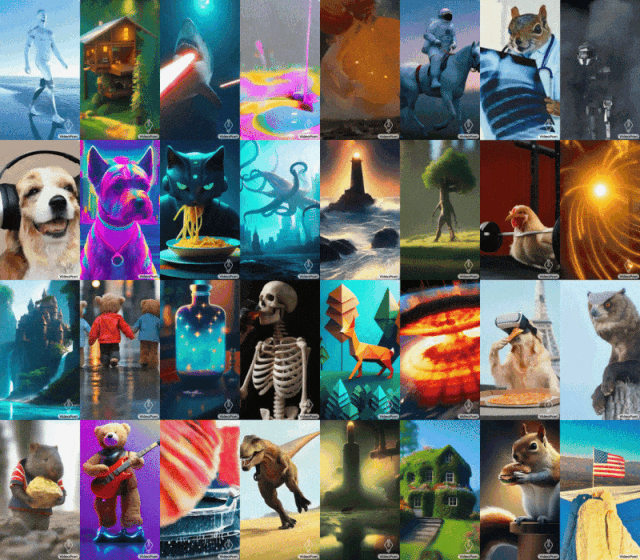













 Komputer menggesa penyelesaian nsiserror
Komputer menggesa penyelesaian nsiserror
 Bagaimana untuk menetapkan saiz fon html
Bagaimana untuk menetapkan saiz fon html
 Bagaimana untuk menerangi Douyin kawan rapat
Bagaimana untuk menerangi Douyin kawan rapat
 Mana satu lebih mudah, thinkphp atau laravel?
Mana satu lebih mudah, thinkphp atau laravel?
 Bagaimana untuk menyemak nilai MD5
Bagaimana untuk menyemak nilai MD5
 Pengenalan kepada penggunaan fungsi MySQL ELT
Pengenalan kepada penggunaan fungsi MySQL ELT
 Bagaimana untuk membuka kebenaran skop
Bagaimana untuk membuka kebenaran skop
 Penyemak keserasian
Penyemak keserasian
 SVN mengabaikan tetapan fail
SVN mengabaikan tetapan fail








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



