
 Peranti teknologi
AI
Visualisasikan ruang vektor FAISS dan laraskan parameter RAG untuk meningkatkan ketepatan hasil
Peranti teknologi
AI
Visualisasikan ruang vektor FAISS dan laraskan parameter RAG untuk meningkatkan ketepatan hasil
Visualisasikan ruang vektor FAISS dan laraskan parameter RAG untuk meningkatkan ketepatan hasil

Memandangkan prestasi model bahasa berskala besar sumber terbuka terus bertambah baik, prestasi menulis dan menganalisis kod, pengesyoran, ringkasan teks dan pasangan menjawab soalan (QA) telah meningkat dengan ketara. Tetapi apabila ia berkaitan dengan QA, LLM sering gagal dalam isu yang berkaitan dengan data yang tidak terlatih, dan banyak dokumen dalaman disimpan dalam syarikat untuk memastikan pematuhan, rahsia perdagangan atau privasi. Apabila dokumen ini disoal, LLM boleh berhalusinasi dan menghasilkan kandungan yang tidak relevan, rekaan atau tidak konsisten.

Satu teknik yang mungkin untuk menangani cabaran ini ialah Retrieval Augmented Generation (RAG). Ia melibatkan proses meningkatkan respons dengan merujuk pangkalan pengetahuan berwibawa di luar sumber data latihan untuk meningkatkan kualiti dan ketepatan penjanaan. Sistem RAG terdiri daripada sistem perolehan semula yang mengambil serpihan dokumen yang berkaitan daripada korpus, dan model LLM yang menggunakan serpihan yang diperoleh semula sebagai konteks untuk menjana respons. Oleh itu, kualiti korpus dan perwakilan yang tertanam dalam ruang vektor adalah penting untuk prestasi RAG.
Dalam artikel ini, kami akan menggunakan pustaka visualisasi renumics-spotlight untuk memvisualisasikan pembenaman berbilang dimensi ruang vektor FAISS dalam 2-D dan mencari kemungkinan untuk meningkatkan ketepatan tindak balas RAG dengan menukar beberapa parameter vektorisasi utama. Untuk LLM yang kami pilih, kami akan menggunakan Sembang TinyLlama 1.1B, model padat dengan seni bina yang sama seperti Llama 2. Ia mempunyai kelebihan kerana mempunyai jejak sumber yang lebih kecil dan masa jalan yang lebih pantas tanpa penurunan ketepatan yang berkadar, menjadikannya sesuai untuk percubaan pantas.
Reka bentuk sistem
Sistem QA mempunyai dua modul, seperti yang ditunjukkan dalam rajah.
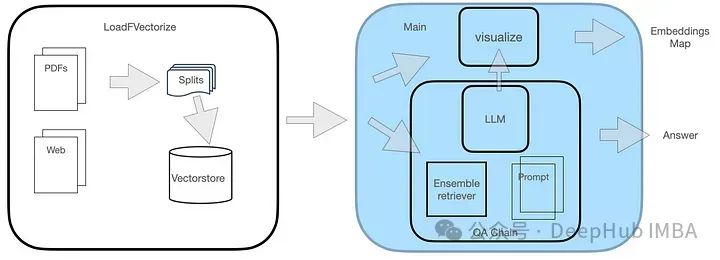
Modul LoadFVectorize digunakan untuk memuatkan dokumen PDF atau Web dan melaksanakan ujian dan visualisasi awal. Modul lain bertanggungjawab untuk memuatkan LLM dan menginstant pencari FAISS, dan kemudian membina rantai carian termasuk LLM, pencari dan gesaan pertanyaan tersuai. Akhirnya, kami menggambarkan ruang vektor.
Pelaksanaan kod
1. Pasang perpustakaan yang diperlukan
perpustakaan lampu sorot renomics menggunakan kaedah visualisasi seperti umap untuk mengurangkan pembenaman visualisasi berdimensi tinggi ke dalam atribut 2iD yang boleh diurus Kami telah memperkenalkan secara ringkas penggunaan umap sebelum ini, tetapi hanya fungsi asas. Kali ini, kami menyepadukannya ke dalam projek sebenar sebagai sebahagian daripada reka bentuk sistem. Pertama, anda perlu memasang perpustakaan yang diperlukan.
pip install langchain faiss-cpu sentence-transformers flask-sqlalchemy psutil unstructured pdf2image unstructured_inference pillow_heif opencv-python pikepdf pypdf pip install renumics-spotlight CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 pip install --upgrade --force-reinstall llama-cpp-python --no-cache-dir
Barisan terakhir di atas ialah memasang perpustakaan llama-pcp-python dengan sokongan Metal, yang akan digunakan untuk memuatkan TinyLlama dengan pecutan perkakasan pada pemproses M1.
2. Modul LoadFVectorize
modul merangkumi 3 fungsi:
load_doc mengendalikan pemuatan dokumen pdf dalam talian, setiap blok dibahagikan kepada 512 aksara dan dokumen bertindih 1.00
vectorize memanggil fungsi load_doc di atas untuk mendapatkan senarai blok dokumen, mencipta benam dan menyimpannya ke direktori tempatan opdf_index, dan mengembalikan tika FAISS.
load_db menyemak sama ada pustaka FAISS berada pada cakera dalam direktori opdf_index dan cuba memuatkannya, akhirnya mengembalikan objek FAISS. Kod Lengkap Kod Modul ini adalah seperti berikut:
# LoadFVectorize.py from langchain_community.embeddings import HuggingFaceEmbeddings from langchain_community.document_loaders import OnlinePDFLoader from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_community.vectorstores import FAISS # access an online pdf def load_doc() -> 'List[Document]':loader = OnlinePDFLoader("https://support.riverbed.com/bin/support/download?did=7q6behe7hotvnpqd9a03h1dji&versinotallow=9.15.0")documents = loader.load()text_splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=100)docs = text_splitter.split_documents(documents)return docs # vectorize and commit to disk def vectorize(embeddings_model) -> 'FAISS':docs = load_doc()db = FAISS.from_documents(docs, embeddings_model)db.save_local("./opdf_index")return db # attempts to load vectorstore from disk def load_db() -> 'FAISS':embeddings_model = HuggingFaceEmbeddings()try:db = FAISS.load_local("./opdf_index", embeddings_model)except Exception as e:print(f'Exception: {e}\nNo index on disk, creating new...')db = vectorize(embeddings_model)return dbModul Utama pada mulanya mentakrifkan template Tinyllama Prompt template berikut:
{context}{question}Kemudian gunakan objek FAISS yang dikembalikan oleh modul LoadFVectorize, buat pengutip FAISS, buat seketika RetrievalQA dan gunakannya untuk pertanyaan. . -id, digunakan Jumlah kiraan dokumen yang divektorkan diwakili oleh atribut jumlah objek indeks.
# main.py from langchain.chains import RetrievalQA from langchain.prompts import PromptTemplate from langchain_community.llms import LlamaCpp from langchain_community.embeddings import HuggingFaceEmbeddings import LoadFVectorize from renumics import spotlight import pandas as pd import numpy as np # Prompt template qa_template = """ You are a friendly chatbot who always responds in a precise manner. If answer is unknown to you, you will politely say so. Use the following context to answer the question below: {context} {question} """ # Create a prompt instance QA_PROMPT = PromptTemplate.from_template(qa_template) # load LLM llm = LlamaCpp(model_path="./models/tinyllama_gguf/tinyllama-1.1b-chat-v1.0.Q5_K_M.gguf",temperature=0.01,max_tokens=2000,top_p=1,verbose=False,n_ctx=2048 ) # vectorize and create a retriever db = LoadFVectorize.load_db() faiss_retriever = db.as_retriever(search_type="mmr", search_kwargs={'fetch_k': 3}, max_tokens_limit=1000) # Define a QA chain qa_chain = RetrievalQA.from_chain_type(llm,retriever=faiss_retriever,chain_type_kwargs={"prompt": QA_PROMPT} ) query = 'What versions of TLS supported by Client Accelerator 6.3.0?' result = qa_chain({"query": query}) print(f'--------------\nQ: {query}\nA: {result["result"]}') visualize_distance(db,query,result["result"])vs = db.__dict__.get("docstore")index_list = db.__dict__.get("index_to_docstore_id").values()doc_cnt = db.index.ntotal
embeddings_vec = db.index.reconstruct_n()
doc_list = list() for i,doc-id in enumerate(index_list):a_doc = vs.search(doc-id)doc_list.append([doc-id,a_doc.metadata.get("source"),a_doc.page_content,embeddings_vec[i]])在继续进行可视化之前,还需要将问题和答案结合起来,我们创建一个单独的问题以及答案的DF,然后与上面的df进行合并,这样能够显示问题和答案出现的地方,在可视化时我们可以高亮显示:
# add rows for question and answerembeddings_model = HuggingFaceEmbeddings()question_df = pd.DataFrame({"id": "question","question": question,"embedding": [embeddings_model.embed_query(question)],})answer_df = pd.DataFrame({"id": "answer","answer": answer,"embedding": [embeddings_model.embed_query(answer)],})df = pd.concat([question_df, answer_df, df])这里使用使用np.linalg.norm在文件和问题嵌入上的进行距离大小的计算:
question_embedding = embeddings_model.embed_query(question)# add column for vector distancedf["dist"] = df.apply( lambda row: np.linalg.norm(np.array(row["embedding"]) - question_embedding),axis=1,)
因为spotlight可以对df进行可视化,所有我们直接调用即可
spotlight.show(df)
Langkah ini akan melancarkan sorotan dalam tetingkap penyemak imbas. 、 Ujian berjalan 基 1. Ujian asas
Di bawah ialah contoh masalah yang kami pilih:
Apakah versi TLS yang Disokong oleh Client Accelerator 6.3.0
jawapan betulBetul: Ya
Betul?
Clien Accelerator 6.3.0 menyokong TLS 1.1 atau 1.2.
Maklumat tambahan berikut mungkin disertakan dalam respons.
Anda mesti mendayakan keupayaan ini menggunakan arahan CLI berikut pada Client Accelerator:(config) # policy id
ssl backend client-tls-1.2Walaupun TLS 1.1 tidak disebut dalam sintaks arahan ini, menggunakan arahan ini secara automatik mendayakan sokongan untuk kedua-dua TLS 1.1 dan 1.2.
Kemudian mari kita lihat jawapan TinyLlama untuk soalan di atas:
Pemecut Pelanggan 6.3.0 sebagai lalai atau TLS Accelerator 6.3.0. versi TLS yang disokong dengan Client Accelerator Anda mesti mendayakan keupayaan ini menggunakan arahan CLI berikut pada Client Accelerator:```(config) # policy id
sebaliknya.s clients backend -tlss1.2```Perhatikan bahawa arahan ini hanya terpakai pada TLS 1.1 atau TLS 1.2 Jika anda perlu menyokong versi TLS yang lebih lama, anda boleh menggunakan arahan ssl backend dengan klien-tlss1.0. atau pilihan pelanggan-tlss1.1
kelihatan sangat serupa dengan jawapan sebenar, tetapi ia tidak betul sepenuhnya kerana versi TLS ini bukan lalainya.
Jadi mari kita lihat petikan mana dia mendapat jawapannya?
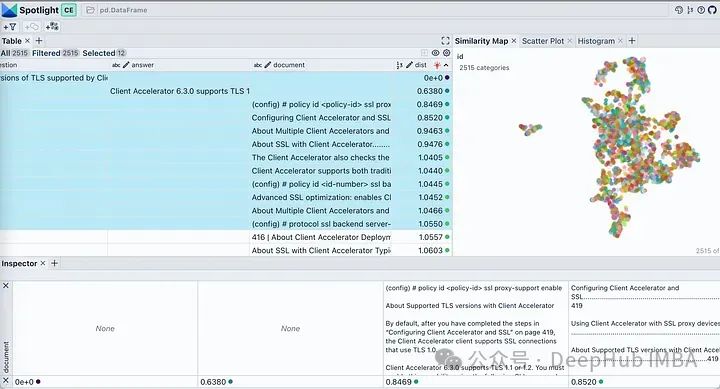
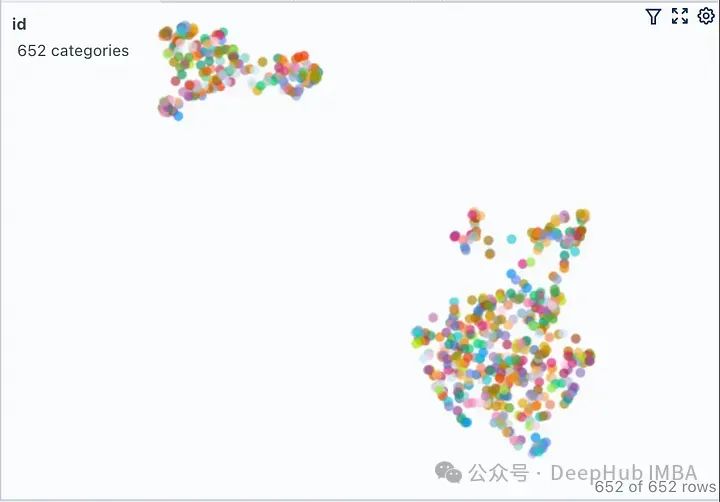
Gunakan butang yang kelihatan dalam lampu sorot untuk mengawal lajur yang dipaparkan. Isih jadual mengikut "dist" untuk menunjukkan soalan, jawapan dan coretan dokumen yang paling berkaitan di bahagian atas. Melihat pada pembenaman dokumen kami, ia menerangkan hampir semua bahagian dokumen sebagai satu kelompok. Ini adalah munasabah kerana PDF asal kami ialah panduan penggunaan untuk produk tertentu, jadi tiada masalah untuk dianggap sebagai kluster.
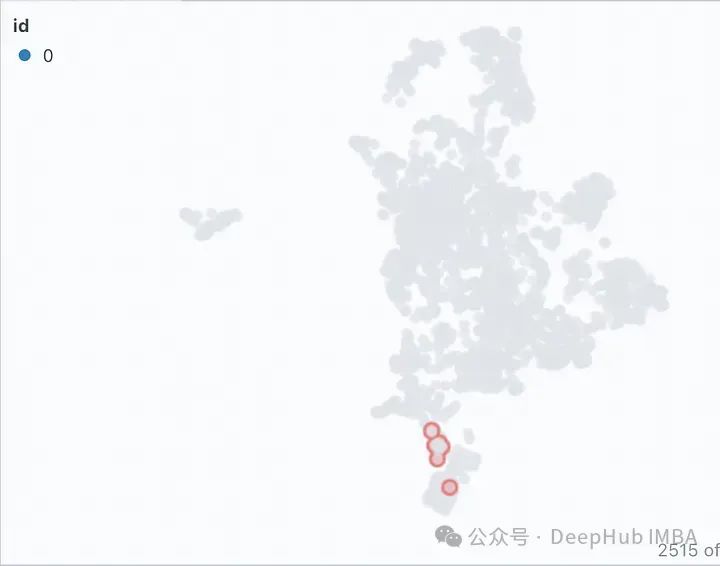
Klik pada ikon penapis dalam tab Peta Persamaan, ia hanya menyerlahkan senarai dokumen yang dipilih, yang berkelompok rapat, dan selebihnya ditunjukkan dalam warna kelabu seperti yang ditunjukkan dalam imej di bawah. . Saiz ketulan TextSplitter (1000, 2000) dan/atau bertindih (100, 200) parameter adalah berbeza semasa pemisahan dokumen.
Keluaran nampaknya serupa untuk semua kombinasi, tetapi jika kita membandingkan dengan teliti jawapan yang betul dengan setiap jawapan, jawapan yang tepat ialah (1000,200). Butiran yang salah dalam respons lain telah diserlahkan dengan warna merah. Mari cuba terangkan tingkah laku ini menggunakan pembenaman visual:
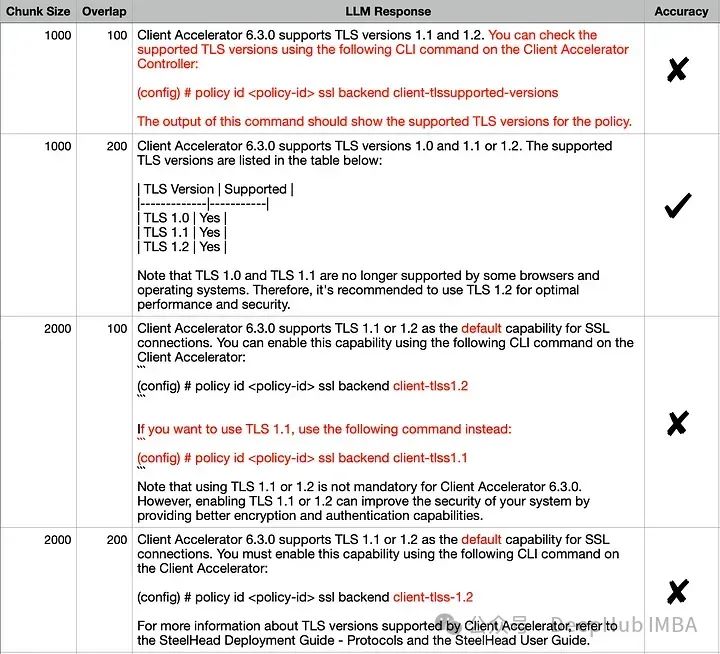
如果查询位于簇中心等位置时由于最近邻可能不同,在这些参数发生变化时响应很可能会发生显著变化。如果RAG应用程序无法提供预期答案给某些问题,则可以通过生成类似上述可视化图表并结合这些问题进行分析,可能找到最佳划分语料库以提高整体性能方面优化方法。 为了进一步说明,我们将两个来自不相关领域(Grammy Awards和JWST telescope)的维基百科文档的向量空间进行可视化展示。 只修改了上面代码其余的代码保持不变。运行修改后的代码,我们得到下图所示的向量空间可视化。 这里有两个不同的不重叠的簇。如果我们要在任何一个簇之外提出一个问题,那么从检索器获得上下文不仅不会对LLM有帮助,而且还很可能是有害的。提出之前提出的同样的问题,看看我们LLM产生什么样的“幻觉” Client Accelerator 6.3.0 supports the following versions of Transport Layer Security (TLS): 这里我们使用FAISS用于向量存储。如果你正在使用ChromaDB并想知道如何执行类似的可视化,renumics-spotlight也是支持的。 检索增强生成(RAG)允许我们利用大型语言模型的能力,即使LLM没有对内部文档进行训练也能得到很好的结果。RAG涉及从矢量库中检索许多相关文档块,然后LLM将其用作生成的上下文。因此嵌入的质量将在RAG性能中发挥重要作用。 在本文中,我们演示并可视化了几个关键矢量化参数对LLM整体性能的影响。并使用renumics-spotlight,展示了如何表示整个FAISS向量空间,然后将嵌入可视化。Spotlight直观的用户界面可以帮助我们根据问题探索向量空间,从而更好地理解LLM的反应。通过调整某些矢量化参数,我们能够影响其生成行为以提高精度。def load_doc():loader = WebBaseLoader(['https://en.wikipedia.org/wiki/66th_Annual_Grammy_Awards','https://en.wikipedia.org/wiki/James_Webb_Space_Telescope'])documents = loader.load()...
总结
Atas ialah kandungan terperinci Visualisasikan ruang vektor FAISS dan laraskan parameter RAG untuk meningkatkan ketepatan hasil. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Mengapa penyemak imbas Chrome ranap? Bagaimana untuk menyelesaikan masalah ranap Google Chrome semasa membuka?
Mar 13, 2024 pm 07:28 PM
Mengapa penyemak imbas Chrome ranap? Bagaimana untuk menyelesaikan masalah ranap Google Chrome semasa membuka?
Mar 13, 2024 pm 07:28 PM
Google Chrome mempunyai keselamatan yang tinggi dan kestabilan yang kukuh, dan disukai oleh majoriti pengguna. Walau bagaimanapun, sesetengah pengguna mendapati bahawa Google Chrome ranap sebaik sahaja mereka membukanya. Apa yang sedang berlaku? Mungkin terlalu banyak tab dibuka, atau versi penyemak imbas terlalu lama Mari kita lihat penyelesaian terperinci di bawah. Bagaimana untuk menyelesaikan masalah ranap Google Chrome? 1. Tutup beberapa tab yang tidak perlu Jika terdapat terlalu banyak tab terbuka, cuba tutup beberapa tab yang tidak diperlukan, yang boleh mengurangkan tekanan sumber Google Chrome dengan berkesan dan mengurangkan kemungkinan ranap. 2. Kemas kini Google Chrome Jika versi Google Chrome terlalu lama, ia juga akan menyebabkan ranap dan ralat lain Anda disyorkan untuk mengemas kini Chrome kepada versi terkini. Klik [Sesuaikan dan Kawalan]-[Tetapan] di penjuru kanan sebelah atas
 Windows pada Ollama: Alat baharu untuk menjalankan model bahasa besar (LLM) secara tempatan
Feb 28, 2024 pm 02:43 PM
Windows pada Ollama: Alat baharu untuk menjalankan model bahasa besar (LLM) secara tempatan
Feb 28, 2024 pm 02:43 PM
Baru-baru ini, kedua-dua OpenAITranslator dan NextChat telah mula menyokong model bahasa berskala besar yang dijalankan secara tempatan di Ollama, yang menambah cara baharu bermain untuk peminat "pemula". Lebih-lebih lagi, pelancaran Ollama pada Windows (versi pratonton) telah meruntuhkan sepenuhnya cara pembangunan AI pada peranti Windows Ia telah membimbing laluan yang jelas untuk penjelajah dalam bidang AI dan "pemain ujian air" biasa. Apa itu Ollama? Ollama ialah platform alat kecerdasan buatan (AI) dan pembelajaran mesin (ML) terobosan yang sangat memudahkan pembangunan dan penggunaan model AI. Dalam komuniti teknikal, konfigurasi perkakasan dan pembinaan persekitaran model AI sentiasa menjadi isu yang sukar.
 Bagaimana untuk menyelesaikan ranap pycharm
Apr 25, 2024 am 05:09 AM
Bagaimana untuk menyelesaikan ranap pycharm
Apr 25, 2024 am 05:09 AM
Penyelesaian kepada ranap PyCharm termasuk: semak penggunaan memori dan tingkatkan had ingatan PyCharm kepada versi terkini dan lumpuhkan atau nyahpasang tetapan PyCharm, lumpuhkan pecutan perkakasan; Untuk pertolongan.
 Mengapakah model bahasa besar menggunakan SwiGLU sebagai fungsi pengaktifan?
Apr 08, 2024 pm 09:31 PM
Mengapakah model bahasa besar menggunakan SwiGLU sebagai fungsi pengaktifan?
Apr 08, 2024 pm 09:31 PM
Jika anda telah memberi perhatian kepada seni bina model bahasa yang besar, anda mungkin pernah melihat istilah "SwiGLU" dalam model dan kertas penyelidikan terkini. SwiGLU boleh dikatakan sebagai fungsi pengaktifan yang paling biasa digunakan dalam model bahasa besar Kami akan memperkenalkannya secara terperinci dalam artikel ini. SwiGLU sebenarnya adalah fungsi pengaktifan yang dicadangkan oleh Google pada tahun 2020, yang menggabungkan ciri-ciri SWISH dan GLU. Nama penuh Cina SwiGLU ialah "unit linear berpagar dua arah". Ia mengoptimumkan dan menggabungkan dua fungsi pengaktifan, SWISH dan GLU, untuk meningkatkan keupayaan ekspresi tak linear model. SWISH ialah fungsi pengaktifan yang sangat biasa yang digunakan secara meluas dalam model bahasa besar, manakala GLU telah menunjukkan prestasi yang baik dalam tugas pemprosesan bahasa semula jadi.
 Panduan langkah demi langkah untuk menggunakan Groq Llama 3 70B secara tempatan
Jun 10, 2024 am 09:16 AM
Panduan langkah demi langkah untuk menggunakan Groq Llama 3 70B secara tempatan
Jun 10, 2024 am 09:16 AM
Penterjemah |. Tinjauan Bugatti |. Chonglou Artikel ini menerangkan cara menggunakan enjin inferens GroqLPU untuk menjana respons sangat pantas dalam JanAI dan VSCode. Semua orang sedang berusaha membina model bahasa besar (LLM) yang lebih baik, seperti Groq yang memfokuskan pada bahagian infrastruktur AI. Sambutan pantas daripada model besar ini adalah kunci untuk memastikan model besar ini bertindak balas dengan lebih cepat. Tutorial ini akan memperkenalkan enjin parsing GroqLPU dan cara mengaksesnya secara setempat pada komputer riba anda menggunakan API dan JanAI. Artikel ini juga akan menyepadukannya ke dalam VSCode untuk membantu kami menjana kod, kod refactor, memasukkan dokumentasi dan menjana unit ujian. Artikel ini akan mencipta pembantu pengaturcaraan kecerdasan buatan kami sendiri secara percuma. Pengenalan kepada enjin inferens GroqLPU Groq
 Emulator Android disyorkan yang lebih lancar (pilih emulator Android yang anda mahu gunakan)
Apr 21, 2024 pm 06:01 PM
Emulator Android disyorkan yang lebih lancar (pilih emulator Android yang anda mahu gunakan)
Apr 21, 2024 pm 06:01 PM
Ia boleh memberikan pengguna pengalaman permainan dan pengalaman penggunaan yang lebih baik Emulator Android ialah perisian yang boleh mensimulasikan perjalanan sistem Android pada komputer. Terdapat banyak jenis emulator Android di pasaran, dan kualitinya berbeza-beza, walau bagaimanapun. Untuk membantu pembaca memilih emulator yang paling sesuai untuk mereka, artikel ini akan memfokuskan pada beberapa emulator Android yang lancar dan mudah digunakan. 1. BlueStacks: Kelajuan larian yang pantas Dengan kelajuan larian yang sangat baik dan pengalaman pengguna yang lancar, BlueStacks ialah emulator Android yang popular. Membenarkan pengguna bermain pelbagai permainan dan aplikasi mudah alih, ia boleh mencontohi sistem Android pada komputer dengan prestasi yang sangat tinggi. 2. NoxPlayer: Menyokong berbilang bukaan, menjadikannya lebih menyeronokkan untuk bermain permainan Anda boleh menjalankan permainan yang berbeza dalam berbilang emulator pada masa yang sama
 Adakah saya perlu mendayakan pecutan perkakasan GPU?
Feb 26, 2024 pm 08:45 PM
Adakah saya perlu mendayakan pecutan perkakasan GPU?
Feb 26, 2024 pm 08:45 PM
Adakah perlu untuk mendayakan GPU dipercepatkan perkakasan? Dengan pembangunan dan kemajuan teknologi yang berterusan, GPU (Unit Pemprosesan Grafik), sebagai komponen teras pemprosesan grafik komputer, memainkan peranan penting. Walau bagaimanapun, sesetengah pengguna mungkin mempunyai soalan tentang sama ada pecutan perkakasan perlu dihidupkan. Artikel ini akan membincangkan keperluan pecutan perkakasan untuk GPU dan kesan menghidupkan pecutan perkakasan pada prestasi komputer dan pengalaman pengguna. Pertama, kita perlu memahami cara GPU dipercepatkan perkakasan berfungsi. GPU adalah khusus
 Apakah yang perlu saya lakukan jika borang WPS bertindak balas dengan perlahan? Mengapa borang WPS tersekat dan lambat untuk bertindak balas?
Mar 14, 2024 pm 02:43 PM
Apakah yang perlu saya lakukan jika borang WPS bertindak balas dengan perlahan? Mengapa borang WPS tersekat dan lambat untuk bertindak balas?
Mar 14, 2024 pm 02:43 PM
Apakah yang perlu saya lakukan jika borang WPS bertindak balas dengan sangat perlahan? Pengguna boleh cuba menutup program lain atau mengemas kini perisian untuk menjalankan operasi Biarkan tapak ini memperkenalkan dengan teliti kepada pengguna mengapa borang WPS lambat bertindak balas. Mengapa jadual WPS lambat bertindak balas 1. Tutup program lain: Tutup program lain yang sedang berjalan, terutamanya yang menggunakan banyak sumber sistem. Ini boleh menyediakan WPS Office dengan lebih banyak sumber pengkomputeran dan mengurangkan ketinggalan dan kelewatan. 2. Kemas kini WPSOffice: Pastikan anda menggunakan versi terkini WPSOffice. Memuat turun dan memasang versi terkini daripada tapak web WPSOffice rasmi boleh menyelesaikan beberapa isu prestasi yang diketahui. 3. Kecilkan saiz fail
