

EfficientSAM Kerja ini dimasukkan dalam CVPR 2024 dengan skor sempurna 5/5/5! Penulis berkongsi hasilnya di media sosial, seperti yang ditunjukkan dalam gambar di bawah:
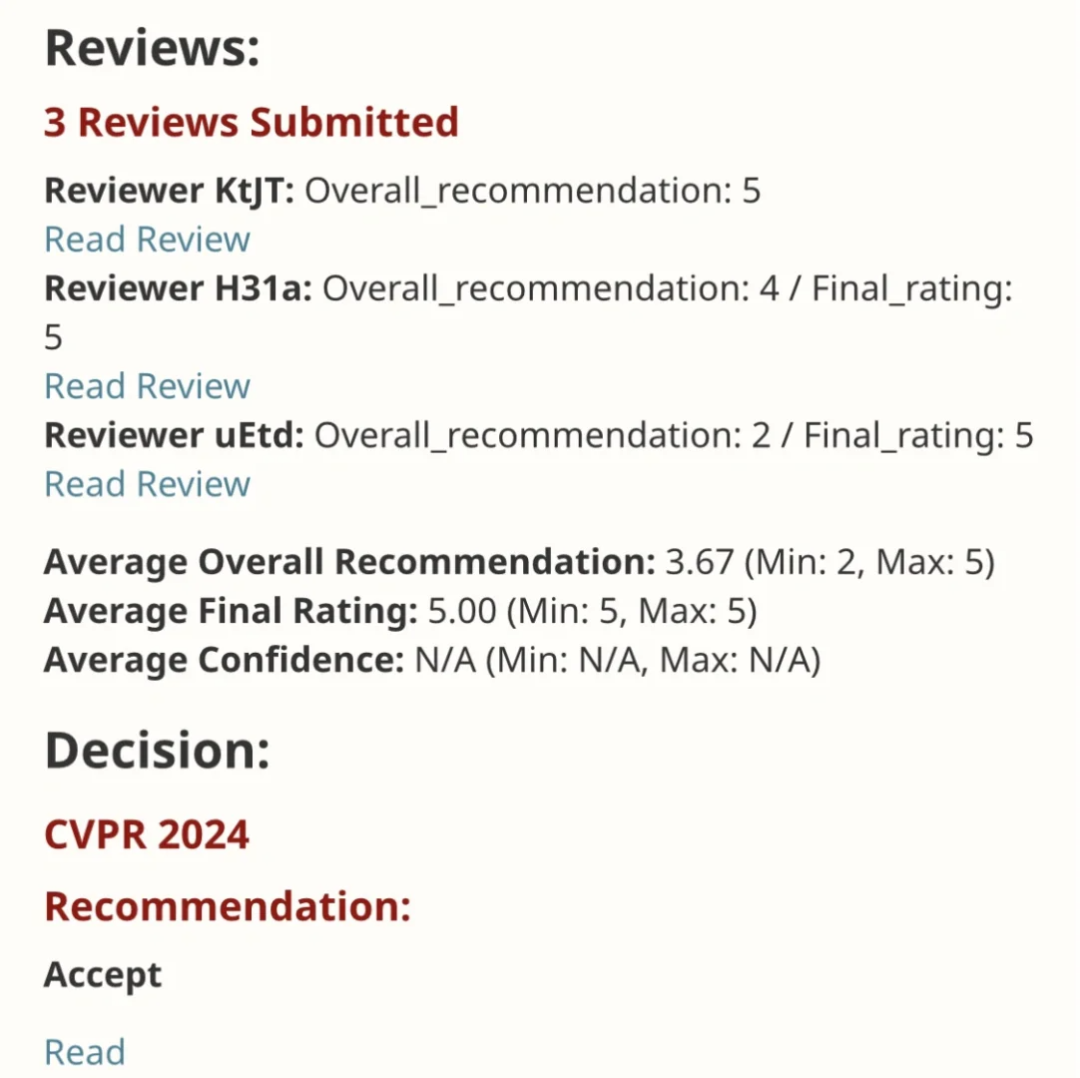
Pemenang Anugerah LeCun Turing juga sangat mengesyorkan karya ini!

Dalam penyelidikan baru-baru ini, penyelidik Meta telah mencadangkan kaedah baharu yang dipertingkatkan, pra-latihan imej bertopeng menggunakan SAM (SAMI). Pendekatan ini menggabungkan teknik pra-latihan MAE dan model SAM untuk mencapai pengekod ViT pra-latihan berkualiti tinggi. Melalui SAMI, penyelidik cuba meningkatkan prestasi dan kecekapan model dan menyediakan penyelesaian yang lebih baik untuk tugas penglihatan. Cadangan kaedah ini membawa idea dan peluang baharu untuk meneroka dan mengembangkan lagi bidang visi komputer dan pembelajaran mendalam. Dengan menggabungkan teknik pra-latihan dan struktur model yang berbeza, penyelidik terus

Untuk mengesahkan keberkesanan kaedah ini, penyelidik menggunakan tetapan pembelajaran pemindahan yang telah dilatih terlebih dahulu pada imej bertopeng. Khususnya, mereka mula-mula melatih model dengan kehilangan pembinaan semula pada dataset ImageNet dengan resolusi imej 224×224. Mereka kemudian memperhalusi model menggunakan data yang diselia daripada tugas sasaran. Kaedah pembelajaran pemindahan ini boleh membantu model belajar dengan cepat dan meningkatkan prestasi pada tugasan baharu kerana model telah belajar mengekstrak ciri daripada data asal melalui peringkat pra-latihan. Strategi pembelajaran pemindahan ini menggunakan secara berkesan pengetahuan yang dipelajari pada set data berskala besar, menjadikannya lebih mudah untuk model menyesuaikan diri dengan tugasan yang berbeza, manakala
ViT-Tiny boleh dilatih pada ImageNet-1K melalui pra-latihan SAMI/- Kecil/-Base dan model lain, dan meningkatkan prestasi generalisasi. Untuk model ViT-Small, selepas penyelidik memperhalusi 100 kali pada ImageNet-1K, ketepatan Top-1nya mencapai 82.7%, yang lebih baik daripada garis dasar pra-latihan imej terkini yang lain.
Para penyelidik memperhalusi model pra-latihan mengenai pengesanan sasaran, pembahagian contoh dan pembahagian semantik. Dalam semua tugas ini, kaedah kami mencapai hasil yang lebih baik daripada garis dasar pra-latihan lain, dan yang lebih penting, mencapai keuntungan yang ketara pada model kecil.
Yunyang Xiong, pengarang kertas itu, berkata: Parameter EfficientSAM yang dicadangkan dalam artikel ini dikurangkan sebanyak 20 kali, tetapi masa berjalan adalah 20 kali lebih cepat Perbezaan dengan model SAM asal hanya dalam 2 mata peratusan , yang jauh lebih baik daripada MobileSAM/FastSAM.


:
Alamat percubaan: https://ab348ea7942fe2af48.gradio.live/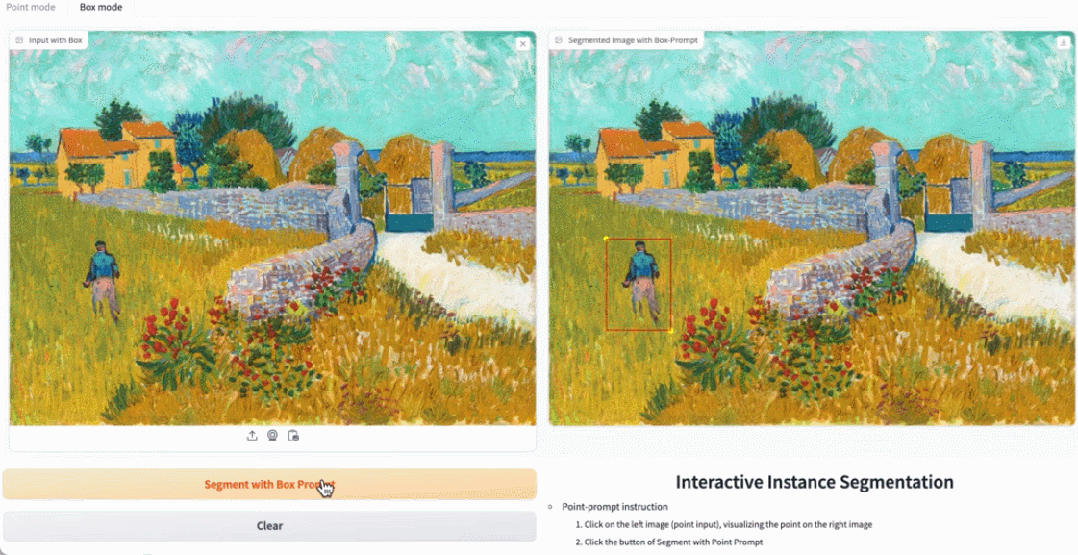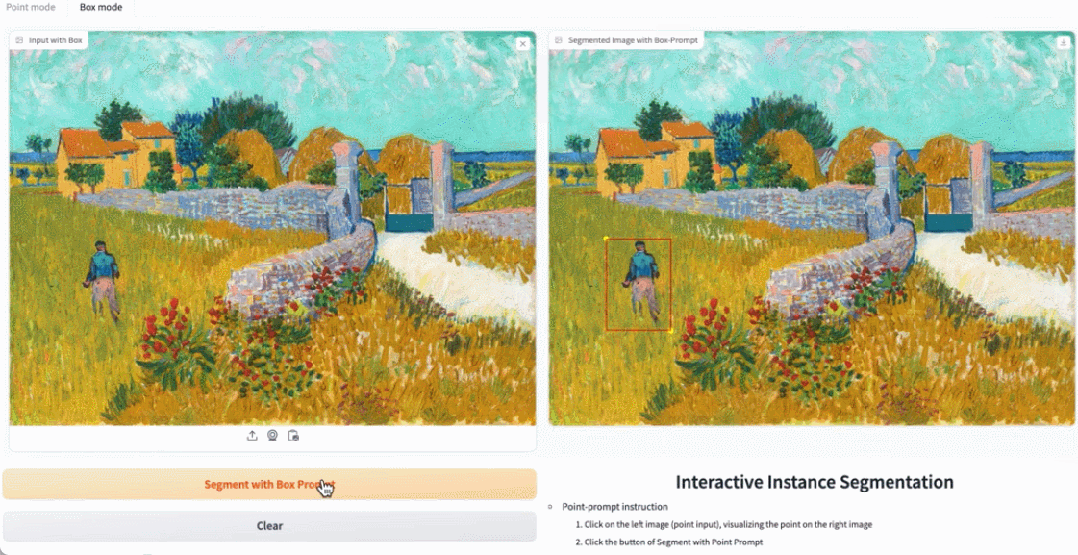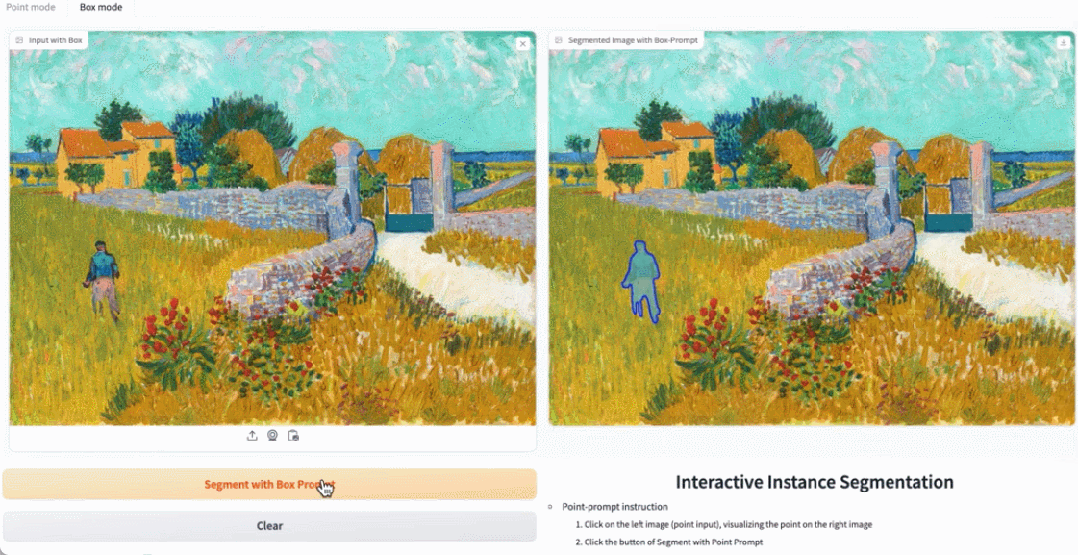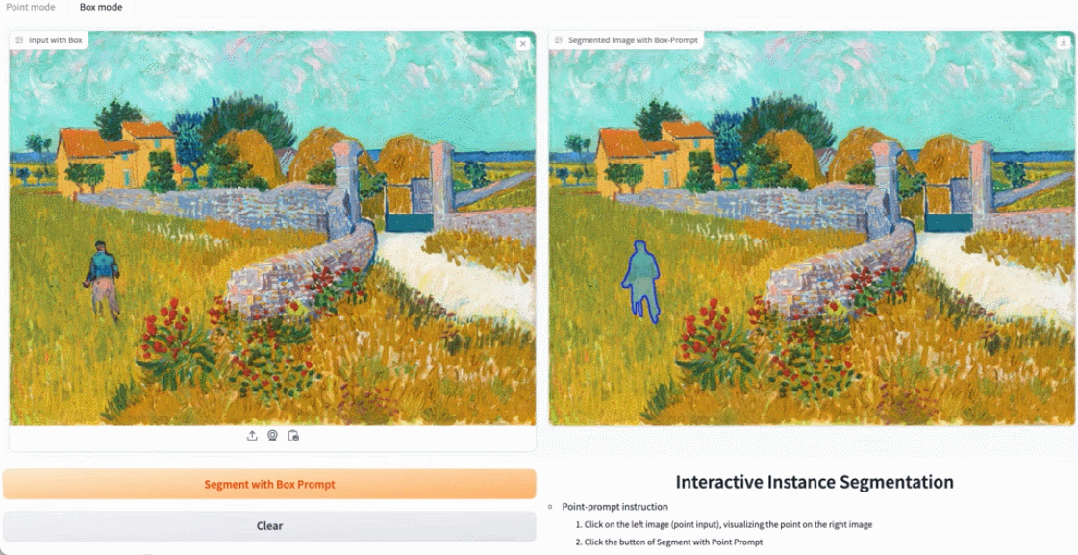
Kaedah
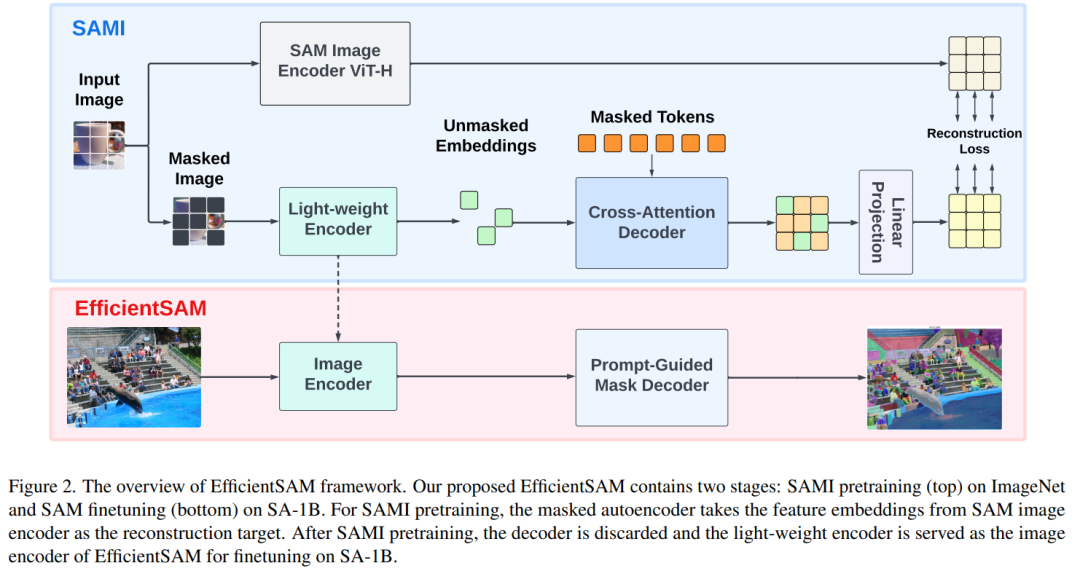
EfficientSAM terutamanya mengandungi komponen berikut:
Penyahkod perhatian silang: Di bawah pengawasan ciri SAM, kertas ini memerhatikan bahawa hanya token topeng perlu dibina semula oleh penyahkod, manakala output pengekod boleh dibina semula semasa proses pembinaan semula bertindak sebagai sauh. Dalam penyahkod silang perhatian, pertanyaan datang daripada token bertopeng, dan kunci serta nilai diperoleh daripada ciri yang tidak bertopeng dan ciri bertopeng daripada pengekod. Kertas kerja ini menggabungkan ciri output daripada token bertopeng penyahkod perhatian silang dan ciri output token tidak bertopeng daripada pengekod untuk pembenaman output MAE. Ciri gabungan ini kemudiannya akan disusun semula ke kedudukan asal token imej input dalam output MAE akhir.
Kepala unjuran linear. Kami kemudiannya memasukkan output imej yang diperoleh melalui pengekod dan penyahkod perhatian silang ke dalam kepala projek kecil untuk menyelaraskan ciri dalam pengekod imej SAM. Untuk kesederhanaan, kertas ini hanya menggunakan kepala unjuran linear untuk menyelesaikan ketidakpadanan dimensi ciri antara pengekod imej SAM dan output MAE.
Membina semula kerugian. Dalam setiap lelaran latihan, SAMI menyertakan pengekstrakan ciri ke hadapan daripada pengekod imej SAM dan proses ke hadapan dan perambatan belakang MAE. Output daripada pengekod imej SAM dan kepala unjuran linear MAE dibandingkan untuk mengira kerugian pembinaan semula.
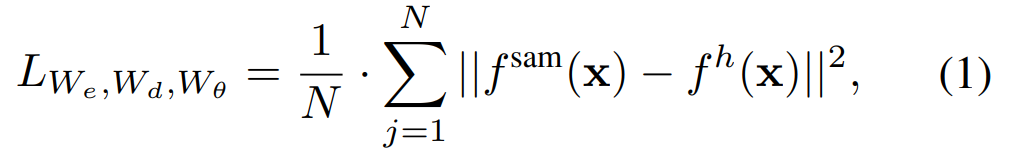
Selepas pra-latihan, pengekod boleh mengekstrak perwakilan ciri untuk pelbagai tugas visual, dan penyahkod juga akan dibuang. Khususnya, untuk membina model SAM yang cekap untuk sebarang tugas pembahagian, makalah ini menggunakan pengekod ringan pra-terlatih SAMI (seperti ViT-Tiny dan ViT-Small) sebagai pengekod imej EfficientSAM dan penyahkod topeng lalai SAM. , seperti yang ditunjukkan dalam Rajah 2 (bawah). Kertas kerja ini memperhalusi model EfficientSAM pada set data SA-1B untuk mencapai pembahagian sebarang tugas.
Klasifikasi imej. Untuk menilai keberkesanan kaedah ini pada tugas pengelasan imej, penyelidik menggunakan idea SAMI pada model ViT dan membandingkan prestasi mereka pada ImageNet-1K.
Seperti yang ditunjukkan dalam Jadual 1, SAMI dibandingkan dengan kaedah pra-latihan seperti MAE, iBOT, CAE dan BEiT, dan kaedah penyulingan seperti DeiT dan SSTA.
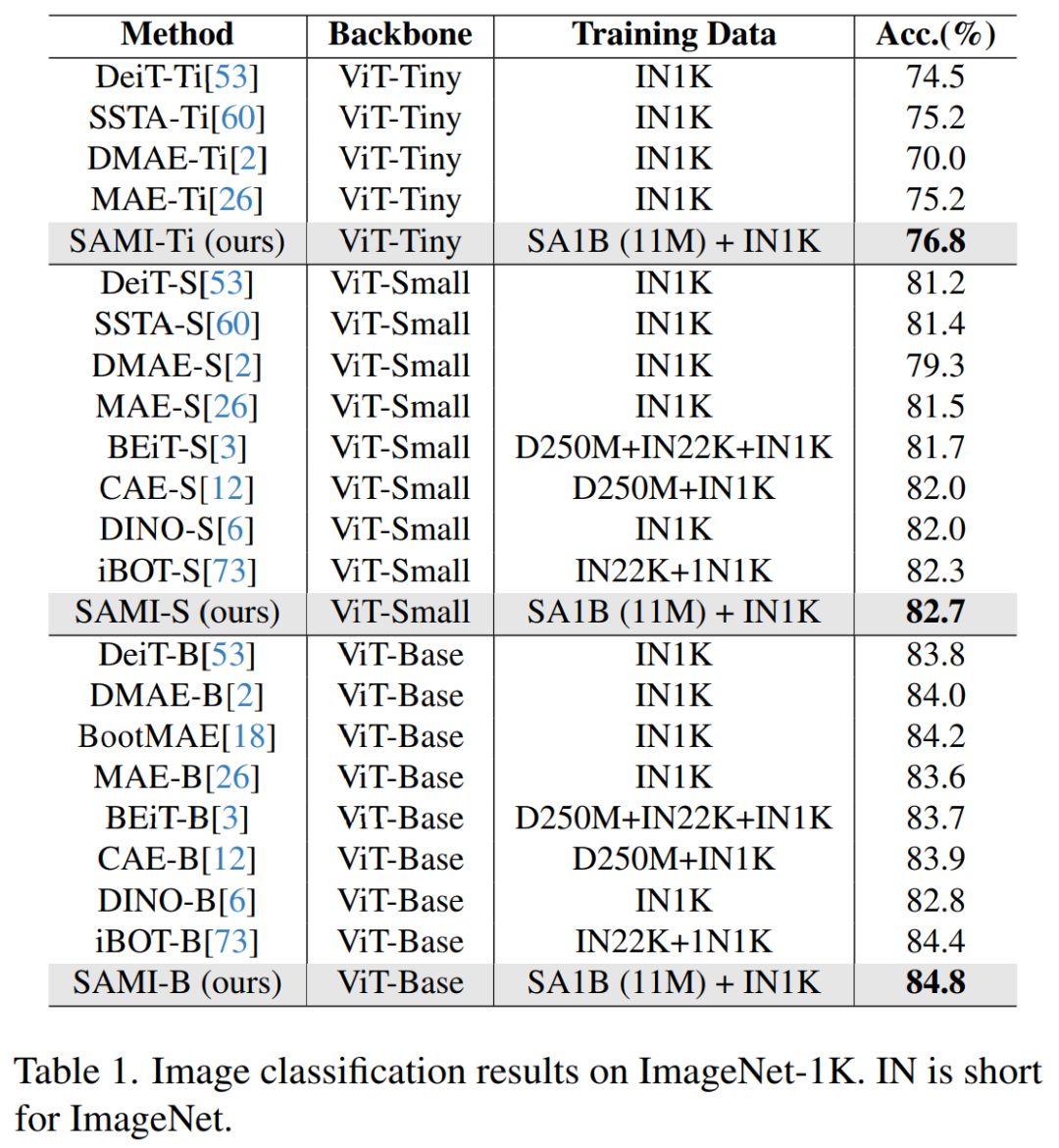
Ketepatan 1 teratas SAMI-B mencapai 84.8%, iaitu lebih tinggi daripada garis dasar pra-latihan, MAE, DMAE, iBOT, CAE dan BEiT. SAMI juga menunjukkan peningkatan yang besar berbanding kaedah penyulingan seperti DeiT dan SSTA. Untuk model ringan seperti ViT-Tiny dan ViT-Small, keputusan SAMI menunjukkan keuntungan yang ketara berbanding DeiT, SSTA, DMAE dan MAE.
Pengesanan objek dan pembahagian contoh. Makalah ini juga memanjangkan tulang belakang ViT yang dipralatih SAMI kepada pengesanan objek hiliran dan tugas pembahagian contoh dan membandingkannya dengan garis dasar yang telah dilatih pada set data COCO. Seperti yang ditunjukkan dalam Jadual 2, SAMI secara konsisten mengatasi prestasi garis dasar lain.
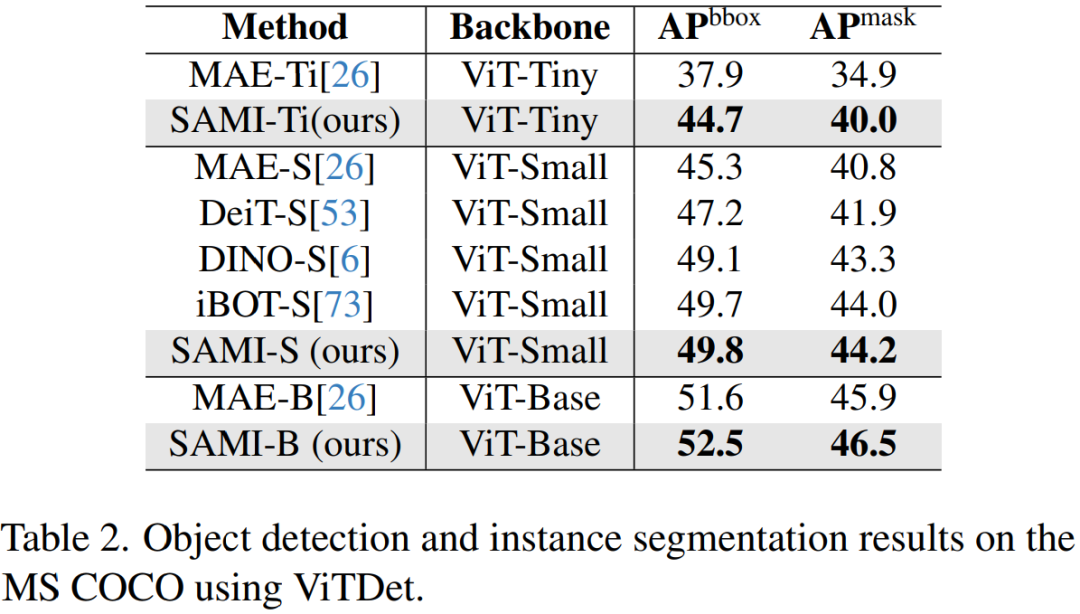
Keputusan eksperimen ini menunjukkan bahawa tulang belakang pengesan pra-latihan yang disediakan oleh SAMI sangat berkesan dalam pengesanan objek dan tugas pembahagian contoh.
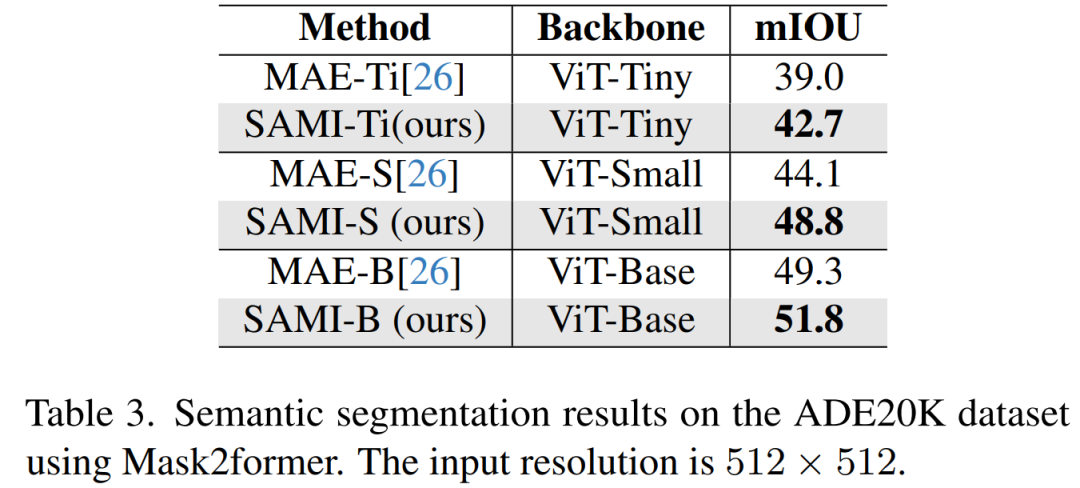
Pembahagian semantik. Kertas kerja ini memanjangkan lagi tulang belakang yang telah dilatih kepada tugasan segmentasi semantik untuk menilai keberkesanannya. Keputusan ditunjukkan dalam Jadual 3. Mask2former menggunakan tulang belakang pra-latihan SAMI mencapai mIoU yang lebih baik pada ImageNet-1K daripada menggunakan tulang belakang pra-latihan MAE. Keputusan eksperimen ini mengesahkan bahawa teknologi yang dicadangkan dalam kertas ini boleh digeneralisasikan dengan baik kepada pelbagai tugas hiliran.
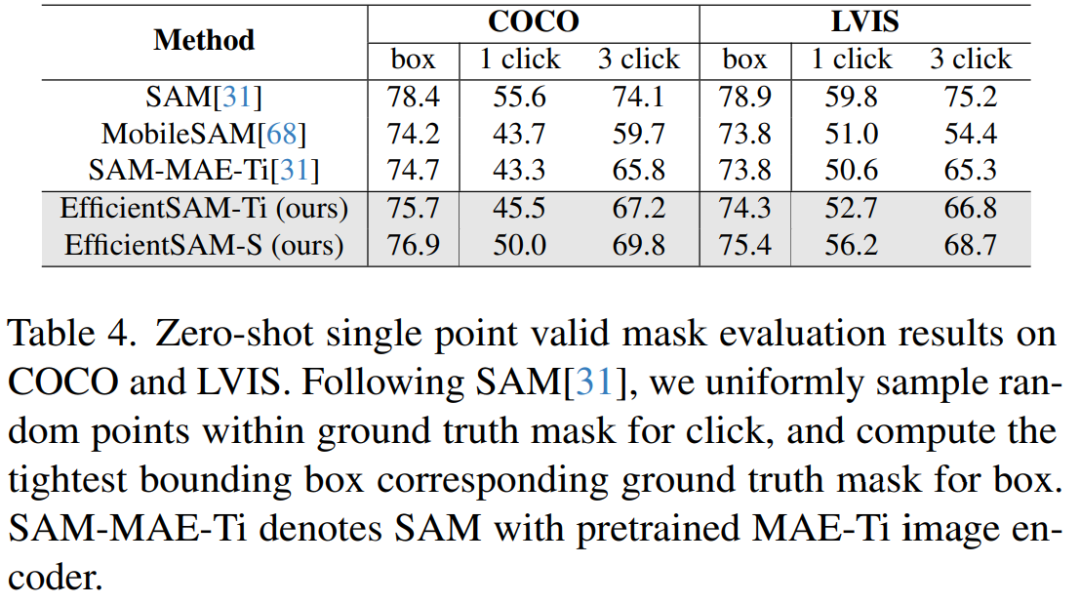
Jadual 4 membandingkan EfficientSAMs dengan SAM, MobileSAM dan SAM-MAE-Ti. Mengenai COCO, EfficientSAM-Ti mengatasi prestasi MobileSAM. EfficientSAM-Ti mempunyai pemberat pra-latihan SAMI dan juga berprestasi lebih baik daripada pemberat pra-latihan MAE.
Selain itu, EfficientSAM-S hanya 1.5 mIoU lebih rendah daripada SAM pada kotak COCO dan 3.5 mIoU lebih rendah daripada SAM pada kotak LVIS, dengan parameter 20 kali lebih sedikit. Kertas kerja ini juga mendapati bahawa EfficientSAM juga menunjukkan prestasi yang baik dalam berbilang klik berbanding dengan MobileSAM dan SAM-MAE-Ti.
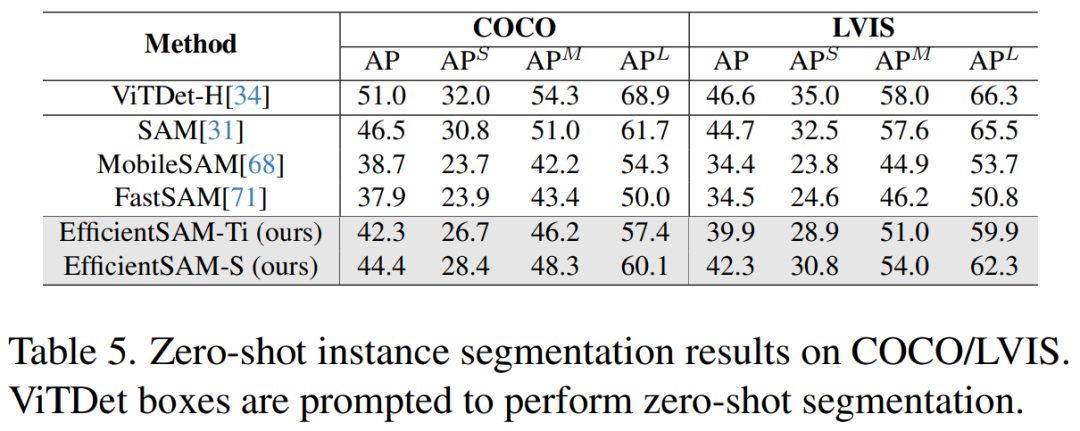
Jadual 5 menunjukkan AP, APS, APM dan APL bagi pembahagian contoh sifar pukulan. Para penyelidik membandingkan EfficientSAM dengan MobileSAM dan FastSAM, dan dapat dilihat bahawa berbanding dengan FastSAM, EfficientSAM-S memperoleh lebih daripada 6.5 AP pada COCO dan 7.8 AP pada LVIS. Dalam kes EffidientSAM-Ti, ia masih jauh lebih baik daripada FastSAM, dengan 4.1 AP pada COCO dan 5.3 AP pada LVIS, manakala MobileSAM mempunyai 3.6 AP pada COCO dan 5.5 AP pada LVIS.
Selain itu, EfficientSAM jauh lebih ringan daripada FastSAM, parameter efficientSAM-Ti ialah 9.8M, manakala parameter FastSAM ialah 68M.
Rajah 3, 4, dan 5 memberikan beberapa hasil kualitatif supaya pembaca boleh mempunyai pemahaman tambahan tentang keupayaan pembahagian contoh EfficientSAMs.



Untuk butiran penyelidikan lanjut, sila rujuk kertas asal.
Atas ialah kandungan terperinci Kertas skor sempurna VPR 2024! Meta mencadangkan EfficientSAM: cepat belah semuanya!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Penggunaan penyentuh AC
Penggunaan penyentuh AC
 Bagaimana untuk memulihkan data dari cakera keras mudah alih
Bagaimana untuk memulihkan data dari cakera keras mudah alih
 Penyelesaian kepada tandatangan tidak sah
Penyelesaian kepada tandatangan tidak sah
 Bagaimana untuk menyimpan program yang ditulis dalam pycharm
Bagaimana untuk menyimpan program yang ditulis dalam pycharm
 Lima sebab mengapa komputer anda tidak dapat dihidupkan
Lima sebab mengapa komputer anda tidak dapat dihidupkan
 Penyelesaian kepada ralat sintaks prosedur sql
Penyelesaian kepada ralat sintaks prosedur sql
 Formula pilih atur dan gabungan yang biasa digunakan
Formula pilih atur dan gabungan yang biasa digunakan
 Penyelesaian ralat httpstatus500
Penyelesaian ralat httpstatus500








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



