
 Peranti teknologi
AI
Model besar Llama kecil yang boleh dijalankan dengan sumber pengiraan dan memori yang minimum
Peranti teknologi
AI
Model besar Llama kecil yang boleh dijalankan dengan sumber pengiraan dan memori yang minimum
Model besar Llama kecil yang boleh dijalankan dengan sumber pengiraan dan memori yang minimum

Pengenalan latar belakang
Dalam era maklumat letupan semasa, latihan model bahasa menjadi semakin kompleks dan sukar. Untuk melatih model bahasa yang cekap, kami memerlukan banyak sumber dan masa pengkomputeran, yang tidak praktikal untuk ramai orang. Pada masa yang sama, kami juga berdepan dengan cabaran bagaimana menggunakan model bahasa yang besar di bawah memori dan sumber pengkomputeran yang terhad, terutamanya pada peranti edge.
Hari ini saya ingin mengesyorkan kepada anda projek sumber terbuka GitHub jzhang38/TinyLlama Projek ini mempunyai lebih daripada 4.3k bintang di GitHub Untuk memperkenalkan projek dalam satu ayat ialah: "Projek TinyLlama adalah usaha terbuka untuk pralatih model Llama 1.1B pada 3 trilion token."

Pengenalan Projek
Matlamat TinyLlama adalah untuk pra-melatih model Llama 1.1B pada 3 trilion token. Dengan pengoptimuman yang betul, kami boleh mencapai ini dalam masa 90 hari sahaja menggunakan 16 GPU A100-40G. Projek ini menggunakan seni bina dan tokenizer yang sama seperti Llama 2, yang bermaksud TinyLlama boleh dibenamkan dengan mudah dan digunakan dalam banyak projek sumber terbuka berasaskan Llama. Selain itu, TinyLlama sangat padat, dengan hanya 1.1B parameter. Kekompakan ini menjadikannya sesuai untuk banyak senario aplikasi yang memerlukan pengkomputeran terhad dan jejak memori.


Cara menggunakan
Anda boleh memuat turun model secara terus dan menggunakannya, atau gunakan demo melalui huggingface.

Jika anda ingin berlatih sendiri, sila rujuk butiran latihan di bawah.

Projek Promosi
TinyLlama ialah projek sumber terbuka yang menarik yang sedang aktif menyelesaikan beberapa masalah utama dan telah mendapat perhatian meluas dalam komuniti sumber terbuka.

Berikut ialah carta arah aliran Bintang projek (mewakili tahap aktiviti projek):

Untuk butiran lanjut projek, sila semak pautan di bawah.
Alamat projek sumber terbuka: https://github.com/jzhang38/TinyLlama
Pengarang projek sumber terbuka: jzhang38
Yang berikut adalah semua ahli yang terlibat dalam pembinaan projek:

Atas ialah kandungan terperinci Model besar Llama kecil yang boleh dijalankan dengan sumber pengiraan dan memori yang minimum. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
Awal bulan ini, penyelidik dari MIT dan institusi lain mencadangkan alternatif yang sangat menjanjikan kepada MLP - KAN. KAN mengatasi MLP dari segi ketepatan dan kebolehtafsiran. Dan ia boleh mengatasi prestasi MLP berjalan dengan bilangan parameter yang lebih besar dengan bilangan parameter yang sangat kecil. Sebagai contoh, penulis menyatakan bahawa mereka menggunakan KAN untuk menghasilkan semula keputusan DeepMind dengan rangkaian yang lebih kecil dan tahap automasi yang lebih tinggi. Khususnya, MLP DeepMind mempunyai kira-kira 300,000 parameter, manakala KAN hanya mempunyai kira-kira 200 parameter. KAN mempunyai asas matematik yang kukuh seperti MLP berdasarkan teorem penghampiran universal, manakala KAN berdasarkan teorem perwakilan Kolmogorov-Arnold. Seperti yang ditunjukkan dalam rajah di bawah, KAN telah
 Versi Kuaishou Sora 'Ke Ling' dibuka untuk ujian: menghasilkan video lebih 120-an, memahami fizik dengan lebih baik dan boleh memodelkan pergerakan kompleks dengan tepat
Jun 11, 2024 am 09:51 AM
Versi Kuaishou Sora 'Ke Ling' dibuka untuk ujian: menghasilkan video lebih 120-an, memahami fizik dengan lebih baik dan boleh memodelkan pergerakan kompleks dengan tepat
Jun 11, 2024 am 09:51 AM
Apa? Adakah Zootopia dibawa menjadi realiti oleh AI domestik? Didedahkan bersama-sama dengan video itu ialah model penjanaan video domestik berskala besar baharu yang dipanggil "Keling". Sora menggunakan laluan teknikal yang serupa dan menggabungkan beberapa inovasi teknologi yang dibangunkan sendiri untuk menghasilkan video yang bukan sahaja mempunyai pergerakan yang besar dan munasabah, tetapi juga mensimulasikan ciri-ciri dunia fizikal dan mempunyai keupayaan gabungan konsep dan imaginasi yang kuat. Mengikut data, Keling menyokong penjanaan video ultra panjang sehingga 2 minit pada 30fps, dengan resolusi sehingga 1080p dan menyokong berbilang nisbah aspek. Satu lagi perkara penting ialah Keling bukanlah demo atau demonstrasi hasil video yang dikeluarkan oleh makmal, tetapi aplikasi peringkat produk yang dilancarkan oleh Kuaishou, pemain terkemuka dalam bidang video pendek. Selain itu, tumpuan utama adalah untuk menjadi pragmatik, bukan untuk menulis cek kosong, dan pergi ke dalam talian sebaik sahaja ia dikeluarkan Model besar Ke Ling telah pun dikeluarkan di Kuaiying.
 Cara menyempurnakan deepseek di dalam negara
Feb 19, 2025 pm 05:21 PM
Cara menyempurnakan deepseek di dalam negara
Feb 19, 2025 pm 05:21 PM
Penalaan setempat model kelas DeepSeek menghadapi cabaran sumber dan kepakaran pengkomputeran yang tidak mencukupi. Untuk menangani cabaran-cabaran ini, strategi berikut boleh diterima pakai: Kuantisasi model: Menukar parameter model ke dalam bilangan bulat ketepatan rendah, mengurangkan jejak memori. Gunakan model yang lebih kecil: Pilih model pretrained dengan parameter yang lebih kecil untuk penalaan halus tempatan yang lebih mudah. Pemilihan data dan pra-proses: Pilih data berkualiti tinggi dan lakukan pra-proses yang sesuai untuk mengelakkan kualiti data yang lemah yang mempengaruhi keberkesanan model. Latihan Batch: Untuk set data yang besar, beban data dalam kelompok untuk latihan untuk mengelakkan limpahan memori. Percepatan dengan GPU: Gunakan kad grafik bebas untuk mempercepatkan proses latihan dan memendekkan masa latihan.
 Apa yang perlu dilakukan jika pelayar Edge menggunakan terlalu banyak memori Apa yang perlu dilakukan jika pelayar Edge menggunakan terlalu banyak memori
May 09, 2024 am 11:10 AM
Apa yang perlu dilakukan jika pelayar Edge menggunakan terlalu banyak memori Apa yang perlu dilakukan jika pelayar Edge menggunakan terlalu banyak memori
May 09, 2024 am 11:10 AM
1. Mula-mula, masukkan pelayar Edge dan klik tiga titik di penjuru kanan sebelah atas. 2. Kemudian, pilih [Sambungan] dalam bar tugas. 3. Seterusnya, tutup atau nyahpasang pemalam yang anda tidak perlukan.
 Tiada data OpenAI diperlukan, sertai senarai model kod besar! UIUC mengeluarkan StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Tiada data OpenAI diperlukan, sertai senarai model kod besar! UIUC mengeluarkan StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Di barisan hadapan teknologi perisian, kumpulan UIUC Zhang Lingming, bersama penyelidik dari organisasi BigCode, baru-baru ini mengumumkan model kod besar StarCoder2-15B-Instruct. Pencapaian inovatif ini mencapai kejayaan ketara dalam tugas penjanaan kod, berjaya mengatasi CodeLlama-70B-Instruct dan mencapai bahagian atas senarai prestasi penjanaan kod. Keunikan StarCoder2-15B-Instruct terletak pada strategi penjajaran diri yang tulen Keseluruhan proses latihan adalah terbuka, telus, dan sepenuhnya autonomi dan boleh dikawal. Model ini menjana beribu-ribu arahan melalui StarCoder2-15B sebagai tindak balas kepada penalaan halus model asas StarCoder-15B tanpa bergantung pada anotasi manual yang mahal.
 Melebihi DPO secara menyeluruh: Pasukan Chen Danqi mencadangkan pengoptimuman pilihan mudah SimPO, dan turut memperhalusi model sumber terbuka 8B terkuat
Jun 01, 2024 pm 04:41 PM
Melebihi DPO secara menyeluruh: Pasukan Chen Danqi mencadangkan pengoptimuman pilihan mudah SimPO, dan turut memperhalusi model sumber terbuka 8B terkuat
Jun 01, 2024 pm 04:41 PM
Untuk menyelaraskan model bahasa besar (LLM) dengan nilai dan niat manusia, adalah penting untuk mempelajari maklum balas manusia untuk memastikan bahawa ia berguna, jujur dan tidak berbahaya. Dari segi penjajaran LLM, kaedah yang berkesan ialah pembelajaran pengukuhan berdasarkan maklum balas manusia (RLHF). Walaupun keputusan kaedah RLHF adalah cemerlang, terdapat beberapa cabaran pengoptimuman yang terlibat. Ini melibatkan latihan model ganjaran dan kemudian mengoptimumkan model dasar untuk memaksimumkan ganjaran tersebut. Baru-baru ini, beberapa penyelidik telah meneroka algoritma luar talian yang lebih mudah, salah satunya ialah pengoptimuman keutamaan langsung (DPO). DPO mempelajari model dasar secara langsung berdasarkan data keutamaan dengan meparameterkan fungsi ganjaran dalam RLHF, sekali gus menghapuskan keperluan untuk model ganjaran yang jelas. Kaedah ini mudah dan stabil
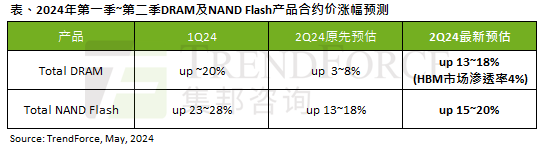 Kesan gelombang AI adalah jelas TrendForce telah menyemak semula ramalannya untuk memori DRAM dan harga kontrak memori kilat NAND meningkat pada suku ini.
May 07, 2024 pm 09:58 PM
Kesan gelombang AI adalah jelas TrendForce telah menyemak semula ramalannya untuk memori DRAM dan harga kontrak memori kilat NAND meningkat pada suku ini.
May 07, 2024 pm 09:58 PM
Menurut laporan tinjauan TrendForce, gelombang AI mempunyai impak yang besar pada memori DRAM dan pasaran memori flash NAND. Dalam berita laman web ini pada 7 Mei, TrendForce berkata dalam laporan penyelidikan terbarunya hari ini bahawa agensi itu telah meningkatkan kenaikan harga kontrak untuk dua jenis produk storan pada suku ini. Secara khusus, TrendForce pada asalnya menganggarkan bahawa harga kontrak memori DRAM pada suku kedua 2024 akan meningkat sebanyak 3~8%, dan kini menganggarkannya pada 13~18% dari segi memori kilat NAND, anggaran asal akan meningkat sebanyak 13~ 18%, dan anggaran baharu ialah 15%. ~20%, hanya eMMC/UFS mempunyai peningkatan yang lebih rendah sebanyak 10%. ▲Sumber imej TrendForce TrendForce menyatakan bahawa agensi itu pada asalnya menjangkakan untuk meneruskan
 Yolov10: Penjelasan terperinci, penggunaan dan aplikasi semuanya di satu tempat!
Jun 07, 2024 pm 12:05 PM
Yolov10: Penjelasan terperinci, penggunaan dan aplikasi semuanya di satu tempat!
Jun 07, 2024 pm 12:05 PM
1. Pengenalan Sejak beberapa tahun kebelakangan ini, YOLO telah menjadi paradigma dominan dalam bidang pengesanan objek masa nyata kerana keseimbangannya yang berkesan antara kos pengiraan dan prestasi pengesanan. Penyelidik telah meneroka reka bentuk seni bina YOLO, matlamat pengoptimuman, strategi pengembangan data, dsb., dan telah mencapai kemajuan yang ketara. Pada masa yang sama, bergantung pada penindasan bukan maksimum (NMS) untuk pemprosesan pasca menghalang penggunaan YOLO dari hujung ke hujung dan memberi kesan buruk kepada kependaman inferens. Dalam YOLO, reka bentuk pelbagai komponen tidak mempunyai pemeriksaan yang komprehensif dan teliti, mengakibatkan lebihan pengiraan yang ketara dan mengehadkan keupayaan model. Ia menawarkan kecekapan suboptimum, dan potensi yang agak besar untuk peningkatan prestasi. Dalam kerja ini, matlamatnya adalah untuk meningkatkan lagi sempadan kecekapan prestasi YOLO daripada kedua-dua pasca pemprosesan dan seni bina model. sampai habis
